1. はじめに
みなさん、こんにちは。前回に引き続き偏相関係数をSPSS Modelerで計算してみようと思います。
前回は、線形回帰モデルを使用して計算しましたが、今回はおなじみの拡張ノードを使って、Pythonで実装しようと思います。
今回使用したストリームはGit Hubに公開しています。ご自由にダウンロードしてください。
データは、以下のサイトよりダウンロードをお願いします。(前回の記事のデータと同一です。)
2. 拡張ノードを使った偏相関係数の計算
2.1 ストリーム全体
以下がストリーム全体です。拡張の出力ノードを使います。

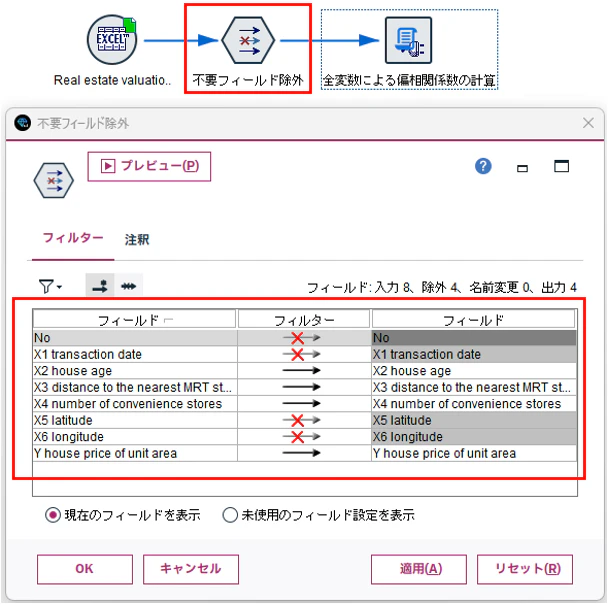
2.2 データの入力と不要フィールドの除外
データの入力は同じです。今回は「No」フィールドも除外します。
2.3 偏相関係数の計算
さて、拡張の出力ノードへPythonシンタックスを記述し、偏相関係数の計算をしていきます。
2.3.1 シンタックス全体
pythonで実装するので、全変数間の偏相関係数を計算してみます。以下がシンタックス全体です。
#--------------------------------------------------------------
# SPSS Modeler Extension Output Node
# Python Syntax
# Partial Correlation (All Variables)
#--------------------------------------------------------------
#=============================
# ライブラリ導入
#=============================
import modelerpy
import pandas as pd
import numpy as np
#==============================
# データ入力
#==============================
mdf = modelerpy.readPandasDataframe()
#==============================
# 説明変数設定(数値列のみ抽出)
#==============================
mdf_numeric = mdf.select_dtypes(include=['number'])
#==============================
# 偏相関係数の計算関数
#==============================
def get_partial_corr_matrix(indf):
# 相関行列の計算
corr_mat = indf.corr()
try:
# 逆行列(精度行列)の計算
# 多重共線性がある場合はここでエラーになる
inv_corr = np.linalg.inv(corr_mat.values)
except np.linalg.LinAlgError:
return None
# 対角成分の平方根(分母の計算用)
d = np.sqrt(np.diag(inv_corr))
# 偏相関係数の計算: -w_ij / sqrt(w_ii * w_jj)
partial_corr = -inv_corr / np.outer(d, d)
# 対角成分を1.0に修正
np.fill_diagonal(partial_corr, 1.0)
return pd.DataFrame(partial_corr, index=corr_mat.index, columns=corr_mat.columns)
#==================================
# 計算の実行
#===================================
pcorr_matrix = get_partial_corr_matrix(mdf_numeric)
#===================================
# 全カラムを対象とした結果出力
#===================================
if pcorr_matrix is not None:
print("=== Partial Correlation Analysis (All Columns) ===")
# 数値列のリストをループで回す
for target in mdf_numeric.columns:
print(f"\nTarget Variable: [ {target} ]")
print("-" * 40)
# 自身を除外して降順(正の相関が強い順)にソート
result = pcorr_matrix[target].drop(target).sort_values(ascending=False)
# 結果の表示
if result.empty:
print("No other numeric variables to compare.")
else:
print(result)
print("-" * 40)
else:
print("Calculation Error: Singular matrix (multicollinearity).")
2.3.2 シンタックス詳細
詳細をみていきます。
①. ライブラリの導入
SPSS Modeler用のライブラリと、numpy、pandasをインポートします。
#=============================
# ライブラリ導入
#=============================
import modelerpy
import pandas as pd
import numpy as np
②. データの入力
データをModelerからPandasで取得し、数値フィールドのみに絞り込みます。
(今回、絞り込みはしなくてもいいのですが。)
#==============================
# データ入力
#==============================
mdf = modelerpy.readPandasDataframe()
#==============================
# 説明変数設定(数値列のみ抽出)
#==============================
mdf_numeric = mdf.select_dtypes(include=['number'])
③. 偏相関係数を計算する関数の定義
偏相関係数を計算する関数を定義しています。
相関行列の逆行列を $W$ としたとき、変数 $i$ と変数 $j$ の偏相関係数は以下の数式で求められるという数学的性質を利用しています。$$偏相関係数 = - \frac{w_{ij}}{\sqrt{w_{ii} w_{jj}}}$$($w_{ij}$ は逆行列の $i$ 行 $j$ 列目の成分、$w_{ii}$ と $w_{jj}$ はそれぞれの対角成分です)
以下の順で処理をしています。
- 分子で使用する相関行列の逆行列を計算
- 分母で使用する対角成分の平方根を計算
- 偏相関係数を計算
- 対角成分の偏相関係数が-1.0になるので1.0に手動で修正
#==============================
# 偏相関係数の計算関数
#==============================
def get_partial_corr_matrix(indf):
# 相関行列の計算
corr_mat = indf.corr()
try:
# 逆行列(精度行列)の計算
# 多重共線性がある場合はここでエラーになる
inv_corr = np.linalg.inv(corr_mat.values)
except np.linalg.LinAlgError:
return None
# 対角成分の平方根(分母の計算用)
d = np.sqrt(np.diag(inv_corr))
# 偏相関係数の計算: -w_ij / sqrt(w_ii * w_jj)
partial_corr = -inv_corr / np.outer(d, d)
# 対角成分を1.0に修正
np.fill_diagonal(partial_corr, 1.0)
return pd.DataFrame(partial_corr, index=corr_mat.index, columns=corr_mat.columns)
④. 計算結果の出力
最後に結果を出力します。
ループ処理で全変数を対象にし、正の相関係数が高い順にソートしています。
また、不正なデータや多重共線性がある変数の逆行列を計算してしまうと
エラーが発生する可能性があるため、エラー処理を入れています。
#==================================
# 計算の実行
#===================================
pcorr_matrix = get_partial_corr_matrix(mdf_numeric)
#===================================
# 全カラムを対象とした結果出力
#===================================
if pcorr_matrix is not None:
print("=== Partial Correlation Analysis (All Columns) ===")
# 数値列のリストをループで回す
for target in mdf_numeric.columns:
print(f"\nTarget Variable: [ {target} ]")
print("-" * 40)
# 自身を除外して降順(正の相関が強い順)にソート
result = pcorr_matrix[target].drop(target).sort_values(ascending=False)
# 結果の表示
if result.empty:
print("No other numeric variables to compare.")
else:
print(result)
print("-" * 40)
else:
print("Calculation Error: Singular matrix (multicollinearity).")
2.4 結果の出力
最後に結果を確認しましょう。
Target Variableが偏相関係数を計算する対象の変数です。
その行の下にその変数との偏相関係数及び変数名が出力されています。
「Y house price of unit area」と「X3 distance to the nearest MRT station」の偏相関係数も
前回計算した「-0.506」とほぼ同じですね。(小数点以下の出力の関係上ちょっと異なる)

最後に
さて、いかがでしたでしょうか?Pythonを使うと簡単に全変数の偏相関係数が計算できましたね。
SPSS Modelerだけでは実現が難しくても、上手くPythonなどを活用することで色々実現できるようになっています。
このようなプログラムは、今後IBM Bobなどを使うことでますます身近になっていくと思います。
但し、コードは書いてくれても、どのように分析したらいいいのか?まではしてアシストしてくれません。
きちんとした分析結果を得るためには、指示をしてコードを書かせる必要があります(このモデルで、こんな特徴量をつくってなど)。
分析者とSPSS Modeler、Bobを上手にコラボレーションさせながら精進していきましょう!
参考
SPSS Modeler ノードリファレンス目次
SPSS Modeler 逆引きストリーム集
SPSS funさん記事集
SPSS連載ブログバックナンバー
SPSSヒモトクブログなどは以下のTechXchangeのコミュニティに統合されました。
ご興味がある方は、ぜひiBM IDを登録して参加してみてください!!!お待ちしています。
IBM TechXchange Data Science Japan