1. 初めに
バックエンドとして開発したことから設計についてまとめてみました。
まだ設計から理解してコーディングできていないので復習も兼ねて一番大事だと感じたことから「達人に学ぶDB設計」を読みながら個人的な見解も踏まえてまとめました。
見解や間違いなどありましたら指摘していただけると幸いです。
2. 経験から語るDBを制すものがシステムを制す
- 20xx年にはPB(ペタバイト)が当たり前に処理させる世界で一番重要になります。
結論:データが先、プログラムは後で考える。
基礎概念
3-1.DOAとDOA
-
DOA(Data Oriented Approarch:データ中心)
プログラムより前にデータ設計から始めるという、近年の主流の考え方。 -
POA(Process Oriented Approach:プロセス中心)
「プロセス=プログラミング」で、プログラミングがデータ設計に先立つという考え方。
DOAにすることによって複数のプログラムで1つのDBを共有でき冗長性を排除できるため、仕様変更も比較的対応できるメリット。
実際DOAでなければ詰む...
3-2.設計工程とデータベース
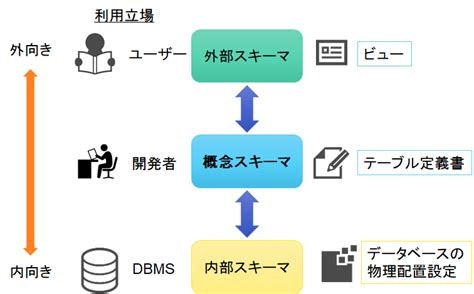
上記3種類のスキーマが、DB設計のステップに密接に関連する。
-
外部スキーマ
いわゆる「ユーザからDB」である
画面のUIや入力データなども外部スキーマに含まれる -
概念スキーマ:データ独立性の保障するため
「開発者から見たDB」
DBを保持するデータの要素および、データ同士の関係を記述するスキーマ -
内部スキーマ
概念スキーマで定義された論理データモデルを、具体的にどのようにデータベース管理システム内部に格納するかを定義するスキーマです。
自分が関わったシステムは小規模だったので概念スキーマをあえて作らずに、外部スキーマと内部スキーマだけ定義したが、大きいシステムで2層スキーマを定義してしまうと、スキーマ同士の独立性が低くなって誰にもわかるスキーマ処理ができないことが多々あるみたいです。
*近いうちに大規模の経験積みたい...
スキーマの独立性をデータ独立性と呼ぶ。
概念スキーマはデータ独立性を保障するためにあると認識しています。
4.論理設計と物理設計
データベース設計:論理設計と物理設計に分けられる
信頼性、性能、キャパシティなど要件を満たすように設計をする。
論理設計は物理設計に先立つ
・個人的に、サイジングは難しいと思いました。
・データベース管理システムはユーザに「ファイル」を極力意識させないようにしているが、設計者はファイルレベルで考えるのが物理設計のポイント
・RAID は信頼性、性能、財布を考慮する
・バックアップ、リカバリは超大切
4-1 概念スキーマと論理設計
システム開発におけるDB設計の手順
概念スキーマ
内部スキーマ
論理設計と物理設計が依存していないから、論理設計が物理設計より前に位置する。
論理設計のステップ
-
1.エンティティの抽出
どのようなデータが必要かを抜き出す必要性がある。(エンティティ=実体、物理的実体) -
2.エンティティの定義
データを属性という形で保持します。属性と列は同義である。
RDSではテーブルという形でエンティティを保持しますが、名表がどのような列を持つかを定義するのがこのフェーズになります。 -
3.正規化
正規化はテーブルを整理する作業
特に更新が整合的に行えるように、テーブルのフォーマットを整理します。 -
4.ER図の作成
経験上、正規化を行うテーブルが指数関数的に増加するので、繋がりをわかりやすいように図にしてしまうフェーズ。
4-2.内部スキーマと物理設計
物理設計のステップ
-
テーブル定義
概念スキーマを元にDB管理システム内部に格納するためのテーブル単位に変換していく作業。 -
インデックス定義
インデックス。辞書で検索するときのパフォーマンス -
ハードウェアのサイジング
キャパシティの見積もり。サーバーのメモリやCPUのサイジングを設定。
サイジングはキャパシティ、パフォーマンスの観点から行う。 -
ストレージの冗長構成
・RAID0:ストライピング、冗長構成ではない。
・RAID1:ミラーリング、同じデータを持つ。
・RAID5:パリティ、最低3台構成
・RAID10: RAID0 と RAID1のいいところ取り。最低4台構成になるのでコスト増。
*DBのDAIDは少なくとも5から行う。4だと余裕がないと実感。
-
ファイル物理配置決定
最近のRDBMSでは自動的にファイルの物理配置が決められるので意識しなくてもいいとは思うが一応メモです。- データファイル(I/O量:最大)
- インデックスファイル(I/O量:高)
- システムファイル(I/O量:低)
- 一時ファイル(I/O量:高)
- ログファイル(I/O量:中)
5. 論理設計と正規化
5-1.正規化とは?
正規形とは保持データの冗長性をなくし、一貫性と効率性を保持するためのデータ形式である。
- 冗長性:1つの情報が複数のテーブルに存在し、無駄なデータ領域・面倒な更新処理を発生させる。
- 非一貫性: 冗長なデータを持っていることにより、更新処理のタイムラグによってデータに不整合が生じる。
重要:エンジニアとしてデータの整合性とパフォーマンスのトレードオフだから経験しないと感覚的に習得できないと実感しました。
-
第1正規形
1つのセルには1つの値(スカラ値)しか含まないこと。配列などを含んではいけない。
第1正規形でないことによる問題は、- 主キーを決められないこと(主キーが各列の値を一意に特定できない)
- テーブルの意味やレコードの単位をすぐに理解できないこと
-
第2正規形
第二正規化は完全関数従属のみに整理すること。
完全関数従属とは、主キーを構成するすべての列に従属性がある。
第二正規化に関しても、完全関数従属にするためにテーブルの分割が必要になります。
なぜ第二正規化を行うのか。
主キーを構成する列のデータを登録しようとした時に、NULLのままでは登録をすることができません。そのため、第二正規化を行い、完全関数従属にする必要があるんですね。
異なるレベルのエンティティを、きちんとテーブルとして分離してやること。
正規化は無損失分解である。可逆性を持っているので、元に戻すことが可能。 -
第3正規形 ~推移的関数従属~
推移的関数従属を持っている可能性がある。
2段階の関数従属がある時には第三正規化を行う。
5-2.正規化の功罪(デメリット)
基本的に正規化はすべきだが、パフォーマンスの面でデメリットもある。
-
検索スピードの悪化
正規化によりテーブルを分割していくと、検索時にSQL分の中でJOINが必要になる。
結合はSQLの処理の中でも高コストなため、多用するとSQLの速度低下を引き起こす。
正規化とSQLの更新パフォーマンス
非正規化の場合、基本的には更新処理はすべてのレコードに対して行う為、かなりの数のレコードを更新しないといけません。しかし、正規化している場合には、完全関数従属以外のものはテーブルが切り出されているため、少ないレコード数の更新で済む事があります。更新パフォーマンスとしては正規化を行ったほうが、恩恵は受けられるでしょう。
正規化と非正規化結局どっちがいいの?
基本的には 正規化の次数が高ければ高い程良い、とされています。
非正規化はあくまでも最終手段として行うべき。
5-3.非正規化とパフォーマンス
正規化によるパフォーマンス問題は2パターン有ります。
サマリデータの冗長性排除と選択条件の冗長性排除です。
サマリデータを冗長に保持すると正規形に違反するが、検索を高速に出来る。
サマリデータとは、日々蓄積される詳細データに対して、一定の決まりで集計・圧縮されたデータのこと。
例えば売上情報であれば、個々の売上(トランザクション)を日別・週別・月別、商品別、担当者別・グループ別・支店別といった形に集計されたデータをいう。
テーブルに日毎の売上行を追加することで、日毎データを参照する際に、テーブルを結合することなく参照できるので、パフォーマンスを出せる。
選択条件を冗長に保持すると正規形に違反するが、検索を高速に出来る
データを参照する際に、必要な選択条件をテーブルに追加する事で、SQLのパフォーマンスを向上させる。
冗長に保持する事で、非正規化が行なわれてしまう。パフォーマンスとのトレードオフである。
5-4.冗長性とパフォーマンスのトレードオフ
非正規化のリスク
1. 更新のパフォーマンスをさげる
2. データのリアルタイム性
3. 後々の仕様変更での手戻りが大きい
更新のパフォーマンスをさげる
パフォーマンス向上の為に追加した、カラム分の更新が別途必要になる為。
データのリアルタイム性
追加されたカラムのデータを更新しなければならないとしたら、どのくらいの更新頻度で更新をかけるのか、というのも業務要件として設定しなければならない。
更新頻度が高ければ高いほどユーザーにとっては嬉しいが、システム的には負荷になる。
両者のバランスが取れる中間点を見極めなければならない。
後々の仕様変更での手戻りが大きい
後々データモデルを変更しようとすると、多くの工数がかかってしまう。
論理設計を行う人は、物理設計の知識も必要となってくる。
6.DBとパフォーマンス
6-1.DBのパフォーマンスを決める要因
インデックス(利点)
-
アプリケーション透過的
つまり、アプリケーションのコードに影響を与えない。非正規化がアプリに大きく改修が必要になるのに対し、インデックスの作成はDBのスコープ内で完結するため、簡単にパフォーマンスの改善を期待できる。 -
データ透過的
つまり、DBテーブルに格納されているデータの中身に影響を与えない。そのためインデックスの作成に合わせて論理設計の修正など不要。 -
性能改善効果が大きい
インデックスの性能はデータ量に対し線形より緩くしか劣化しない(持続性が高い)ため、多くの場合で性能改善効果を見込める。
統計情報
データベース管理システムはどの様な情報がほしいかを受けて、その情報を、多くの選択肢から選んで見つけだしてくれます。統計情報があることで、SQLの最適なアクセスパスを見つけ易くなるということです。
詳しくはこちらのQiitaが勉強になりました。
統計情報の設計指針
オプティマイザの適切な実行計画選定を助けることと、パフォーマンスの観点の両面から統計情報収集のタイミング検討が必要。
1. いつ収集するか?
-
データが大規模に更新された後
INSERT/UPDATE/DELETEによって大きく更新された場合、それまでの古い統計情報と最新のテーブルの状態に齟齬が生じる。そのためオプティマイザが最適ではない実行計画を選定する恐れがあるため、大規模な更新後はなるべく早く統計情報の収集するべき。 -
夜間帯(利用者が少ない時間帯)
統計情報の収集は、それなりんいリソースを消費し長時間かかる処理である。そのためテーブルの規模が大きい場合、日中のようなアクセスが多い時間帯に収集すると、本来の処理を阻害するリスクがある。
したがって、システムの利用者が少ない時間帯に収集することで、システム処理の妨げになることを避ける。
2. どこを収集するか?
データ更新が少ないテーブルに対して頻繁に統計情報収集をするのは、DBMSのパフォーマンスを劣化させるだけなのでよろしくない。
そのため、収集が必要なテーブル(更新処理が多いテーブル)の検討が必要。
一時テーブル
一時的なデータを保持するためのテーブルであり、トランザクションやセッション等のスパンで自動削除される。
メリット
- ビューと異なりアクセス時にSELECT文を実行せずリソース節約できる
- マテリアライズドビューと異なり自動削除されることからストレージの節約にもなる
デメリット
- 統計情報収集によるリスク
- I/O性能に優れるデータファイルを利用できない
※Oracle 一時表だと、
on commit delete rows の場合、手動で削除したわけではないのに
トランザクション終了がしたら、データが削除される。
on commit preserve rows の場合、手動で削除したわけではないのに、
セッションが終了したら、データが削除される。
7.アンチパターン
論理設計のやってはいけない6選
7-1.「非スカラ値」
1999年の標準規格では配列型が利用できました。
しかし、現在配列型をサポートするデータベース管理システムはほとんどありません。
基本的には配列型は使用せず、第一正規化を守るべきです。
7-2. 「ダブルミーニング」
同一の列が2つの意味を持つことを指します。
列は変数ではないので、一度決めたら変更は不可。
7-3. 「単一参照モデル」
同じ構造のテーブルを一つにまとめてしまうこと。
テーブルにはポリモーフィズムはいらない
7-4. 「テーブル分割」
水平分割
レコード単位でテーブルを分割すること。
レコードが増えるほどディスクI/Oが増大しパフォーマンスが劣化するため、テーブル単位のデータ量(レコード数)を減らす目的で水平分割をとる。
→欠点1
分割する意味的な理由がない
正規化の理論からは理由が出てこない。
→欠点2
拡張性に乏しい
→欠点3
代替手段がある
データベース管理システムのパーティション機能があるので代替できる。
垂直分割
列をテーブルを分割すること。
メリデメは水平分割とほぼ同じ。
垂直分割の代替案の集約
-
列の絞り込み(データマート)
頻繁にアクセスがあるデータのみを集めた小規模なテーブルをデータマート(マート)と呼びます。
マートを作成することで、パフォーマンスの向上に繋がります。
しかし、きをつけないといけないところはデータの同期です。
マートはテーブルの分割を行なっているわけではないので、作成元のテーブルとデータを同期させなければなりません。マートの更新はバッチ処理等で行います。
また、テーブルを増やすことになるので、ストレージの圧迫にも繋がります。 -
サマリテーブル
サマリテーブルは集約関数によってレコードを集約した状態で保持することです。
データを参照する時に計算とかしてる場合は時間がかかるから、あらかじめ計算してあるものを別にテーブルを作って入れておこう、ということです。
こちらも列の絞り込みと同じデメリットを持ちます。
7-5.「不適切なキー」
ここで言う「キー」は以下の2つを指します。
・主キー、外部キーなどDBの昨日で設定されるもの
・テーブルの結合条件に使用されるキー
ここで、使うべきではないデータ型は 可変長文字列(VARCHAR) です。
VARCHERは不変性を備えていない、固定長文字列との混同が使うべきでない2つの理由です。
可変長文字列は名前等に使われることが多いので、可変性があります。
可変性があるデータ型はキーには向いていません。
7-6. 「ダブルマスタ」
同じ役割を持つテーブルが2つ存在する。
ダブルマスタはSQLを複雑にし、パフォーマンスを悪化させる。
8.実務経験を得てわかったこと
SQLを考える時のコツ
テーブルを結合(JOIN)するような複雑なSELECT文を作る時、初心者は文の先頭であるSELECT句から考えがち。(私もそうでした。。)
しかし、SELECT句は列を抽出するものであり最後に決まる要素であるため、効率的ではない。
SQLの処理の順番に合わせて、下記の順番に考えるとスムーズ。
1. FROM句:テーブルの選択
2. WHERE句:選択テーブルからレコード絞り込み
3. GROUP BY句:グループ化
4. HAVING句:集計結果に対する絞り込み
マテリアライズドビュー
実データを保持するビュー機能でほぼテーブルのようなもの。
テーブルのスナップショット、つまりテーブルのある時点における断面を実装した機能ともいえる。
マテリアライズドビューへのアクセス時にSELECTは実行されずパフォーマンス面で通常のビューより有利。
また、マテリアライズドビュー内に主キーやインデックスの作成も可能。
データの制約はDB/コードのどちらで持つべきか?
DBに格納されるデータが満たすべき様々な条件(ビジネスロジック)に関して。
DBのCHECK制約等で実現すべきであって、アプリケーションコードでチェックすべきではないという考え方もあるが、現実問題では下記のような困難が発生する。
-
複雑なビジネスロジックを実装できない
「ある列のデータが100以下の数値である」のような単純な制約ならDBで実装できる。
一方、「テーブルAの列aはテーブルBの列bより小さい」といった実際に十分発生しそうなロジックでもDBでの実装は困難。
標準SQLの表明(Assertion)という機能により検討もできるが、DBMS製品のサポートが遅れており現実的ではない。 -
エラーハンドリングが難しい
DBで制約をかけ不正なデータがINSERTされた時に返却されるエラーメッセージはDBMS側で定義されており、柔軟性に欠ける。そのせいでユーザフレンドリーなエラーメッセージの実装が困難であり、サービスの満足度を下げるリスクがある。
結論:
主キー、外部キー、NOT NULL制約などRDSで基本的なルールはDB側で実装する。
それ以外の制約はアプリケーション側で実装する。