※この記事では、コードと一緒に長々と説明を書いています。「とにかく動く学習コードだけ知りたいんじゃ!!」という人はソースだけコピーするか、または別途(内容は一緒ですが)コードだけ全部まとめて載せただけの記事をしたためるか、githubで公開するかも知れません。 GitHubで公開していますのでクローンしてお使いください。
もしもミス・バグ等を見つけましたら、お手数ですがコメント欄にお願いいたします。
<主な編集履歴>
| No. | 編集日 | 編集内容 |
|---|---|---|
| 1. | 2022/09/01 | コードバグ修正、GitHubでの公開を追加。 |
| 2. | 2022/10/01 | 本編が始まるまでが長すぎたので、目次を追加。 |
| 3. | 2022/12/09 | 4. まとめ に、記事リンクを追加。 |
目次
0. はじめに、の前に
1. はじめに
2. 今回実装するテーマ
3. PyTorchでのCNN実装
4. まとめ
5. 参考
0. はじめに、の前に
毎日工場で「ご安全に!」と叫びまわっていた生産技術職からソフトウェア企業に異業界転職し、新卒キラキラ新入社員に紛れて受けていた新人研修も終わってOJTに入った、2021年 夏。
最初にアサインされたのは画像認識系AIの案件で、社内でも機械学習を扱っている人が2~3人くらいしかいない中で「今後のわが社のAIはポテンシャルありそうな君に任せた!」ということで(※筆者の脳内AIが補完しました)、ディープラーニングをゼロから勉強し始めました。
こんなとき、僕と同じく、まずはオライリーの『ゼロから作るDeep Learning Pythonで学ぶディープラーニングの理論と実装』を手に取る人も多いと思います。
そしてオライリーをどうにかこうにか読み終わり、なんだかディープラーニングについて自分もちょっとは理解できてきたかな~~なんて思っている頃に最初にぶち当たる壁は、
オライリー読み終わっても実装方法がよくわからんな?
ということです。
そう、とにかくよくわからんのです。
「あれ、重みとかバイアスとかって自分で全部書くの…?」とか、「誤差逆伝播の計算って全部自分で式組み立てるの…?」とか、赤ちゃんエンジニアの僕は困り果てました。
しかし、近年はオライリーに書いてあるような式を全て自前で書かずとも、もう少し直感的なコーディングで学習ができるようなライブラリも充実しているのです。(ただし何をやっているのか?を理解するにはオライリーはもはや必読といっても良いかも知れない)
そんなわけで、お仕事ではPyTorchを使って画像認識系の学習プログラムを組むことになりました。
あーこれで安心!もう余裕だね!ライブラリが充実してるんでしょ?
と思ったところで、赤ちゃんはまたすぐに壁にぶつかるのです。
PyTorchの使い方よくわからんな?
なにせ赤ちゃんですから、何をどう書けばどういう意味になって学習が進むのかが皆目分からないのです。
まぁ1ヶ月も奮闘すれば最低限レベルの計算は回せるようになるのですが、初心者の自分にとっては「記事を読んでも何をやっているかわからないところが新たに出てきてまた調べる」といった誰しもが通るウロウロ状態で、結構あれこれ調べては読み解いてを繰り返したので、それなりの労力が必要でした。
そこで今回は、「初心者だけどとにかくまずはPyTorchで畳み込みニューラルネットワークを組み立てて学習を回せるようになりたいんや!」という人向けに、PyTorchでの学習方法をまとめてみたいと思います。
1. はじめに
この記事は誰向けか?
本記事は、畳み込みニューラルネットワークの概念までは大体理解できたので、そろそろ自分もPyTorchで画像認識のディープラーニングを回してみたい!でも組み立て方が分からないからとりあえず動く書き方を教えて!という人向けです。
ただ、そのために必要なライブラリのインストール方法などは、記事の長さの都合上、今回は割愛します(使用するライブラリ等については「動作環境」で簡単に触れます)。
インストール方法については、他サイト様によい記事がたくさんありますので、そちらをご参照ください。
またベテランAIエンジニアの方でも、「君の記事に書いてあるこれはもっと簡単なメソッドでまとめて書けるよ!」とか「こういうやり方の方が汎用性あっていいよ!」等を優しく教えてくださる方がいらっしゃれば、ぜひコメントお待ちしております!
動作環境
私の動作環境は以下です。
| 項目 | バージョン |
|---|---|
| OS | Windows 10 |
| Python | 3.9.1 |
| Miniconda | 4.9.2 |
| PyTorch | 1.8.1 |
| torchvision | 0.2.2 |
| opencv | 4.5.1 |
| numpy | 1.23.1 |
| matplotlib | 3.4.3 |
開発環境ですが、私はMinicondaで環境を作り、その中でPyTorch、OpenCV、Numpy、matplotlibのインストールをしました。
2. 今回実装するテーマ
オライリーの『ゼロから作るDeep Learning~』では、MNISTのデータを利用して「数字画像を学習して、何の数字の画像かを当てる教師あり学習のAI」を実装しています。
ただ、本書ではMNISTデータのロードに専用のライブラリを使用しているようですが、実際には自前で作成したデータを使うことも多いと思いますので、本記事では、MNISTのデータをダウンロードして、「自分のPCにMNISTのjpgデータがあり、そのファイル名に答えラベルがついている」という状態を学習のスタートとし、このデータをPyTorchでロードしてネットワーク(モデルとも言います)や学習の実装を行い、数字画像を学習するAIを実装することを目指します。
完全にオリジナルの画像データ作成方法には触れませんが、今回使用するMNISTの画像データの作り方については、データ形状の章で全て説明します。
ということで、ここからは以下の順で説明していきます。
ここからの解説・実装の手順
<前提説明>
<実装>
最後に、実際に今回のコードで学習をしてみて、結果を確認したいと思います。
3. PyTorchでのCNN実装
ディレクトリ構成
今回作成するプログラムは、
- MNISTのデータをjpgファイルにして保存する
mnist_dataload_to_jpg.py - ネットワークを定義する
model.py - 学習全体を実装する
learning.py
の3つだけです。
下図に最終的なディレクトリ構成を示しましたが、カッコで囲っているものはpythonファイルを実行した結果出力されるものです。
├── mnist_dataload_to_jpg.py <- MNISTデータを「MNIST」フォルダに作成するpython
├── model.py <- ネットワーク定義python
├── learning.py <- 学習を行うpython
│
│
│ (mnist_dataload_to_jpg.pyの実行で生成)
│├── (MNIST)
│ ├── (trainImgs) <- 学習用データ
│ ├── (data00000_ans5.jpg)
│ ├── …
│ ├── (testImgs) <- テスト用データ
│ ├── (data00000_ans2.jpg)
│ ├── …
│
│
│ (学習・テスト時に自動生成)
├── (CNNLearningResult)
│ ├── (acc_cnn.png) <- 正解率グラフ
│ └── (loss_cnn.png) <- 損失関数値グラフ
├── (NG_photo)
│ ├── (0-pre-5-ans-8.jpg) <- 最終エポックのテストで不正解した画像
│ └── …
データ形状
学習・テストに使用する画像のデータについて説明します。
まずはデータのプロファイルについてです。
学習・テスト用データについて
画像例:
サイズ:高さ 28px * 幅 28px * 3チャンネル(RGB)(MNISTデータのまま)
ファイル名の例:data00000_ans5.jpg
ファイル名のルールについては以下の通り。
-
dataの後に続く5ケタ数字は、データ名が被らないようにするためだけのユニークナンバー(なので、2つ目のデータは00001、3つ目のデータは00002、…)。 -
ansの後に続く数字が、答え。
補足説明ですが、例えば学習用に作成した1つ目のデータが上のように数字の「5」の画像であったとき、「これの答えは5である」という情報を何らかの形で持っていないといけないので、今回はファイル名にこの情報を入れ込みました。
(正解ラベルの持ち方は、僕も識者からのご意見をいただきたいところです。)
次に、このようなデータを作成する方法を説明します。
今回のデータ作成コードは『MNISTデータをPNGで保存(Pytorch)』を参考にさせていただきました。
一部を変更しています。
# 参考サイト:https://circleken.net/2020/08/post19/
import os
from torchvision import datasets
def main():
"""
MNISTデータをjpgで保存するプログラム
"""
print("start")
# 保存先フォルダ設定
rootdir = "./MNIST"
traindir = os.path.join(rootdir, "trainImgs")
testdir = os.path.join(rootdir, "testImgs")
# MNIST データセット読み込み
train_dataset = datasets.MNIST(root=rootdir, train=True, download=True)
test_dataset = datasets.MNIST(root=rootdir, train=False, download=True)
# 画像保存 train
count = 0
for img, label in train_dataset:
os.makedirs(traindir, exist_ok=True)
img_name = "data" + str(count).zfill(5) + "_ans" + str(label) + ".jpg"
savepath = os.path.join(traindir, img_name)
img.save(savepath)
count += 1
print(savepath)
# 画像保存 test
count = 0
for img, label in test_dataset:
os.makedirs(testdir, exist_ok=True)
img_name = "data" + str(count).zfill(5) + "_ans" + str(label) + ".jpg"
savepath = os.path.join(testdir, img_name)
img.save(savepath)
count += 1
print(savepath)
print("finished")
if __name__ == "__main__":
main()
これを実行すれば、ディレクトリ構成の図のようにMNISTのデータが作成されると思います。
ただデータ数が多いので、とりあえず動かしてみたいだけの場合は適当に6000枚くらいデータを作ったら止めてしまって、5500枚を学習用、500枚をテスト用みたいな感じで振り分けてもいいでしょう。
さて、これ以降ではいよいよCNNによる学習を行うpythonコードを実装していきます。
メイン関数の実装
ここでは、必要なライブラリのインポートと、流れの全体観を示すために、メイン関数を定義していきます。
この後定義していくオリジナルの関数も混ざっていますが、全てこの先の章で説明していきます。
まずはコードを示し、その後で細かい説明をします。
import os
import argparse
import glob
import cv2
import torch
import torchvision
import torch.nn.functional as f
from torchvision.transforms import functional as TF
import matplotlib.pyplot as plt
from model import MyNet # このあと自分で定義するmodel.pyからのネットワーククラス
def Main(args):
# 計算環境が、CUDA(GPU)か、CPUか
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print('device: ' + device)
# 学習・テスト結果の保存用辞書
history_train = {
'train_loss': [], # 損失関数の値
'train_acc': [], # 正解率
}
history_test = {
'test_loss': [], # 損失関数の値
'test_acc': [], # 正解率
}
# ネットワークを構築( : torch.nn.Module は型アノテーション)
# 変数netに構築するMyNet()は「ネットワークの実装」で定義します
net : torch.nn.Module = MyNet()
net = net.to(device) # GPUあるいはCPUに合わせて再構成
# データローダー・データ数を取得
#(load_dataは「学習データ・テストデータのロードの実装(データローダー)」の章で定義します)
train_dir = args.trainDir # 学習用画像があるディレクトリパス
test_dir = args.testDir # テスト用画像があるディレクトリパス
train_loaders, train_data_size = load_data(args.trainDir)
test_loaders, test_data_size = load_data(args.testDir)
# オプティマイザを設定
optimizer = torch.optim.Adam(params=net.parameters(), lr=0.001)
# エポック数(学習回数)
epoch = args.epoch
# 学習・テストを実行
for e in range(epoch):
# 以下2つの関数は「学習の実装」「テストの実装」の章で定義します
cnn_train(net, device, train_loaders, train_data_size, optimizer, e, history_train)
cnn_test(net, device, test_loaders, test_data_size, e, epoch, history_test)
# 学習済みパラメータを保存
torch.save(net.state_dict(), 'params_cnn.pth')
# 結果を出力(「結果出力の実装」の章で定義します)
output_graph(epoch, history_train, history_test)
if __name__ == '__main__':
"""
学習を行うプログラム。
trainDir : 学習用画像があるディレクトリパス
testDir : テスト用画像があるディレクトリパス
epoch : エポック数
"""
# 起動引数設定
parser = argparse.ArgumentParser()
parser.add_argument("-tr", "--trainDir", type=str, default="./MNIST/trainImgs")
parser.add_argument("-ts", "--testDir", type=str, default="./MNIST/testImgs")
parser.add_argument("-ep", "--epoch", type=int, default=10)
args = parser.parse_args()
# メイン関数
Main(args)
まず起動引数設定についてです。
上述のディレクトリ構成に述べた通りになっていれば、おなじみpython learning.pyを叩けばそれで動作します。デフォルトのエポック数は適当に10としています。
ただ一応、学習データのディレクトリパス、テストデータのディレクトリパス、エポック数の3つについては、起動引数で指定すれば変更できるようにしておきました。
例えば、python learning.py -ts ./trainData -ep 5とすれば、学習データだけは同じ階層にある「trainData」フォルダ内にあり、エポックは5回でよい、としてプログラムが実行されます。
次に、Main()についてです。
まず、計算環境としてCUDAのGPUを使いたい人もいるかも知れませんし、今は特別な環境がなく普通のパソコンだからCPUだという人もいるでしょう。
学習において、ネットワーク・データ・パラメータの扱いがCUDAのGPUとCPUで異なるため、それに応じた構成にする必要があります。torch.cuda.is_available()は、CUDAのGPUが使える場合はTrue、使えない場合はFalseを返してくれますので、これで判断できます。
また、適宜必要なものに対し、.to('cuda')とすればCUDAのGPU、.to('cpu')とすれば通常のCPUで使用できる形に再構成してくれます(ちなみに.to()の処理をしなかった場合は、CPU前提として動作する)。
よって、torch.cuda.is_available()の結果によって変数deviceにcudaあるいはcpuの文字列を格納しておき、今後は適宜必要な場面で.to(device)を使用していきます。
ネットワークの構築は、後ほどネットワーククラスとして自分で定義するMyNetを使ってnet = MyNet()としており、学習における順伝播や損失関数、誤差逆伝播でこのnetが必要になります。
このネットワークはGPUかCPUかで構成を合わせる必要があるので、.to(device)を行っています。
次にデータのロードです。
データローダーというPyTorchの機能を使って、画像データと正解ラベルをセットします。
これも詳細は後述します。
オプティマイザの設定は、パラメータの更新を効率よく行うためにどの手法を使うか(オライリーでは第6章)を設定します。
今回は例として、オライリーp.175で紹介されている「Adam」を使っていますが、他の最適化手法を使う場合は必要な引数も変わってきますので、都度調べてみてください。
オプティマイザはパラメータ更新に関わるので、今回のパラメータを教えてあげる必要があります。パラメータは、先ほどネットワークを構築したnetからnet.parameters()によって取得できるので、これを引数paramsに渡します。
またlrは学習率です。1回の学習でどれだけパラメータを変化させるか?を決める値で、実際には色んな値にして結果を確かめてみる必要がありますが、今回は0.001としてみました。
学習・テストの実行では、エポック数(=学習データ全体を使った学習を「学習1回分」として、何回分学習を繰り返すか?を表す数)だけ学習とテストを繰り返します。
これも詳細後述です。
パラメータの保存をするには、net.state_dict()でパラメータを辞書化し、torch.save()で好きな名前を付けて保存すればOKです。「.pth」という拡張子のファイルにしてください。これが「学習済みパラメータ」とか「学習済みモデル」とか言うやつです。開発後の運用時に使用します(詳しくは 学習済みモデルを使って推論を行う方法 にて)
各エポックごとにパラメータを出力したければ、学習の毎エポック終了時のコード内にうまく入れ込んでみてください。
注意点として、「計算はGPUでやるけど、学習済みパラメータを使って実際に色々と推論させるマシンはCPUなんだよなぁ」みたいな人はnet.to('cpu').state_dict()としてパラメータ保存する必要がありますし、またそんな人が各エポックごとにパラメータを出力している場合は次エポックのために再びnet.to('cuda')と戻しておく必要がありますので、この辺りには気を付けてください。
最後に、結果を出力して終了です。
さて、これでおおまかな流れを説明したので、個々の実装に入っていきます。
ネットワークの実装
実務の中ではネットワーク形状の策定から悩むことになりますが、今回は、オライリーP.229~ 7-5章と同じCNNモデルを、「MyNet」と適当な名前を付けてPyTorchで実装してみたいと思います。
出力は、0~9の数字を分類したいためノード10個であり、たまたまですがこのインデックス番号がそのまま「AIが出した答えの数字」を表すことになります。
入力画像データのタテ・ヨコが28pxであること、また後述しますが今回はバッチサイズ128(128枚の画像をまとめて計算する、という意味)にしましたので、入力サイズはほぼ(128, 3, 28, 28)になること(最後のバッチだけはぴったり128個にならないので「ほぼ」)に注意して、以下のように実装します。
今回のネットワーク構成
conv2d - ReLU - Pooling - Affine - ReLU - Affine - Softmax
import torch
import torch.nn.functional as f
class MyNet(torch.nn.Module):
"""
CNNを用いた、オライリーP.229 7-5章と同じモデル。
バッチの画像群に対し、
入力(batch_size, 3, 28, 28) - conv2d - ReLU - Pooling - Affine - ReLU - Affine - Softmax
を計算する。
Returns:
float: 10個の要素に対する確率を格納した配列。
"""
def __init__(self, input_dim=(3, 28, 28)):
"""
ネットワークで使用する関数の定義。
"""
# モジュールの継承
super(MyNet, self).__init__()
filter_num = 30 # フィルター数
filter_size = 5 # フィルター(カーネル)サイズ
# conv2d定義
self.conv1 = torch.nn.Conv2d(in_channels=input_dim[0], out_channels=filter_num, kernel_size=filter_size)
# ReLU定義
self.relu = torch.nn.ReLU()
# Pooling定義
pooling_size = 2
self.pool = torch.nn.MaxPool2d(pooling_size, stride=pooling_size)
# Affine(全結合)レイヤ定義
fc1_size = (input_dim[1] - filter_size + 1) // pooling_size # self.pool終了時の縦横サイズ = 12
self.fc1 = torch.nn.Linear(filter_num * fc1_size * fc1_size, 100) # ノード100個に出力
self.fc2 = torch.nn.Linear(100, 10) # ノード10個に出力
def forward(self, x):
"""
順伝播の定義。
"""
# conv2d - ReLU - Poolingまで
x = self.conv1(x)
x = self.relu(x)
x = self.pool(x)
# 全結合層に入れるため、バッチ内の各画像データをそれぞれ一列にする
x = x.view(x.size()[0], -1)
# Affine - ReLU - Affine
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
# ソフトマックスにより、各ノードの確率を結果として返す
return f.softmax(x, dim=1) # dim=1はバッチ内の各画像データごとにsoftmaxをするため
いくつか補足します。
まずネットワーククラスの定義ですが、torch.nn.Moduleを継承してクラスを定義します。
def __init__()1行目のsuper().__init__()も、そのためのおまじないです。
(python2系の場合は、super(MyNet, self).__init__()のように今回のクラス名を引数に入れる必要があるそうです)
次にネットワークで使用する関数の定義についてです。
畳み込み層の定義のtorch.nn.Conv2dでは、
-
in_channelsに入力のチャンネル数(今回で言えば input_dim[0] = RGBの3) -
output_channelsにフィルター数すなわち出力のチャンネル数 -
kernel_sizeにフィルターの一辺のサイズ
を引数とすれば、畳み込みを計算してくれます。
この畳み込みに使用するフィルターがまさにパラメータであり、学習の際はPyTorchが誤差逆伝播によってジャカジャカと更新してくれます。
またAffine(全結合)層の定義では、第一引数に入力ノード数、第二引数に出力ノード数を書けばその通りに全結合してくれます。
ただし、畳み込み層から出てきた3次元データを横一列に変換して全結合層へ伝播させるには、そのノード数を求めておく必要があります。
そこで、まずpoolingまで終了した時のデータのタテヨコの長さをfc1_size(= 12)として求めました。チャンネル数は畳み込み層で定義した通りfilter_num = 30なので、奥行き x タテ x ヨコでfilter_num * fc1_size * fc1_size = 30 * 12 * 12となっているわけです。
次に、順伝播の定義です。
最初の入力を、形状 (バッチサイズ, 3, 28, 28)のxとして、上記で定義してきた各関数に順次入れます。
そうすると、各画像データそれぞれに対して並列で畳み込みを計算してくれます。
注意点は、既に触れましたが、Affine層に入れる前にバッチ内の画像1つ分の3次元データ(今回は形状(30, 12, 12)であることは既に述べた)を横一列の1次元データに変換する必要があることです。
バッチ並行処理は保ちたいので、「(バッチサイズ) * (pooling処理までした各画像データのノード数 = 30 * 12 * 12)」に変換することが目標になります。
そこで使うのがview()です。これは配列の形状を変換してくれる関数で、第二引数を-1とすると、入力データの形状を「(第一引数) * 〇」の形によしなに変換してくれます。
配列の形状はsize()で求めることができ、x.size()[0]がバッチサイズになるので、x = x.view(x.size()[0], -1) でAffine層に入力できるように変換しています。
それ以降も同様に、バッチサイズ個のデータを並行で全結合~ソフトマックスします。最終出力の形状は、
[0.1130, 0.1007, 0.1103, 0.1040, 0.0895, 0.0892, 0.1054, 0.1157, 0.0962, 0.0760]
のように0~9に対する確率10個セットがバッチサイズ個ある二次元配列になっているので(出力.size()をすると、(バッチサイズ, 10) と出てくるはずである)、引数でdim = 1と指定することで、バッチサイズ個ある確率10個セットそれぞれの中だけでソフトマックスを行います。
これでネットワーク定義は完了です。
学習データ・テストデータのロードの実装(データローダー)
学習を行うプログラムのコーディングに入っていきます。
まずは学習データ・テストデータをPyTorchでロードする方法についてです。
PyTorchでは、まず「データセット」に画像データ群とラベルのペアをセットします。
学習時には、バッチで並行処理したいので、データセットにある全データを「データローダー」でバッチサイズの箱に小分けします。
学習・テストの際にこのデータローダーをfor文で回せば、画像データとその正解ラベルが一緒に飛び出してくる、といったイメージです。
ですので、ここではこのデータローダーに画像データと正解ラベルをバッチにしてセットする作業を行います。
また必須ではありませんが、学習・テストの際に進捗を出力するために、データ数もついでに返しちゃいます。
# Main()で、画像データがあるディレクトリパスをdir_pathとして受け取る
def load_data(dir_path):
"""画像データを読み込み、データセットを作成する。
画像のファイル名は、末尾を「...ans〇.jpg」(〇に正解ラベルの数字を入れる)として用意すること。
Returns:
DataLoader: 画像データ配列と正解ラベル配列がバッチごとにペアになったイテレータ
data_size: データ数
"""
# 画像ファイル名を全て取得
img_paths = os.path.join(dir_path, "*.jpg")
img_path_list = glob.glob(img_paths)
# 画像データ・正解ラベル格納用配列
data = []
labels = []
# 各画像データ・正解ラベルを格納する
for img_path in img_path_list:
# 画像読み込み・(3, height, width)に転置・正規化
img = TF.to_tensor(cv2.imread(img_path))
# 画像をdataにセット
data.append(img.detach().numpy()) # 配列にappendするため、一度ndarray型へ
# 正解ラベルをlabelsにセット
begin = img_path.find('ans') + len('ans')
tail = img_path.find('.jpg')
ans = int(img_path[begin:tail])
labels.append(ans)
# PyTorchで扱うため、tensor型にする
data = torch.tensor(data)
labels = torch.tensor(labels)
# 画像データ・正解ラベルのペアをデータにセットする
dataset = torch.utils.data.TensorDataset(data, labels)
# セットしたデータをバッチサイズごとの配列に入れる。
loader = torch.utils.data.DataLoader(dataset, batch_size=128, shuffle=True)
# データ数を取得
data_size = len(img_path_list)
return loader, data_size
まずは画像データの格納です。
各画像のデータをopencvのimread()で読み取りますが、このままだとサイズが(28, 28, 3)になっています。CNNでは通常、RGB(opencvで読み取った場合はBGRの順ですが)をチャンネル数として考えるので、(3, 28, 28)の形状に直す必要があります。
また各ピクセル値は0~255ですが、これを正規化して0~1で扱いたいと思います。
この2つを一挙に処理してくれるメソッドとして、TF.to_tensor()をしています。
ところが、これによってPyTorchが扱う特別な型「Tensor型」に変換され、これをそのまま空のリストにappendしようとするとうまく動かないのです。
そこで、ちょっとアホらしいですがdetach().numpy()で一度numpyのndarray型に変換し、データの格納配列に追加しています。
正解ラベルはファイル名の「ans」と「.jpg」の間に挟まれているので、これをうまく取得して正解ラベルの格納配列に追加しています。
全ての画像に対してこれらの処理が終わると、この後の学習の計算では先ほど出てきたPyTorchの特別な型「Tensor型」として配列を扱う必要があるため、torch.tensor()でデータとラベルをTensor型に変換しています。
さて、ここまでで画像とラベルが同じ順番で並んだ2つの配列ができたので、いよいよこれをPyTorchのデータとしてセットしてきます。
TensorDatasetによってデータセットが作られたdatasetの中身は、
[ [画像1, 正解ラベル1], [画像2, 正解ラベル2], ... ]
のように、データと正解ラベルがセットになったオブジェクトです。
DataLoaderによってデータローダーが作られたloaderの中身は、これをバッチサイズの画像データ配列、正解ラベル配列のセットにしたオブジェクトです。
バッチサイズは引数で渡せますが、今回はバッチサイズが128なので、loaderの各要素は、128個の画像データ配列と、128個の正解ラベル配列のセットであり、loaderをfor文でイテレートするとこの2つの配列が返ってきます。
また、引数でshuffle=Trueとすると、datasetの順番からシャッフルされた状態でloaderにデータがセットされます。このあたりの必要性はまだ私も知見が少ないのですが、データの順番も多少学習結果に影響があると思われるため、学習結果の平均値を見たい場合はTrueにして複数回実施、再現性が欲しい場合はFalseにするなどの使い分けが必要なのかも知れません。どなたか知見をお持ちの方はぜひご教授ください。
最後、ついでに全データ数も取得しておきます(進捗報告で使うだけ)。
これで学習・テストのデータのロードを実装完了しました。
学習の実装
ここまでで、学習に使用するデータをロードする関数が実装完了したので、いよいよ本題の学習を実装しましょう。
def cnn_train(net, device, loaders, data_size, optimizer, e, history):
"""CNNによる学習を実行する。
net.parameters()に各conv, fcのウェイト・バイアスが格納される。
"""
loss = None # 損失関数の結果
loss_sum = 0 # 損失関数の値(エポック合計)
train_correct_counter = 0 # 正解数カウント
# 学習開始(再開)
net.train(True) # 引数は省略可能
for i, (data, labels) in enumerate(loaders):
# GPUあるいはCPU用に再構成
data = data.to(device) # バッチサイズの画像データtensor
labels = labels.to(device) # バッチサイズの正解ラベルtensor
# 学習
optimizer.zero_grad() # 前回までの誤差逆伝播の勾配をリセット
output = net(data) # 推論を実施(順伝播による出力)
loss = f.nll_loss(output, labels) # 交差エントロピーによる損失計算(バッチ平均値)
loss_sum += loss.item() * data.size()[0] # バッチ合計値に直して加算
loss.backward() # 誤差逆伝播
optimizer.step() # パラメータ更新
train_pred = output.argmax(dim=1, keepdim=True) # 0 ~ 9のインデックス番号がそのまま推論結果
train_correct_counter += train_pred.eq(labels.view_as(train_pred)).sum().item() # 推論と答えを比較し、正解数を加算
# 進捗を出力(8バッチ分ごと)
if i % 8 == 0:
print('Training log: epoch_{} ({} / {}). Loss: {}'.format(e+1, (i+1)*loaders.batch_size, data_size, loss.item()))
# エポック全体の平均の損失関数、正解率を格納
ave_loss = loss_sum / data_size
ave_accuracy = train_correct_counter / data_size
history['train_loss'].append(ave_loss)
history['train_acc'].append(ave_accuracy)
print(f"Train Loss: {ave_loss} , Accuracy: {ave_accuracy}")
return
まず、学習を始める時にnet.train()としています。ネットワークには学習モード/推論モードの切り替えがあり、これによってドロップアウトなどの挙動が変わるようです。今回は学習なので、学習モードにしています。
画像データと正解ラベルはデータローダーにセットされているので、これをイテレートして、data(バッチサイズのデータtensor)およびlabels(バッチサイズの正解ラベルtensor)を受け取ります。
この際、データローダーをenumerateにしていますが、これは単に進捗報告を毎バッチ出力するのは多すぎるかなと思い、適当な回数に区切るためにインデックスを取得しているだけですので、この辺は好みです。
受け取ったdata、labelsは、GPUかCPUかで扱いが変わりますので、.to(device)によって計算環境に合わせた再構築を行っています。
さて、いよいよ学習のコードです。
オプティマイザは、以前に誤差逆伝播で勾配を計算している場合はそれを今回の勾配計算に加算する機能が備わっているようです。RNNなどではこの機能が有用らしいのですが、CNNでは基本的に今回きりの勾配計算だけでよいため、zero_grad()によって過去の勾配をリセットしています。
学習を回すための下準備が整ったところで、まずは推論を実施します。
output = net(data)では、データを今回定義したネットワークに入力して、その出力を受け取っています。たった1行なんですね。
このoutputは、形状(バッチサイズ, 分類数=10)の2次元tensorで、要素を1つ取り出してみると、
tensor([0.0226, 0.1732, 0.0030, 0.7078, 0.0234, 0.0044, 0.0145, 0.0267, 0.0070, 0.0174])
のように10個の確率(ソフトマックスの出力)が入っています。この例ではインデックス番号 3 が最も高い確率になっています。
これに対して、labelsは、形状(バッチサイズ)の1次元tensorです。同じ場所のlabelsの要素を見てみたとき、正解ラベルとしてtensor(3)(つまり正解は「3」の画像)が入っていれば、推論が正解したということになります。
そして、これに基づいて損失計算を行っているのが交差エントロピーloss = f.nll_loss(output, labels)です。
このlossを出力してみると、tensor(-0.1054, grad_fn=< NllLossBackward0>) となにやらただの数値が入ってるだけではなさそうですが、この交差エントロピーnll_loss()は単なる結果の数値だけではなく、この後の誤差逆伝播に必要な情報が含まれたもののようです。
またnll_loss()は、デフォルトではそのバッチの損失関数値の平均値を出してくれています。
また最後に1エポックでの平均値を出したいため、loss.item()でバッチごとの損失関数の平均値を取り出し、データ数をかけて合計値に戻して加算する処理も行っています。
その損失計算に基づいて誤差逆伝播をloss.backward()で行い、これとオプティマイザの設定によってパラメータ更新をoptimizer.step()で実施しています。
これで1バッチ分の学習は完了です。
ここからは、バッチごとの正解数、そして学習ごとの正解率を算出していきましょう。
まずargmax()は、配列の最大値を示すインデックス番号を返してくれます。今回、推論結果であるoutputはバッチサイズ個のソフトマックス出力を持っているので、引数にdim=1を与えることで、バッチの各要素(=1データ)ごとに、最大値のインデックス番号を出してくれます。
また引数keepdim=Trueでは、argmaxをした結果を、元の次元を保ったまま形状(バッチサイズ, 1)の2次元tensorで返します。デフォルトではFalseのため、指定しない場合は形状(バッチサイズ)の1次元tensorで返ってきます。
すなわち、train_predには、各データに対して出力されたソフトマックスの最大値を示すインデックス番号たちが並んだtensorが格納されることになります。これはまさに、正解ラベルと比較したい値そのものですね。
しかしこのままだと、出力と正解ラベルの次元が異なるので、labels.view_as(train_pred)でlabelsも形状(バッチサイズ, 1)の2次元tensorに整形しています。ここまでで、
train_pred = tensor( [ [5], [2], [3], ... ] )
labels = tensor( [ [5], [1], [3], ... ] )
のような形になっています。(0要素目は正解、1要素目は不正解、2要素目は正解、…)
これをeq()で処理することで、要素1つずつを比較し、一致すればTrue、不一致ならFalseが、tensor( [ [True], [False], [True], ... ] ) のように格納された形状(バッチサイズ, 1)の2次元tensorとして返ってきます。
これにsum()をすることで、Trueの数を数えた結果が、tensor型の数値 tensor(Trueの個数) として返ってきます。
これを通常の整数として取り出すためにitem()をかければ、今バッチの正解数を整数取り出すことができるので、バッチごとに加算しておきます。
これで、全バッチを学習し終えた(「1エポック学習した」とか「学習が1回まわった」とか言います)ときに全正解数と損失関数の合計値が求まっているので、それぞれデータサイズで割って今エポックの平均正解率・平均損失関数値として、表示および格納しておきます。
これで学習の実装が完了しました。
テストの実装
学習とは異なるデータを使って推論を行い、学習済みモデルが未知のデータに対してどれだけの精度があるかを確かめるのがテストです。「検証」とか言ったりもします。
内容は学習のコードと大部分が共通していますが、ちょっとした違いもあります。
まずはコードをどうぞ。
def cnn_test(net, device, loaders, data_size, e, epoch, history):
"""
学習したパラメータでテストを実施する。
"""
# 学習のストップ
net.eval() # または net.train(False)でもいい
loss_sum = 0 # 損失関数の値(数値のみ)
test_correct_counter = 0 # 正解数カウント
data_num = 0 # 最終エポックでの出力画像用ナンバー
with torch.no_grad():
for data, labels in loaders:
# GPUあるいはCPU用に再構成
data = data.to(device) # バッチサイズの画像データtensor
labels = labels.to(device) # バッチサイズの正解ラベルtensor
output = net(data) # 推論を実施(順伝播による出力)
loss_sum += f.nll_loss(output, labels, reduction='sum').item() # 損失計算 バッチ内の合計値を加算
test_pred = output.argmax(dim=1, keepdim=True) # 0 ~ 9のインデックス番号がそのまま推論結果
test_correct_counter += test_pred.eq(labels.view_as(test_pred)).sum().item() # 推論と答えを比較し、正解数を加算
# 最終エポックのみNG画像を出力
if e == epoch - 1:
last_epoch_NG_output(data, test_pred, labels, data_num)
data_num += loaders.batch_size
# テスト全体の平均の損失関数、正解率を格納
ave_loss = loss_sum / data_size
ave_accuracy = test_correct_counter / data_size
history['test_loss'].append(ave_loss)
history['test_acc'].append(ave_accuracy)
print(f'Test Loss: {ave_loss} , Accuracy: {ave_accuracy}\n')
return
def last_epoch_NG_output(data, test_pred, target, counter):
"""
不正解した画像を出力する。
ファイル名:「データ番号-pre-推論結果-ans-正解ラベル.jpg」
"""
# フォルダがなければ作る
dir_path = "./NG_photo_CNN"
os.makedirs(dir_path, exist_ok=True)
for i, img in enumerate(data):
pred_num = test_pred[i].item() # 推論結果
ans = target[i].item() # 正解ラベル
# 推論結果と正解ラベルを比較して不正解なら画像保存
if pred_num != ans:
# ファイル名設定
data_num = str(counter+i).zfill(5)
img_name = f"{data_num}-pre-{pred_num}-ans-{ans}.jpg"
fname = os.path.join(dir_path, img_name)
# 画像保存
torchvision.utils.save_image(img, fname)
return
まず、ネットワークをnet.eval()で推論モードに切り替えます。
次に、データローダーからジャカジャカとデータと正解ラベルをイテレートするのですが、その際にwith torch.no_grad():としています。
学習の実装の損失関数のところでも見たように、tensorには値以外のプロファイルも入っており、勾配の計算も備わっているようです。このtensorの勾配の計算を不可にして、メモリの消費を減らしているそうです。
データと正解ラベルのバッチは、やはりGPUかCPUかで扱いが変わりますので、.to(device)によって計算環境に合わせた再構築を行っています。
データのバッチをネットワークに入力して、推論を実施します。
次に損失関数を算出していますが、学習の際にはなかったreduction=sumという引数が加わっています。
これは、デフォルト(あるいはreduction=meanとしても同様)だと損失関数のバッチ平均値を返すのに対し、この引数があることで「バッチの損失関数の合計値」を返してくれます。
ただ、学習の際は、この損失関数の値がパラメータ更新に響いてしまうため、reduction=sumをしない方がよいと思います。
また今回は単なるテストのため、誤差逆伝播やパラメータ更新はありません。
バッチごとの正解数も学習時と同様にして求めます。
ここで、最終エポックだけは不正解した画像をファイル名「データ番号-pre-推論結果-ans-正解ラベル.jpg」で出力するようにしています。
これを確認することで、どんな画像をどう間違えたのかが手元で確認でき、てんでダメな結果なのか、人間でも間違えそうなものばかり不正解しているのかなどが何となく分かります。
最後に、テスト全体の正解率および損失関数の平均値を格納し、完了です。
結果出力の実装
学習・テストそれぞれの各エポック最終結果を、損失関数および正解率のグラフにして出力します。
matplotlib.pyplotの使い方は、必要あれば適宜調べてみてください。
def output_graph(epoch, history_train, history_test):
os.makedirs("./CNNLearningResult", exist_ok=True)
# 各エポックの損失関数グラフ
plt.figure()
plt.plot(range(1, epoch+1), history_train['train_loss'], label='train_loss', marker='.')
plt.plot(range(1, epoch+1), history_test['test_loss'], label='test_loss', marker='.')
plt.xlabel('epoch')
plt.legend() # 凡例
plt.savefig('./CNNLearningResult/loss_cnn.png')
# 各エポックの正解率グラフ
plt.figure()
plt.plot(range(1, epoch+1), history_train['train_acc'], label='train_acc', marker='.')
plt.plot(range(1, epoch+1), history_test['test_acc'], label='test_acc', marker='.')
plt.xlabel('epoch')
plt.legend() # 凡例
plt.savefig('./CNNLearningResult/acc_cnn.png')
return
さて!
これにて、学習に必要な全てのコードを実装完了しました!
お疲れさまでした~!!
学習済みモデルを使って推論を行う方法
ここからは、学習が完了したあとの話です。
実際に学習を回してみることで、学習済みモデルparams_cnn.pthが得られました。
さて、運用時(例えばこの学習済みモデルがシステムや商品の中に入って動くときなど)は、学習済みモデルを使って推論を行います。
これはどういうことか?の結論を先に書くと、
学習済みモデルを使った推論とは
テストの実装 で書いたテストを、学習済みモデルのパラメータで実施するだけ、ということ。
簡単に説明します。
通常の業務では開発時に学習を行い、運用時には開発で得られた学習済みモデルを使って推論のみを行います。
場合によっては、現場で推論を行いながら新しいデータが入ってくるたびに更に学習も続けて常にパラメータを更新するAIもありますが、今回は既に開発段階で学習を完了したパラメータをそのまま使うことを考えることにしましょう
これは言い換えると、「学習済みモデルをロードしてネットワークにセットし、テストを実行する」のと同じだということです。
テストの実装では、ネットワークnetが学習をしたあとそのままテストを行っていたので、netにエポック終了時のパラメータ情報が既に入っていて、これを使ってテストの推論を実行していたのです。
運用時は、少なくともプログラムを初めて起動するときはネットワークのパラメータは初期化されてしまっているので、最初に学習済みモデルをロードして、あとはテストでやったのと大体同じことをすればよいということです。
長々と説明しましたが!
要するに!
ここで出てくる新しい話は学習済みモデルのロード方法だけだということです。ヤッタネ!
ということで、学習済みモデルのロード方法を説明します。
既におなじみnet = MyNet().to(device)でGPU(CUDA)あるいはCPUに合わせたネットワークを生成したあと、
# パラメータを取得
params = torch.load("params_cnn.pth", map_location=torch.device(device))
# 設定
net.load_state_dict(params)
とすれば、params_cnn.pthに保存された学習済みモデルをnetにロードすることができます。
これだけ!おわり!
あとは、テストの実装でやったように、net.eval()で推論モードにしたのち、with torch.no_grad():で勾配計算をなしにしながら推論を実行すればOKです。
テストと違うのは、運用時はニーズに合わせて推論結果だけ出力したり確率も一緒に出したりと必要なものが変わると思いますので、ここからは適宜状況に合わせて実装していってください。
さて!
これでMNISTを使った画像データ・正解ラベルの作成から、学習の実行、また学習後に出力された学習済みモデルをロードして推論を行うプログラムの実装が完了しました!
実際に学習を実行してみた
最後に、せっかくなので今回のコードで実際に学習を実行してみます。
今回はちょっとデータ少なめに、学習用データ5500枚くらい、テストデータ500枚くらいで、10エポックで学習してみました。
その結果がこちらです。
| 各エポックの正解率 | 各エポックの損失関数 |
|---|---|
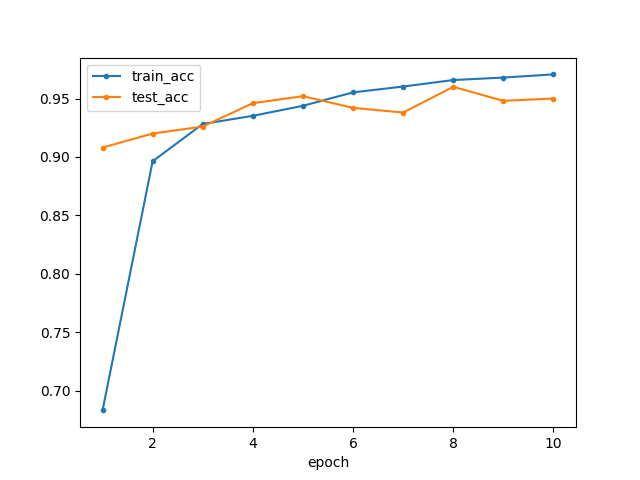 |
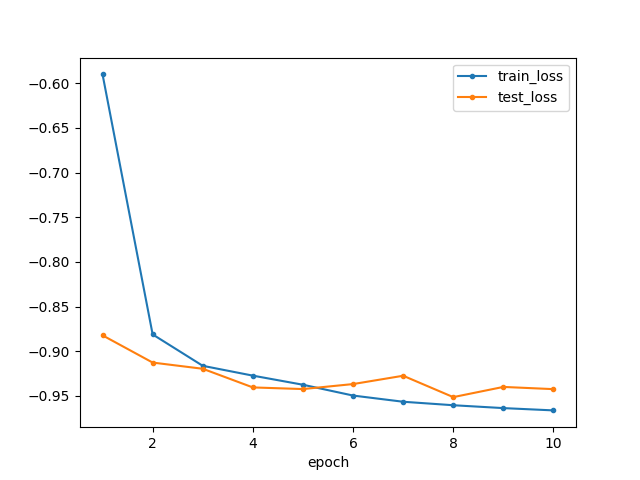 |
<凡例>
- train_acc:学習の正解率(エポック平均)
- test_acc :テストの正解率
- train_loss:学習の損失値(エポック平均)
- test_loss :テストの損失値
<観察・考察>
最終的には学習でもテストでも95%前後の精度になっています。割と少なめのデータ数&簡単なネットワークでもこのくらいの精度は出せてしまうようです。
おもしろい!
全体を通して精度の変化を見てみましょう。回を重ねるごとに、学習の結果は向上し続けています。一方でテストの結果には上下がありそうなものの、トレンドとしてはまだ向上傾向なのかもしれません。このくらいなら、明らかな過学習というほどではないような気がしますので、もう少しエポック数を増やして学習させてから判断してもよさそうです。
ところで学習初期は、テストよりも学習時の方が正解率・損失関数の結果が悪くなっています。これは、正解率も損失関数も、学習1エポック分の中でも前半と後半でモデル精度に差があって(学習しているので当然)、その平均を取っているのに対し、テストはその回の学習が終わったモデルを使って実行されているためです。
そういう意味では、学習の正解率や損失関数はエポック内最後のバッチの結果を代表値として見てもよいのかも知れませんが、データ数がバッチサイズ程度だとやや信頼性に欠けますし、GPUを使うともっとバッチサイズを小さくしないとメモリオーバーしてプログラムが回らないこともあり(Azureで、もっと大きい画像を使った学習を行ったときはバッチサイズ8で限界だったこともあります)、これを考えると余計に信頼性がない気がします。また、学習が進めば1エポック内での精度の差も縮まってくると思われるので、むしろ今回のようにエポック平均で見る方法で良いのかなと考えています。
このあたりは僕も、もっと有識者にご意見をいただきたいところです。
ここで、最終的に500枚のテストデータの中から不正解となった25枚を見てみましょう。
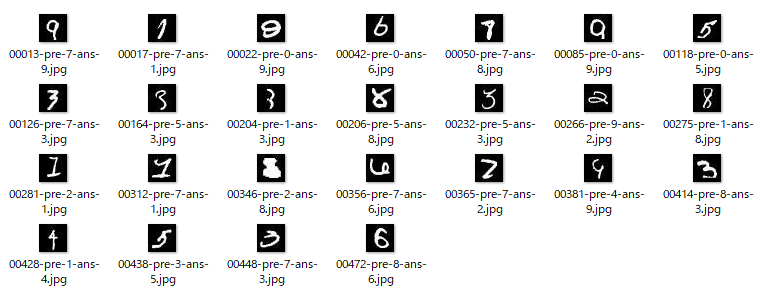
例えば一番左上の画像は、正解が9に対して7と推論しています。確かにこれはハッキリと9な画像ですが、7と形状は似ている数字でもあります。
また一番右上の画像は、正解が5に対して0と推論しています。確かに5ではありますが、全体的にひしゃげていて0の形に少し近い気もします。
こうして見ると、人間の目で見てもある程度は間違える気持ちもわかるような数字が多い印象です。
今回はデータ数をもっと増やせますし、またネットワーク形状もだいぶ簡素なので改善の余地はあります。
学習率はlr=0.001としていますが、これを変更したらまた結果が変わるでしょうし、最適化手法の種類によって収束する精度やそれに必要なエポック数が大きく異なるかも知れません。
損失関数も交差エントロピーを使用していますが、他にも損失関数の種類はあります。ネットワークの最後の活性化関数についても、今回はオライリーに沿ってsoftmaxですが、対数を取ったlog_softmaxなどの種類もあります。都度必要なものを選んだり試したりすることもあるでしょう。
こうした要素によって必要なエポック数や過学習の状況が変わるので、特に今回の条件からは更なる精度向上が目指せるはずです。(たぶん!)
4. まとめ
今回は、PyTorch初心者が畳み込みニューラルネットワークの学習を初めて回してみるためにひとまず必要だと思われる内容を説明しました。
model.pyネットワークの記述では、今回は各関数を全て並列的に書いてしまいましたが、nn.Sequentialを継承していくつかのまとまりに分けて記述する方法があり、その方がforward()の中がすっきりして見通しがよくなります。
またデータセットの作成時にも、1つのデータ群から学習データとテストデータをランダムで切り分けてくれる関数もあるなど、他にもまだまだ色んな設定なり機能なりがあると思いますので、お互い学んでいきましょう!
【追記】
続編的な記事として、画像認識で活躍しているVGG16の出力を変えて自分の行いたい分類問題に変更できるよう、転移学習・ファインチューニングするためのコーディング方法について書きましたので、よろしければご参照ください。
5. 参考
この辺りの記事を見ると、各コードが何をやっているかもう少し親切に解説してくれていそうです。
- わかりやすいPyTorch入門④(CNN:畳み込みニューラルネットワーク)
- 【PyTorch】サンプル⑧ 〜 複雑なモデルの構築方法 〜
- PyTorchの気になるところ(GW第1弾)
- PyTorchのtorch.no_grad()とは何か(超個人的メモ)
MNISTの画像保存は以下記事を参考にしました。
その他