本記事はestie Advent Calendar 2019-12日目のものとなります.
是非他の記事もご覧くださいね![]()
はじめに
不動産ベンチャーestie.incエンジニアのymjです.
弊社はオフィス向け不動産としてお客様により良い物件を提案できるよう様々な角度から技術的なチャレンジをしています.今回はその中でも「似ている物件」を定義する技術についての考察をまとめてみました.これは賃料を推定したり,レコメンドする物件を決めたりなどする場合に有用です.
「似ている物件」すなわち「類似度が高い物件」を定義する方法はこれまで多く考案されてきました.特にレコメンドの分野では「ユーザ(お客様)×アイテム(物件)」のマトリクスを作成し「同じようなユーザに同じような評価されているアイテムは似ているだろう」という前提のもとアイテムの類似度を定義します.この考え方はいわゆるAmazonの「この商品に興味のあるお客様が見ている商品」として活用されています.しかしながら,この考え方は当然「ユーザの評価や閲覧履歴が必要」という大前提があります.
では,サービスリリース当初のような「ユーザの評価」がまだ蓄積されていない時に,アイテムの類似度はどう定義すれば良いでしょうか.本記事はこの問いに対する考察を示すものです.
前提
本記事における議論の定義範囲です.
本記事は,
- アイテムの基本的な属性情報を元に類似度を算出する場合の話です.
- 類似度算出方法(およびその特徴量の選定方法)はこれだ!と示すものではありません.あくまで考え方の参考になることを目指しています.
- 文書のカテゴライズなどで用いられるような類似度とは考え方が少し異なります.
データ
弊社ではオフィス向け物件を取り扱っていますが,オフィス向け物件はデータが少しマニアックなところがあります.より一般の方に近いデータで説明する方が少しでも理解しやすいと思い今回はSUUMOさんの賃貸物件を利用させていただきます.ありがとうございます!
※本記事をみて弊社サービスに触れてみたい!となっていただいた方は是非体験してみてください!
スクレイピングしてくる
山手線/東京駅の物件ページをスクレイピングしてきました.
スクレイピングの方法は本記事では本題ではないので各記事,書籍をご参考ください.
こんな感じで1ページ分のデータを取得しました.(2019/12/11時点)

これは取得データの一部例です.全て載せるのは大変なので以降例を使って説明していきます.カラム名やカラムの順番は適当です.念の為左から
[住所, その募集物件の階数, 物件自体の階数, 管理費, 間取り, 面積, 物件名, 最寄駅, 礼金, 家賃, 敷金, 築年数]
です.「え,築年古ければ東京駅付近でも10万くらいで住めるんだ![]() 」とか思いながら進めて行きます(本記事では関係ありませんがこういうことの繰り返しがドメイン知識になっていきます).物件名は元ページをご覧いただければ分かりますが「最寄駅+築年数」記載の物件もあるようです,が気にせず進めます.
」とか思いながら進めて行きます(本記事では関係ありませんがこういうことの繰り返しがドメイン知識になっていきます).物件名は元ページをご覧いただければ分かりますが「最寄駅+築年数」記載の物件もあるようです,が気にせず進めます.
クレンジングする
上記スクレイピングデータは表記揺れがあったり数値としてそのまま扱うことができません.今回は類似度に関する記事ということで,類似度計算の対象とするカラムを**[その募集物件の階数, 物件自体の階数, 管理費, 面積, 礼金, 家賃, 敷金, 築年数]**として,これらを数値に直していきます(カラムの選定に根拠は特にありません,例えばの話です).また,完全に同じ物件(全ての特徴量が同じ物件)がいくつかあったのでそれら重複を省きます.こんな感じになりました.
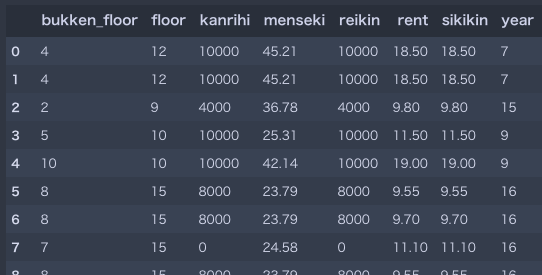
各レコードが各物件を表しています.最終的にレコード数は52件になりました(同じ物件名は30件でした).データ数としては多くありませんが精度を求めている訳でないのでひとまずこのままで良いでしょう.単位やデータ型を揃えるとかは本記事では本質ではないのであまりこだわずドシドシ進めます.
さあ数値データになりました.分析したくてうずうずし始めますね![]()
類似度の算出
お待たせしました.やっとメインです.
いざ各物件の属性情報のみを使って類似度を算出するためにまず類似度の算出方法を定義します.
類似度の定義
今回は各物件をベクトルとして扱い類似度計算をします.ベクトルの類似度計算は以下が代表的です.
- コサイン類似度
- ピアソンの積率相関係数
- MSD(Mean Squared Differece)
あとで出てきますが,コサイン類似度とピアソンの積率相関係数は数学的にほぼ同じ意味を持っています.MSDはその名の通り各特徴量の2乗誤差の平均がベースとなっています.1つでも誤差が大きい特徴量があると類似度が下がるのでそういった用途には良いでしょう.
今回はコサイン類似度を元に進めていきます.
いざやってみる
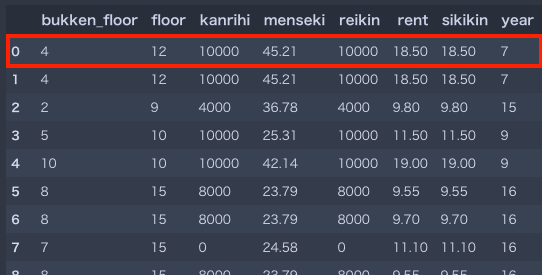
本記事では分かりやすくするために,ある1つの物件に着目しその物件との類似度を算出していきます.今回は先頭のレコード(下記赤枠)とします.
さあ,上記横方向を物件の特徴ベクトルとして各レコード(物件)とのコサイン類似度を求めていきます.結果はどうなるでしょうか.
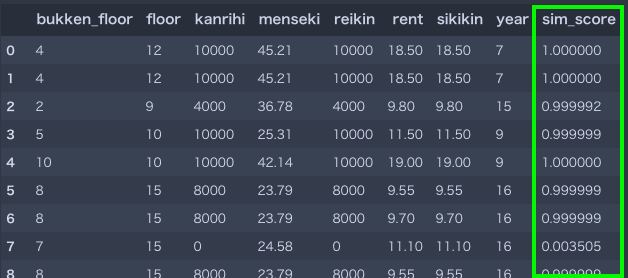
1番右が類似度です.ほとんどが1(に近い)です.「特徴量が似ているからでは?」いえいえ,ほぼ全ての物件データで1に近くなりますし,上の例でも家賃が2倍近く離れていても(レコード2)類似度がほぼ1です.
どこに原因があるのでしょう.
ベクトルの中心化
ここで分かりやすくするためにあるベクトルを例にとってみます.
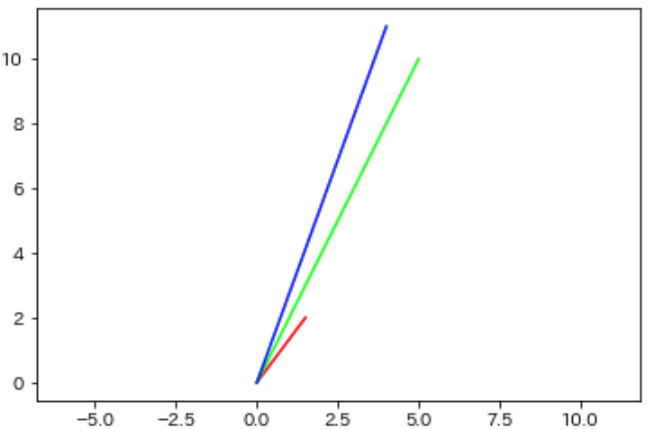
これらのベクトルは「似ている」でしょうか.「直感的」には青ベクトルと緑ベクトルは似ていますが,赤ベクトルはそれらと比べると似てないように見えます.では「コサイン類似度的」に似ているでしょうか.下記がコサイン類似度です.
"""
|赤-赤,赤-青,赤-緑|
|青-赤,青-青,青-緑|
|緑-赤,緑-青,緑-緑|
"""
array([[1. , 0.98386991, 0.95688058],
[0.98386991, 1. , 0.99340894],
[0.95688058, 0.99340894, 1. ]])
対角成分は同じであることに注意してください.青-緑(緑-青)はもちろん高いですが,赤-◯(◯-赤)も負けじ劣らず高いです.これはコサイン類似度の定義が向きしか考慮していないからです.
この問題を解決するために良く用いられる方法がベクトルの中心化です.定義は下記です.
\cos \theta = \frac{\sum_{i=1}^n (x_i - \overline{x})(y_i - \overline{y})}{\sqrt{\sum_{i=1}^n (x_i - \overline{x})^2} \sqrt{\sum_{i=1}^n (y_i - \overline{y})^2}}
コサイン類似度との違いは平均値を表す$\overline{x}$(および$\overline{y}$)が元データから減算されているところです.そしてこの式こそが相関係数を表し数学的に同じ意味であることを示します.
ではベクトルを中心化します.
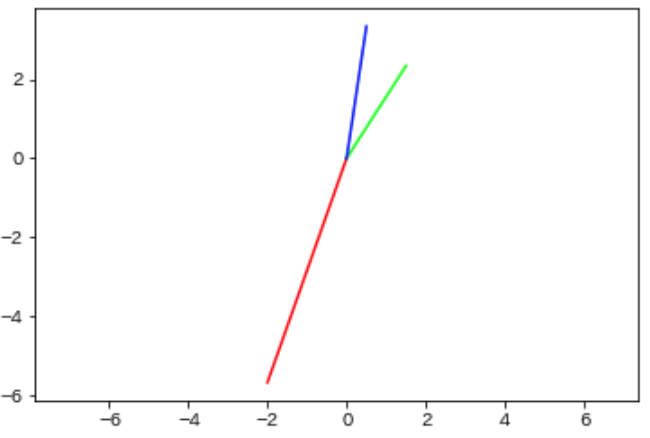
今度は赤ベクトルと他ベクトルとの類似度が低そうです.下記が算出したコサイン類似度です.
"""
|赤-赤,赤-青,赤-緑|
|青-赤,青-青,青-緑|
|緑-赤,緑-青,緑-緑|
"""
array([[ 1. , -0.97319818, -0.98192811],
[-0.97319818, 1. , 0.9120882 ],
[-0.98192811, 0.9120882 , 1. ]])
青-緑(緑-青)は高く,赤-◯(◯-赤)が低くなりました.中心化によりベクトルの大きさも考慮されていることが分かります.
ちなみにデータを1つ増やしてみます.
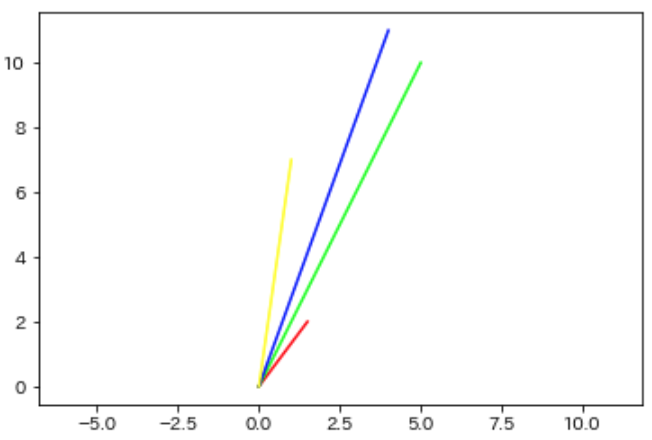
黄ベクトルが追加されました.まだ中心化はしていないです.
中心化してみましょう.
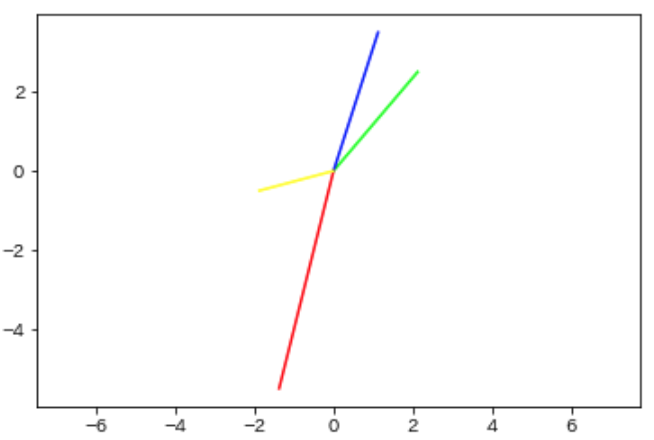
やはりベクトルの大きさが情報として追加されていそうです.
ここで注目したいのが元々の赤/緑/青ベクトルについてです.黄ベクトルを追加する前後で中心化されたベクトルを比べると微妙に変化していることが分かります.これは中心化は各データの平均値を減算するからに他なりません.今回で言えば黄色ベクトルによって各データ(の各特徴量)が影響を受けた形になります(もちろん黄ベクトルも他のベクトルから影響を受ける).中心化はそうやってそれぞれのデータに影響を与えあっています.すると,中心化はデータ全体における相対的な立ち位置を示すということが見えてきます.
例を挙げましょう.
例えばテストの点数が「60点」だった場合に,隣の人が80点だとした場合「私はなんて低いんだ!」となります.しかし周り見渡すとほとんどが50点程度なら自分の点数が高い「層」だということが分かります.その場合80点の人との類似度が高くなり,他の50点の人との類似度が低くなるでしょう.つまり全体の中でみたときに私とあなたは類似しているのかという視点で捉えることができます.これは「似ているか似ていないか」はあくまで相対的にしか判断できないという本質をついています.
さあ中心化により上手く行きそうな気がしてきました.
では中心化した上でコサイン類似度を算出してみましょう.結果はどうなるでしょうか.
なかなか薄情な結果です.1に近い値は減りましたが反対に-1付近が頻発しています.類似しているものとしていないもので白黒はっきりしていますがもう少し「近さ」に連続性が欲しいところです.
どこに原因があるのでしょう.
特徴量の正規化
ここで分かりやすくするために**[物件自体の階数, 管理費]**カラムを取り出してみましょう.
試しに3つの物件のレコードを抽出します.
array([[ 12, 10000],
[ 10, 24500],
[ 11, 9000]])
物件自体の階数(以下:階数)はせいぜい2桁,管理費は4桁〜5桁のデータです.ベクトルをプロットしてみます.
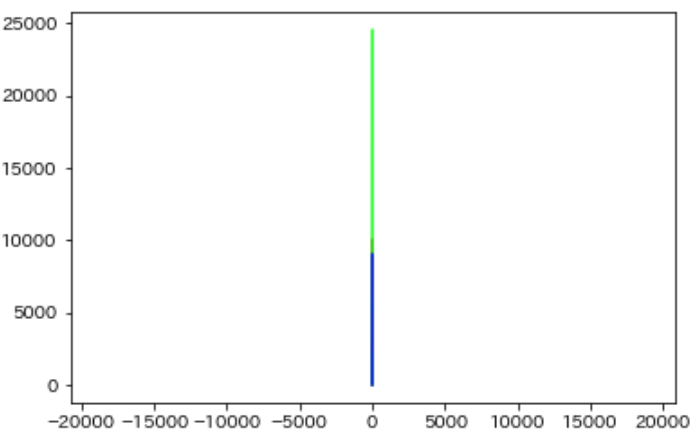
ほとんど同じ向きです.当然の結果です.では中心化したものはどうでしょう.
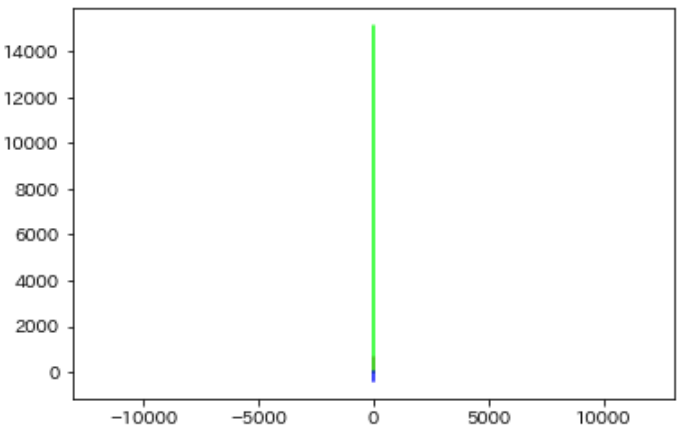
同じく直線的です.ただし青ベクトルは反対向きに見えます.反対向きだろうがほぼ直線に並んでいるので,当然類似度は1か-1になります.
原因は明白です.**特徴量のスケールが大きく異なるからです.この場合正規化が有効です.**この特徴量を正規化する手法として,Min-Maxスケーリングを使ってみます.Min-Maxスケーリングは特徴量ごとに[0, 1]に収まるようにスケーリングします.先ほどのベクトルをスケーリングすると,
array([[0.19230769, 0.40816327],
[0.11538462, 1. ],
[0.15384615, 0.36734694]])
となりました.プロットしてみましょう.
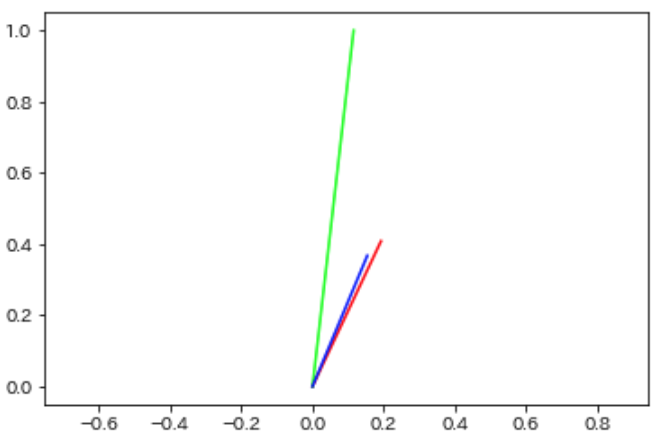
直線に並ぶことがなくなりました.ただし中心化していないため,大きさを考慮できていません.向きが同じであれば類似度が高くなります.これは「物件自体の階数と管理費がそれぞれ同じ倍数の物件は類似している」ということになってあまり良くなさそうです(また,ここが文書カテゴリの類似度と考え方が異なると言った理由です.文書では倍数になろうが「同じカテゴリの文書」として分類することが一般的です).中心化してみます.
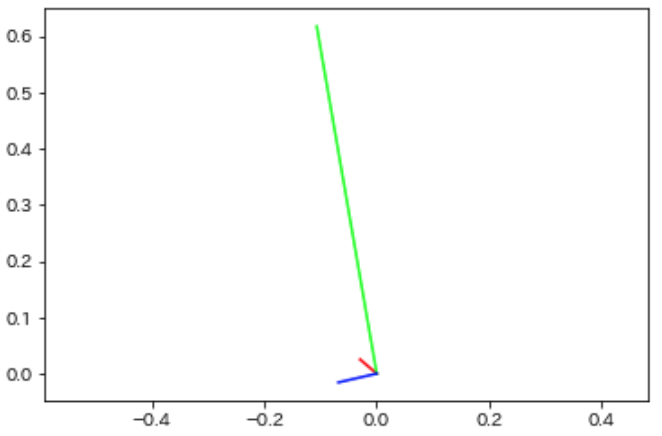
大きさを考慮できていそうです.
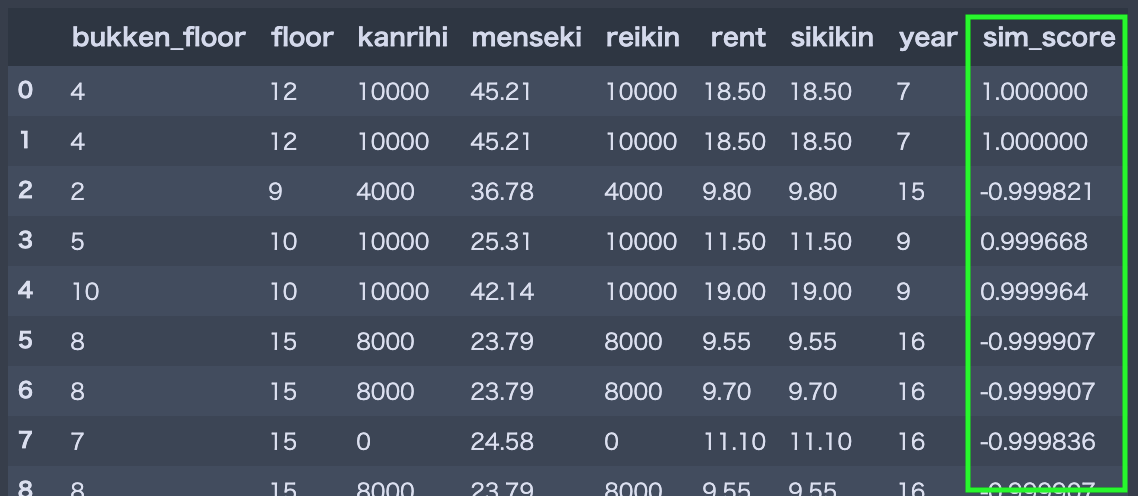
ちなみに**[物件自体の階数, 管理費]カラムのみに着目しMin-Maxスケーリングかつ中心化**した後にコサイン類似度を求めた上位数件の結果です.
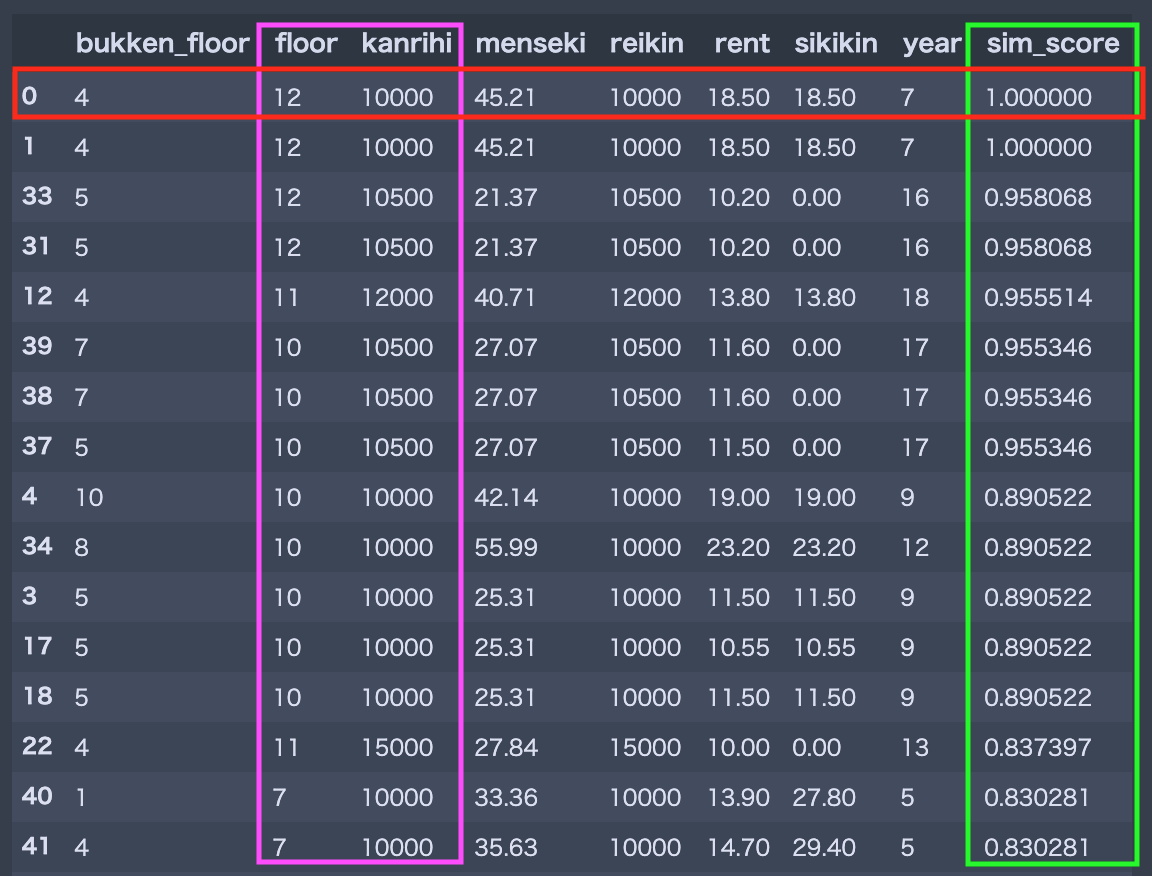
ピンク色が類似度計算に利用しているカラム,緑色がスコアです.赤色が類似度計算の対象元となっている物件です.確かにピンク色の特徴量について近そうな物件が上位にきてますし,スコアの粒度も細かいです.これであれば「類似している!」と自信を持って言えそうになってきました.
では,全てのカラム(特徴量)に着目して類似度を計算してみます.結果はこちらです.
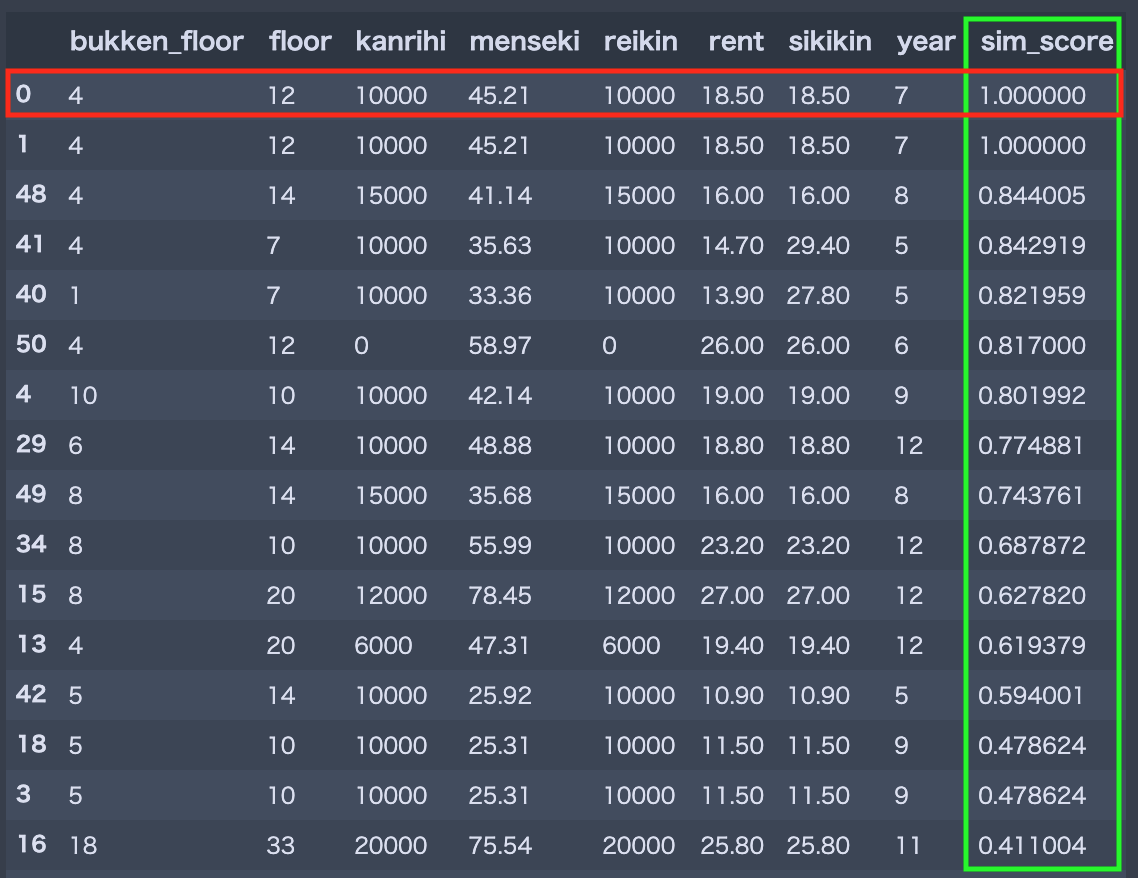
いかがでしょうか.値が大きな特徴量に引っ張られることなく,かつ全ての特徴量に対して満遍なく類似している物件が上位にきていると言えるのではないでしょうか.データ数をもっと増やせばより選別された物件が取得できそうです.
完全ではありませんが,晴れて類似している物件はこれだと自信を持って言えそうです![]()
対数スケーリングについて
本記事では触れませんが,ある特徴量の分布に偏りがある場合はその特徴量を対数スケーリングしてからMin-Maxスケーリングした方が良いかもしれません.これはデータが密集している箇所では細かい変化が重要なケースが多いと思いますが,Min-Maxスケーリングだけではその変化を掴みきれないからです.対数スケーリングは一般的なデータ分析においても良く用いられる前処理です.
留意事項
留意していただきたいのは,今回は各特徴量の数値を画一的に扱っていることです.例えば「家賃と階数の重要度は全然違う!!」などの意見があるでしょう.そういった場合は,全ての特徴量を1つのベクトルにするのではなく,重要な特徴量を分離して重み付けするなどの対応方法などが考えられます.
また,類似度計算を阻害するカラム(特徴量)は省くべきでしょう.例えば「階数」が物件の類似度を考慮する上であまり重要でない場合積極的に省きましょう.
さらに,一般的に特徴量の数が多くなると類似度は低くなりやすいです.例えば数十次元の特徴量ベクトルの類似度が1に近くなることは非常に稀です.ですので特徴量の数は「類似している」と判断するための閾値の決め方にも影響してくるでしょう.
いずれにせよこれらはビジネス側の実用途を踏まえた上で慎重に吟味する必要があるでしょう.estieでも実用途を踏まえた上で微調整しながら最適解を導く努力を続けています![]()
まとめ
本記事では,
- アイテムの基本的な属性情報を元に類似度を定義する方法について考察してみました.
- Min-Maxスケーリングと中心化によりある程度アイテムの類似度を算出できることがわかりました.
- 類似度計算に使うカラム(特徴量)や閾値の選定は実用途に応じて選定しましょう.
次はあなたの番です.何か知見があれば共有いただけると幸いです.