勉強会で資料を作ったのでせっかくなので公開してみます
本書にないことも書いており、純粋なまとめとは異なります。特に自分が加筆した章は「(haruyama480)」をつけました
まえがき
8章で述べたように現実のシステムはフォールトが起き得る
- パケットはロストし、順序は狂い、複製され、遅延が生じる
- クロックは正確ではない
- ノードは一時停止したりクラッシュする
耐障害性(fault-torelance)を持つシステムは、有益な保証を持つ汎用的な抽象概念を持ち、それが実現される
この章は、その概念に触れながら合意を説明していく
- 一貫性
- 順序
- 合意
9.1 一貫性の保証
DBが提供する一貫性(consistency)にはいくつか種類がある。9章では以下が紹介される
- 結果整合性(eventual consistency) 9.1
- 線形化可能性(linearizability) 9.2
- 因果律との一貫性(causal consistency) 9.3.1
- 逐次一貫性(sequential consistency) 9.3.3.2
結果整合性とは
- 2つのノードへの更新には必然的にラグが生じるため、レプリケーションを行うDBはラグが避けられない
- このようなレプリケーションを行うDBは少なくとも結果整合性(enventual consistency)という弱めの保証が提供される
- この保証は、書き込みが止めば"いつか"すべてのリクエストに対して同じ値が返されることを保証する
- 言い換えると非一貫性は一時的なもので最終的には解消される
- どちらかというと収束性の方が適切な名前かもしれない
結果整合性は弱い整合性である
- いつ収束するのか、収束するまで何の値になるのか、何の値に収束するのかわからない
- これはシングルスレッドのプログラムにおける変数の振る舞いとあまりに異なるため、アプリケーション開発者にとって扱いにくい
- 例. aの初期値が0で, write(a,1)と操作してもその直後の read(a) の結果が 1になることが保証されない
- 再現性の低くテストで発見しにくくバグを産む
トランザクションの分離レベルと一貫性の違い
- トランザクション分離レベル: トランザクションのレース条件を避けること
- 一貫性: 遅延やフォールトに対してレプリカの状態を調整(coordinate?)すること
しかし、これらは関連しあっている。9章ではこれらを紹介していく
- 強い一貫性モデルである線形化可能性
- 一貫性モデルの基本要素である順序の概念
- 線形化可能性 ↔ 合意などの関係
9.2 線形化可能性
本書ではいろいろな表現で紹介されている
- レプリカが一つしかないようにふるまうこと
- 最新性の保証
- すべての操作はシーケンスで表現され、状態はそのシーケンスに沿った処理で説明できる
本書の説明は少し冗長に見えるので、厳密な定義を紹介する。関数をread/writeと読みかえるとわかりやすい
wikiより
線形化可能性のこの定義は、次のものと同等である。
- すべての関数の呼び出しは、その呼び出しと応答の間のある瞬間に線形化点(線形化ポイント)を持つ。
- すべての関数はその線形化点(線形化ポイント)で瞬時に発生しているように見え、逐次定義で指定された通りに動作する。
(ここにはかかれていないが、呼び出しと応答のタイミングは絶対時間の存在を前提にしている)
改めて図9-4(p.358)を見るとイメージがつく。グレーの縦線が線形化ポイント
(本を持ってない人は、https://accelazh.github.io/storage/Linearizability-Vs-Serializability-And-Distributed-Transactions の1つ目の図を見る)
線形化可能性でない例
- wとした後にその結果が直後のrで反映されない
- 線形化ポイントの逐次実行として矛盾する
- もうちょっと複雑な例
- 初期状態0のa,b,a',b'に対して、AliceとBobが並列にread/writeを行う
- Alice: write(a,1)→write(b,1)
- Bob: write(a',a)→write(b',b)
- このとき、任意のタイミングでread(a')=1,read(b')=0を観測するか?
- 答え: 線形化可能性を持つなら観測できない
- 線形化可能ポイントをどこに置いても線形化可能モデルではその観測を説明できない
- 観測するには write(a,1)の結果がa'にwriteされず、write(b,1)の結果がb'にwriteされる必要があるが、これは線形化可能性と矛盾する
- 初期状態0のa,b,a',b'に対して、AliceとBobが並列にread/writeを行う
要点
- 線形化可能性は、絶対時間を前提にしており、操作(read/write)の開始と終了時間が与えられる
- 操作の開始と終了の条件(X)が与えられたときの、そのrの結果は、Xで制約された線形化ポイントによってその振る舞いを説明できる
- (本書では明示されてないが、これを理解していると逐次一貫性との違いが理解できる)
コラム: 線形化可能性と逐次一貫性の違い (haruyama480)
逐次一貫性
- 操作の開始と終了は与えられないが、順序だけが与えられることを前提とする
- 読み取りは、書き込み操作が逐次的に実行したように観測できる
- しかし、読み取りの最新性は保証されない
- つまり、「線形化可能性でない例」の2つ目の例を満たせるが、1つ目の例を満たせない
メモ
- データベースでなくても、ハードウェア上でも同様に一貫性の話が出てくる
- プログラムが操作する変数が複数のCPUのキャッシュラインにまたがっている場合がそうだ。
- コンパイラはキャッシュ間で一貫性が崩れないようにCPU命令列を生成できる。
- 実際には、適切にメモリモデルを設計し、メモリバリアの命令を使うことで一貫性は保たれる
- 例えば、GoはDRF-SCというメモリモデルを持ち、コンパイラはこれを遵守した命令列を吐く。https://go.dev/ref/mem
- メモリモデルでは、実際の実行時間は頼りにならず、実行順のみが頼りになるので、線形化可能性ではなく逐次一貫性という概念が使われる。
参考
- 線形化可能性と逐次一貫性の違い
- https://cse.buffalo.edu/~stevko/courses/cse486/spring13/lectures/26-consistency2.pdf
- 線形化可能性は、時間を気にしている。ある操作(r/w/rw)の実行期間はあるスパンで表現され、そのスパンの順序で線形化ポイントが制約される
- 逐次一貫性は、プログラムの実行順序を気にしている。ある操作のシークエンスが複数与えられた時の状態の遷移を保証する
- (また逐次一貫性は複数オブジェクトを前提にできるらしい)
- しかし、上のpdfではsingle copyを対象にしていそうなので解釈のブレが存在しているかも
-
複数のオブジェクトがそれぞれSequential Consistencyをサポートしてもそれらを同時に利用するオブジェクトはSequential Consistencyを満たさない。(略)
-
とあるCPUのキャッシュ実装は単一のキャッシュラインについてはこのSequential Consistencyをサポートしているが、複数のキャッシュラインに跨ってしまうとSequential Consistencyを満たせなくなる。一般にCPUのキャッシュはSequential Consistencyすら満たしていない。
- https://qiita.com/kumagi/items/3867862c6be65328f89c#sequential-consistency
コラム: 線形化可能性と直列化可能性
直列化可能性は、トランザクションの分離性
- 複数オブジェクトを操作する1トランザクション同士が干渉しないことを保証する
- トランザクションの実行順序を保証しない
線形化可能性は、一貫性モデル
- 個々のオブジェクトに関する読み書きの最新性を保証する
- 例. write(a,1)の直後はread(a)=1となる
- 操作をトランザクションにまとめるものではないため、read→writeみたいな操作の原子性を保証しない
- トランザクションがないため書き込みスキューが生じる
- 例. AliceとBobが同時に a=read(x)→write(x,a+1)を行うと、aが1しかインクリメントされないことがある
組み合わせを考える
- どちらも満たす: strict serializabilityまたはstrong one-copy serializability(string-1SR) と呼ばれる
- 前者のみ満たす: SSI (p.282)
- 後者のみ満たす: 書き込みスキューが起こるケース
9.2.2 線形化可能性が役に立つケース
- ロックとリーダー選出
- 制約及びユニーク性の保証
- ロックに線形化可能性が不可欠
- アトミックな操作(compare-and-set)に線形化可能性が保証されることで競合が避けられる
- クロスチャネルタイイミング依存関係
- write側がA→Bの順で実施したら、read側もA→Bの順で更新が読み取れるよね、みたいな話
9.2.3 線形化可能なシステムの実装
シングルコピーで線形化可能性を実装しても耐障害性がない
線形化可能なレプリケーションは、どのように実現されるだろうかを考えてみよう
(◯: 実現できる, ☓:実現できない)
シングルリーダーレプリケーション ◯~△
- リーダーに同期されていたら潜在的に線形化可能だが、実際には設計上の理由で線形化可能でないこともある
- リーダーを読めば線形化可能だが、もしかしたらそのノードは自身リーダーと思い込んでいるだけかもしれない
合意アルゴリズム ◯
- 線形化可能なストレージを安全に実装できる
- ZooKeeperやetcdがその例
マルチリーダーレプリケーション ☓
- 線形化可能ではない
- 書き込みが複数ノード上で並行して処理され、非同期で他ノードへレプリケーションされるため、書き込みの衝突が生じる
リーダーレスレプリケーション △~☓
- 信頼性のないクロックに基づくLWWは、順序が一貫性を持つことを保証できないため、ほとんど線形化不可能
- 線形化可能性とクオラム
- クオラムにより読み書きは強い一貫性を持つが、ネットワークの遅延により最新性を保証できない
- 厳密にはクオラムを線形化可能にできるがパフォーマンス劣化を起こすため、線形化可能性を提供しないと考える方が安全
要点
- 合意があれば線形化可能性を実現できる
9.2.4 線形化可能にすることによるコスト
線形化可能性と可用性のトレードオフ
シングルリーダーレプリケーションのネットワーク分断の例
- 複数DCにまたがったシングルリーダーレプリケーションを想定する (図9-7 p.367)
- DC間のネットワーク分断が起こると、フォロワー側のDCに接続するクライアントは書き込むことも、線形化可能な読み取りをすることもできない
- 復旧を待つしかない
実は線形化可能なDBは必然的にこの問題が起こることが説明できる。
一般的に、以下のトレードオフが知られている。
- アプリケーションに線形化可能性が必須な場合、一部のレプリカが他のレプリカから切り離されてしまったら、切り離されているレプリカはリクエストを処理できなくなる。それらのレプリカはネットワークの問題が解消されるのを待つか、エラーを返すしかない
- アプリケーションに線形化可能性が不要な場合、レプリカが切り離されていても独立してリクエストを処理できる(例.マルチリーダー)
CAP定理の紹介
- 上記のトレードオフを説明できる
- 2000年にEric BrewerがDBのトレードオフについての議論するために提唱した概念
- しかし、議論対象が狭い: 考慮しているのは1つの一貫性モデル(線形可能性)と1種類のフォールト(ネットワーク分断)のみ
- 今日では歴史的な関心として紹介される
コラム: 役に立たないCAP定理
- C(consistency), A(availability), P(partition tolerance)のうち、Pは絶対必要
- つまり、ネットワーク分断が起きた際に、CとAどちらを選ぶかの話でしかない
- しかもAの定義が曖昧で誤用される
- 避けたほうがいい
- また後述するように、ハードウェアの議論でも意味をなさない
- Pを保証しなくて良いハードウェアでもパフォーマンスを理由にCを捨てることがある
線形化可能性とネットワーク遅延
ハードウェアは線形化可能性を犠牲にしてパフォーマンスをとるトレードオフがある。
例. 現代的なマルチコアCPU
- 複数のCPUコアは個別にメモリキャッシュとストアバッファを持っている
- 次のような時間遅延がある: コアAの書き込み→コアAのキャッシュ→メインメモリ→コアBから観測できるようになる
- 書き込まれた値を読むためには、コンパイラがメモリバリアの命令を使って協調的に読み込めるようなバイナリを生成する必要があります。
これは線形化可能性を捨てた分散DBについても当てはまる。
線形化可能性とパフォーマンスをいいとこ取りすることはできない
- 線形化可能な読み書きリクエストに対するレスポンス速度とネットワーク遅延の不確実性のトレードオフが証明されている
- 上限のない遅延をもつネットワークでは、線形化可能性は大きなコストになる
9.3 順序の保証
一貫性の基本概念となる順序を理解する。
- 線形化可能性が持つ全順序(totally order)
- 因果律が持つ半順序(partially order)
順序と因果関係
線形化可能性なシステムは全順序を持つ
全順序とは
- 任意の2つの要素を必ず大小比較できる順序
- 例. 自然数。任意の数n,mは必ず大小もしくは等しいことを判定できる
線形化システムの操作(線形化ポイント)は、シーケンスなので自然数にマッピングできるため全順序を持つ
因果律は半順序を持つ
半順序とは
- 全順序と異なり、任意の2つの要素を必ずしも大小比較できるわけではない順序
- 例1. 集合
- {a}と{a,b}と{a,b,c}は包含関係で順序付け可能ですが、{a,b}と{a,c}は包含関係を持たないため順序付けできない
- 例2. 複数科目の成績
- (数学,美術)の成績を考える。(1,1)<(3,3)は成り立つが、(1,4)と(3,2)は順序が定義できない(しない)モデルが考えられる
- 後のランポートタイムスタンプはほぼこれ
因果律
- 2つの操作間に事前発生(happens-before)関係という順序関係を発生させる
- 一方、2つの操作が並行されていた場合この関係は発生しません
- つまり、因果律の操作は半順序関係を持つ
コラム: 半順序集合と全順序集合 (haruyama480)
本書では数学的な表現なかったが、全順序と半順序は集合論の概念です。そんなに難しくないので紹介してみます
半順序集合は、集合`X`と以下を満たす二項関係ρのペア(X,ρ)で定義される
- 反射律: すべての
xについてx ρ x - 推移律:
x ρ yかつy ρ zならばx ρ z - 反対称律:
x ρ yかつy ρ xならばx = y
半順序集合は必ずしも任意の要素にx ρ yかy ρ xが成り立たなくても良い。なりたつ場合は全順序集合と呼ぶ
例1. 自然数のペアによる半順序集合((N,N),<=)
- 数学と美術の成績の例と同じ
- 対象律, 推移律, 反対称律が成り立つ
-
(1,1) <= (3,3)は成り立つ -
(1,4) <= (3,2)と(3,2) <= (1,4)はどちらも成り立たない
例2. 自然数による全順序集合(N,<=)
- 対象律, 推移律, 反対称律が成り立つ
- 任意の要素
a,bは、a<=bかb<=aが成り立つ
半順序集合は任意の2要素は2項関係が成り立っても成り立たたなくても良いので、任意の全順序集合は半順序集合でもある。逆に言えば、半順序集合は全順序集合を含む
任意の要素a,bが異なることを前提にしてよいとき、=は省略して使われることがある
因果律の一貫性(causal consistency)よりも強い線形化可能性(linearizability)
- 半順序集合 ⊃ 全順序集合なので、線形化可能性も因果関係を持つ
- しかし、線形化可能性には「線形化可能性とパフォーマンス」で示したトレードオフがある
- 多くの場合本当に必要なのは線形化可能性ではなく因果律の一貫性なので、研究者はパフォーマンスと可用性と因果律を両立するデータベースの探求を行っている
因果律における依存関係のトレース
- 因果律を持った操作はレプリカ間で同じ半順序を保ったまま処理される必要がある
- この順序を判断するためには、ノードの各操作に対して依存関係を保持しなくてはならない
- p.197「5.4.4 並行書き込みの検出」に似た手法を用い、データベース全体で依存関係を追跡できる
- この追跡にはバージョンベクトルを利用できる
シーケンス番号の順序
- 因果律は理論上の重要な概念だが、実際に因果律のすべての依存関係を追跡するのは現実的ではない
- 実際はシーケンス番号やタイムスタンプをつかって順序付けできる
- タイムスタンプには実際の時刻ではなく操作ごとにインクリメントされる論理クロックで十分なことが多い
因果的でないシーケンス番号生成器
- 例. ノード1は奇数を、ノード2は偶数をシーケンス番号として生成していく
- ノードごとに行われる操作数が等しくないので、前後関係がズレていくため因果律の一貫性を失っていまう
ランポートタイムスタンプ
- https://en.wikipedia.org/wiki/Lamport_timestamp
- ノードは(counter, node ID)を保持する。node IDは固定。クライアントから操作を受け付ける度に観測した最大のcounter+1にcounterを更新する。
- クライアントは、観測した最大のcounterをノードに送る。
- 因果律を知るには半順序で十分だが、全順序まで提供してしまっている
ユーザー名がユニークであることを保証しなければならないシステムの例
- 2つのアカウントが同じユーザー名を取得しようとした場合、一見、全順序で勝者を選択できそう
- しかし、この全順序は全ノードでの取得操作を収集した後に決まるため、即座にリクエストが成功するかどうかを判定できない
実は全順序はいつ確定するかがわからなければ役に立たない
確定時期を知るには、全順序ブロードキャストが必要になる
9.3.3 全順序のブロードキャスト
全順序のブロードキャストは、以下の2つを保証する必要がある
- 信頼できる配信: メッセージはロストせず、受信したメッセージは他のノードに配信されなくてはならない
- 全順序づけされた配信: メッセージはすべてのノードに同じ順序で配信されなければならない
全順序のブロードキャストの利用
利用例
- ZooKeeprやetcdのような合意サービス
- 直列化可能なトランザクション
- フェンシングトークンを提供するロックサービス
特徴
- 全順序のブロードキャストにより、レプリカ同士は同じ順序で操作を実行することができるので一貫性を保てる(state machine replicationの原則)
- タイムスタンプ違って、メッセージが配信された時点で順序が確定する
- 追記しかできな(append-onlyな)ログを生成する方法とも捉えられる
全順序のブロードキャストを利用した線形化可能なストレージの実装
全順序のブロードキャストがあれば、線形化可能なストレージを実装できる。
例えば、アトミックなcompare-and-set操作(CASとも)を、ユニークなユーザー名の取得する操作を例に構築できる。
- 取得したいユーザー名をログに追記する
- ログを読み取り追記したメッセージが配信されるの待つ
- 取得したいユーザー名が他に要求されていないか確認する
- 自身が取得要求をした最初のユーザーであることを確認できたら要求したユーザー名をコミットする
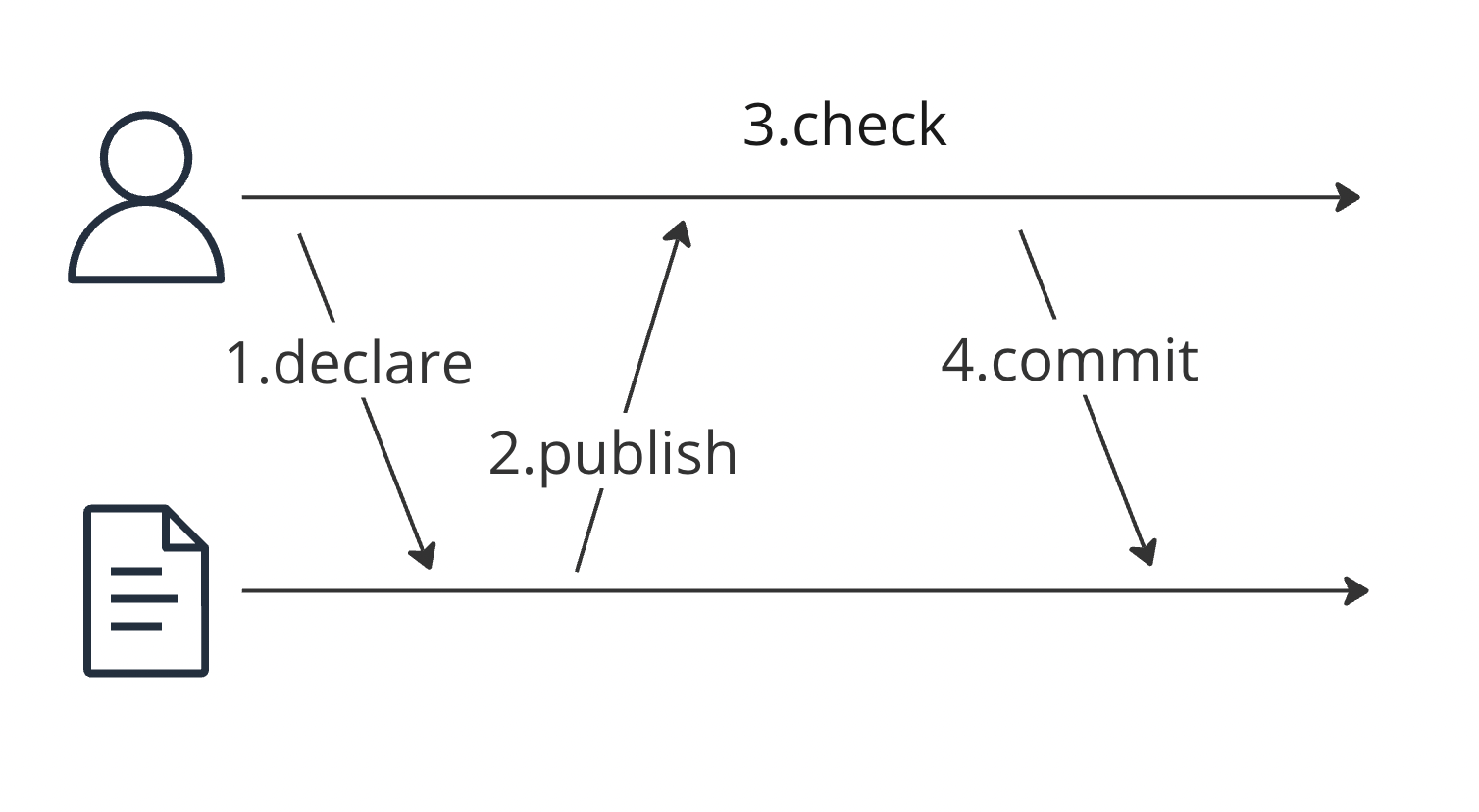
このままだと実はレプリカの最新性は保証できない。言い換えると線形化可能性より弱い、逐次一貫性(sequential consistency)までしか保証できない
線形化可能性を保証するには以下の選択肢がある
- 読み込みの宣言をログに追記し、実際にメッセージが配信されてはじめてログを読み込む
- 最新のログメッセージ位置を何らかの線形化可能なやりかたで取得し、それが配信されるのを待つ
- 確実に最新の書き込みが同期されるレプリカから読み取る

線形化可能なストレージの実装を使った全順序のブロードキャストの実装
整数レジスタからincrement-and-get操作を使って得たシーケンス番号をメッセージに添付しブロードキャストする
受信側は歯抜けが無いように順番に読む
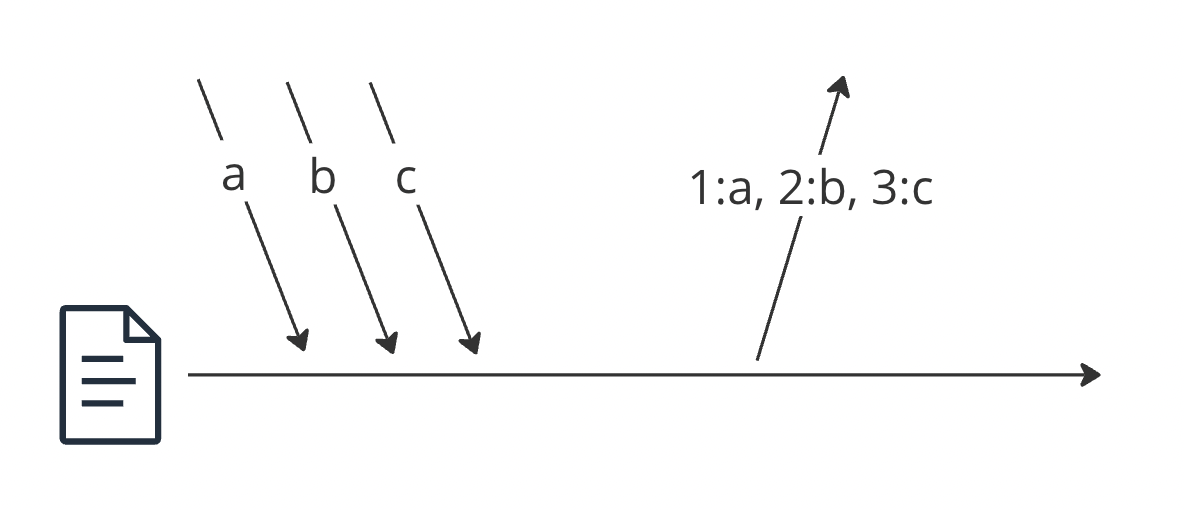
線形化可能なストレージと全順序のブロードキャストが等価な問題であることがわかった。
なんと、これまで議論した以下の問題は等価であることが実は証明できる。
- 線形化可能なcompare-and-set(あるいはincrement-and-get)レジスタ
- 全順序ブロードキャスト
- 合意
上2つが等価なのは直近の章による。合意→線形化可能性は9.2.3による。
9.4 分散トランザクションと合意
複数のノードを何かについて合意させることは、分散コンピューティングでは最も重要で基本的な問題の一つであるにもかかわらず、とてもつかみどころがなかった(subtle?)ために、今まで本書で取り上げてこなかった。レプリケーション、トランザクション、システムモデル、線形化可能性、全順序ブロードキャストを論じてきたので、ついに合意について取り組む。(エモい)
合意の用途
- リーダー選出(leader election)
- シングルリーダーレプリケーションのフォールト時に利用される機能
- スプリットブレイン状態を回避できる
- アトミックなコミット
- 複数ノードにまたがるトランザクションを全ノードで成功することを保証するために合意が必要
- 1ノードでも失敗すればそれはアトミックではない
まずアトミックコミットについて考える
コラム: FLP帰結
- ノードがクラッシュするリスクがあれば、合意に達するアルゴリズムが存在しないという証明
- しかし、前提とするモデルはクロックやタイムアウトを使うことができない、という強い制約を持つ
- 実際問題になることはない
9.4.1 アトミックなコミットと2相コミット(2PC)
2PCはアトミックコミットを実現する。
つまり、すべてのノードがコミットするかまたはコミットを中断するかのどちらかになることを保証できる
登場人物
- コーディネータ: トランザクションの発行者
- 参加者: DB。コミットする主体。複数
手順
- コーディネータが準備リクエストを送信
- 参加者はyesで返答
- いずれかがnoだった場合コーディネーターは全ノードに中断リクエスト
- コーディネータはコミットリクエストを送信
- 参加者はコミット
2つの帰還不可能点
- ① 2で参加者はyesを返した時点で間違いなくコミットできることを約束する。コーディネータが決断するまで待つしかない
- ② 3でコーディネータが決断すると覆せない
結婚式の誓いの例
- 神父がコーディネータ、新郎新婦が参加者とする
- コ「誓いますか」→参「yes」→コ「夫婦になったことを宣言」→参「認知」
2PCの課題
- 新郎新婦がyesと答えた直後に失神したら、復帰後にコーディネータから結果を聞くまで参加者は結果(コミットの有無)を知り得ない
- 新郎新婦がyesと答えたあとに神父が失神したら、新郎新婦は待つしかない(コーディネータの障害)
- 参加者がコーディネータのリカバリを待つしか無いことから2PCはブロッキングと表現される
スリーフェーズコミット
- ブロッキングな2PCに対して、ノンブロッキングな3PCが提唱された
- しかし、3PCはネットワーク遅延に上限があることを前提にしているため、現実のシステムの多くで原子性を保証できない
- そのため今でも2PCが使われ続けている
一般的にノンブロッキングなアトミックコミットには完璧な障害検出の仕組みが必要だが、遅延に上限がない実際のネットワークでは、クラッシュなのかネットワーク遅延なのか区別できず信頼できる仕組みを実現できない
9.4.2 分散トランザクションの実際
賛否両論
- o: 分散トランザクション上で重要な安全性を保証している
- x: パフォーマンスを損なう。提供できている以上の約束をしてしまっている
実際にパフォーマンスを理由に多くのクラウドサービスは分散トランザクションを実装しないという選択肢をとっている
しかし分散トランザクションからはいろいろな教訓が学べる
2種類の分散トランザクション
- データベース内部: トランザクションは同じデータベースソフトウェアで実行される
- ヘテロジニアス: 2つ以上の技術またはシステムをまたぐ
ヘテロジニアスは、システムをまたいでアトミックコミット(exactly-once)を実現する
- 例1. MQからメッセージをconsume → データベースでメッセージを処理、というトランザクション
- 片方が失敗したら、片方はロールバックできなくてはならない
- 例2. メール送信 → 何かしら
- 失敗してリトライされても、メール送信は2度送信されてはならない
XAトランザクション
- ヘテロジニアスな分散トランザクションを実現する2PCの標準
- 多くのRDBやMQでサポートされる
- トランザクションコーディネータに対するAPIでしかない
コーディネータの障害からのリカバリ方法
- 2PCの正しい実装は永久に保持しつづけること。つまり待つしか無い
- 管理者が手作業でトランザクションのコミットもしくはロールバックの判断を下す
- XAではヒューリスティックな判断(heuristic decisions)と呼ばれる操作が可能
分散トランザクションの限界
- コーディネータは単一障害点となりえる
- アプリケーションがコーディネータを含む場合、トランザクションのログが必要になるためアプリケーションはステートレスでなくなる
- XAは幅広いシステムに適合するため、機能が絞られる。デッドロックの検出やSSIなどのシステムと協調することができない
- 2PCはすべての参加者の回答が必要なため、1ノードのクラッシュでトランザクション全体が失敗する。水平スケールするほど分散トランザクションは障害を増幅してしまう
9.4.3 耐障害性を持つ合意
合意は複数ノード間で何かを同意する
- 1つ以上のノードが提案(propose)
- それらの提案の中から一つを決定(decide)
合意は以下の性質を満たす
- 一様同意: 2つ以上のノードが異なる決定をしない
- 整合性: 2回決定をしない
- 妥当性: vという決定に対してvという提案が存在する
- 終了性: クラッシュしていないノードは、最終的に何らかの値を決定する
各性質の解釈
- 上2つは合意の核となるルール
- 妥当性は、固定でnullを提案するモデルを弾くためのルール
- 終了性は、障害耐性の概念を形式化したもの
- シングルリーダーがクラッシュしても他のノードで合意しなくてはならない。独裁的なモデルは弾かれる
終了性が表すもの
- ノードが消えた後リカバリを待つと終了性が満たせなくなるので、ノードは戻ってこないことを前提とする
- クオラムが満たせなくなってしまうので、半数以上のクラッシュは前提としない
- しかし、ほとんどの合意の実装はノードに大多数の障害が起きても、一様同意,整合性,妥当性を欠くことはない
また、多くの合意アルゴリズムは、ビザンチン障害を前提としない
一応、ビザンチン障害を起こすノードが1/3未満であれば、ビザンチン障害耐性を持った合意を形成することは可能
合意アルゴリズムと全順序ブロードキャスト
耐障害性をもつ合意アルゴリズムには、Viestamped Replication(VSR), Paxos, Raft, Zabがある
合意なら全順序ブロードキャストが実現できる。上記の殆どで実装されている
- 合意の一様同意から、すべてのノードは同じメッセージを同じ順序で配信できる
- 整合性から、メッセージは複製されない
- 妥当性から、メッセージがでっちあげられることはない
- 終了性から、メッセージがロストすることはない
VSR, Raft, Zabは直接全順序ブロードキャストを実装している。一方Paxosの全順序ブロードキャストはMulti-Paxosにより実現される。
シングルリーダーレプリケーションと合意
- シングルリーダーレプリケーションは独裁的なリーダーの全順序ブロードキャストによって合意は形成可能
- しかし、独裁者がクラッシュして、リーダーの選出が必要になると他のノードで合意が必要になる
シングルリーダーレプリケーションは合意の先延ばしとして考えることができる
エポック番号とクオラム
エポック(epoch)番号
- Paxosでは投票(ballot), VSRではビュー(view), Raftでは期間(term)と呼ばれる
- 各エポックではリーダーが一意であることが保証される
- リーダーが落ちると、エポック番号がインクリメントされる
- エポックが異なるリーダーが衝突したら、大きいエポックが優先される
リーダーが何かを決定するとき毎度2回の投票が行われる
- リーダー選出
- 新しいリーダーが存在するかもしれないので、自身がリーダーだと思うノードは自身がリーダーだと提案し合意を得る
- リーダーの提案
- リーダーが決定したい何かを提案し合意を得る
- 新しいリーダーの存在がいないことがわかるまで現在のリーダーは確信を持って決定できる
この2つの投票は2PCに似ているが、耐障害性を持つという意味で異なる
- 2PC: コーディネータが単一障害点。すべての参加者がyesと答える必要がある
- 合意: コーディネータは合意により選出される。クオラムがyesと答えれば十分
合意の限界
合意は、全順序のブロードキャストを実現できるゆえ、耐障害性を持った線形化可能なアトミックな操作を実現できる
強力な保証を持つ、一方で以下のデメリットが知られている
- 同期レプリケーションのパフォーマンス
- 投票のプロセスは同期レプリケーションで行われるため遅い
- パフォーマンスを優先して非同期レプリケーションがしばしばDBに設定されるが、フェイルオーバーによってコミットされたデータが失われる可能性がある
- 合意に過半数のノードが必要
- 1ノードの障害に耐えるため3ノード、2つの障害に耐えるため5ノード必要になる
- ネットワークの分断耐性が低い
- 分断されても過半数は合意を進められるが、過半数未満のノードは何もできない
- 動的なメンバーシップについて理解が十分でない
- 障害ノードの検出はタイムアウトに依存しており、一時的なネットワークの問題で酷くパフォーマンスが低下することがある
9.4.4 メンバーシップと協調サービス
ZooKeeperやetcdは少量のデータについて耐障害性を持つ全順序ブロードキャストできるように作られている。
アプリケーションのデータを全部置くという使い方はしない。
ZooKeeperはGoogleのChubbyを参考に以下の機能が実装される
- 線形可能なアトミックな操作: 分散ロックが実現できる
- 操作の全順序: プロセスの一時停止による競合を防げるフェンシングトークンを提供できる
- 障害検知: ハートビートを定期的にチェックすることでエフェメラルノードの死活監視ができる
- 変更通知: 障害を通知したり、クライアントは通知をサブスクライブすることができる
リーダーの選出は、シングルリーダーDB以外にも用途がある
- ノードへの処理の割り当て
- ジョブスケジューラ
- ノードに対するパーティションの割り当て
- 数千ノードの投票を一部のノードが代表して行う(アウトソーシング的)
- サービスディスカバリ
- 特定サービスに対してIPを返すサービス
- DNSが線形化可能でないように、線形化可能でないリードオンリーレプリカが使われることがある
- メンバーシップサービス
- ノードの死活状態をノード間で同意できる
- 例えば、リーダーの選出をノードIDの若い順に行える
まとめ
- 線形化可能性は、わかりやすい強い一貫性を提供するが、ネットワークの遅延が大きいとパフォーマンスが悪い
- 因果律の一貫性は、弱い一貫性を提供するが、シーケンス番号で実装すると順序の確定時期を知るために合意が必要となった
- 合意はいろいろな問題と等価だった:
- 線形化可能なcompare-and-setレジスタ, アトミックなトランザクション, 全順序ブロードキャスト
- ロックとリース, メンバーシップ/協調サービス, ユニーク制約
- シングルリーダーレプリケーションでリーダーの障害が起きた場合は以下の対処法がある
- リーダーのリカバリを待つ
- 手動でフェイルオーバーを行う(ヒューリスティック)
- 合意によって新しいリーダーを選出する
- 合意アルゴリズム
- シングルリーダーレプリケーションは合意を先送りし頻度を低くしているだけとみなせる
- 独裁者により合意なしで線形化可能性(厳密には逐次一貫性?)を提供できるが、リーダーシップの変更時に結局耐障害性を持つ合意アルゴリズムが重要になる
- ZooKeeperは、合意,障害検出,メンバーシップのアウトソーシングサービスを提供できる
- とはいえ合意は必須ではなく、重線形化可能性がないことに対処し、分岐や合流を伴うデータをうまく扱うことが必要(LWW等?)
読んだ感想(haruyama480)
- 脱線しながらいろんな話題に触れられるので知的好奇心は満たされた
- 読みやすいように敢えて風呂敷を広げすぎないような印象があった
- 半順序と全順序, 逐次一貫性, 合意, k8s
- 一方で苦労した部分もあった
- 体系だった章立てではなくまとめずらかった
- 冗長な記述も多かった: 線形化可能性, ZooKeeper
- 最終的に内容もまとめる過程も勉強になった