はじめに
前回の ADOPT の記事で RAdam を強く推したのですが、一般的に RAdam は使われていません。RAdam が学習率のスケジューリングと干渉して使いづらい点が広く使われない原因と考えています。
しかしながら、現在 RAdam と相性のいいスケジューリング手法が主流になりそうということで紹介したいと思います。
紹介する手法は下記の3つなります。
- ScheduleFree
- WSD/WSD-S
- Constant LR + EWA
ScheduleFree
ScheduleFree ついては RAdamScheduleFree の作者のはまなすなぎさ氏がこれ以上ないぐらいに詳しく書いています。
なんども読み返しました。
RAdamScheduleFree は学習率ぐらいしか設定する必要があるハイパーパラメータがないため、極めて使いやすいです。RAdamScheduleFree を使えばそれだけであなたも RAdam ユーザです。
注意点としては以下の2点があります。
- 学習時と評価時のパラメータが異なるため、学習時の指標が参考情報程度(ただし、実行した感じでは割と順調に学習損失も減っていきます)
- Batch Normalization を使った場合、Batch Normalization 用の統計情報を評価の直前に取り直す必要がある
学習時の損失は元々参考情報みたいなものですし、Batch Normalization は最近はめっきり使わないため、実質デメリットなしです。
WSD/WSD-S
WSD は Warmup-Stable-Decay の略です。
つまり、最初に学習率を0から徐々に上げていき、一定の学習率で学習した後、最後に学習率を下げながら学習する手法です。最近 Cosine Annealing LR よりも良いという評判です。
この手法で RAdam を適用する場合、単純に Warmup の部分を RAdam で代替すればよいはずです。RAdam-Stable-Decay ということになるのでしょうか。
以下に詳しい分析をした論文へのリングを記載します。
この論文では WSD-S(WSD-Simplified)という手法を提案しています。
違いは学習の再開の仕方で一度 WSD で学習を行いパラメータを保存した後にさらに長く学習したいというときに挙動が異なります。WSD では学習率を下げる直前のパラメータを保存しておいて、そこから再開します。対して、WSD-S では学習率を下げ終わった後に保存したものから再開します。
以下に論文中の図を引用します。
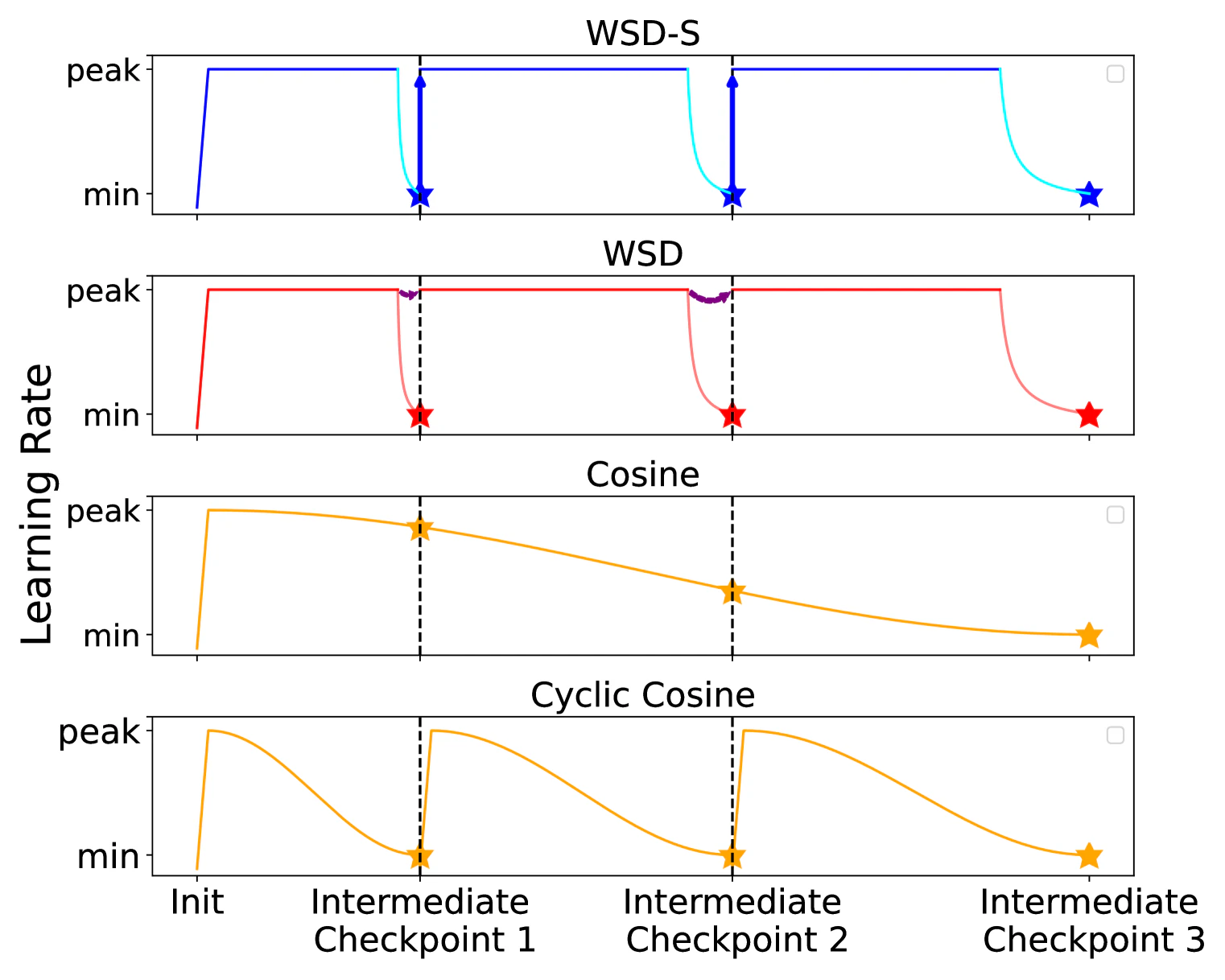
デメリットとしては学習中の validation の指標が参考にならないという点ぐらいでしょうか。基本的に Decay の際に急激に指標が良くなるので。
Constant LR + EWA
Constant LR + EWA は学習自体は固定学習率で行い、評価用モデルを EWA で作成します。
EWA は Exponentially Weighted Average の略で学習中に、一定間隔でパラメータの指数移動平均を計算し、評価用モデルとします。
この手法も単純に RAdam と組み合わせて使っても何も問題がありません。なにせ学習率は一定なのですから。
以下の論文で ScheduleFree, WSD, Constant LR +EWA の比較で、最も性能が良かったと紹介されています。
デメリットとしてはメモリ使用量が増加する点、ScheduleFree と同様に Batch Normalization の統計量を取り直す必要がある点があります。
おわりに
RAdam を使いやすい手法について紹介しました。
どれも単に RAdam と組み合わせ易いだけではなく、性能が良い上に学習の中断・延長などがしやすい利便性の高い手法なのでおすすめです。