1. はじめに
みなさん、こんにちは。IBM Granite Time Series Model編は前回の記事で一区切りとなりました。今回は、番外編としてSPSS Modelerに搭載されている時系列モデルを使って同じデータで予測をしてみたいと思います。
GitHubに今回利用しているストリームをアップロードしています。
ご自由にダウンロードしてください。
2. SPSS Modelerの時系列モデル
SPSS Modelerの時系列モデルの使い方については、西牧さんの記事を参考にしてください。
上記モデル以外にも時間因果モデル(TCMモデル)も搭載されています。
3. 準備
3.1 データ
データは、前回まで使用してきた Hugging Face にあるスペインのエネルギーデータです。
energy_dataset.csvをダウンロードしてください。
3.2 ストリーム
ストリームもデータ加工及び結合部分までは、前回までと同様です。
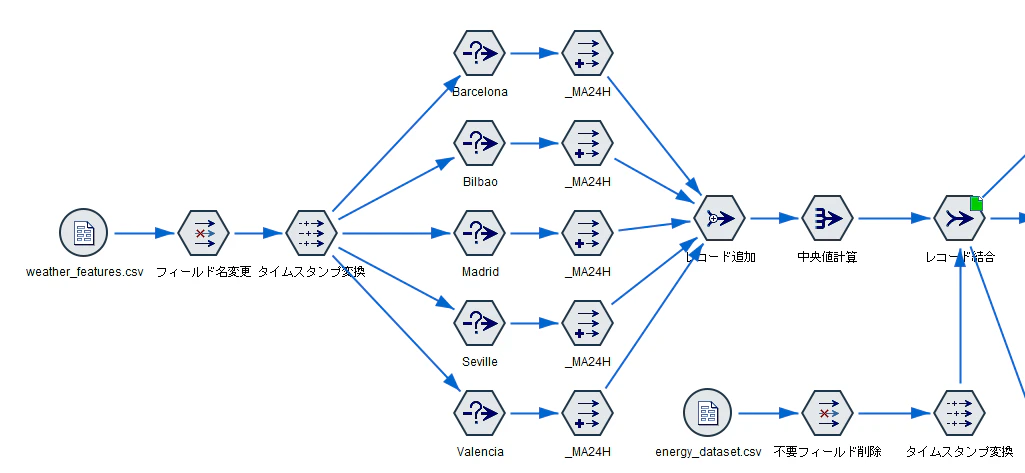
データ加工のやり方は、下記の記事を参照してください。
4. SPSS Modelerの時系列モデルを使って予測
さて、ここから時系列モデルによる予測を実施していきます。
4.1 時系列モデルノードを使った予測
今回は時系列モデルノードによる予測を紹介します。
時系列モデルノードによる予測部分のストリームは以下の通りです。
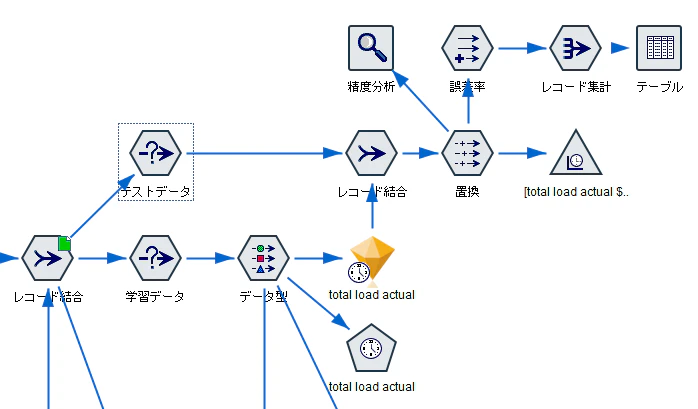
4.1.1 処理詳細
詳細をみていきましょう。
4.1.1.1 テストデータと学習データ
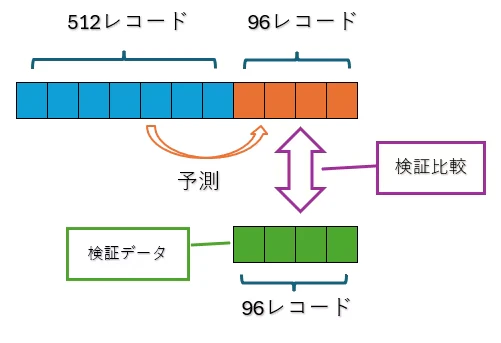
SPSS Modelerにはデータ区分ノードというデータを学習・テスト・検証に分けてくれるノードが準備されています。
ですが、ここではGranite Time Seriesと同様のデータにするため手動でデータを分割します。
以下のイメージのように、条件抽出ノードを使用して分割します。
・レコードの最後から96レコードをテストデータ(緑色の部分)
・テストデータから前の512レコードを学習データにします。(青色の部分)
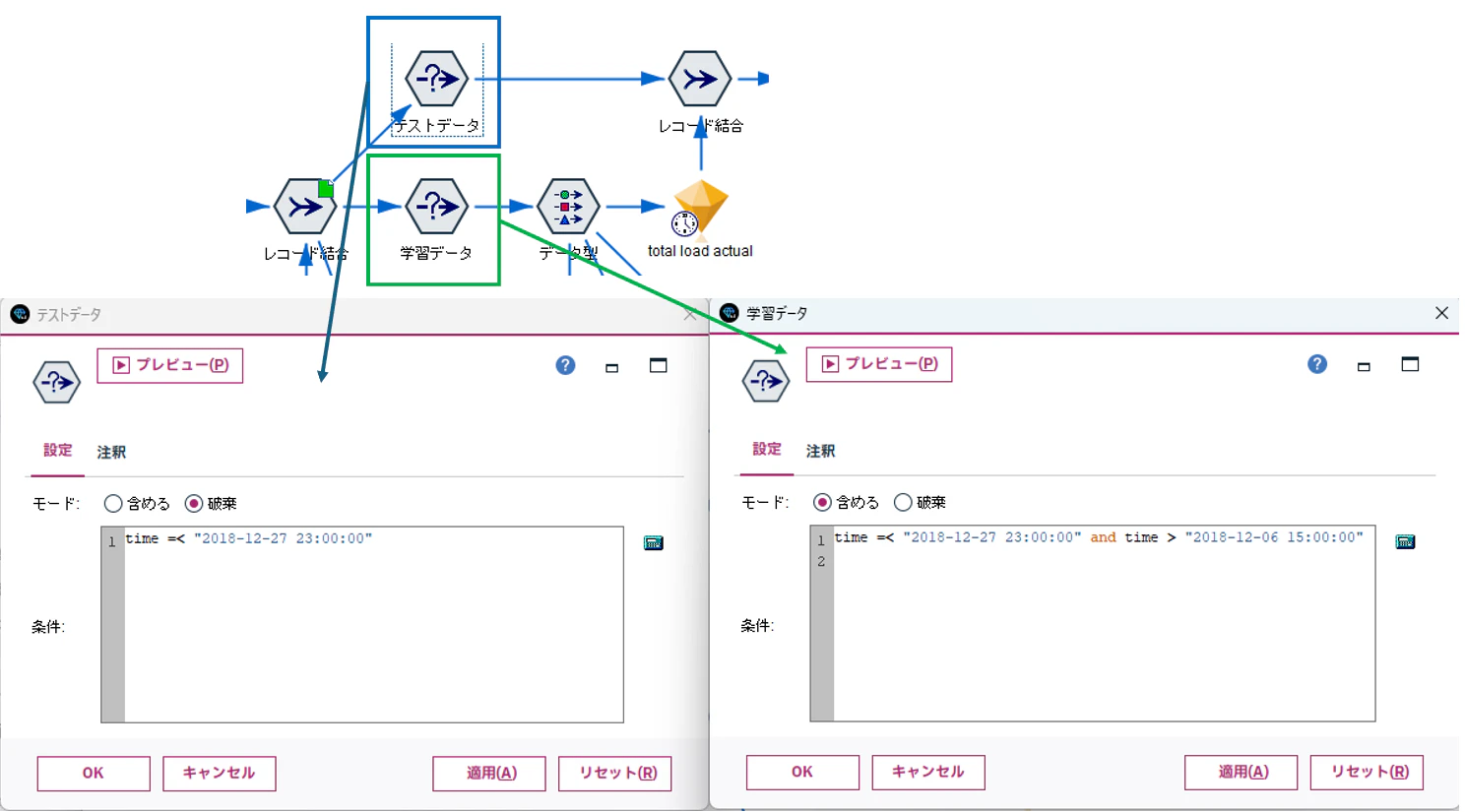
以下のように日付を指定して条件抽出しています。
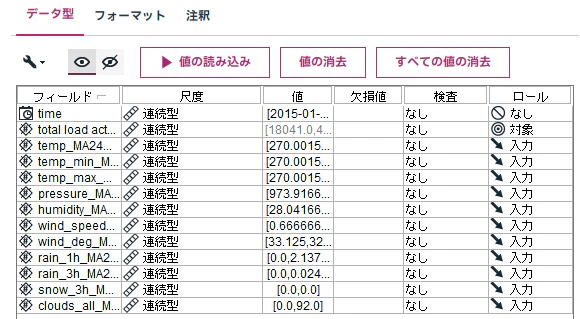
4.1.1.2 データ型ノードの設定
モデルを作成する際に必ずデータ型ノードでインスタンス化を実施する必要があります。
※.インスタンス化 = データの型やロール(役割)を定義すること
ここでは、
対象 = "total load actual"
入力 = "time" と "total load actual"以外のフィールド
としています。
4.1.1.3 時系列モデルノードの設定
つづいて時系列モデルノードの設定を実施します。
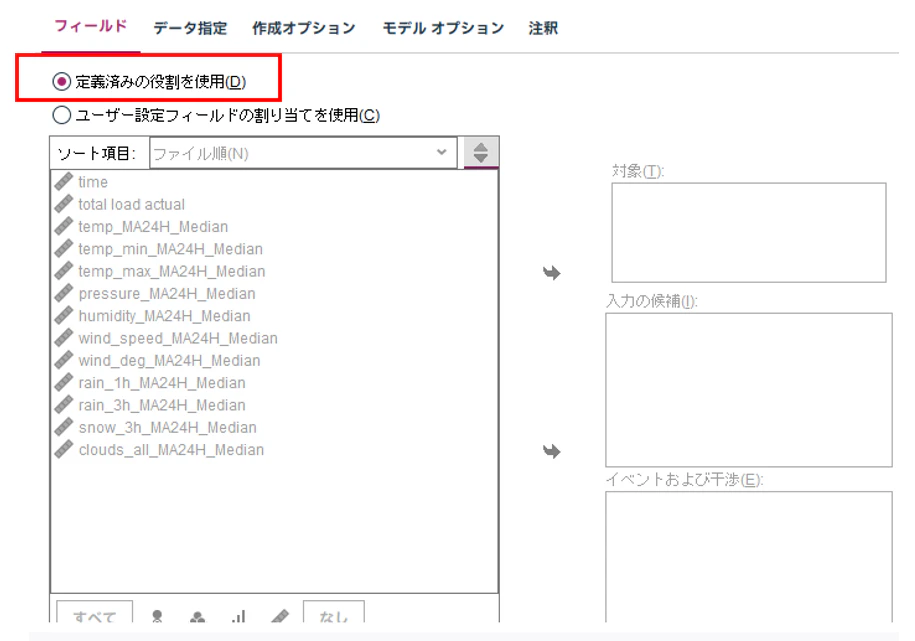
①. フィールド設定
データ型ノードでロールを設定しているため、"定義済みの役割を使用"を設定します。
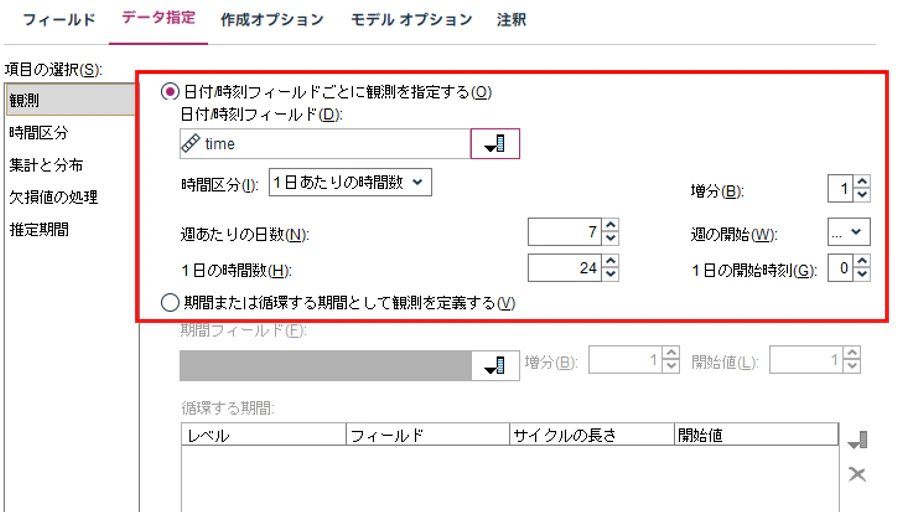
②. データの指定
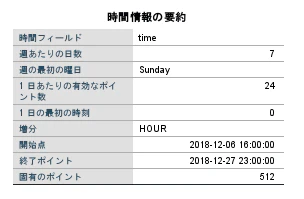
時系列の定義を実施します。
日付時刻フィールド = "time"
時間区分 = "1日あたりの時間数" ※今回のデータは1時間ごとのデータのため
増分 = "1" ※今回のデータは1時間ごとのデータのため
週当たりの日数 = "7"
週の開始 = "日曜日"
1日の時間数 = "24"
1日の開始時刻 = "0"
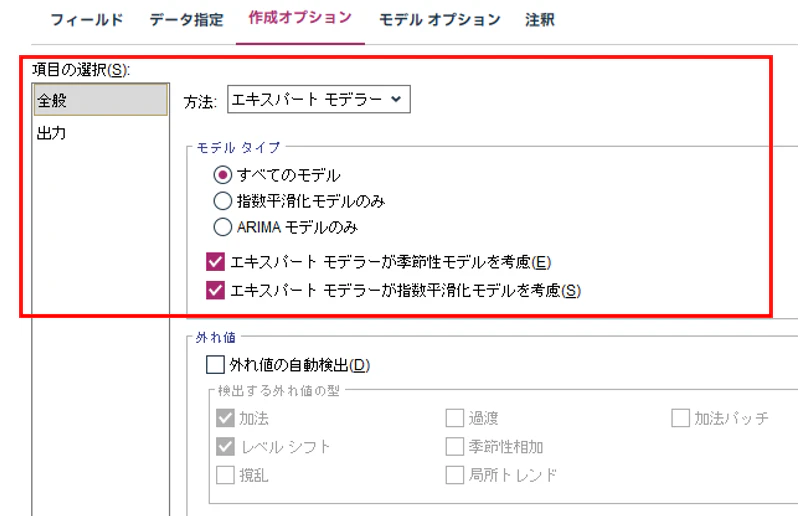
③. 作成オプション<全般タブ>
オプション<全般>を設定します。
方法 = "エキスパートモデラー"
エキスパートモデラーは、ARIMAモデル、指数平滑化モデル等を作成して最も適合するモデルを選択してくれる便利な機能です。
オプション1 = "季節性モデルを考慮"にチェック
季節性を考慮しない場合は、非季節性モデルのみが考慮されます。
オプション2 = "指数平滑化モデルを考慮"にチェック
指数平滑化モデルはv18.1以降で6個のモデルが追加され全13個のモデルが用意されています。
指数平滑化モデルを考慮しない場合、v18.1以降で追加されてモデルは使わず7個のモデルのみが考慮されます。
④. 作成オプション<出力タブ>
オプション<出力>を設定します。
変数の重要度を計算にチェックをいれます。

⑤. モデルオプション<出力タブ>
モデルオプションを設定します。
予測の将来への拡張を "96" に設定します。
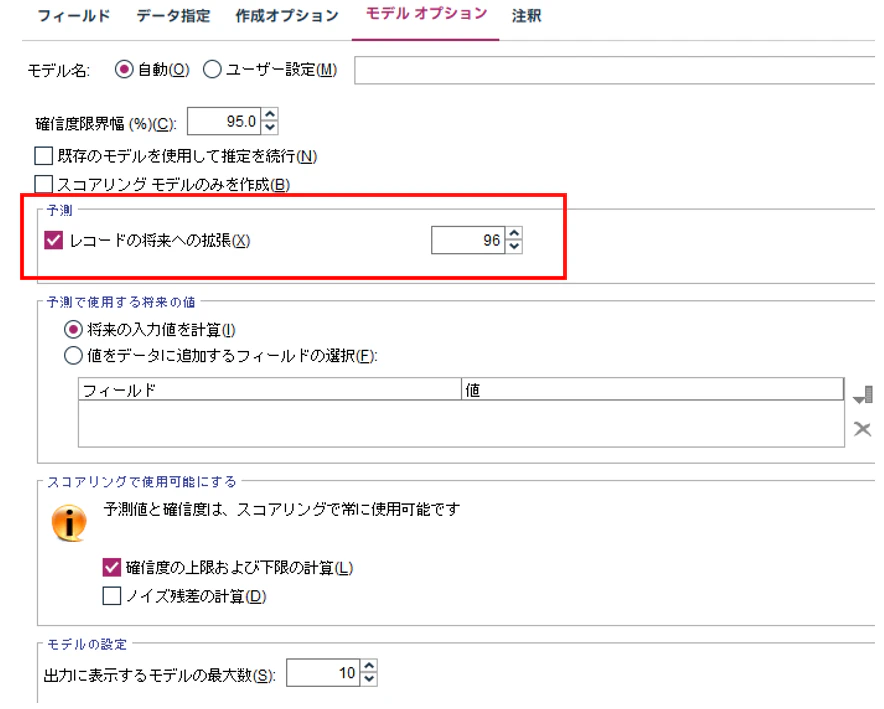
Granite Time Seriesモデルは 512レコードを使って、96レコード先まで予測するものを使用しました。そのモデルに合わせた設定です。
4.1.1.3 時系列モデルナゲットの確認
先ほどまでの設定で、モデルを実行するとモデルナゲットが作成されますので、その内容をみてみましょう。
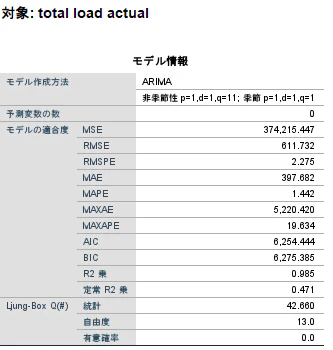
①. モデルの要約
まずは、モデルの概要が出力されます。今回のデータや設定の内容が出力されています。
②. モデルの精度
選択されてモデルや、その精度が確認できます。
ARIMAモデル ー 両方を組み合わせた ARIMA モデル(SARIMA)
今回は、季節性・非季節性を組み合わせたモデルが採用されています。
非季節性 (p=1, d=1, q=1)
季節性 (p=1, d=1, q=1)
共に、
p=1 → AR(1)成分あり
d=1 → 1階差分をとって定常化
q=1 → MA(1)成分あり
注意が必要なのは、ここで出力される精度は学習データによるモデルの精度です。
テストデータによる精度ではありません。そのためかなり高い精度( MAPE = 1.442 % など)がでていることが確認できると思います。
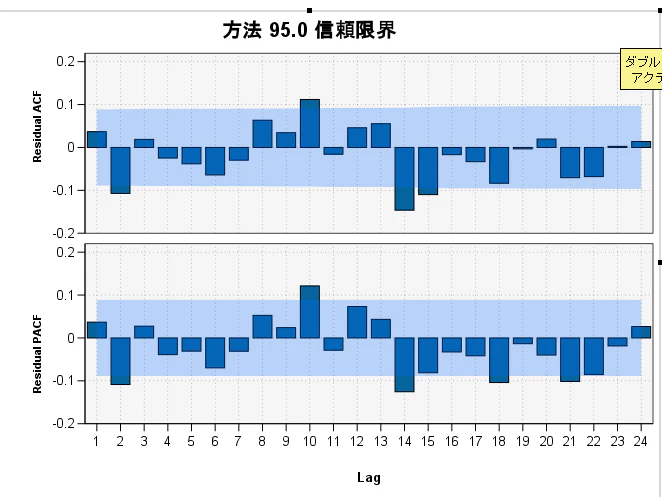
③. 残差の自己相関
残差の自己相関(ACF)と偏自己相関(PACF)のグラフで、モデルの妥当性を判断できます。
ほとんど、青い帯の内側に収まっているので、残差に相関は少なく良好なモデルといえそうです。
ただし、ラグの10、15あたりが外側にはみ出ているので改善の余地はあると思われますが、精度が高いため、このまま採用します。
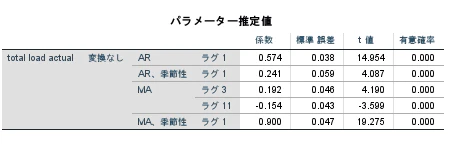
④. パラメーターの推定値
最後に変数について確認します。
入力変数に各種中央値をいれてモデルを作成しましたが、"total load actual"自身で予測しているという結果になっていますね。
ラグが1、3、11となっているので、1、3、11時間前のデータが影響を及ぼしていそうです。
4.1.1.4 テストデータによる精度の確認
作成した時系列モデルでは 96レコード 先まで予測値を取得しています。このレコードとテスト用の96レコードを突合して精度を確認します。
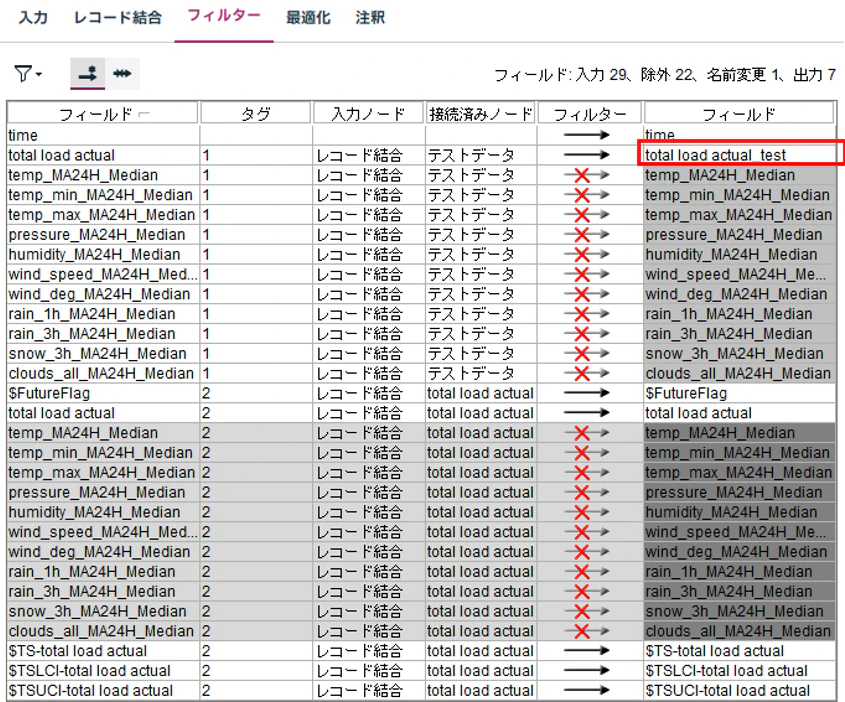
①. レコード結合
テストデータと予測結果を突合するため、レコード結合ノードでデータを内部結合します。
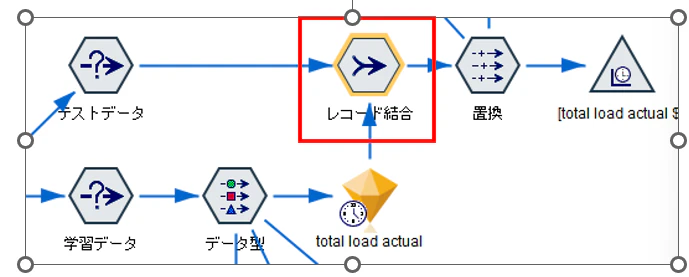
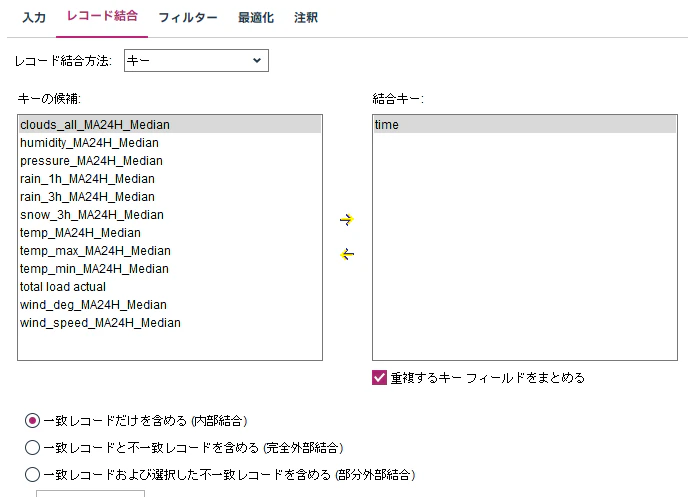
また、フィルタータブで、実測値と予測値以外のフィールドを除外します。
ついでに、今回は説明のために、テストデータの"total load actual"のフィールド名を変更しておきます。今回は、"total load actual_test"としています。
②. テストデータによる置換
以下が、結合した結果になります。
各フィールドの説明は以下の通り。
total load actual_test = テストデータ
tatal load actual = 学習データ ※96レコード分は入力されていないので"NULL"
$FutureFlag = 未来への拡張で追加されたレコードにフラグ "1" が設定される
$TS-total load actual = 予測値
$TSLCI-total load actual = 予測値の95%信頼区間の下限
$TSUCI-total load actual = 予測値の95%信頼区間の上限
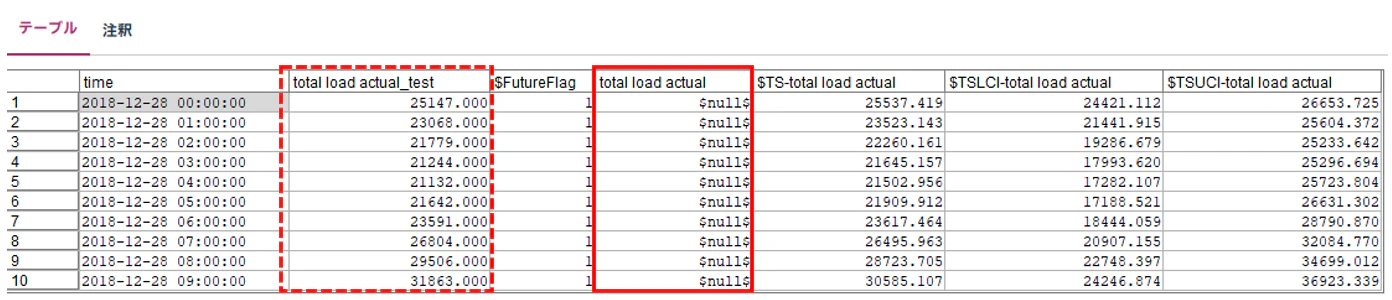
後続で精度分析ノードを利用して精度を確認するために、"total load actual" のデータを"total load actual_test"の値で上書します。
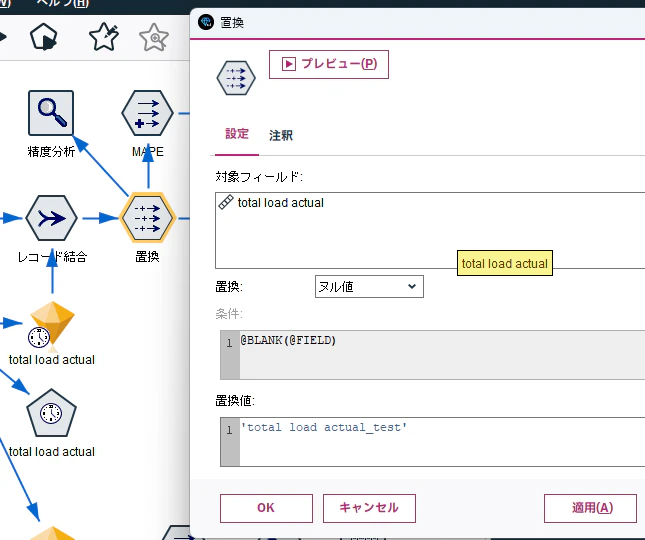
③. 精度の確認1
精度分析ノードで精度を確認します。
設定は、何も変更せずに実行します。
以下が精度分析結果になります。やはり学習データの場合からは精度が下がっていますね。
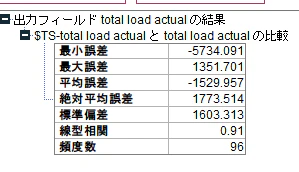
④. 精度の確認2
MAPEを計算します。
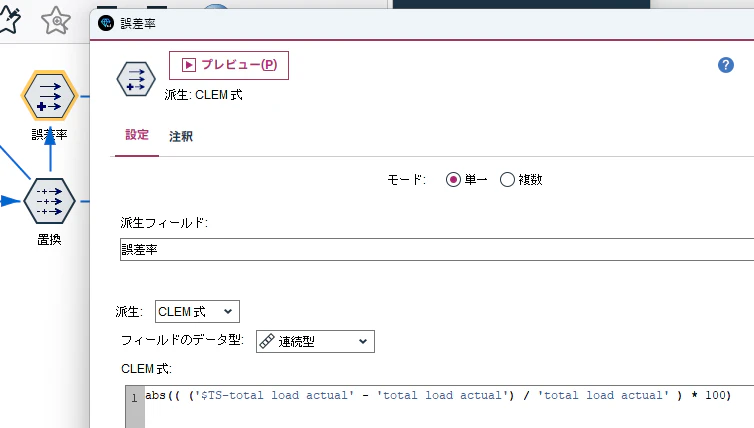
まずは、フィールド作成ノードで誤差率を計算します。
単純に(予測値ー実測値 / 実測値)× 100 を計算して絶対値を取得しています。
続いて、誤差率の平均値をレコード集計ノードで計算します。
結果は、6.813% となりました。

④. グラフによる確認
今回は、拡張した96レコードのみのため、時系列グラフを使用してみます。
以下のように設定して実行します。
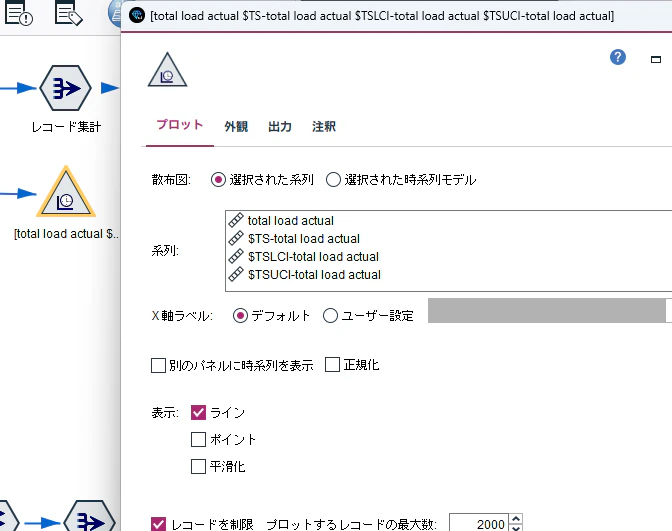
以下が結果となります。
上下の緑と青の線が95%信頼区間です。
水色が実績、赤が予測値です。結構当たっていますね。
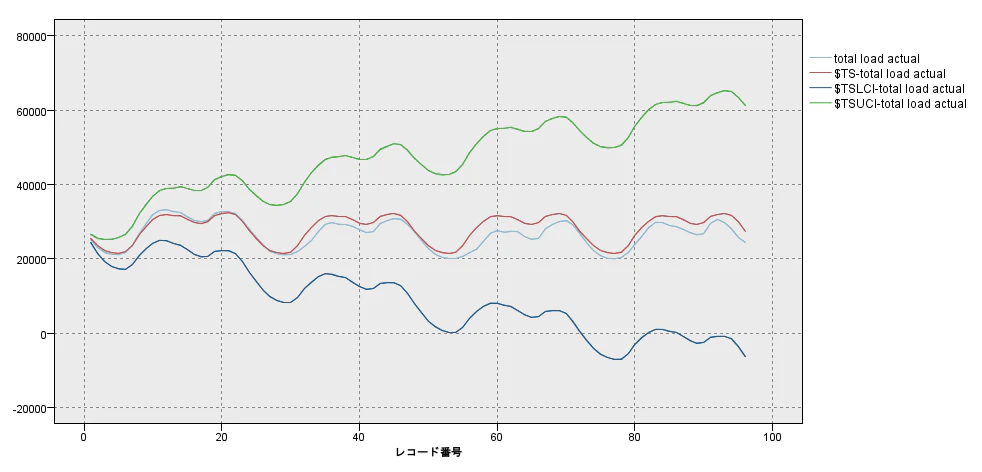
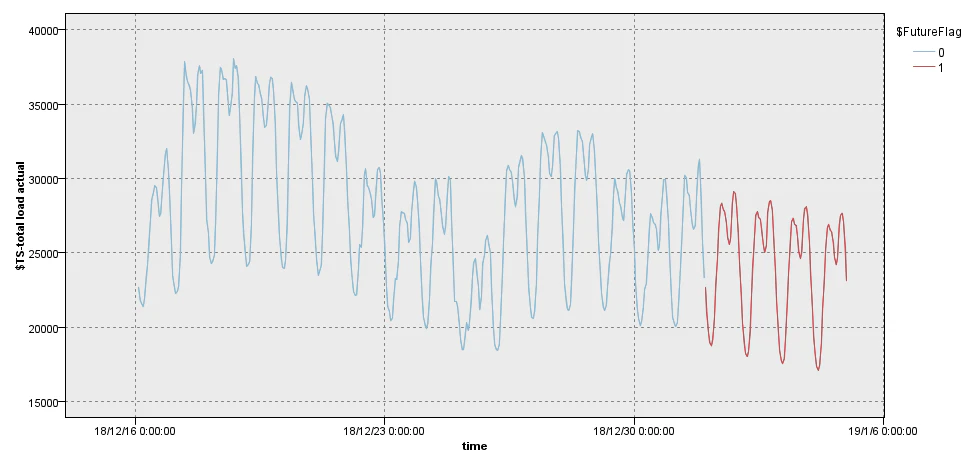
Graniteのときと同様に最終レコード以降の96レコードを予測すると以下のようになりました。
若干下がっていくトレンドのグラフになっていますね。Graniteとは違った結果になっています。
5. 精度の比較
さて、最後にGranite Time Series との精度の比較をしてみましょう。
MAPEのみ計算してみました。
| Model | MAPE |
|---|---|
| Granite Zero-Shot | 9.41% |
| Granite Fine-Tuning | 8.08% |
| Granite Watsonx API | 6.08% |
| SPSS Modeler 時系列モデル | 6.81% |
Watsonx上のモデルが一番いい結果となりました。
6. 最後に
いかがでしたでしょうか?
全7回にわたって、Granite Time Series Model及び時系列モデルノードについて紹介させていただきました。
やはり、GUIで実装できる SPSS Modeler は楽ですね(笑)。
ただ、Graniteはオープンソースであるところが驚くべき点です。この精度をだせる時系列モデルが、誰でも自由に利用できるとは。IBMさん太っ腹ですね。
IBMがモデルをアップデートしてくれれば、さらに精度も向上していくのではないでしょうか。
今後に期待しましょう!!
参考
SPSS Modeler ノードリファレンス目次
SPSS Modeler 逆引きストリーム集
SPSS funさん記事集
SPSS連載ブログバックナンバー
SPSSヒモトクブログなどは以下のTechXchangeのコミュニティに統合されました。
ご興味がある方は、ぜひiBM IDを登録して参加してみてください!!!お待ちしています。
IBM TechXchange Data Science Japan