はじめに
最近(2024年11月頃)発表された Adam 系の最適化機である ADOPT について色々遊んでみた結果です。
ADOPT とは
ADOPT は最近(2024年11月頃)発表された Adam 系の最適化機です。
Adam では保証されていない理論的な収束の保証されている点が特徴です。
元論文とソースコードへのリンクは以下になります。
論文
ソースコード
次に更新式について記します。
$$
\begin{align}
m_t &\leftarrow \beta_1 m_{t-1} + (1 - \beta_1)Clip(\frac{g_t}{max(\sqrt{v_{t-1}}, \epsilon)}, C_t) \\
\theta_t &\leftarrow \theta_{t-1} - \alpha m_t\\
v_t &\leftarrow \beta_2 v_{t-1} + (1 -\beta_2)g_t \odot g_t
\end{align}
$$
ただし、$m_t$ の更新には $v_{t-1}$ を参照するため、最初のステップでは以下の式で $v_t$ の設定のみを行います。
$$
v_0 \leftarrow g_0 \odot g_0
$$
Adam との主な違いは以下2点です。
- 勾配の正規化に一つ前のステップの $v_{t-1}$ を利用する
- 勾配の正規化の後に移動平均を計算する
ADOPT の体感的な挙動の確認
ADOPT について理論的なことはまったくわからなかったため、実験して挙動を確認しました。
トイ関数
トイ関数は論文中に記載のある以下のものになります。
$$
\begin{align}
&f_t \left( \theta \right) =
\begin{cases}
k \theta, & \text { with probability } 1/k \\ - \theta, & \text { with probability } 1 - 1 / k \\
\end{cases}
\end{align}
$$
この関数は期待値が $\frac{\theta}{k}$ なので最適化を行うと、$\theta$ が小さくなっていきます。
私の実装では論文と異なり特にクリップしていないので、無限に小さくなります。
k を 50 として実験を行いました。
最初は数式の通り、疑似乱数を使ったのですが、相当長く実行しないと期待した結果になりませんでした。そこで、ズル&手抜きで $k \theta$ を 1 回返したら、$k - 1$回の $- \theta$ 返すようにしました。
ざっと以下の最適化機の結果を計算しました。
- Momentum SGD
- Adam
- AMSGrad
- ADOPT
- Lion
なお、ADOPT では素の挙動を確認するため、クリッピングをオフにしています。適応学習率に関連する $\beta_2$ を利用する手法ではに 0.99 に統一しています。それ以外のハイパーパラメータはグラフが極端にならないように調整しています。詳細については末尾の実装に記載しています。
結果は以下の通りです。
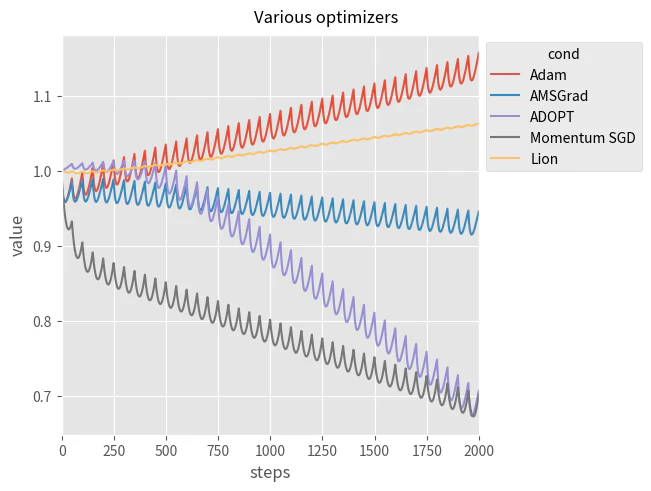
傾向で分類すると以下のようになります。
- $\theta$ の値が減少(最小化成功)
- Momentum SGD, AMSGrad, ADOPT
- $\theta$ の値が増加(最小化失敗)
- Adam, Lion
SGD について単純に勾配の大きさの分更新しているため、素直に値が小さくなっていると考えて良さそうです。
次に Adam が失敗している理由を考えます。最初にトイ関数の出力毎に出現確率と勾配の積を計算します。
| 出力 | 勾配 | 出現確率 | 出現確率と勾配の積 | 出現確率と勾配の積(k=50の場合) |
|---|---|---|---|---|
| $k \theta$ | $k$ | $1/k$ | 1 | 1 |
| $-\theta$ | $-1$ | $\frac{k - 1}{k}$ | $-\frac{k - 1}{k}$ | $-\frac{49}{50} = -0.98$ |
$k \theta$ の場合の方が出現確率と勾配の積が大きくなっています。しかし、差はわずかであるため $k \theta$ のときの適応学習率が $-\theta$ のときの適応学習率よりも小さくなれば、更新方向は逆になりそうです。実際、Adam では更新方向が逆になりました。
もう少し詳しく考えると Adam の適応学習率は $\frac{1}{\sqrt{v_t}}$ です。このとき $v_t$ は指数移動平均であるため、勾配が大きい $k \theta$ のときに大きくなり、勾配が小さい $-\theta$ のときに徐々に小さくなるという動作を繰り返します。つまり、$k \theta$ のときの適応学習率が最も小さくなります。どの程度小さくなるかは $\beta_2$ に依存します。
試しに、$\beta_2$ を変更した Adam を実行してみます。なお、比較のために ADOPT の結果も記載しています。
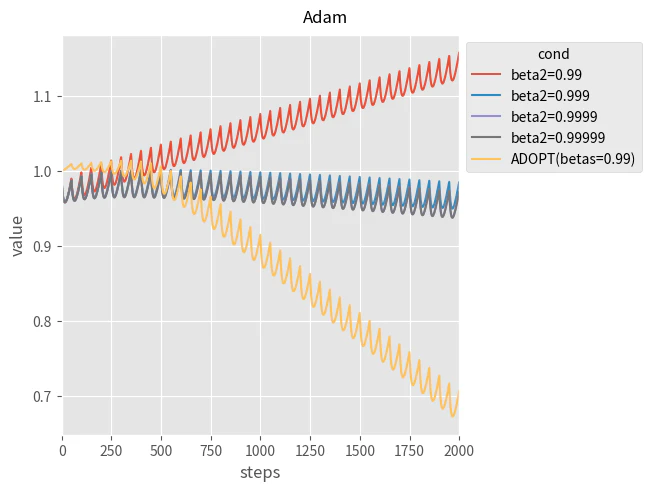
$\beta_2$ を 0.999 にすると最小化に成功するようになりました。それでは $\beta_2$ を大きくすればよいという話になりそうなところですが、私の経験では $\beta_2$ を大きくすると性能が悪化します。そのため、安易に大きくはできません。
一方、ADOPT の場合、$v_{t-1}$ を正規化に利用します。そのため、適応学習率が最も小さくなるのは $k\theta$ の次のステップであり、 $k\theta$ での適応学習率は逆に最大の値になります。
まとめると Adam と ADOPT の挙動の違いは以下になります。
- Adam では相対的に大きな勾配の適応学習率は相対的に小さくなる
- ADOPTでは逆に相対的に大きな勾配の適応学習率は相対的に大きくなる
ただし、あくまで相対的な違いであるため、すべての勾配の大きさが単純に2倍になるようなケースでは双方とも適応学習率は半分になります。
密な方向が正しい場合のトイ関数
前述の実験で ADOPT では勾配が相対的に大きいステップでの適応学習率を多くすることがわかりました。そこで先程のトイ関数とは逆に、多数の小さい勾配の方向が最小化の方向となるような場合はどうなるのかという疑問が浮かびました。
期待値が負の値になるようにトイ関数を改変し、実験をしてみました。
$$
\begin{align}
&f_t \left( \theta \right) =
\begin{cases}
(0.96 * 50) \theta, & \text { with probability } 1/50 = 0.02\\- \theta, & \text { with probability } 1 - 1 /50 = 0.98\\
\end{cases},
\end{align}
$$
k = 50 の場合に期待値が負になるような係数を $k \theta$ にかけています。今回は 0.96 を使いました。
この場合、期待値は -$0.02 \theta$ となり僅かに負の値となります。
実行結果は以下になります。
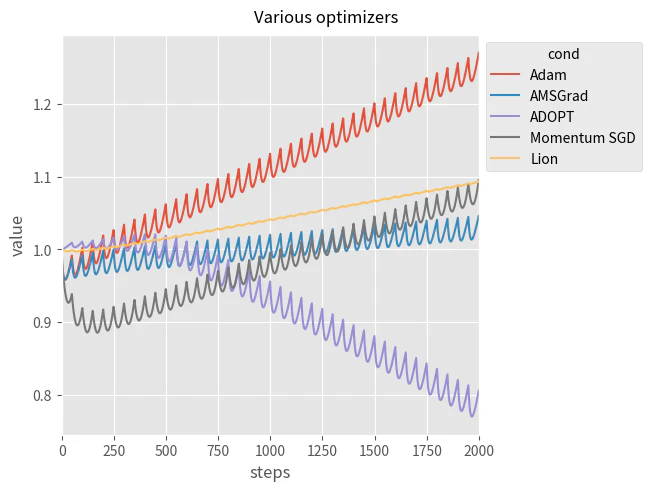
期待値が負の値なので $\theta$ の値は上昇することを期待しましたが、ADOPT では値は減少しています。
理論的には収束が保証されているはずなので、このトイ関数が理論上の前提から外れてるということになるのかもしれません。しかし、私には収束の保証に関する証明がまったくわからないので、なんとも言えません。
初期の不安定性について
次に話を変えましてトイ関数を元に戻した上で最初の $k \theta$ の位置 p を変えて挙動を確認し、不安定な部分を改善できないか試みました。
$k \theta$ の位置 p = 0 の場合、0 step 目の損失の値が $k \theta$ となり、$k$回毎に $k \theta$となります。
p = 1 では同様に、1 step 目の損失の値が $k \theta$ となり、そこから $k$回毎に $k \theta$となります。
k = 50, p = 0, 1, 49 の場合の ADOPT の挙動を確認します。
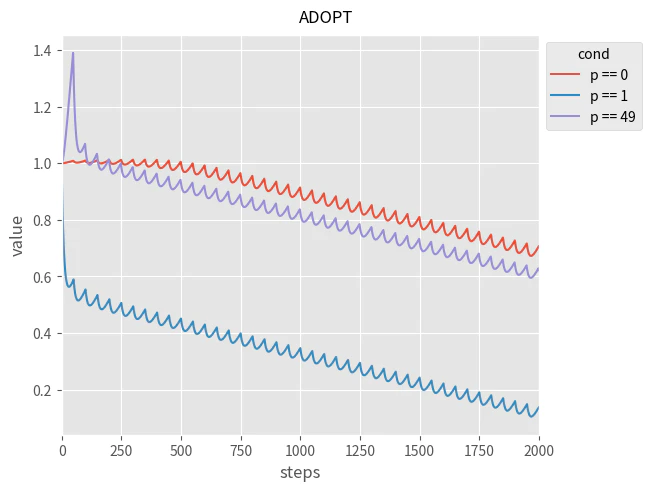
初期の挙動に以下の問題があるように見えます
- p = 0 で更新幅が小さい
- p = 1 で更新幅が大きすぎる
- p = 49 で $\theta$ が非常に大きくなる
バイアス補正
ADOPT では Adam のバイアス補正が削除されています。
バイアス補正を復活させると挙動が改善されるか確認しました。
まず、$m_t$(正規化された勾配の指数移動平均)のバイアス補正の復活させます。
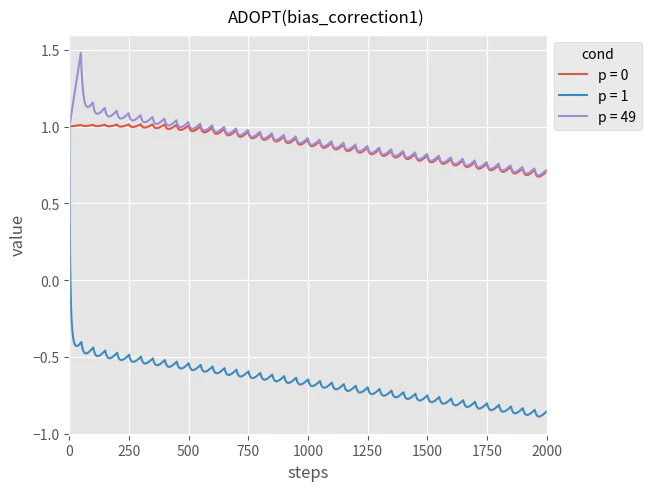
どの問題も改善せずに、1 と 3 は問題が悪化しました。
つぎに、$v_t$ (勾配の2乗の指数移動平均)勾配のバイアス補正の復活させます。この場合は $m_t$のバイアス補正は再度無効にしています。
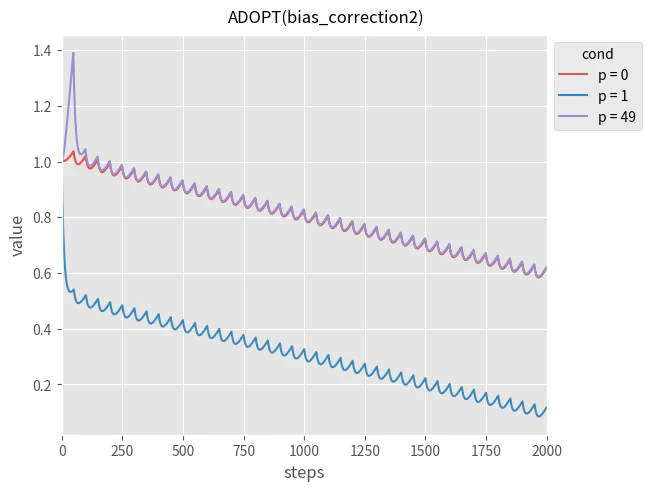
問題2が改善しました。
しかし、他の問題はそのままです。
RAdam
Adam にて学習を安定させる手法として RAdam があります。
以下に参考文献へのリンクを記します。
今回の実験にあたっては、 $\rho_t$ が 4 未満の場合 SGD で更新するのではなく、補正項を 0 としてまったく更新が発生しないように実装しました。また、最初に更新が行われる5ステップ目で $k^2 \theta$ となるように調整した場合についても、実行を行い不安定な挙動をしないか確認しました。
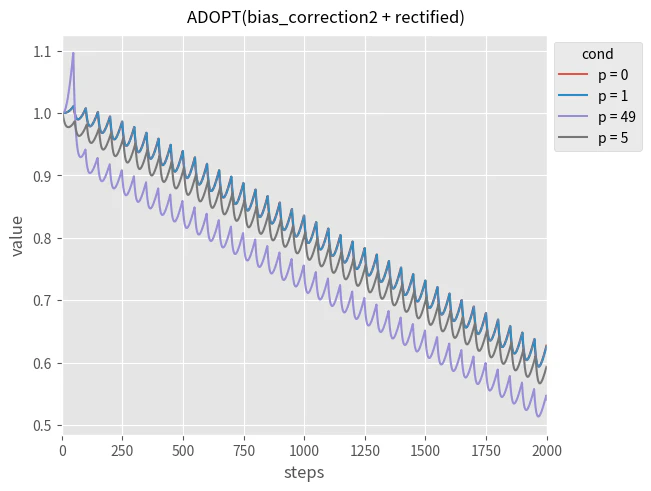
p=1 での初期の更新量が大きい問題は完全に解決し、p=49 で大きくなる問題も大きく軽減されています。また、p=5での挙動も安定おり、ADOPT で RAdam を採用するメリットは大きいと考えています。
RAdam の ADOPT における重要性について
ADOPT では Adam 以上に RAdam が重要です。
なぜなら Adam の場合、RAdam は単純に学習率のスケジューリングで等価な処理が可能であるのに対して、ADOPT では困難であるためです。
まず、Adam で学習率のスケジューリングで代替できることを説明します。
Adam の場合、以下の更新式を見ての通り、RAdam の補正項 $r_t$ は学習率 $\alpha$ と同じ場所で同じように乗算します。
RAdam の更新式(バイアス補正と $\epsilon$ については省略)
$$
\begin{align}
m_t &= \beta_1 m_{t-1} + (1 - \beta_1) g_t \\
v_t &= \beta_2 v_{t-1} + (1 - \beta_2) g_t^2 \\
\theta &= \theta - \alpha \mathbf{r_t} \frac{m_t}{\sqrt{v_t}}
\end{align}
$$
したがって、学習率を $\alpha r_t$ にスケジュールすることと等価となります。
次に ADOPT で学習率のスケジューリングで RAdam を代替することが難しい理由を説明します。
ADOPT での更新式は以下の通りです。
ADOPT + RAdam の更新式(バイアス補正と $\epsilon$ については省略)
$$
\begin{align}
m_t &= \beta_1 m_{t-1} + (1 - \beta_2) \mathbf{r_t}\frac{g_t}{\sqrt{v_{t-1}}} \\
\theta &= \theta - \alpha m_t \\
v_t &= \beta_2 v_{t-1} + (1 - \beta_2) g_t^2
\end{align}
$$
学習率 $\alpha$ と RAdam の補正項 $r_t$ が計算式上まったく別の場所にあり、学習率 $\alpha$ をスケジュールすることで等価な式を作ることができません。
もちろん、単純に Warmup を採用することで学習が安定する可能性は高いですが、計算式上は別物になります。
まとめ
様々な条件でトイ関数を ADOPT を最適化しました。その結果、失敗した条件もあったため、無条件で Adam から乗り換えられるようなものではないと感じました。
また、ADOPT においては RAdam の重要性が高く私としては採用を強く勧めます
付録: 実験用ソースコード
実験用のソースコードの本体と実験用の ADOPT の実装の2ファイルあります。
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import torch
import torch.nn as nn
from torch.optim import SGD, Adam
from experimental_adopt import ExperimentalADOPT as ADOPT
from pytorch_optimizer import Lion
plt.style.use('ggplot')
class Model(nn.Module):
def __init__(self):
super().__init__()
self.var1 = nn.Parameter(torch.ones([]))
def forward(self):
return self.var1
class ToyFunc(nn.Module):
def __init__(self, k=50, p=0, pos_coeff=1.0, neg_coeff=1.0):
super().__init__()
self.p = p
self.k = k
self.pos_coeff = pos_coeff
self.neg_coeff = neg_coeff
def forward(self, x, step):
'''
E(var1) = var1/k
'''
if step % self.k == self.p:
return x * self.k * self.pos_coeff
else:
return -x * self.neg_coeff
def testOptim(loss, optim, total_steps):
ys = []
model = Model()
o = optim(model.parameters())
if hasattr(o, 'eval'):
o.train()
for i in range(total_steps):
def _p():
o.zero_grad()
y = model()
loss(y, i).backward()
o.step(_p)
ys.append(model.var1.item())
return ys
def testOptims(title, output, conds, total_steps):
results = []
xs = torch.arange(total_steps)
for name, loss, optim in conds:
ys = testOptim(loss, optim, total_steps)
df = pd.DataFrame({'steps': xs, 'value': ys})
df['cond'] = name
results.append(df)
results = pd.concat(results, ignore_index=True)
fig, ax = plt.subplots(layout="constrained")
try:
sns.lineplot(results, x='steps', y='value', hue='cond', ax=ax)
sns.move_legend(ax, loc='upper left', bbox_to_anchor=(1.0, 1.0))
fig.suptitle(title)
fig.savefig(output, bbox_inches="tight")
finally:
fig.clf()
plt.close(fig)
def opt(cls, *args, **kwargs):
def _p(ps):
return cls(ps, *args, **kwargs)
return _p
loss = ToyFunc(50, 0)
testOptims('Various optimizers', 'images/various_optimizers.png',
[
('Adam', loss, opt(Adam, 0.01, betas=(0.9, 0.99))),
('AMSGrad', loss, opt(Adam, 0.01, betas=(0.9, 0.99), amsgrad=True)),
('ADOPT', loss, opt(ADOPT, 0.01, betas=(0.9, 0.99), clip_lambda=None)),
('Momentum SGD', loss, opt(SGD, 1e-4, 0.98)),
('Lion', loss, opt(Lion, 1e-4)),
],
total_steps=2000)
loss = ToyFunc(50, 0, pos_coeff=0.96)
testOptims('Various optimizers', 'images/various_optimizers_toyfunc2.png',
[
('Adam', loss, opt(Adam, 0.01, betas=(0.9, 0.99))),
('AMSGrad', loss, opt(Adam, 0.01, betas=(0.9, 0.99), amsgrad=True)),
('ADOPT', loss, opt(ADOPT, 0.01, betas=(0.9, 0.99), clip_lambda=None)),
('Momentum SGD', loss, opt(SGD, 1e-4, 0.98)),
('Lion', loss, opt(Lion, 1e-4)),
],
total_steps=2000)
loss = ToyFunc(50, 0)
testOptims('Adam', 'images/adam_beta2.png',
[
('beta2=0.99', loss, opt(Adam, 0.01, betas=(0.9, 0.99))),
('beta2=0.999', loss, opt(Adam, 0.01, betas=(0.9, 0.999))),
('beta2=0.9999', loss, opt(Adam, 0.01, betas=(0.9, 0.99999))),
('beta2=0.99999', loss, opt(Adam, 0.01, betas=(0.9, 0.999999))),
('ADOPT(betas=0.99)', loss, opt(ADOPT, 0.01, betas=(0.9, 0.99), clip_lambda=None)),
],
total_steps=2000)
testOptims('ADOPT', 'images/adopt.png',
[
('p == 0', ToyFunc(50, 0), opt(ADOPT, 0.01, betas=(0.9, 0.99), clip_lambda=None)),
('p == 1', ToyFunc(50, 1), opt(ADOPT, 0.01, betas=(0.9, 0.99), clip_lambda=None)),
('p == 49', ToyFunc(50, 49), opt(ADOPT, 0.01, betas=(0.9, 0.99), clip_lambda=None)),
],
total_steps=2000)
testOptims('ADOPT(bias_correction2)', 'images/adopt_bias_correction2.png',
[
('p = 0', ToyFunc(50, 0), opt(ADOPT, 0.01, betas=(0.9, 0.99), clip_lambda=None, do_bias_correction2=True)),
('p = 1', ToyFunc(50, 1), opt(ADOPT, 0.01, betas=(0.9, 0.99), clip_lambda=None, do_bias_correction2=True)),
('p = 49', ToyFunc(50, 49), opt(ADOPT, 0.01, betas=(0.9, 0.99), clip_lambda=None, do_bias_correction2=True)),
],
total_steps=2000)
testOptims('ADOPT(bias_correction1)', 'images/adopt_bias_correction1.png',
[
('p = 0', ToyFunc(50, 0), opt(ADOPT, 0.01, betas=(0.9, 0.99), clip_lambda=None, do_bias_correction1=True)),
('p = 1', ToyFunc(50, 1), opt(ADOPT, 0.01, betas=(0.9, 0.99), clip_lambda=None, do_bias_correction1=True)),
('p = 49', ToyFunc(50, 49), opt(ADOPT, 0.01, betas=(0.9, 0.99), clip_lambda=None, do_bias_correction1=True)),
],
total_steps=2000)
testOptims('ADOPT(bias_correction2 + rectified)', 'images/adopt_rectified.png',
[
('p = 0', ToyFunc(50, 0), opt(ADOPT, 0.01, betas=(0.9, 0.99), clip_lambda=None, do_bias_correction2=True, rectified=True)),
('p = 1', ToyFunc(50, 1), opt(ADOPT, 0.01, betas=(0.9, 0.99), clip_lambda=None, do_bias_correction2=True, rectified=True)),
('p = 49', ToyFunc(50, 49), opt(ADOPT, 0.01, betas=(0.9, 0.99), clip_lambda=None, do_bias_correction2=True, rectified=True)),
('p = 5', ToyFunc(50, 5), opt(ADOPT, 0.01, betas=(0.9, 0.99), clip_lambda=None, do_bias_correction2=True, rectified=True)),
],
total_steps=2000)
experimental_adopt.py
from typing import Callable, Optional, Tuple
import torch
from torch import Tensor
from torch.optim.optimizer import Optimizer, ParamsT
class ExperimentalADOPT(Optimizer):
def __init__(
self,
params: ParamsT,
lr: float = 1e-3,
betas: Tuple[float, float] = (0.9, 0.999),
eps: float = 1e-8,
clip_lambda: Optional[Callable[[int], float]] = lambda step: step**0.25,
weight_decay: float = 0.0,
decouple: bool = True,
rectified: bool = False,
do_bias_correction1: bool = False,
do_bias_correction2: bool = False ,
):
if not 0.0 <= lr:
raise ValueError(f"Invalid learning rate: {lr}")
if not 0.0 <= eps:
raise ValueError(f"Invalid epsilon value: {eps}")
if not 0.0 <= betas[0] < 1.0:
raise ValueError(f"Invalid beta parameter at index 0: {betas[0]}")
if not 0.0 <= betas[1] < 1.0:
raise ValueError(f"Invalid beta parameter at index 1: {betas[1]}")
if not 0.0 <= weight_decay:
raise ValueError(f"Invalid weight_decay value: {weight_decay}")
self.clip_lambda = clip_lambda
defaults = dict(
lr=lr,
betas=betas,
eps=eps,
weight_decay=weight_decay,
decouple=decouple,
rectified=rectified,
do_bias_correction1=do_bias_correction1,
do_bias_correction2=do_bias_correction2,
)
super().__init__(params, defaults)
def step(self, closure=None):
loss = None
if closure is not None:
with torch.enable_grad():
loss = closure()
for group in self.param_groups:
if "step" not in group:
group["step"] = 0
lr = group["lr"]
beta1, beta2 = group["betas"]
weight_decay = group["weight_decay"]
eps = group["eps"]
decouple = group["decouple"]
rectified = group["rectified"]
step = group["step"]
bias_correction1 = 1 - beta1**step if group['do_bias_correction1'] else 1.0
exp_avg_sq_update_rate = 1 - beta2
if group['do_bias_correction2']:
bias_correction2 = 1 - beta2**step
else:
bias_correction2 = 1
if step == 0:
exp_avg_sq_update_rate = 1.0
if step != 0 and rectified:
# maximum length of the approximated SMA
rho_inf = 2 / (1 - beta2) - 1
# compute the length of the approximated SMA
rho_t = rho_inf - 2 * step * (beta2**step) / (1 - beta2**step)
if rho_t > 4.0:
rect = ((rho_t - 4) * (rho_t - 2) * rho_inf / ((rho_inf - 4) * (rho_inf - 2) * rho_t)) ** 0.5
else:
rect = 0.0
else:
rect = 1.0
for p in group["params"]:
if p.grad is None:
continue
grad = p.grad
if p.grad.is_sparse:
raise RuntimeError("ADOPT_RS does not support sparse gradients")
state = self.state[p]
if len(state) == 0:
state['exp_avg'] = torch.zeros_like(p)
state['exp_avg_sq'] = torch.zeros_like(p)
exp_avg = state["exp_avg"]
exp_avg_sq = state["exp_avg_sq"]
if weight_decay != 0 and not decouple:
grad = grad.add(param, alpha=weight_decay)
if step != 0:
if weight_decay != 0 and decouple:
param.add_(param, alpha=-lr*rect*weight_decay)
denom = exp_avg_sq.sqrt().add_(eps)
normed_grad = grad.div(denom).mul_(rect * bias_correction2**0.5)
if self.clip_lambda is not None:
clip = self.clip_lambda(step)
normed_grad.clamp_(-clip, clip)
exp_avg.lerp_(normed_grad, 1 - beta1)
p.add_(exp_avg, alpha=-lr/bias_correction1)
exp_avg_sq.mul_(beta2).addcmul_(grad, grad, value=exp_avg_sq_update_rate)
group["step"] += 1