はじめに
https://youtu.be/dEeMCIgpfwo?si=-EyjRFDRcutW8Ppi
この動画見て記事を書いています。この動画で言っていたのは
「AIにコアラの対義語を聞くと徳政になるらしい」
AI は なぜ「徳政」と答えるのか
その理由を ベクトルと単語の意味表現から紐解いていく。
ベクトルとは何か
ベクトルというと
「向きと大きさを持つもの」という数学的定義を思い浮かべがちだが、
AIの文脈ではもう少しシンプルに考えてよく
ベクトル = 数字の組
例えば:
- 二次元:
[24, 45] - 三次元:
[30, 90, 7]
実際のAIでは
- 数百次元
- 数千次元
といった 非常に高次元の数字の配列が使われている。
単語ベクトルとは
単語ベクトルとは、
単語1つ1つに対して、意味を表すベクトルを割り当てたもの
例えば(イメージ):
犬 → [0.12, 0.88, -0.32, ...]
猫 → [0.10, 0.85, -0.30, ...]
自動車 → [-0.91, 0.22, 0.40, ...]
重要なのは
意味が似ている単語ほど、ベクトルも似る
- 犬 と 猫 → ベクトルが近い
- 犬 と 自動車 → ベクトルが遠い
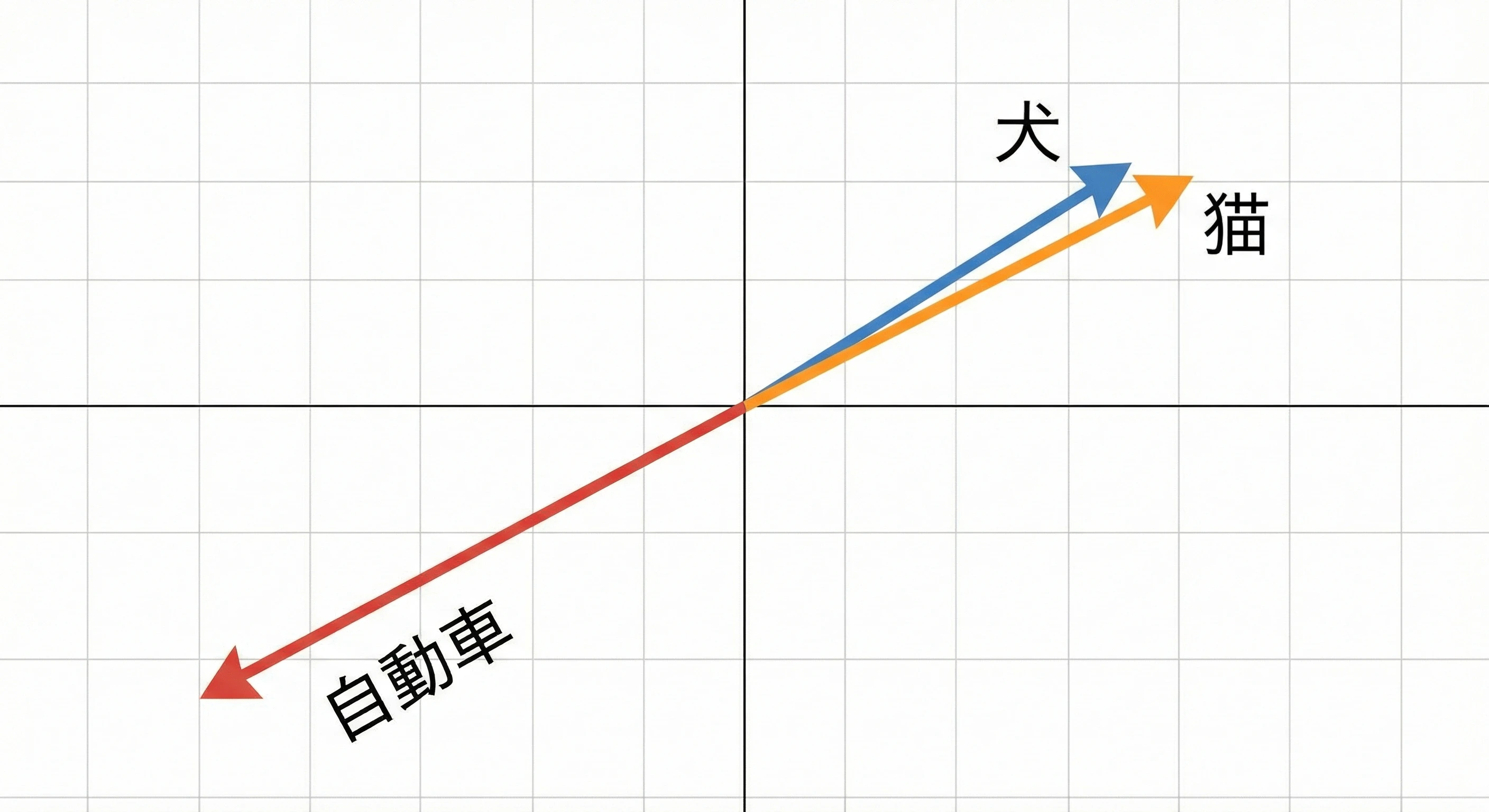
これによって AI は
「単語の意味の近さ」を 距離として扱える。
パラメータはどうやって決まるのか
「次にどんな単語が来やすいか」
「どんな文脈で使われるか」
という 確率予測を大量に繰り返して決まる。

この画像では、
各単語の後にどの動詞が続きやすいかを確率(頻度)として表している。
「犬」 と「猫」 は、
「飼う」 という動詞と一緒に使われることが多いため、
「飼う」方向の値が大きくなっている。
「自動車」 は、
「給油」 という動詞と強く結びつくため、
「給油」方向の値が大きくなっている。
このように単語ベクトルは、
単語そのものの意味を理解しているわけではなく、どのような文脈で使われやすいか
を数値として学習する。
その結果、
「犬」と「猫」は
同じような文脈(飼う・世話をする)で使われやすいため、
意味的に近い単語としてベクトル空間上でも近くに配置される。
「自動車」は
「給油」「運転する」といった異なる文脈で使われるため、
犬や猫とは離れた位置に配置される。
つまり単語ベクトルは、
「似た意味」=「似た文脈で使われる単語」
として捉える仕組みになっていることが、この図から分かる。
ここが一番誤解されやすいポイント。
❌ よくある誤解:
少年 = 男 + 若い + 人間
というように、意味的なラベルで数値を振っている
少年をどのようにベクトル化するのか
AIは「少年」をこう分解してはいない
- 男
- 若さ
- 子ども
代わりに、
- 「少年が走る」
- 「少年漫画」
- 「少年時代」
- 「少年と犬」
といった 出現文脈を大量に学習し、
「この単語の周辺には、こういう単語が来やすい」
という情報を
ベクトル(数字の組)に圧縮している。
なぜ「コアラの対義語」が徳政になると言われたのか
「コアラの対義語をAIに聞くと徳政になる」という話がある。
これは、単語ベクトルの性質から説明できる。
単語はそれぞれ ベクトル(数値の組) として表現されており、
意味が似ている単語ほどベクトルが近く、
意味が離れている単語ほどベクトルの距離が遠くなる。
ここで「対義語」を
ベクトル空間上で最も離れている単語
と仮定すると、
「コアラ」という具体的な動物名から最も遠い単語の一つとして
「徳政」のような全く文脈の異なる語が選ばれる可能性がある。
これが
「コアラの対義語が徳政になる」
と言われた理由だと考えられる。
しかし「対義語」は本当に“一番離れた言葉”なのか
ここで重要な誤解がある。
対義語 = 真反対の言葉
と思われがちだが、実際にはそうではない。
多くの対義語は、
「ほとんど同じ意味構造を持ち、一部だけが異なる」
という関係にある。
少年と少女の例
少年:男・若さ
少女:女・若さ
違うのは性別という一要素だけであり、
「年齢」「人間であること」「使われる文脈」は非常に近い。
つまり、
対義語は、意味空間では“遠い”のではなく、むしろ“近い”
単語ベクトルの限界
単語ベクトルは、
- 「似た意味かどうか」
- 「同じ文脈で使われやすいか」
を捉えるのは得意だが、
- 「意味の反対」
- 「論理的な対義関係」
を直接表現するようには作られていない。
そのため、
- 似た意味の単語を見つけることはできる
- 対義語を正確に見つけることは難しい
という性質を持つ。
まとめ
- ベクトルとは 数字の組
- 単語ベクトルは 使われ方を数値化したもの
- 意味が似ている単語は ベクトルが近い
- AIは「意味」を理解しているのではなく文脈の統計を学習している