はじめに
RUNTEQ Advent Calendar 2022の24日目の記事です。
プログラミングスクールRUNTEQ内でチームメンバーを募り、東京都オープンデータハッカソンに出場してpluspoというサービスを開発中です。
サービス内でスポーツ施設のHPに載っているデータを使用しているのですが、現在のデータは手打ちで入れています。
さすがにこのままじゃあこの先厳しいので、後々スクレイピングでデータを入れようと考えています。
しかし、、、チーム内にスクレイピングに知見のあるメンバーがいません...!(もちろん校長を除いて)
ということで初スクレイピングしてみました!
(pluspoのレイアウトが崩れていますが突っ込まないでくださいw)
※ スクレイピングは法に触れる場合があるみたいなので諸々確認してから行ってください。
早速スクレイピングする
簡単にできそうなmechanizeというgemを使ってみます。
mechanizeの使い方
開発環境これです(一応)
rubyは2系でも全然いいです。
~/P/mechanize-scrape ❯❯❯ ruby -v [main]
ruby 3.1.2p20 (2022-04-12 revision 4491bb740a) [x86_64-darwin19]
ディレクトリ作ってmechanize入れる。
mkdir mechanize-scrape
cd mechanize-scrape
gem install mechanize
scrape.rbというファイルに書いていきます。
ベースとなる書き方はこれだけです。
require 'mechanize'
agent = Mechanize.new
page = agent.get('スクレイピングしたいページのURL')
これだけ書いたら、あとはpage.searchでアクセスしたページ内の好きなHTML要素を取得できます。
# divタグの中のaタグを全て取得する
a_elements = page.search('div a')
あとはrubyメソッドを使用して好きに成形すればOK!
pluspoでやってみる
pluspoには以下のようにスポーツ施設の情報が一覧表示されているので、これをスクレイピングで取得してみます。
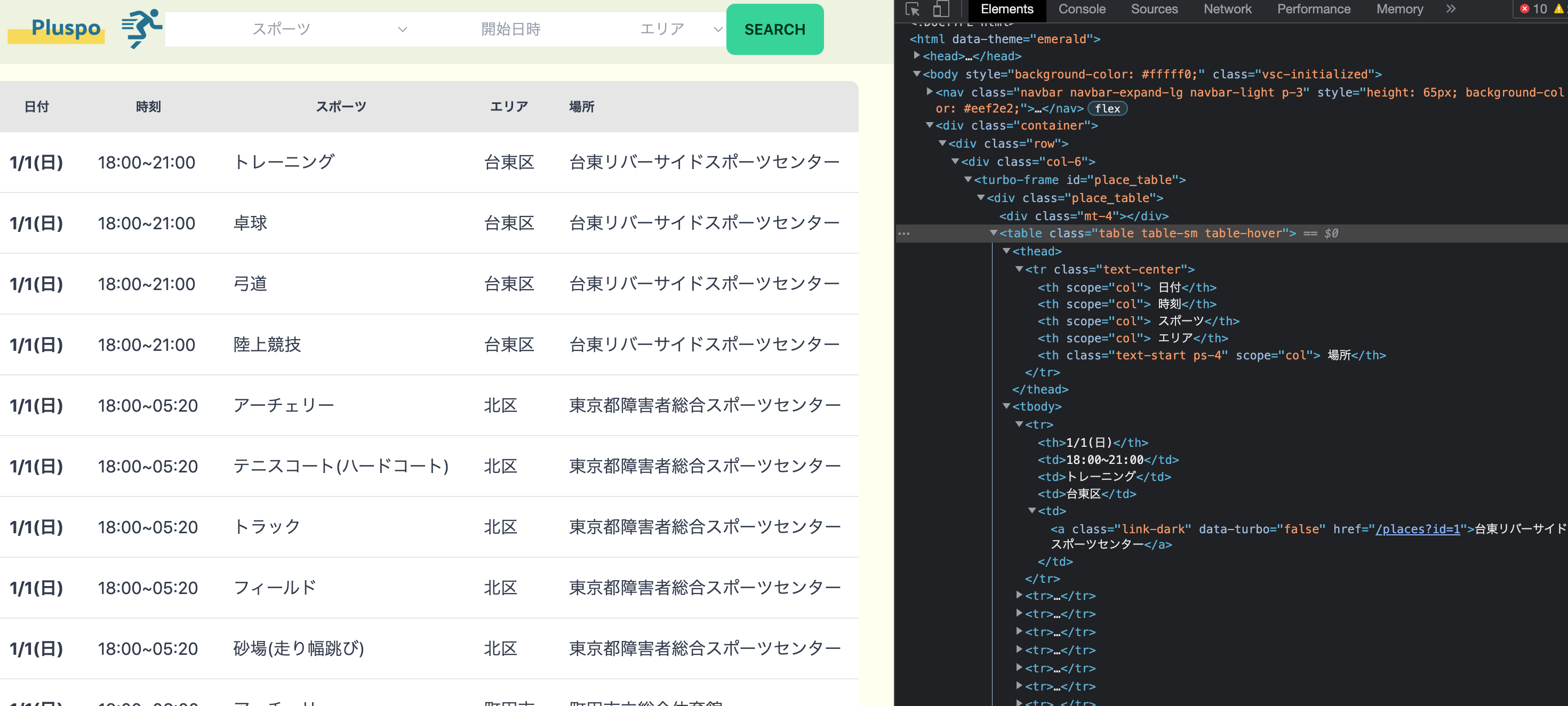
この一覧表示はtableで作られているため、この構造を解析して取得します。
<thead>と<tbody>を利用して取得していきます。
メソッドチェーンが凄まじいですが気にせずに行きましょう〜
そして取得したデータはcsvに出力します。
rubyでcsvを使う場合、gemなどは必要ないみたいです。便利!
require 'csv'
require 'mechanize'
agent = Mechanize.new
page = agent.get('https://pluspo.magia.runteq.jp/')
# csvに出力したいデータをここに格納していく
data = []
# テーブルのヘッダを取得して格納
thead_elements = page.search('thead tr')
data << thead_elements.children[0].children.map{|th| th.text}
# テーブルのレコードを取得して格納
tbody_elements = page.search('tbody tr')
data += tbody_elements.children.map{|t| t.children[0].text}.each_slice(5).to_a
# 取得したデータをCSVに書き込む
CSV.open('./result.csv','w', force_quotes: true) do |csv|
data.each do |datum|
csv << datum
end
end
そしてスクレイピング実行!
# これだけ!
ruby scrape.rb
csvファイルが新たに作られ、ちゃんと出力されていますね!
" 日付"," 時刻"," スポーツ"," エリア"," 場所"
"1/1(日)","18:00~21:00","トレーニング","台東区","台東リバーサイドスポーツセンター"
"1/1(日)","18:00~21:00","卓球","台東区","台東リバーサイドスポーツセンター"
"1/1(日)","18:00~21:00","弓道","台東区","台東リバーサイドスポーツセンター"
"1/1(日)","18:00~21:00","陸上競技","台東区","台東リバーサイドスポーツセンター"
"1/1(日)","18:00~05:20","アーチェリー","北区","東京都障害者総合スポーツセンター"
"1/1(日)","18:00~05:20","テニスコート(ハードコート)","北区","東京都障害者総合スポーツセンター"
"1/1(日)","18:00~05:20","トラック","北区","東京都障害者総合スポーツセンター"
"1/1(日)","18:00~05:20","フィールド","北区","東京都障害者総合スポーツセンター"
"1/1(日)","18:00~05:20","砂場(走り幅跳び)","北区","東京都障害者総合スポーツセンター"
"1/1(日)","18:00~06:00","アーチェリー","町田市","町田市立総合体育館"
"1/1(日)","18:00~06:00","インディアカ","町田市","町田市立総合体育館"
"1/1(日)","18:00~06:00","エアロビクス","町田市","サン町田旭体育館"
"1/1(日)","18:00~06:00","エアロビクス","町田市","町田市立総合体育館"
"1/1(日)","18:00~06:00","エアロビクス","町田市","町田市立総合体育館"
"1/1(日)","18:00~06:00","クラシックバレエ","町田市","町田市立総合体育館"
"1/1(日)","18:00~06:00","クラシックバレエ","町田市","町田市立総合体育館"
"1/1(日)","18:00~06:00","ゴールボール","北区","東京都障害者総合スポーツセンター"
"1/1(日)","18:00~06:00","ゴールボール","北区","東京都障害者総合スポーツセンター"
"1/1(日)","18:00~06:00","サウンドテーブルテニス","北区","東京都障害者総合スポーツセンター"
"1/1(日)","18:00~06:00","シッティングバレーボール","北区","東京都障害者総合スポーツセンター"
感想
初めてスクレイピングしてみましたけど、意外と簡単ですね?
ただ実際にスクレイピングしたいスポーツ施設のHPは、HTML構造はサイト毎に違うしかなり複雑なものもあるので一筋縄ではいかなそうです。。。
スクレイピングの難易度はHTML構造の複雑さと直結すると思いました。