Plotlyでヒストグラム その2
この記事では plotly 2.3.0を利用しています。
はじめに
下記でヒストグラムについて述べたのですが、より実務に近い形で。
ここではkaggleのTitanicのデータを利用しています。
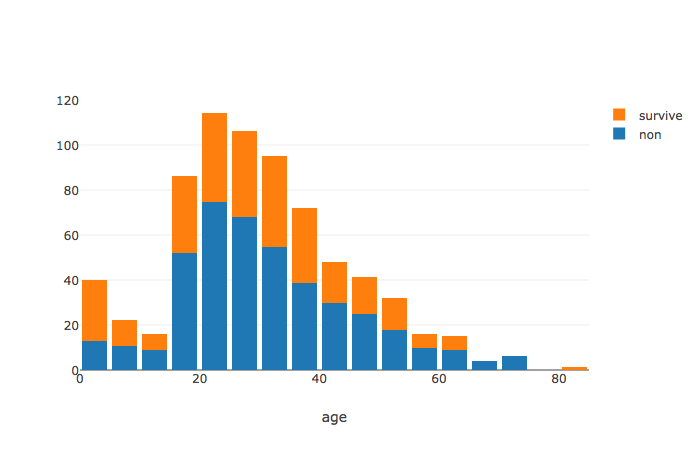
連続変数ごとに、カテゴリカルな変数の傾向を見る
ここでは5歳刻みの年齢(Age)ごとに、生死(Survived)の傾向を積み上げグラフで見ます。
# coding:utf-8
import pandas as pd
import numpy as np
import plotly.plotly as py
import plotly.graph_objs as go
import plotly.offline as offline
offline.init_notebook_mode()
# データ部分については省略。
# dfというデータフレームで、年齢を表す変数が Age(float), 生死を表す変数が Survived(object型で値は0,1)
x0 = df['Age'][df['Survived'] == '0'].values
x1 = df['Age'][df['Survived'] == '1'].values
trace0 = go.Histogram(x=x0,xbins=dict(start=0, size=5, end=np.max(df['Age']) + 5), name = 'non')
trace1 = go.Histogram(x=x1,xbins=dict(start=0, size=5, end=np.max(df['Age']) + 5), name = 'survive')
layout = go.Layout(bargap = 0.2, barmode = 'stack',xaxis = dict(title="Age"))
fig = go.Figure(data=[trace0, trace1], layout=layout)
offline.iplot(fig)
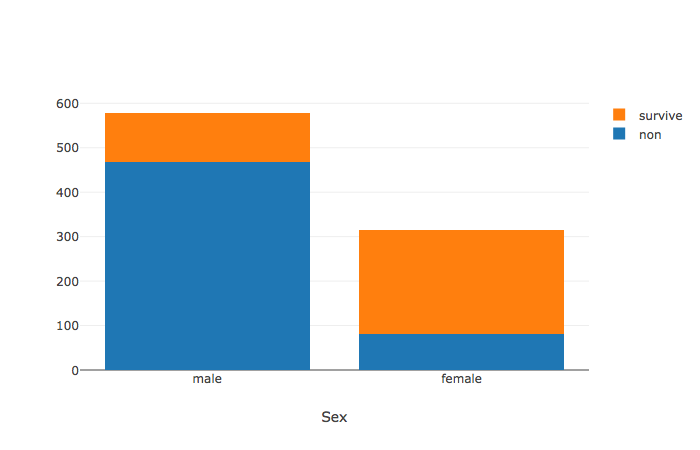
カテゴリカル x カテゴリカル
そうなるとカテゴリカルな変数ごとに、つまり普通のクロス表を可視化するにはどうしようということでやってみました。
基本的に上のものと変わりないのですが、もっといい書き方があるような気もしています・・・。
(もし誤っている部分などあれば、ご指摘いただけると助かります。)
# coding:utf-8
# 性別ごとに傾向を見る
x0 = df['Sex'][df['Survived'] == '0'].values
x1 = df['Sex'][df['Survived'] == '1'].values
trace0 = go.Histogram(x=x0, name = 'non')
trace1 = go.Histogram(x=x1, name = 'survive')
layout = go.Layout(bargap = 0.2, barmode = 'stack',xaxis = dict(title="Sex", dtick = 1))
fig = go.Figure(data=[trace0, trace1], layout=layout)
offline.iplot(fig)