SPSS Modelerでのテキストマイニング 感情分析編
こんにちは。
前回の記事からの続きになります。
今回は、感情分析をサンプルデータを使ってやってみます。
使うのは、拡張の変換ノードです。このノードを使って感情分析を実装します。
データは、日本語の感情分析の研究用データセットのWRIMEv1.0の"wrime-ver1.tsv"を使います。
主観(テキストの筆者1人)と客観(クラウドワーカ3人)の両方の立場から感情ラベル等もあり、いろいろな活用方法がありそうなデータですね。
1. 感情分析をやってみよう。
①. ストリーム全体
今回は、感情分析までの部分を紹介します。形態素解析は次回の予定です。

②. データ入力処理
感情分析する前のデータ入力処理について説明します。
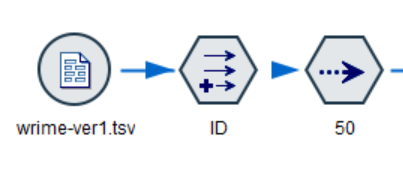
a. データ入力
可変長ファイルノードで"wrime-ver1.tsv"を読み込みます。
文字コードが"UTF-8"、区切り文字は"タブ"のデータです。

また、Sentence以外のフィールドは使わないためフィルタータブで除外しておきます。
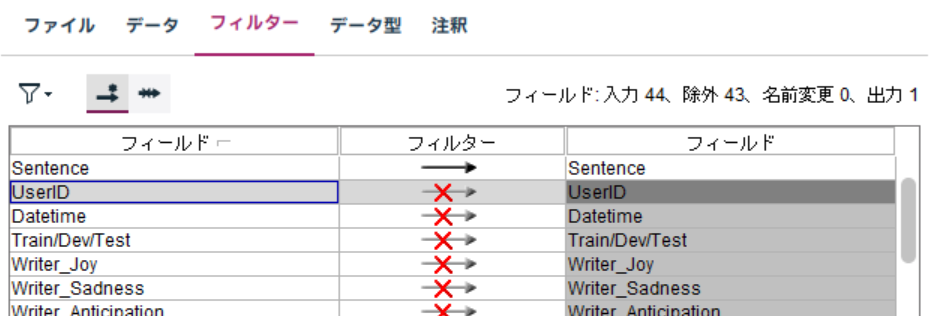
プレビューすると以下のようなデータです。

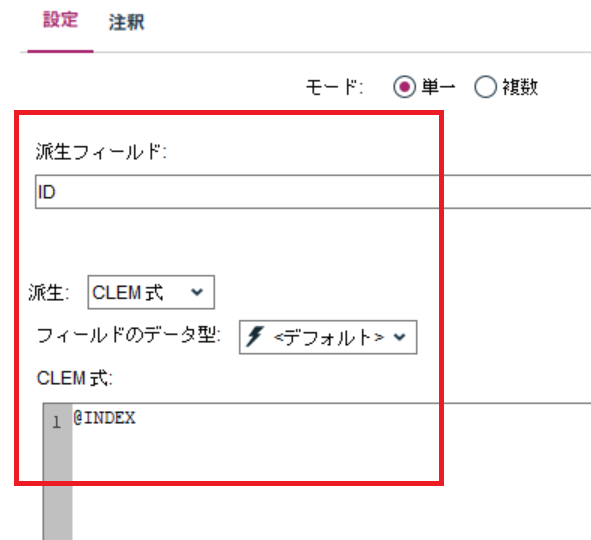
b. IDの付与
フィールド作成ノードで一意となるIDフィールドとして@INDEXでレコード番号を付与します。
c. データの絞り込み
サンプリングノードで最初の50レコードに絞っています。このデータは40,000レコード以上あるのですが、私の環境は非力なため処理が終わらないためです。ここは、ユーザーの方の環境毎に調整してください。

③. 感情分析処理
拡張の変換ノードを使ってPythonシンタックスで実装します。
a. コード全体
まずは、コード全体です。詳細は次の項から説明します。
#-------------------------------------------------------
# ライブラリインポート
#-------------------------------------------------------
# Modeler用ライブラリ
import modelerpy
# モデル構築用 Piplineタスク
from transformers import pipeline
# モデルロード用
from transformers import AutoModelForSequenceClassification
# Bert Tokenizer
from transformers import BertJapaneseTokenizer
# Pandas
import pandas as pd
#-------------------------------------------------------
# 出力用データ定義処理
#-------------------------------------------------------
if modelerpy.isComputeDataModelOnly():
#データモデル取得
modelerDataModel = modelerpy.getDataModel()
#--------------------------------------------------------------
#出力用変数フィールドを追加
#--------------------------------------------------------------
#データモデルにフィールドを追加
field_name_1 = "label"
field_name_2 = "score"
#データモデルの設定
modelerDataModel.addField(modelerpy.Field(field_name_1, "string", measure="nominal"))
modelerDataModel.addField(modelerpy.Field(field_name_2, "real", measure="continuous"))
#出力データモデル定義
modelerpy.setOutputDataModel(modelerDataModel)
#-------------------------------------------------------
# 感情分析モデル作成
#-------------------------------------------------------
else:
#入力データ取得
modelerData = modelerpy.readPandasDataframe()
outputData = None
#-------------------------------------------------------
# 感情分析モデル前処理
#-------------------------------------------------------
# daigo/bert-base-japanese-sentiment は非公開になっている
# koheiduck/bert-japanese-finetuned-sentimentを使います
model = AutoModelForSequenceClassification.from_pretrained('koheiduck/bert-japanese-finetuned-sentiment')
# 東北大学の乾研究室が作成したtokenizerを使いますす
tokenizer = BertJapaneseTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
# 感情分析のPipline定義
nlp = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
#-------------------------------------------------------
# 感情分析処理
#-------------------------------------------------------
# 感情分析実行 - Sentenceフィールドを分析
result = modelerData['Sentence'].apply(lambda x: nlp(x)[0])
#-------------------------------------------------------
# 感情分析結果まとめ処理
#-------------------------------------------------------
#Pandas用フィールド名定義
field_name_1 = "label"
field_name_2 = "score"
# label と score のフィールドに分けてデータフレームに変換
df_result = pd.DataFrame(result.tolist(), columns=[field_name_1, field_name_2])
# 結果を入力データに結合
outputData = pd.concat([modelerData, df_result], axis=1)
#-------------------------------------------------------
# Modelerに戻す
#-------------------------------------------------------
modelerpy.writePandasDataframe(outputData)
b. コード詳細
さて処理別にコードの内容をみていきましょう。
b-1. ライブラリインポート部分
まずは必要なライブラリをインポートしているだけです。
事前に準備の記事を参考にライブラリを導入しましょう。
#-------------------------------------------------------
# ライブラリインポート
#-------------------------------------------------------
# Modeler用ライブラリ
import modelerpy
# transformersは事前にインストールしておくこと
# モデル構築用 Piplineタスク
from transformers import pipeline
# モデルロード用
from transformers import AutoModelForSequenceClassification
# Bert Tokenizer
from transformers import BertJapaneseTokenizer
# Pandas
import pandas as pd
b-2. データモデル定義
拡張の変換ノードでは、後続ノードへデータモデルを渡すために、あらかじめデータモデルを定義する処理が必要になります。
#-------------------------------------------------------
# 出力用データ定義処理
#-------------------------------------------------------
if modelerpy.isComputeDataModelOnly():
#データモデル取得
modelerDataModel = modelerpy.getDataModel()
#--------------------------------------------------------------
#出力用変数フィールドを追加
#--------------------------------------------------------------
#データモデルにフィールドを追加
field_name_1 = "label"
field_name_2 = "score"
#データモデルの設定
modelerDataModel.addField(modelerpy.Field(field_name_1, "string", measure="nominal"))
modelerDataModel.addField(modelerpy.Field(field_name_2, "real", measure="continuous"))
#出力データモデル定義
modelerpy.setOutputDataModel(modelerDataModel)
b-2-1. if文の分岐
if modelerpy.isComputeDataModelOnly():
このif文の中でデータモデルを定義します。
"modelerpy.isComputeDataModelOnly()" の意味は、
後続ノードがデータモデルを参照するだけの場合という意味ですね。
(データを通過させなくてもフィルターノードなどはデータモデルを参照する必要があります。)
b-2-2. データモデル取得
modelerDataModel = modelerpy.getDataModel()
ここでは、直前のノードからのデータモデルを取得しています。
b-2-3. データモデルへのフィールド定義追加
modelerDataModel.addField(modelerpy.Field(field_name_1, "string", measure="nominal"))
modelerDataModel.addField(modelerpy.Field(field_name_2, "real", measure="continuous"))
ここでは、感情分析の結果(label)とスコア(score)を格納するフィールドを追加しています。
b-2-4. データモデルのセット
modelerpy.setOutputDataModel(modelerDataModel)
最後、後続ノードに渡すデータモデルをセットします。
b-3. 感情分析の実行
つづいて、データを通過させた場合の処理をelse以下に記述していきます。
ここでは、感情分析を実施します。
#-------------------------------------------------------
# 感情分析モデル作成
#-------------------------------------------------------
else:
#入力データ取得
modelerData = modelerpy.readPandasDataframe()
outputData = None
#-------------------------------------------------------
# 感情分析モデル前処理
#-------------------------------------------------------
# daigo/bert-base-japanese-sentiment は非公開になっている
# koheiduck/bert-japanese-finetuned-sentimentを使います
model = AutoModelForSequenceClassification.from_pretrained('koheiduck/bert-japanese-finetuned-sentiment')
# 東北大学の乾研究室が作成したtokenizerを使います
tokenizer = BertJapaneseTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
# 感情分析のPipline定義
nlp = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
#-------------------------------------------------------
# 感情分析処理
#-------------------------------------------------------
# 感性分析実行 - Sentenceフィールドを分析
result = modelerData['Sentence'].apply(lambda x: nlp(x)[0])
#-------------------------------------------------------
# 感情分析結果まとめ処理
#-------------------------------------------------------
#データモデルにフィールドを追加
field_name_1 = "label"
field_name_2 = "score"
# label と score のフィールドに分けてデータフレームに変換
df_result = pd.DataFrame(result.tolist(), columns=[field_name_1, field_name_2])
# 結果を結合
outputData = pd.concat([modelerData, df_result], axis=1)
#-------------------------------------------------------
# Modelerに戻す
#-------------------------------------------------------
modelerpy.writePandasDataframe(outputData)
詳しく見ていきましょう。
b-3-1. データの取得
#入力データ取得
modelerData = modelerpy.readPandasDataframe()
outputData = None
まずは、ModelerからPandasデータフレームでデータを読み込みます。
b-3-2. 学習済みのモデルの設定
#-------------------------------------------------------
# 感情分析モデル前処理
#-------------------------------------------------------
# daigo/bert-base-japanese-sentiment は非公開になっている
# koheiduck/bert-japanese-finetuned-sentimentを使います
model = AutoModelForSequenceClassification.from_pretrained('koheiduck/bert-japanese-finetuned-sentiment')
今回は、'koheiduck/bert-japanese-finetuned-sentiment'という、学習済みのモデルを利用します。初回実行時はここで、モデルがダウンロードされます。
★モデルは、トークン化されたデータを受け取り、それに基づいて予測や出力を行う役割を担います。
b-3-3. トークナイザーの設定
# 東北大学の乾研究室が作成したtokenizerを使います
tokenizer = BertJapaneseTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
東北大学が作成して公開しているトークナイザーを利用します。
初回実行時はここで、トークナイザーがダウンロードされます。
★トークナイザーはテキストデータ(文章)を、モデルが理解できる単位(トークン)に変換する役割を担います。
例: 私はPythonが好きです。 → [私, は, Python, が, 好き, です, 。]
b-3-4. パイプラインの構築
# 感情分析のPipline定義
nlp = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
指定したモデルとトークナイザーで"感情分析(sentiment analysis)"を実行するためのパイプライン(処理の流れ)を構築します。
b-3-5. 感情分析の実行
#-------------------------------------------------------
# 感情分析処理の実行
#-------------------------------------------------------
# 感性分析実行 - Sentenceフィールドを分析
result = modelerData['Sentence'].apply(lambda x: nlp(x)[0])
定義したpipelineを使ってvrimeのSentenceフィールドを感情分析します。
b-3-6. 分析結果の加工処理
#-------------------------------------------------------
# 感情分析結果まとめ処理
#-------------------------------------------------------
#Pandas用フィールド名定義
field_name_1 = "label"
field_name_2 = "score"
# label と score のフィールドに分けてデータフレームに変換
df_result = pd.DataFrame(result.tolist(), columns=[field_name_1, field_name_2])
# 結果を入力データに結合
outputData = pd.concat([modelerData, df_result], axis=1)
結果をpandasのデータフレームに一旦格納し、次に入力データに結合します。
※. 事前に定義したデータモデルと同じカラム名と数になるように、出力するデータも加工すること。
b-3-7. データの出力
#-------------------------------------------------------
# Modelerに戻す
#-------------------------------------------------------
modelerpy.writePandasDataframe(outputData)
最後にModelerへデータを戻します。
③. 結果の確認
結果をテーブルノードで確認してみます。
labelとscoreフィールドに感情分析の結果と、結果にする確信度が入っています。

1レコード目は、
「ぼけっとしてたらこんな時間。チャリあるから食べにでたいのに…」はNEGATIVEとなり
2レコード目は、
「今日の月も白くて明るい。昨日より雲が少なくてキレイな? と立ち止まる帰り道。チャリなし生活も悪くない。」はPOSITIVEとなっていますね。
結果は、問題なさそうです。
2. まとめ
残念ながら、SPSS Modelerの標準機能での日本語のテキストマイニングはサポート終了となってしまっていますが、Pythonのライブラリを利用することで、幅広い学習済みのモデルやトークナイザーを利用することもできます。
ぜひ、挑戦してみてください。
10/17 追記
v18.4以前のユーザーさんでも参考になるように「Python for Spark」での記事も書きました。
3. 動作させるまでに発生したあれこれ その2
さて、ここまでの簡単な内容でも初めて触ると結構苦労しました。
いろいろ動作させるまでに苦労した点の第2弾を以下に参考までに記載します。
⑤. サーバー データ モデルで不正な数のフィールドが検出されました。 期待された数: 0 実際: 1
こんなエラーメッセージが表示されて処理が中断することがあります。

最初は???なんのことですか?となりました。
このエラーは十中八九、"出力データモデル"と"出力データ"のカラム名や数があっていない場合に発生します。
今回の記事の内容だと、
「b-2-4. データモデルのセット」で定義したデータモデルと、
「b-3-7. データの出力」で出力するデータフレームの内容が異なる場合に発生します。
カラム名などを見直しましょう。
⑥. ibm_spss_modeler.UserCancelledError: Fetch data is fininished
何回実行しても、以下のようなメッセージがでて完了できない場合がありました。

ibm_spss_modeler.UserCancelledError: Fetch data is fininished
During handling of the above exception, another exception occurred:
このエラーは拡張ノードの処理を無理やり実行中止にした後から発生したと思います。
このエラーが発生すると、なぜか何回実行して同じノード処理はうまくいきません。
その時は、サンプルで拡張の変換ノードを作成し、準備編のようなユーザー入力ノードから実行して回避しました。
下記コードは、単にデータを素通りさせているだけです。いったんメモリ上のデータをきれいにしてあげる必要があるのか???
###Use this code to transfer data between Modeler and Python
import modelerpy
if modelerpy.isComputeDataModelOnly():
modelerDataModel = modelerpy.getDataModel()
outputDataModel = modelerDataModel
### compute your output data model
modelerpy.setOutputDataModel(outputDataModel)
else:
modelerData = modelerpy.readPandasDataframe()
outputData = modelerData
### compute your output data
modelerpy.writePandasDataframe(outputData)
次回
次回は、Mecabを使って形態素解析をしてみます。
参考
SPSS Modeler ノードリファレンス目次
SPSS Modeler 逆引きストリーム集
SPSS funさん記事集
SPSS連載ブログバックナンバー
SPSSヒモトクブログ