『達人に学ぶDB設計徹底指南書: 初級者で終わりたくないあなたへ』第2章
p.54 COLUMN「物理レプリケーションと論理レプリケーション」が面白かったので、メモ。
データベースのレプリケーションとは
-
現用系・待機系2つのDBを用意し、現用系から待機系へデータ送信をすることで、DBのレベルでデータが同じになるようにする技術
- レプリケーションによってデータが反映される待機系DBを「レプリカ」と呼ぶこともある
- 方法としては「同期レプリケーション」と「非同期レプリケーション」の2種類
-
同期レプリケーション:現用系に渡されたデータを現用系にコミット後、そのままリアルタイムでデータを待機系に渡し、待機系コミットが確認できてからシステムに完了通知を戻す
- 非同期レプリケーションと比較して、コミット時間のずれが少ない
-
非同期レプリケーション:現用系コミット→システムに完了通知を戻した後に、同データを待機系にコミットを行う
- 同期レプリケーションと比較してコミット時間のずれが生じる
-
同期レプリケーション:現用系に渡されたデータを現用系にコミット後、そのままリアルタイムでデータを待機系に渡し、待機系コミットが確認できてからシステムに完了通知を戻す
- レプリケーションには 物理レプリケーション と 論理レプリケーション がある
- 詳細は以降
このあたりは実業務で触れているので、概略はあれのことねとわかります。
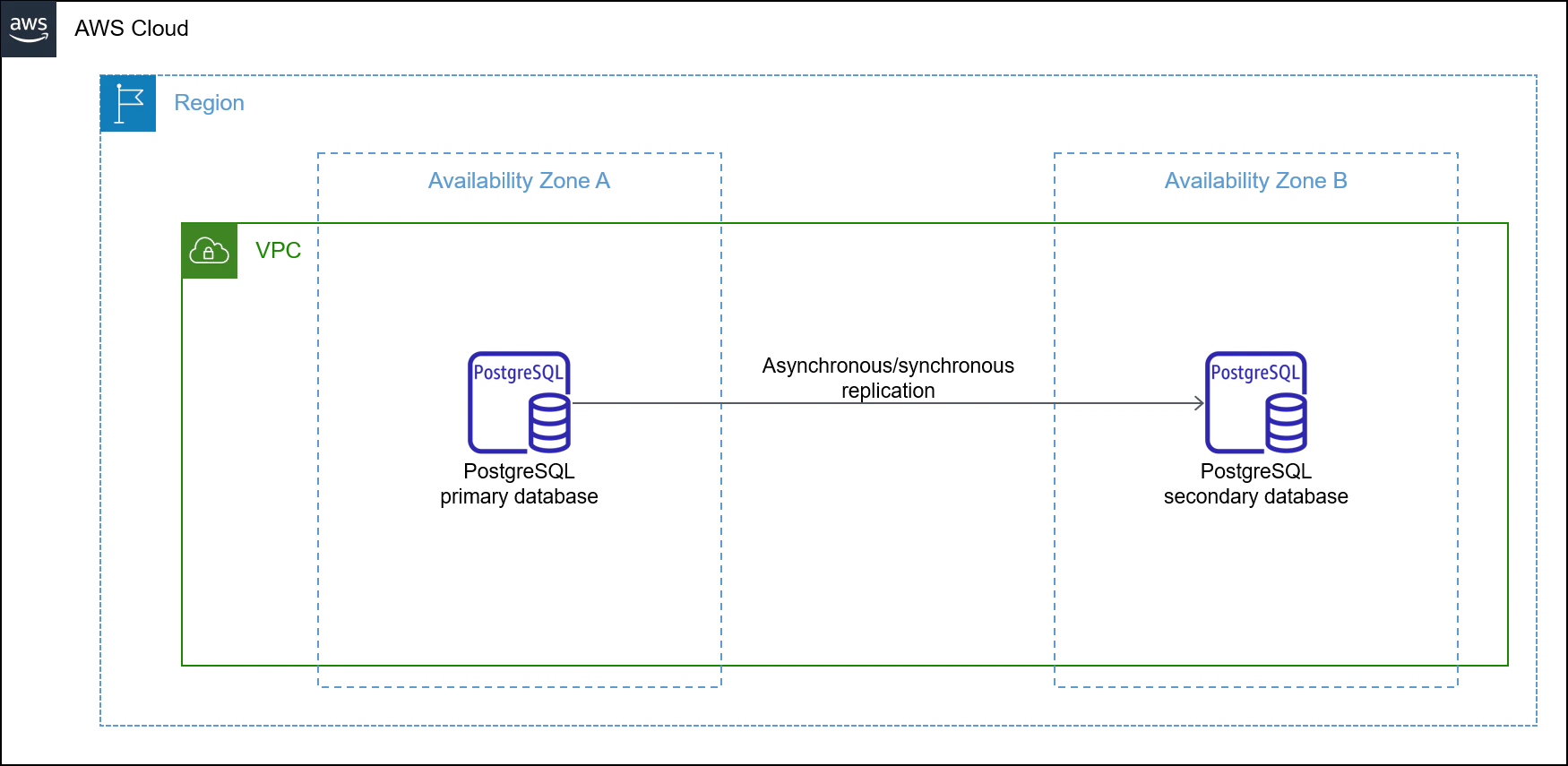
物理レプリケーション
- データベース全体の完全な複製
- トランザクションログそのもの(REDOログ、WALログ)を転送することでスタンバイ側でもバイナリレベルで同一のデータベースを複製
- したがって、異なるバージョン間での複製はできない
- 主な使用シーン
- 災害対策
- 参照負荷分散
- 先日「SQL発行回数を増やすかLINQで絞るか」という記事を書いたのですが、この場合SQL発行回数の増加に耐えられるためのDBの分散には、論理レプリケーションよりも物理レプリケーションのほうが適しているということか(というか、自分の中で漠然と物理のイメージであった)
- その他
- 「ストリーミングレプリケーション」ともいうらしい
- AWSの場合、大規模なデータベースには物理レプリケーションを利用できるが、同期にはかなりの時間がかかる場合がある
- AWSでの物理レプリケーションの一例
- 1. EC2 インスタンスのデータベースをレプリケートし、アーカイブファイルをコピー
- 2. 新しいレプリカをデータベースライターエンドポイントとして昇格
- 3. アプリケーションを新しいターゲットデータベースに向ける
論理レプリケーション
- 論理的な変更情報(特定のテーブルのレコードに対する変更情報、イメージとしては更新SQLそのもの)を転送することで、スタンバイ側で変更操作をリプレイすることで複製を行う
- したがって、基本的にテーブルに対する変更処理を対象として用いられるため、異なるバージョン間であっても複製が可能
- 主な使用シーン
- 特定テーブルの複製
- バージョンアップ時のデータ移行
- 異OS間のレプリケーション
- その他
- 「ロジカルレプリケーション」ともいうらしい
- PostgreSQLの場合
- TRANCATEコマンドやDDLはレプリケーションされない
- シーケンス、通常のテーブル以外(インデックス・ビュー・マテビューなど)もレプリケーション外
- 双方向レプリケーションはできない
- コミットされた変更情報のみ反映、ロールバックされた変更はスタンバイ側に送信されない
- レプリケーション衝突(一意制約の衝突など)が発生した場合、変更情報を適用するプロセスはエラー終了する
- レプリケーション衝突を検知する機能は搭載していない
余談
- レプリケーションが個人的に面白いと思った点
- 突発的に発生する可能性がある自体を想定していかに対策を組むか、というところが面白い
- アプリケーションのアーキテクチャもそうで、制限がある中で最大限目的が達成できる水準を見極めて狙っていくみたいなことを考えるのがたのしい
他参考