この記事は PostgreSQL Advent Calendar 2018 に参加しています。
本稿のテーマ
PostgreSQL界隈では10月にリリースされたバージョン11の話題がホットですが、本稿では1年前のバージョン10から導入されたクォーラムコミットを取り上げます。
クォーラムコミットとは
クォーラムコミットは PostgreSQL で同期レプリケーションを構成するときの方式の一つです。同期レプリケーションでは、プライマリサーバで行われたトランザクションのコミットがスタンバイサーバに伝播することが保証されます。逆に言うとスタンバイサーバへの伝播が完了しない限り、プライマリ上の COMMIT の応答が返ってきません。このとき、スタンバイサーバの「全て」ではなくて「いずれか N台」に伝播したら OK とするという指定がクォーラムコミットです。例えばプライマリpostgresql.conf 以下のように指定すると、スタンバイ s1、s2、s3 のうちの2台に伝播が完了すれば同期したと見做されます。
synchronous_standby_names = 'ANY 2 (s1 s2 s3)'
これによって「プライマリの変更は確実に伝播させたい」「スタンバイ側の障害のためにプライマリがサービス停止する事態は避けたい」という2つの要求に対して、バランスの取れた構成を選択できるようになります。これをPostgreSQLのインメモリクラスタ構成に応用してみようというのが今回の試みです。
インメモリクラスタ構成
PostgreSQLの更新処理を高速化するのにデータベースクラスタ($PGDATA)をメモリ上に載せてしまうことが思いつきます。しかし、そうするとデータベースの永続性(ACIDのD、Durability)が失われてしまいます。何かコミットした書き込み内容を保証する代替が必要です。そこでクラスタ内の全ノードがダウンする可能性は十分低いと仮定して、レプリケーションでスタンバイノードに伝播したことをもって永続性を保証しようというのが、インメモリクラスタです。インメモリクラスタ構成のデータベース製品としては MySQL Cluster や VoltDB があります。
PostgreSQLはインメモリ用に設計されていませんが、似たようなことをやってみたらどうなるか試してみます。
とりあえず構築
Azureで適当に以下図のように作ってみます。インスタンスは全て Basic A2 (2 vCPU / 3.5GB memory) で SSD使用、標準付属のストレージのみとしました。

postgresql.conf 設定はこんな具合です。
max_connections = 200
listen_addresses = '*'
shared_buffers = 512MB
fsync = off
synchronous_commit = remote_apply
archive_mode = on
archive_command = 'cp %p /data/arclog/%f'
synchronous_standby_names = 'ANY 1 (*)'
ポイントは fsync=off だけど WALアーカイブはしっかりとるということです。インメモリですがバックアップだけはストレージにしっかり取る想定です。synchronous_commit は on でもよいのですが、Pgpool-II などでデータ遅延の無い参照負荷分散をさせる想定で remote_apply としました。また、クォーラムコミットは2台のスタンバイのうち1台に伝播すればOkという設定です。
ベンチマーク
まずは性能を確認しましょう。性能が出ないのなら、参照処理の振り分けやノードダウン時のフェイルオーバーを一生懸命作っても徒労に終わります。そもそもオンメモリ+クォーラムコミットの同期レプリケーションで更新トランザクション性能はどのくらいでるのでしょうか。
おなじみの pgbenchを使って「余裕をもってメモリに載るデータサイズ」で試験することにします。これでオンメモリ動作の性能が優れないなら、本構成は問題外と結論できます。以下の初期化で 150MB 程度のユーザデータが生成されます。システムデータを含めても 200MB以内です。
$ pgbench -i -s 10
クライアント側は以下コマンドを使います。-c 32 は -c N の N を増やして、後述の (b) の構成で TPS が頭打ちになるあたりを選んでいます。本当は複数の水準でやると良いのですが、ここでは手抜きです。
$ pgbench -c 32 -j 2 -h {pg1ホスト}
以下の条件でテストしてみます。参照負荷分散は無しで、単純にプライマリの pg1 サーバを対象とします。
- (a) クラスタ無し / fsync = on
- (b) クラスタ有り / fsync = on
- (c) クラスタ有り / fsync = off
- (d) クラスタ有り / fsync = off / WALがオンメモリ
- (e) クラスタ有り / fsync = off / WALとデータがオンメモリ
その結果が以下です。
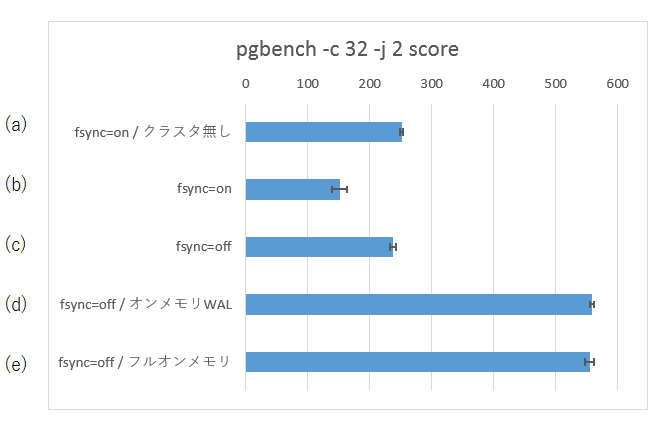
このときインスタンスの負荷情報を見ると、(a)(b) が CPU利用40%くらい、(c)が50%くらい、(d) と (e) が100%近くです。また、(a)(b)(c) はディスクI/Oが 200 MB/s に張り付いています。ただし、IOPSで見ると (c) は (a)(b) よりはハッキリと少ないです。
考察: (a) vs (b)
(b)は通常単体PostgreSQLの(a)と比べて同期レプリケーションのペナルティがあります。TPSは(a)の6割程度です。結構、削られますね。
考察: (a) vs (c)
クォーラム同期レプリケーションを組む代わりに fsync=off としたら、性能としてどうかという比較です。(a) と (c) は同程度の性能で、若干 (c) が負けています。性能負荷分散であるとか、マシンダウン時の可用性といったことを考慮すれば (c) を採用する価値もあるかな、という程度でしょうか。
カーネルのダーティバッファ書き出しについてチューニングすれば、(c)をもう少し良くできる可能性はありそうです。
考察: (c) vs (d) vs (e)
(c) に対して、WAL(pg_wal/)をメモリ(tmpfs)上に配置したのが (d)、さらに $PGDATA 全体をメモリに配置したのが (e) です。
WALをメモリ上に置く効果が絶大です。(c) あるいは (a) の2倍以上の性能が出ています。一方、(d) と (e) は大体同じTPSです。データ本体は共有バッファに載っていますので、データ本体への書き込みの性能影響は無いということでしょう。
ただし、3台使って、運用形態も変えて、それで 2.2倍ほどの性能というのはちょっと残念かもしれません。
考察: (b) vs (d)(e)
既に同期レプリケーションを使って参照負荷分散&高可用性クラスタを組むことが前提となっているなら、それをオンメモリ化することは、(b) と (d)(e) の比較です。これは4倍弱の性能が得られることになりますし、「クラスタ構成を組む」ということも追加コストではありませんので、お買い得です。
まとめ
さて、(d) (e) がそこそこ速かったわけですが、みなさんの感想はいかがでしょうか。「大胆なことをした割に大したこと無いな」と思った方も多いかもしれません。これは、
- 共有バッファに載る条件 + SSD で既にストレージ処理のボトルネックは小さくなっている
- PostgreSQLはインメモリクラスタ構成用に設計されているわけではないのでインメモリで使うには無駄な処理が沢山ある
といった解釈ができます。とはいえ、それでも 2倍~4倍の性能が得られるだけでも魅力的ですね。fsync=off で構成するのが常識という時代も来るかもしれません。
明日の PostgreSQL Advent Calendar 2018 は、ester41 さんです。
なお、補欠用の記事「pg_rlimit で PostgreSQL のセッションごとに ulimit設定をする」 も公開しています。
追記 2019-03-08
JPUG合宿 で、同様の構成で遊んだときの Ansibleスクリプトを公開します。こちらには Pgpool-IIによる振り分けも含まれています。