初めに
JavaScript / TypeScript にまつわる豆知識を、10 個ほど集めてみました。
コードは全て TypeScript で書いていますが、内容はほぼ全て JavaScript にも当てはまることです。
少し長めの読み物ではありますが、気軽に当記事を楽しんで頂ければ幸いです。
それでは、以下が目次です。
1.Nullish と Falsy
最初に、nullやundefinedを扱う時に少し便利になる演算子を取り上げます。
基本的には数値型を、しかし例外的に undefined を返すような関数 $f(x)$ を考えてみます。なんでも良いのですが、以下を具体例とします。
function f(x: number): number | undefined {
if (x !== 0) {
return (x - 1) / x;
} else {
return undefined;
}
}
このような関数の評価結果を、undefinedの混入を許さずに全て数値型で扱いたい、具体的には undefined が返ってくる場合は 999 などの適当な数値で例外処理をしたい、ということはよくあると思います。
ここで、一部の他言語などでも汎用的に使える手段の一つに、論理和演算子|| を用いた短絡評価が挙げられます。
console.log(f(2));
// 結果: 0.5
console.log(f(0));
// 結果: undefined ← 例外処理したい
console.log(f(2) || 999);
// 結果: 0.5
console.log(f(0) || 999);
// 結果: 999 ← 例外処理されている!
undefinedが Falsy、つまり偽値なので、その場合に限り||の後ろ側の値が評価されるという仕組みです。bash などの三項演算子がない言語や、コードゴルフなどでよく目にする書かれ方です。
しかし、 この手法の困ったこと としては、以下のような状況が挙げられます。
console.log(f(1));
// 結果: 0 ← 正常に数値型が返って来ている
console.log(f(1) || 999);
// 結果: 999 ← 例外処理されてしまっている!?
つまり、undefined以外の偽値、 0や""までもが例外処理をされてしまう という事です。
これが実現したいことになる場合もありますが、今回はそうではないとします。そうすると、三項演算子を用いるしか道がなさそうに思えます。(事実、一部言語は他に手段がありません)
しかし、三項演算子を用いると、関数名が長い場合は可読性が下がったり、関数呼び出しを2回する必要があったり、一時変数を用意したり、いろいろと面倒です。
そこで役立つのが Null 合体演算子 (Nullish coalescing operator)である ?? です。
この演算子は Nullish 、つまり、値が null または undefined のいずれか の時のみ、演算子の右にある値を返します。
console.log(f(1));
// 結果: 0 ← 偽値(0)を返す場合でも、
console.log(f(1) ?? 999);
// 結果: 0 ← 例外処理をしない!!
また、 Null 合体代入 (Nullish coalescing assignment)(??=)もあります。
let x = null;
x ??= 1;
機能自体はなんてこと無いものではありますが、短絡評価を発展させて使おうとする創造性、null や undefined を抱えながらそれを少しでも安全に扱おうとする努力が垣間見えるような気がして、私は数ある演算子の中でもこれが最も好きです。
ところで、Truthy, Falsy という概念は非常に面白いなと私は思っています。先程に触れた論理和演算子||による例外処理も、これが返り値として論理値以外の値を取り得るという事に依拠しており、C++などではそうはいきません。暗黙な型変換により論理値しか返ってこないからです。
しかし、それ故に Falsy には一種の罠も存在します。
一つ例を挙げてみます。
以下は Python のコードですが、list である Xs の値を後ろから順に pop して while 文を回していこうとしています。特に、while 文の条件式に当たる while Xs という部分に注目して下さい。このコードは正常に動作します。
Xs = [1, 2, 3]
while Xs: # 注目!
print(Xs.pop())
# Output: 3 2 1
また、C++では while(Xs) と書くと、expression must have bool type (or be convertible to bool) というコンパイルエラーが出てきます。つまり、!Xs.empty() などを用いて bool 型に変換する必要があります。
では、TypeScript でもこのような while 文を書いてみます。
const Xs = [1, 2, 3];
// 注目!
while (Xs) {
console.log(Xs.pop());
}
すると 警告などは一切出ず、トランスパイルも正常に行われるので、じゃあこれは Python と同様に大丈夫なのかなと 思わず油断するのですが……
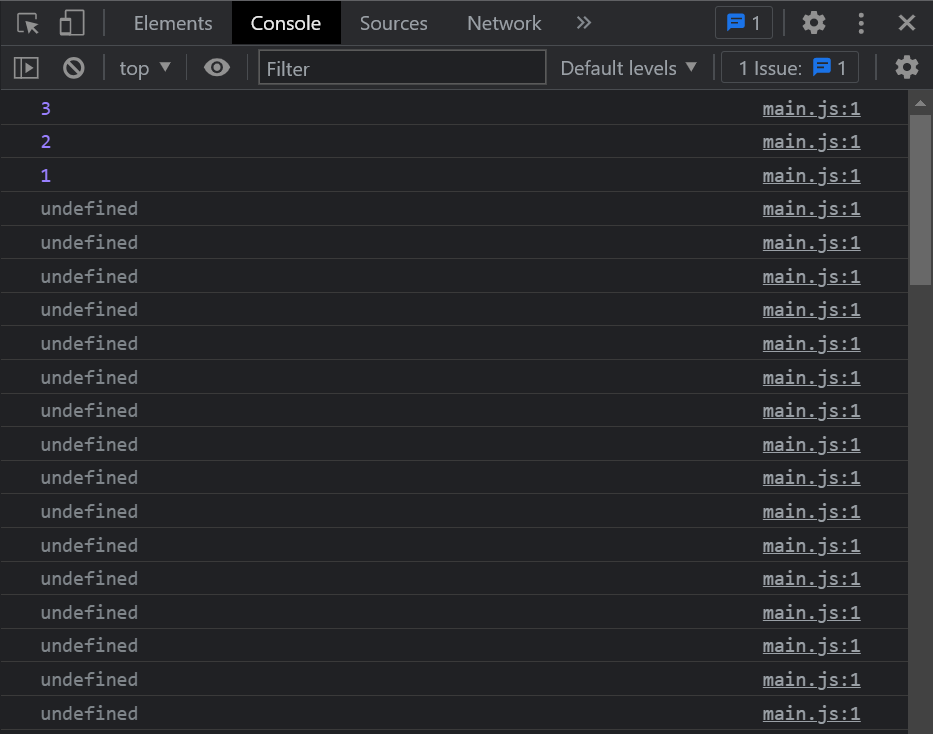
ご覧の通りの undefined の嵐になります。
理由は TypeScript において空の配列は Falsy ではないからです。この条件式だと、Xs の中身に関わらず常に真と判定されます。Pythonとの大きな違いです。なお、while (Xs.length)などとすれば正常に回ります。
型検査で全く引っかからないという点もあり、私がついついやらかすミスの一つです……。
Nullish とも Falsy とも、上手に仲良く付き合っていきたいものですね。
関連参考資料_1
2. tsconfig の便利な設定
この節だけは TypeScript 固有の話を書きます。
tsconfig の"compilerOptions"は"strict": trueとしただけでは、最も多くの警告やエラーを出力する訳ではない、ということはご存じの方も多いかと思われます。
しかし、私自身最近まで、(面倒くさがって"strict": trueだけで放置していたせいもあり) tsconfig でどこまで何が設定できるのかはあまり知りませんでした。
これについては、見やすくなったと噂の公式ドキュメントを見ることで確認出来ます。
ここでは、上記サイトの情報を基に、"Type Checking"に関するDefault:true if strict, false otherwise.と 書かれていない 項目、つまり "strict": trueだけではアクティブにならない項目 を、簡単にではありますが以下に列挙します。
| 名称 | 大雑把な説明(詳細には上記リンク参照) |
|---|---|
| allowUnreachableCode | 到達不可能なコード(dead code)を警告 |
| allowUnusedLabels | 未使用の Label について警告 |
| exactOptionalPropertyTypes | ?付きで宣言されたプロパティへの undefined 代入を不可能にする |
| noFallthroughCasesInSwitch | switch 文の break 忘れなどを警告 |
| noImplicitOverride | override というキーワードなしでの override を警告 |
| noImplicitReturns | 関数内での return 忘れを警告 |
| noPropertyAccessFromIndexSignature | dot 記法(obj.key)と index 記法(obj["key"])を区別する |
| noUncheckedIndexedAccess | 型の未定義のフィールドに undefined が追加される |
| noUnusedLocals | 利用されていないローカル変数を警告 |
| noUnusedParameters | 利用されていない関数のパラメータを警告 |
(出典: Microsoft. "Compiler Options". TypeScript. 2022 年 12 月 20 日. https://www.typescriptlang.org/ja/tsconfig#compilerOptions, (最終閲覧日: 2023 年 1 月 10 日)(抜粋・翻訳は筆者による))
コピペ用
{
"allowUnreachableCode": false,
"allowUnusedLabels": false,
"exactOptionalPropertyTypes": true,
"noFallthroughCasesInSwitch": true,
"noImplicitOverride": true,
"noImplicitReturns": true,
"noPropertyAccessFromIndexSignature": true,
"noUncheckedIndexedAccess": true,
"noUnusedLocals": true,
"noUnusedParameters": true,
}
主観ではありますが、allowUnreachableCode(到達不可能なコード(dead code)を警告)、exactOptionalPropertyTypes(?付きで宣言されたプロパティへの undefined 代入を不可能にする)、noUnusedParameters(利用されていない関数のパラメータを警告)辺りは特に便利だなと思います。
また、個人的に重宝しているのが、 noUnusedLocals という項目です。
日本語版の公式ドキュメントでは「利用されていないローカル変数について、エラーを報告します」とさっぱりした説明になっていますが、個人的には、 不必要な import を警告の形で検出できる という点が非常にありがたいです。
[設定しない場合(ただ暗くなっているだけ)]

[設定した場合(エラーとして下線が引かれる)]

(import "./path"形式のものは、利用しているかどうかに関わらないのでどちらにおいても何ら警告は出ません)
また、これらの警告は 以下のコメントで抑制することも可能です 。
// @ts-ignore: 無視する理由などをここに書けます。
[コメント無し]

[コメント有り]

しかし、tsconfig の設定を変える以上は、警告などをあまり抑制しても意味がなく、
Please note that this comment only suppresses the error reporting, and we recommend you use this comments very sparingly .
(出典: Microsoft. "TypeScript 2.6"(release notes). TypeScript. 2022 年 12 月 19 日. https://www.typescriptlang.org/docs/handbook/release-notes/typescript-2-6.html#suppress-errors-in-ts-files-using--ts-ignore-comments, (最終閲覧日: 2023 年 1 月 9 日)(強調の太字は筆者による))
とある通り、 控え目に このコメントは使用した方が良さそうです。
関連参考資料_2
3. 依存関係の綺麗な図示の仕方
先程、未使用な import へ警告を出す方法に触れましたが、それと合わせて便利なツールを一つ紹介します。
それがプロジェクトの依存関係を分かりやすく図示してくれるツール、 Dependency cruiser です。
これは、JavaScript、TypeScript、LiveScript、そして、CoffeeScript によるプロジェクトの依存関係を調べた上で、
- (あなた自身が定めた)ルールに沿うかどうか検証します
- そして、その規則に違反したものを以下の方法で報告します
- テキスト (ビルド用)
- 画像 (目で見る用)
また、副次的な効果として、依存関係のグラフを様々な出力形式で生成可能で、あなたのおばあちゃんを感動させるようなクールなビジュアライゼーションをも生み出せます。
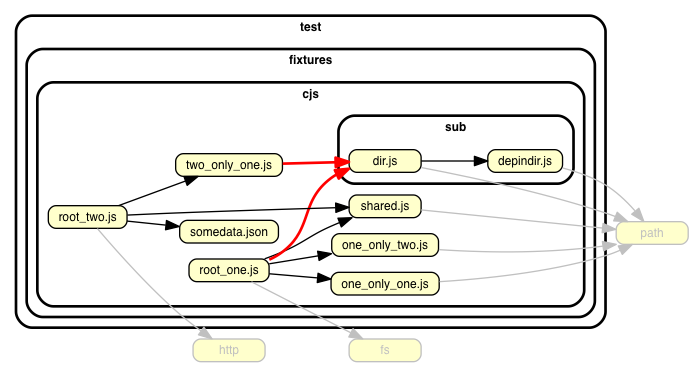
(出典: sverweij. "dependency-cruiser README.md". GitHub. 2022 年 12 月 21 日. https://github.com/sverweij/dependency-cruiser/blob/develop/README.md, (最終閲覧日: 2023 年 1 月 8 日)(翻訳は筆者による))
このレポジトリは、 MIT ライセンスで公開されており、2023 年 1 月現在、 3.4k 個もの stars を集めています。また 現在でも更新が続いています 。
npm や yarn 等で簡単に install 可能です。詳しくはレポジトリの README.md をご覧下さい。
基本的に、このようなツールはかなり大規模なプロジェクトに対してこそ役に立つものだとは思うのですが、小中規模なモノに対しても十分効果があると思います。実際ありました。
特にファイルなどが階層構造を成している時に、それらを 綺麗に階層ごとに分けて表示してくれる というのが個人的感動ポイントです。フォルダを直接見るだけでは限界がある依存関係のゴチャゴチャを、綺麗さっぱり見せてもらうことで、頭も整理されて開発が捗るのではないでしょうか。
気になった方は是非このレポジトリ自体もご覧いただければと思います。
ここでは触れきることの出来ない非常に豊富な機能は、見ているだけでも面白いです。
ちなみに、似たような別ツールに、madgeもあります。こちらも分かりやすそうです。
関連参考資料_3
4.正しい XSS のやり方
XSS (cross-site scripting)、つまり、web アプリケーションの脆弱性を利用した攻撃の手段として、よく<script>for(;;){alert(1)}</script>などが挙げられます。
実際、数年前その話がニュースになったこともありました。
さて、私はそんなある日、この聞きかじりの知識を記憶の引き出しにしまいながら、以下のようなコードを眺めていると、ふとあることに気付きました。
「innerHTML が誤って使われている……!!」
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<title>Infinite Alert</title>
</head>
<body>
<!-- この入力を受け取って -->
<input type="text" />
<!-- その内容を"そのまま"以下に表示する -->
<div></div>
</body>
</html>
const inputElem = document.querySelector("input") as HTMLInputElement;
const divElem = document.querySelector("div") as HTMLDivElement;
inputElem.addEventListener("change", (e) => {
// 内容を表示させようとしているが、
// これは誤ったinnerHTMLの使用!!
divElem.innerHTML = (e.target as HTMLInputElement).value;
});
普段だったらさっさと直すところですが、何故かこの時は、ふと XSS を一度くらい手元で起こして、動作確認をしてみてもいいかな、という気分になり、実際に入力を与えてみました。
まず普通に入力を与えてみると、
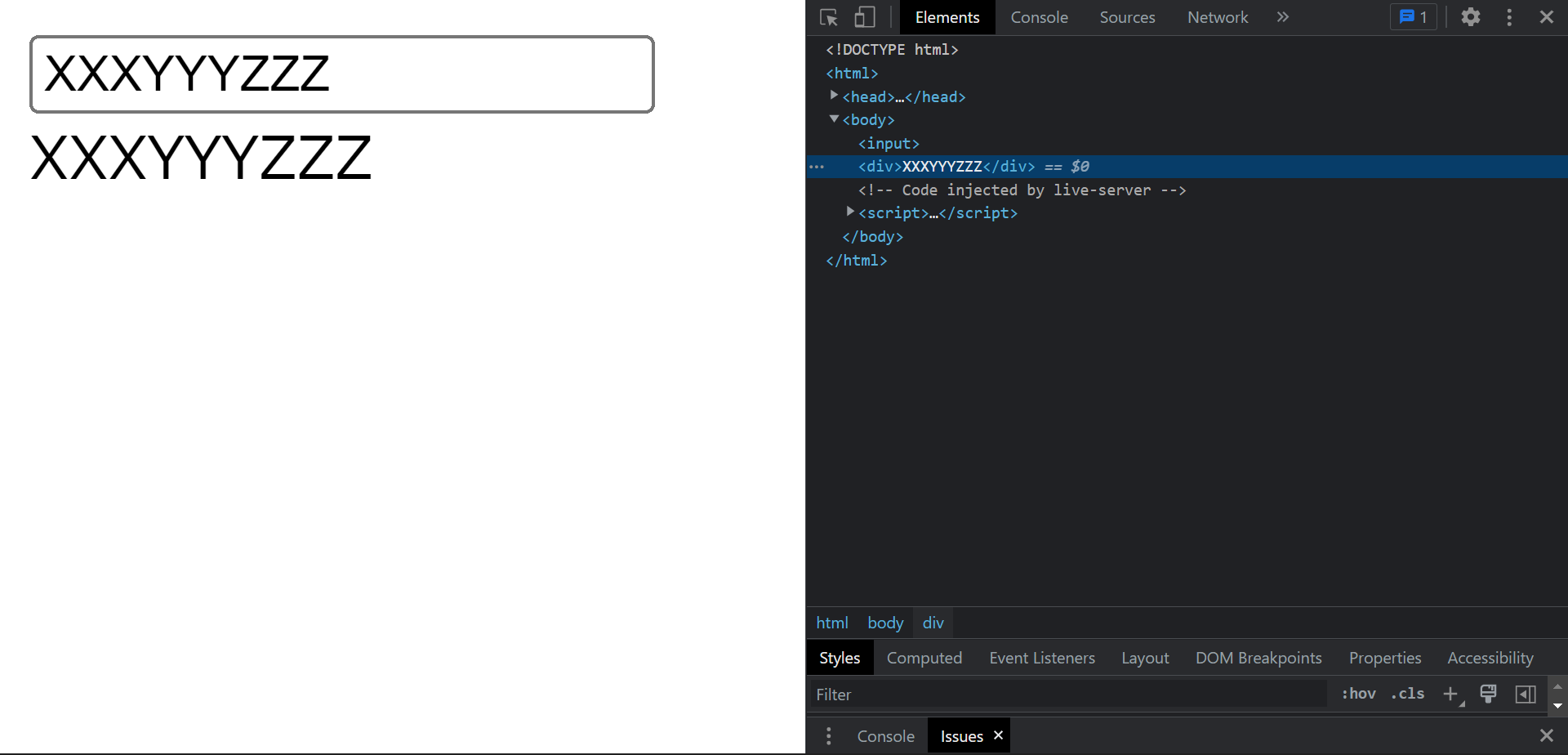
と確かに入力が表示されます。
そして、h1 タグなどを入力すると、
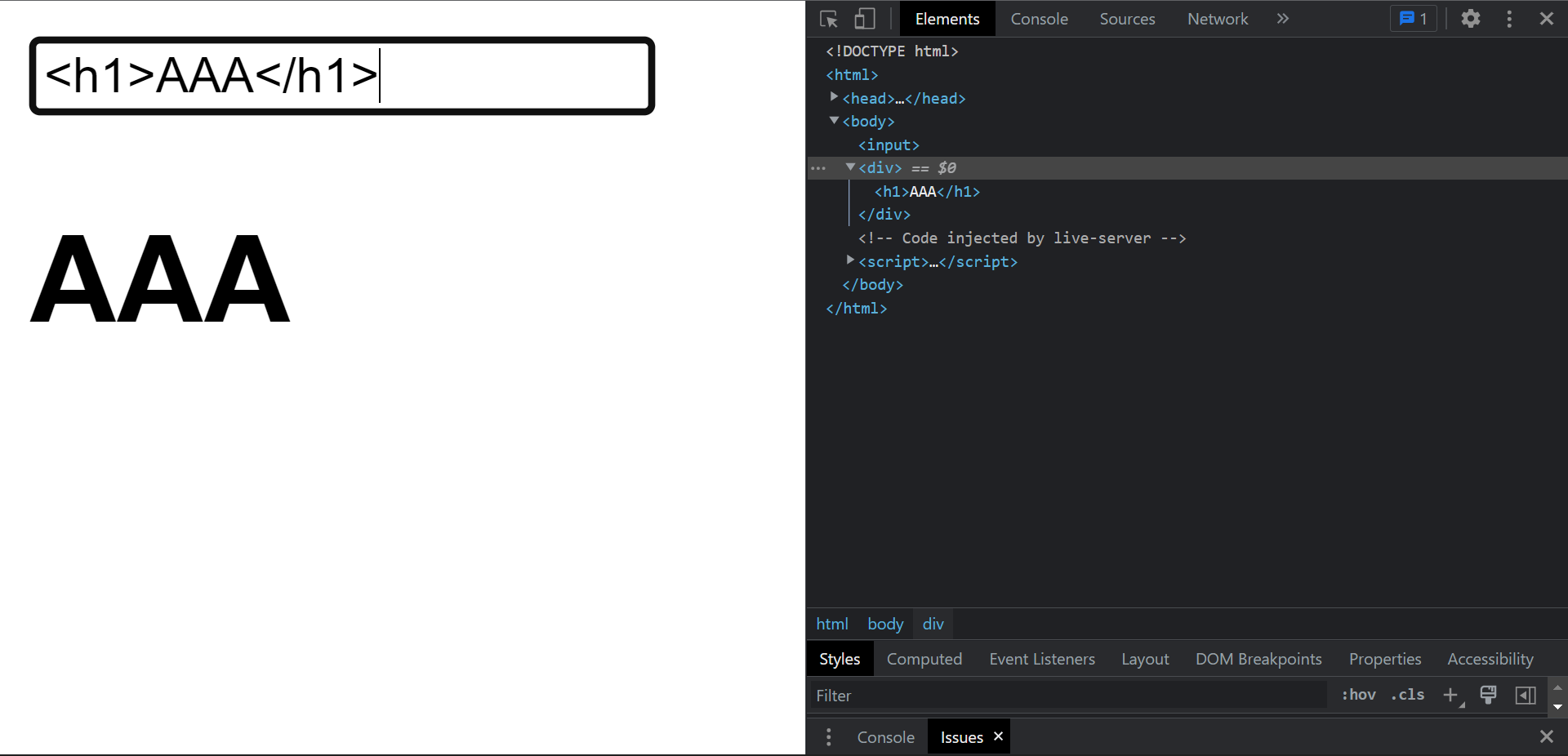
これも確かに h1 タグとして受理されてしまって、本来の仕様とは違う動作をしてしまっていることが分かります。
では、<script>for(;;){alert(1)}</script>を与えると、
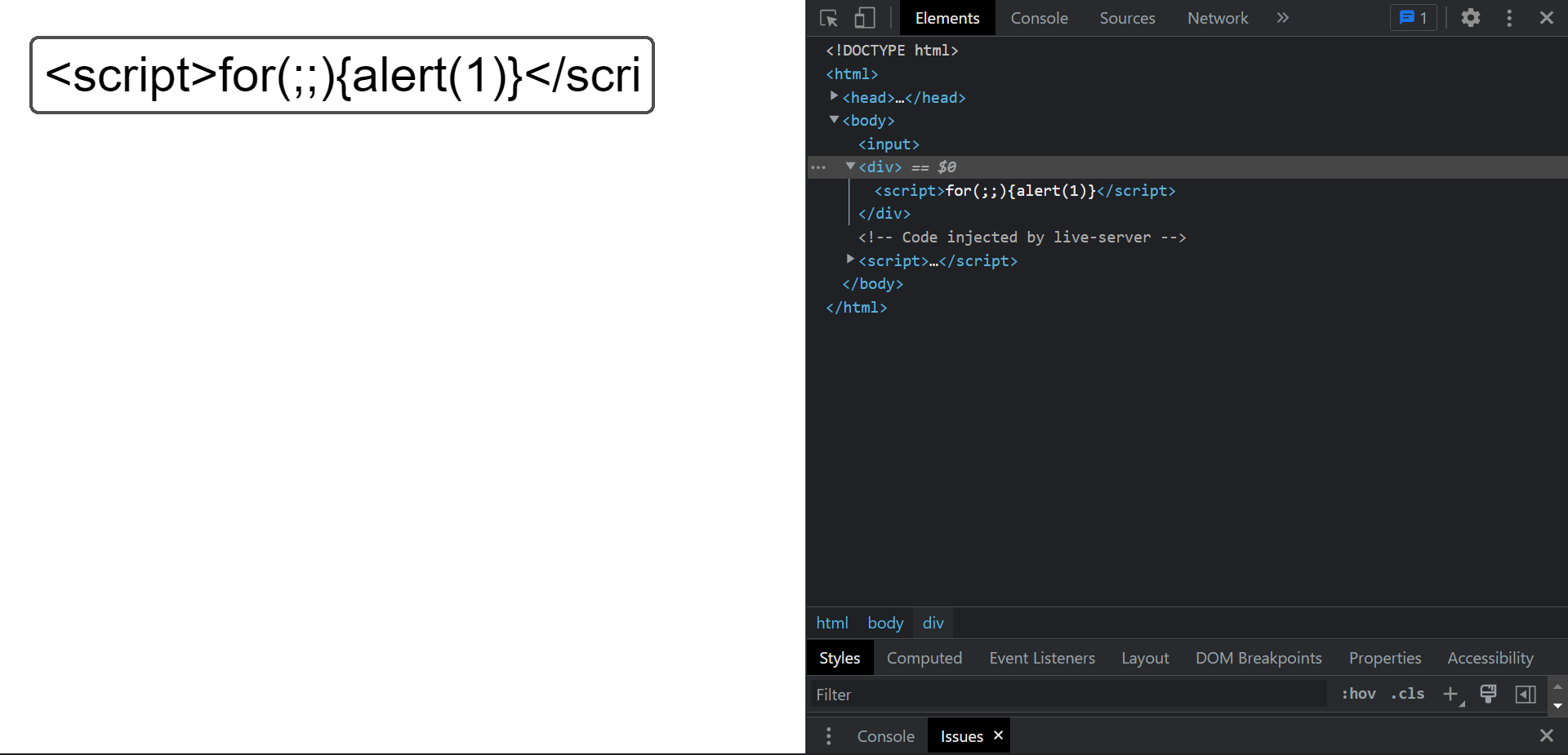
何も表示されないことが分かります。
script タグは元々文字としては表示されないので、
Elements 自体の更新は正しく行われていることが分かります。
ただ、alert(1)が出てこないことを見るに、innerHTML を用いて挿入された script elements は、挿入時にはその内容が実行されないと推測されます。
つまり、表面上このコードではXSSは起こせない、ということになります。これは正しい認識なのでしょうか?
実はこれは誤りです。実際、この例においては、 <img src="X" onError="for(;;){alert(1)}">という、存在しない画像へのリンクを持ち、ロードに失敗した時に無限アラートを表示させる img タグを与えてみると、
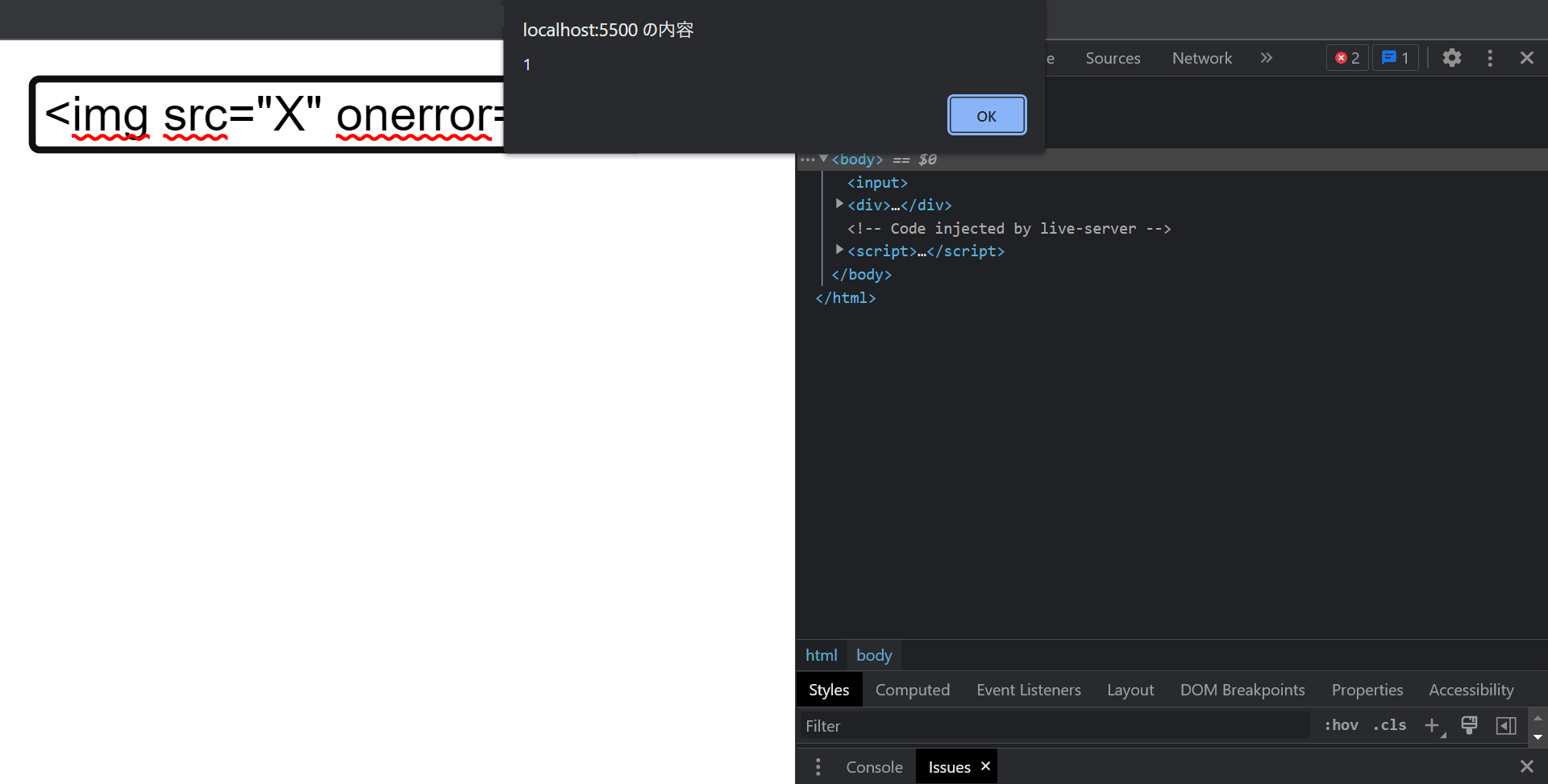
このように、alert が出てきてくれて、無事に(?)攻撃出来ました。
先の実例に補足します。
実は、「 innerHTML を用いて挿入された script elements は、挿入時にはその内容が実行されない 」ということ自体は 正解 です。
これは W3C にもきちんと記されていることです。
Note: script elements inserted using innerHTML do not execute when they are inserted.
(出典: W3C. "2. The Document Object Model". W3C. 2008 年 10 月 6 日. https://www.w3.org/TR/2008/WD-html5-20080610/dom.html#innerhtml0, (最終閲覧日: 2023 年 1 月 8 日))
ただ、それが全ての悪意ある入力を無害化してくれるという認識は誤りです。その一例が<img src="X" onError="for(;;){alert(1)}">であり、このことは MDN にもきちんと記載がある、れっきとした仕様です。また、img の代わりに svg、onError の代わりに onLoad なども使えます。
そもそも、 XSS をわざわざ起こしてやろうという気になる方は少ないように思われたので、(誤った使い方における)innerHTML の危険性よりは、知名度が低そうな事実だなと思い今回は選んでみました。(尤も、CTF とかをやっている方からすれば常識でしょうか?)
なお、これの改善方法としては、IPA による「安全なウェブサイトの作り方」にもある通り、「ウェブページに出力する全ての要素に対して、エスケープ処理を施す」ことや、MDNにもある通りelem.setHTML()やelem.textContent などを代わりに使うことなどが挙げられます。
関連参考資料_4
5.removeChildren
HTML の DOM element の中身を空にしたい時、(React などを除いて)最も良く使われる手法は
elem.innerHTML = "";
かと思われます。
しかし、実は同じことが
elem.replaceChildren();
でも出来ます。
elem.replaceChildren()は elem の子ノードを、引数で指定された新しい一連の子で置き換えるというモノなので、空に置き換える、つまり、ノードを空に出来るという仕組みです。
このメソッドは比較的最近、 全てのブラウザで対応 されてるようになっており、MDN のブラウザーの互換性の項からも分かる通り、Chrome/Edge 86+、 Firefox 78+、 Safari 14+ などで対応されています。
そして、ノードを空にするという使い方も、MDN で言及されており、これは 想定されている使用方法 です。
要するに、安心してこの方法が使えます。
ただ、検索のトップには前者の方法が来ることがやはり多いと思いますし、最近までは一部のブラウザにしか対応されていなかったため、知名度は低そうです。
また、この方法について、DOM Standardに記載されている内部的な実行手順から、他の手法より速いという言説(関連参考資料参照)もありますが、それを「明確に」保証するような記述は私の調べた限り存在しない様に思われます。
この点について、少し気になったので実際に簡易的な計測をしました。
計測手法の詳細
まず、下図のように合計大体 1000 行程のダミー要素を生成して、それを消去するということを繰り返します。

より現実的な状況を再現するためにも、各関数の呼び出しはボタンに紐づけて行い、それぞれ 50 回ほどポチポチして時間を計測しました。
実験環境としては、
- OS: Windows 11 Home
- ブラウザ: GoogleChrome バージョン:108.0.5359.125(Official Build) (64 ビット)
です。
以下にコードを載せます。
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<title>innerHTML vs. replaceChildren</title>
</head>
<body></body>
</html>
const BUTTON1 = document.createElement("button");
BUTTON1.textContent = "gen";
BUTTON1.addEventListener("click", gen);
const BUTTON2 = document.createElement("button");
BUTTON2.textContent = "innerHTML";
BUTTON2.addEventListener("click", eraseByInnerHTML);
const BUTTON3 = document.createElement("button");
BUTTON3.textContent = "replaceChildren";
BUTTON3.addEventListener("click", eraseByReplaceChildren);
const NODE = document.createElement("div");
NODE.style.backgroundColor = "lightgray";
document.body.appendChild(BUTTON1);
document.body.appendChild(BUTTON2);
document.body.appendChild(BUTTON3);
document.body.appendChild(NODE);
function gen() {
for (let _ = 0; _ < 100; _++) {
const TEXT = document.createTextNode("dummy text. ".repeat(Math.random() * 10));
NODE.appendChild(TEXT);
const DIV = document.createElement("div");
DIV.textContent = "dummy div. ".repeat(Math.random() * 10);
NODE.appendChild(DIV);
const SPAN = document.createElement("span");
SPAN.textContent = "dummy span. ".repeat(Math.random() * 10);
const UL = document.createElement("UL");
for (let _ = 0; _ < 5; _++) {
const LI = document.createElement("LI");
LI.textContent = "dummy li. ";
UL.appendChild(LI);
}
NODE.appendChild(TEXT);
NODE.appendChild(DIV);
NODE.appendChild(SPAN);
NODE.appendChild(UL);
}
}
function eraseByReplaceChildren() {
const start = performance.now();
NODE.replaceChildren();
const end = performance.now();
console.log(`eraseByReplaceChildren: ${end - start}`);
}
function eraseByInnerHTML() {
const start = performance.now();
NODE.innerHTML = "";
const end = performance.now();
console.log(`eraseByInnerHTML: ${end - start}`);
}
以下が実験結果の図示用コードです。
import numpy as np
import matplotlib.pyplot as plt
_innerHTML = []
_replaceChildren = []
with open("src/times.txt") as f:
for i in range(100):
name, time = f.readline().split()
assert(name == ("eraseByInnerHTML:" if i %
2 == 0 else "eraseByReplaceChildren:"))
time = float(time)
if i % 2 == 0:
_innerHTML.append(time)
else:
_replaceChildren.append(time)
innerHTML = np.array(_innerHTML)
replaceChildren = np.array(_replaceChildren)
plt.bar([0, 1],
[innerHTML.mean(), replaceChildren.mean()],
yerr=[innerHTML.std(), replaceChildren.std()],
tick_label=['innerHTML', 'replaceChildren'],
error_kw={"lw": 1, "capthick": 1, "capsize": 20})
plt.title("innerHTML vs. replaceChildren")
plt.xlabel("method")
plt.ylabel("average time of 50 trials [ms]")
plt.savefig("img/innerHTML_vs_replaceChildren.png")
plt.show()
(計測手法の詳細 終わり)
計測の結果、以下のように 0.1ms 程度は replaceChildren の方が遅いという結果が出ました。
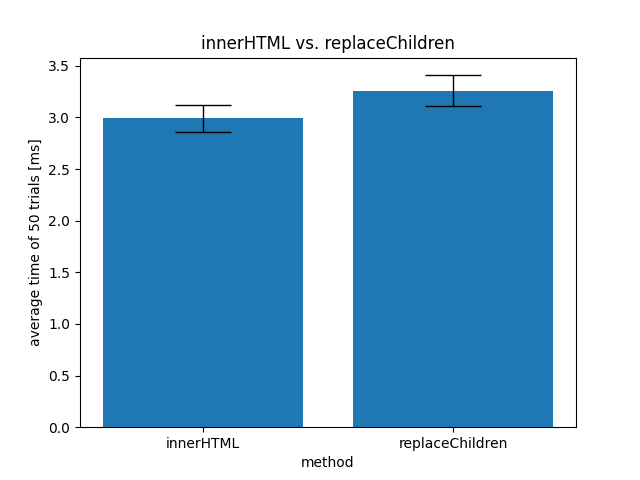
(ただし、この図のエラーバーは標準偏差を示しています。また、もしかすると、検証方法によってはreplaceChildrenの方が高速になるかも知れません。実現できた方は教えて頂けると幸いです)
しかし、かなり大量のノードを消去するとしてもなお 0.1ms 程度の差しかないのであれば、たとえあるとしてもその差は極めて軽微と言えることは確かでしょう。
innerHTML を使わなくて済む点、そして(恐らく多くの場合)速度としても遜色がない点などから、私はよく使用しています。
関連参考資料_5
6.数値型を関数の引数として使う時の小技
突然ですが、以下のような問題を考えてみます。私が過去に取り組んでいた問題をかなり簡略化したモノです。
いくつかの頂点が下図のような階層構造を成しているとします。この時、各頂点の座標(xとy)をプログラムで求めたいです。
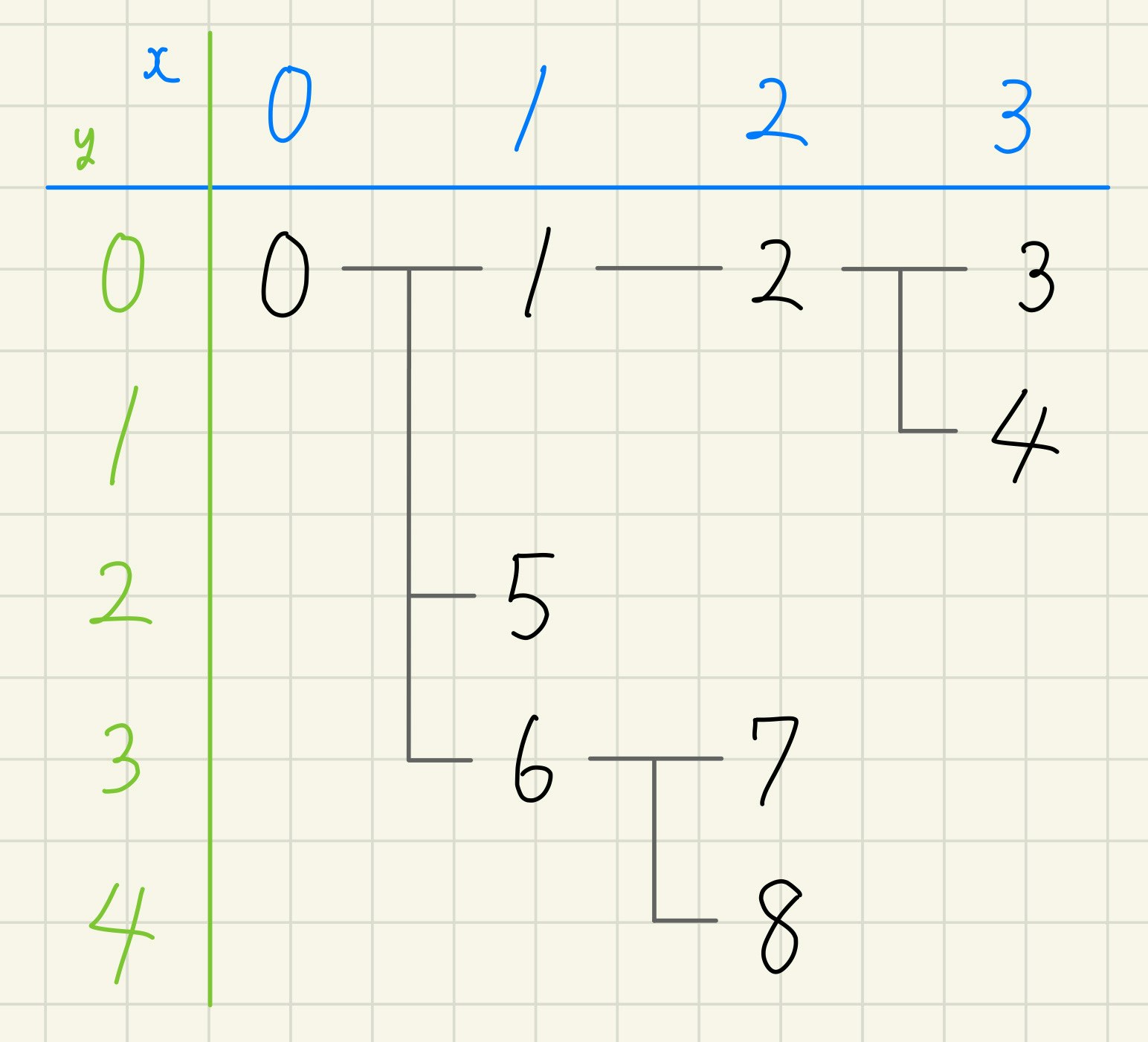
こんな時、例えば C++では数値型の参照渡し(int&)で深さ優先探索(dfs)をすると、かなり綺麗に書けます。
行きがけと帰りがけのタイミングで座標の増減を一括して管理できるのが見やすいと私は思っています。
#include <iostream>
#include <vector>
/**
* @brief 深さ優先探索で各頂点の座標を求める再帰関数
*
* @param adj 階層構造を表す隣接リスト @param ans 各頂点の計算された座標
* @param v 現在いる頂点の番号 @param x, y 暫定的な座標
*/
void dfs(const std::vector<std::vector<int>>& adj,
std::vector<std::pair<int, int>>& ans, const int v,
/* この二つが数値型の参照渡し!→ */ int& x, int& y) {
ans[v] = {x, y};
// 行きがけ時の処理
x += 1;
for (int nv : adj[v]) dfs(adj, ans, nv, x, y);
// 帰りがけ時の処理
x -= 1;
if (adj[v].empty()) y += 1;
}
int main() {
std::vector<std::vector<int>> adj{
{1, 5, 6}, {2}, {3, 4}, {}, {}, {}, {7, 8}, {}, {},
};
std::vector<std::pair<int, int>> ans(adj.size());
int x = 0, y = 0; // 初期座標
dfs(adj, ans, 0, x, y);
// 答えの確認
for (size_t i = 0; i < ans.size(); i++) {
auto [x, y] = ans[i];
std::cout << "・ 頂点番号" << i << "の座標は {" << x << "," << y << "}"
<< std::endl;
}
std::cout << "最終的な深さは" << y - 1 << "です。" << std::endl;
return 0;
}
さて、それと同様のコードを TypeScript でも書いてみます。(以下のコードは dfs の部分だけを取り出したものです)
function dfs(adj: number[][], ans: [number, number][], v: number, x: number, y: number) {
ans[v] = [x, y];
// 行きがけ時の処理
x += 1;
for (const nv of adj[v]) dfs(adj, ans, nv, x, y);
// 帰りがけ時の処理 (???)
x -= 1;
if (adj[v].length === 0) y += 1;
}
この時、x は正しい値が返って来てくれるのですが、y は誤った値が返ってきます。理由は単純で、C++で言うところの数値型の参照渡しがこれでは実現できていないからです。 帰りがけの処理に当たる部分が意味を成していません。また、このような挙動を厳密に JavaScript / TypeScript で実現することは恐らく不可能です。
そうとなれば、これを何とかしたいと思う訳ですが、その方法に私はなかなか迷いました。
(x は正しいので y だけを返り値で更新するようにしても良いですが、それだと x, y の対称性が崩れます。また、行きがけ / 帰りがけに処理がまとめられていた利点も失われてしまいます。そうとなれば、更新の必要がある数値型を全て返り値で管理しようかとも思うのですが、(今回はかなり簡略化して書いているものの)他にも色々引数が多くてそれが面倒という状況でした。また、先の C++のコードでは、main 関数内で y が関数の副作用の結果として更新されていて、それも地味に嬉しい点でした)
結論を述べると、色々と調べた結果、以下のようにするのが恐らく今回は最適だろうとなりました。
+ interface XY {
+ x: number;
+ y: number;
+ }
- function dfs(/*中略*/, x: number, y: number) {
+ function dfs(/*中略*/, xy: XY) {
則ち、
interface XY {
x: number;
y: number;
}
function dfs(adj: number[][], ans: XY[], v: number, xy: XY) {
ans[v] = Object.assign({}, xy);
// 行きがけ時の処理
xy.x += 1;
for (const nv of adj[v]) dfs(adj, ans, nv, xy);
// 帰りがけ時の処理
xy.x -= 1;
if (adj[v].length === 0) xy.y += 1;
}
とすることです。つまり、x と y を(型が必要であれば interface などを適宜用いて) object 型として管理 すれば、C++の参照渡しのような挙動になり、やりたかった数値型の参照渡し(のようなこと)が出来ます。
言われてみれば至極当然な話で、何で気付かなかったんだ? とはなりました。
"数値型の参照渡し" (のようなこと)を実現しようとした際に、 "参照渡し" の方をどうしようかと悩んでいたのですが、実は "数値型" の方を変えれば良いという逆転の発想に私は中々気付けず、長らくネットの海を彷徨ってしまっていました。
こうして整理してみると、より一層私が愚かなだけだった話ではありましたが、これが他山の石となれば幸いです。
なお、以下にいくつかの補足を載せておきます。
補足
まず、「数値型の参照渡し(のようなこと)」と先程書きましたが、お察しの通り、これはあまり正確な言い方ではありません。
「JavaScript 値渡し 参照渡し」などと検索すれば、ご存じの通りこの話題に関する記事が大量に出てきますが、「参照渡しも値渡しもある」「実は値渡ししかない」「実は参照渡しも値渡しも存在しない」「実は共有渡し」「実は共有渡しじゃない」などと、もしかしてそれぞれ違う言語のお話をされていますか? みたいな悲惨な様相を呈しています。そして往々にしてこの手の記事は正確な出典や参考文献が無い、もしくは曖昧で、個人の帰納的な推測から語られがちな印象があります。一応MDN には「値渡し」という語が存在するようです([追記]コメントでこの点に関する言及も頂きました)。
さて、それを踏まえた上で、今回の内容について考えると、そもそも数値型の参照渡し(のようなこと)はあまり乱用すべきではないのではないか、という考え方があることを考慮すべきでしょう。先述の通り、数値型の参照渡しは、たとえそれが無くても同等なコードが書けます。
最近だと、また C++の話にはなりますが、int 型の参照を持った拡張ユークリッドの互除法の再帰関数が少し話題になっていました。批判を加えるつもりは一切ありませんが、やはり数値型の参照を扱う時には可読性などに注意した方が良いという主張には私も同意するところです。ただ同時に、適切に用いられた数値型の参照は、実装の簡潔さを保ちながら可読性をも向上させることが可能だ、というのもまた事実です。
さらに、C++ や Rust などのように数値型の参照が可能な言語ではそれらを用いたコードをよく目にしますが、逆に Python などのようにそれが不可能な言語では、(無理矢理それに近いことを実現させる手段こそあるものの)滅多に見かけることがない、というのも中々に示唆的な事実だと思います。(尤も、個人の感想の域を出ません)
しかし、今回の内容に関して言えば、ぱっと見だと無理矢理なやり口にも感じるかもしれませんが、基本が object 型である JavaScript / TypeScript の世界では、冷静に見るとかなり合理的な手段だと私は言えると思います。(これも、個人の感想の域を出ません)
結局、最終的には個人の趣味嗜好や、開発チームの方針によることとは思いますが、私個人としては、比較的合理的なやり方として、可読性が保たれる範囲内ではこの方法を使うのは十分ありだと考えています。
関連参考資料_6
追記: コメントで、クロージャを利用する方法を丁寧なコード付きでご教授して頂きました。非常にありがとうございます。引数として渡すこと自体を変えるという発想が自分にはなかったので、完全に想定外な解決策でした。確かに、このような方法でも今回やりたかったことは実現できますね。
非常に有用なもう一つの選択肢を教えて頂き、どうもありがとうございました。
7.hidden を変えても変わらない?
さて、続いてこちらも私が過去に取り組んでいた問題を大幅に簡略化したケースです。
まず、以下の GIF をご覧下さい。
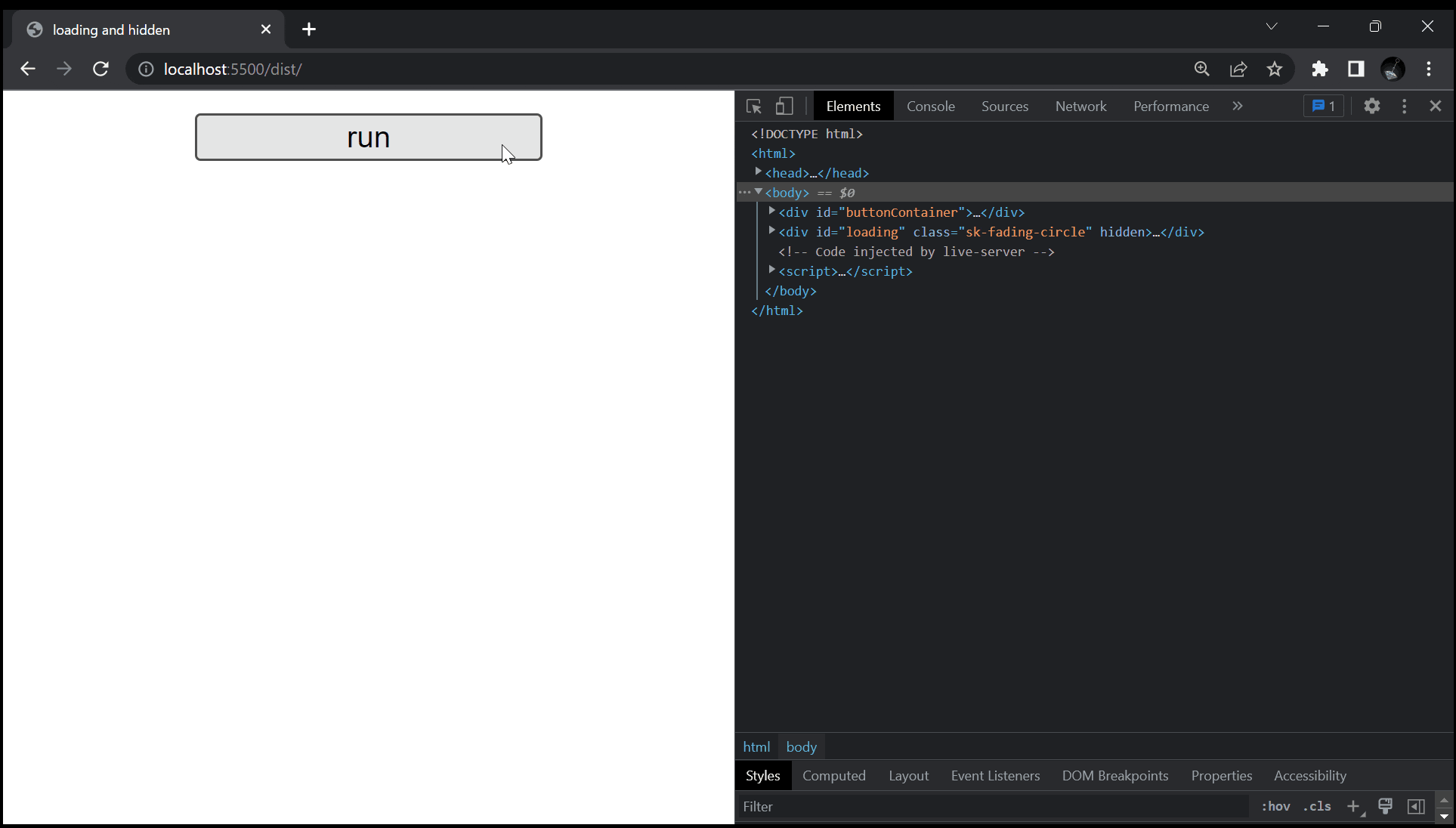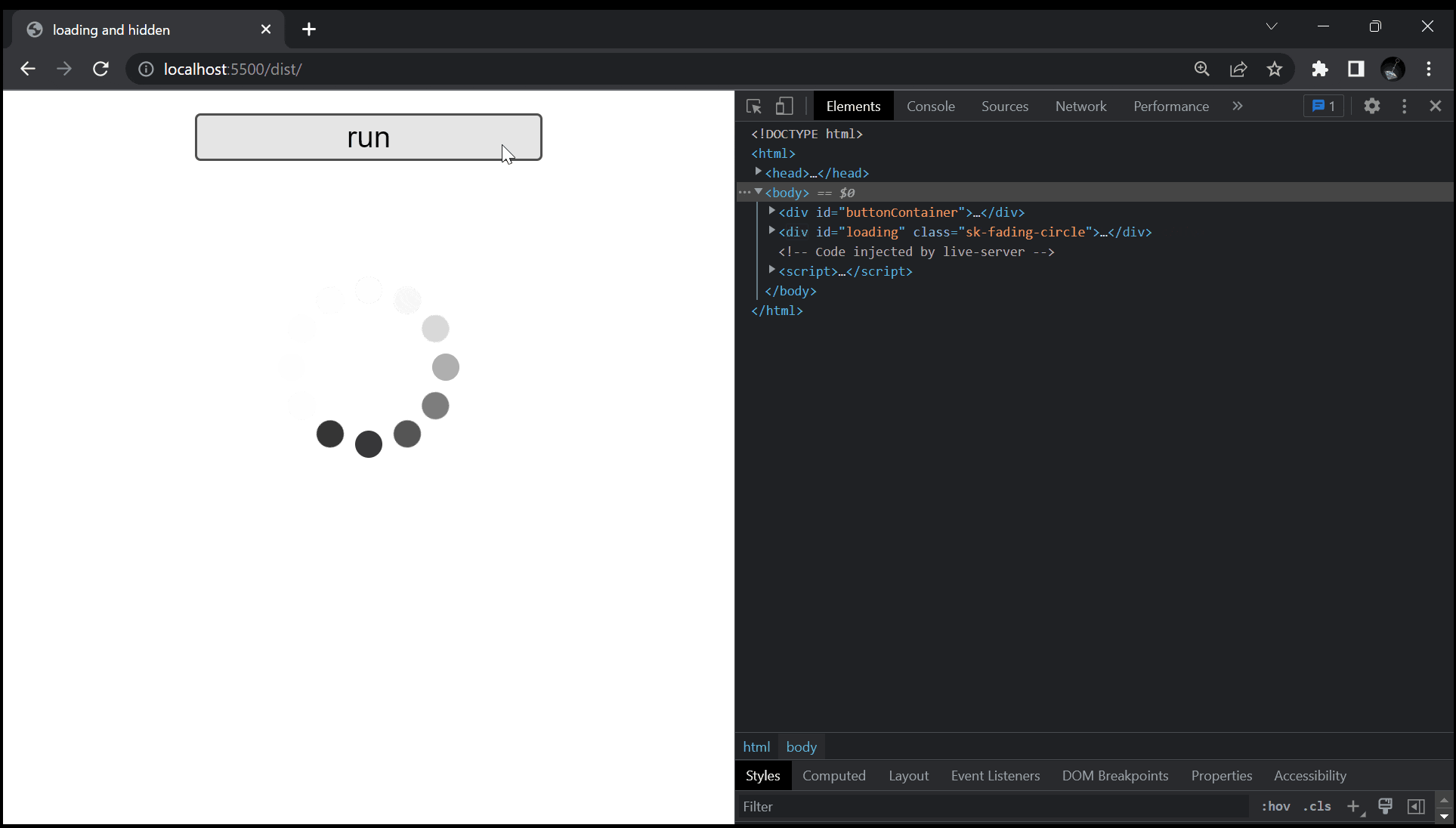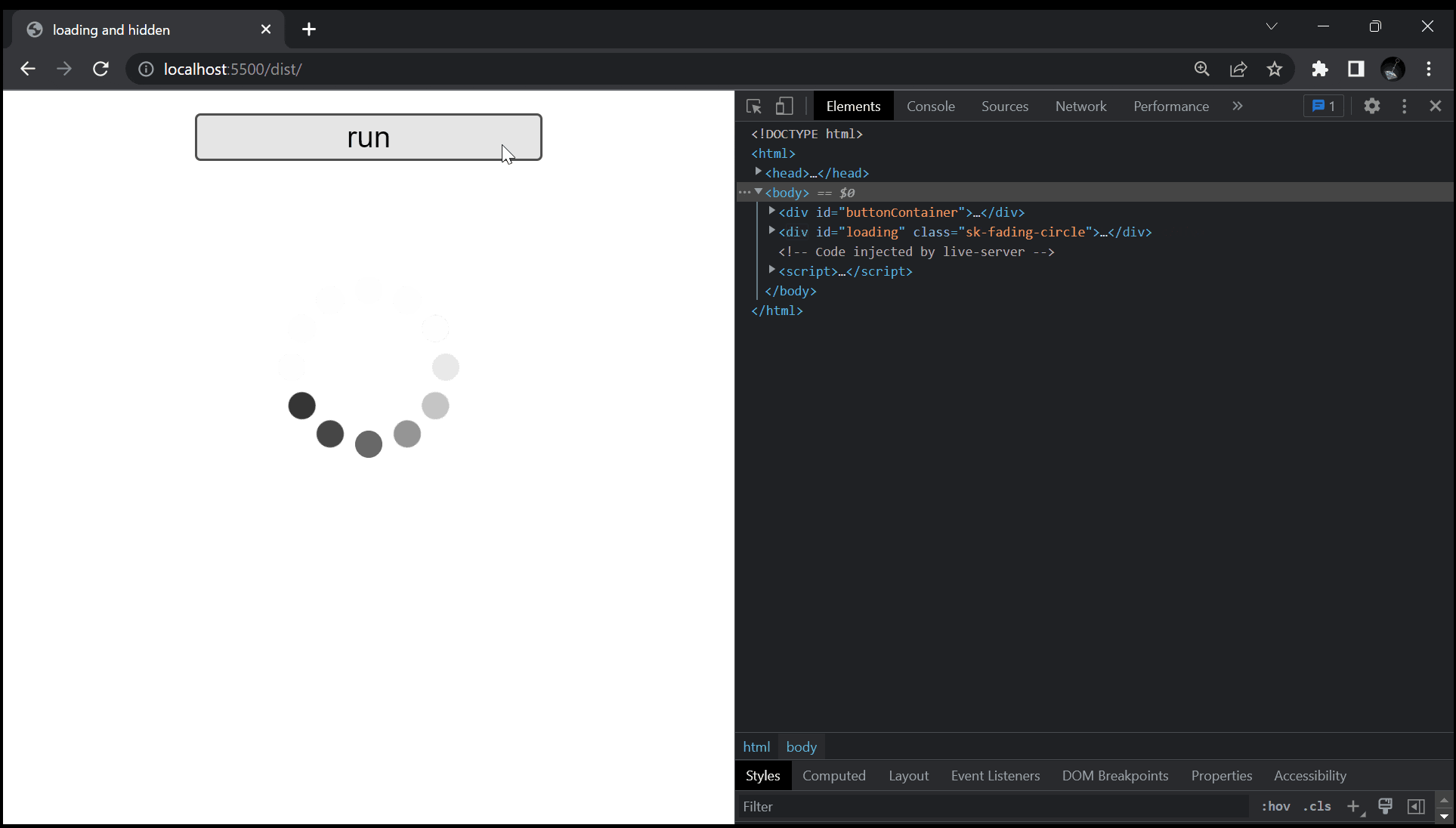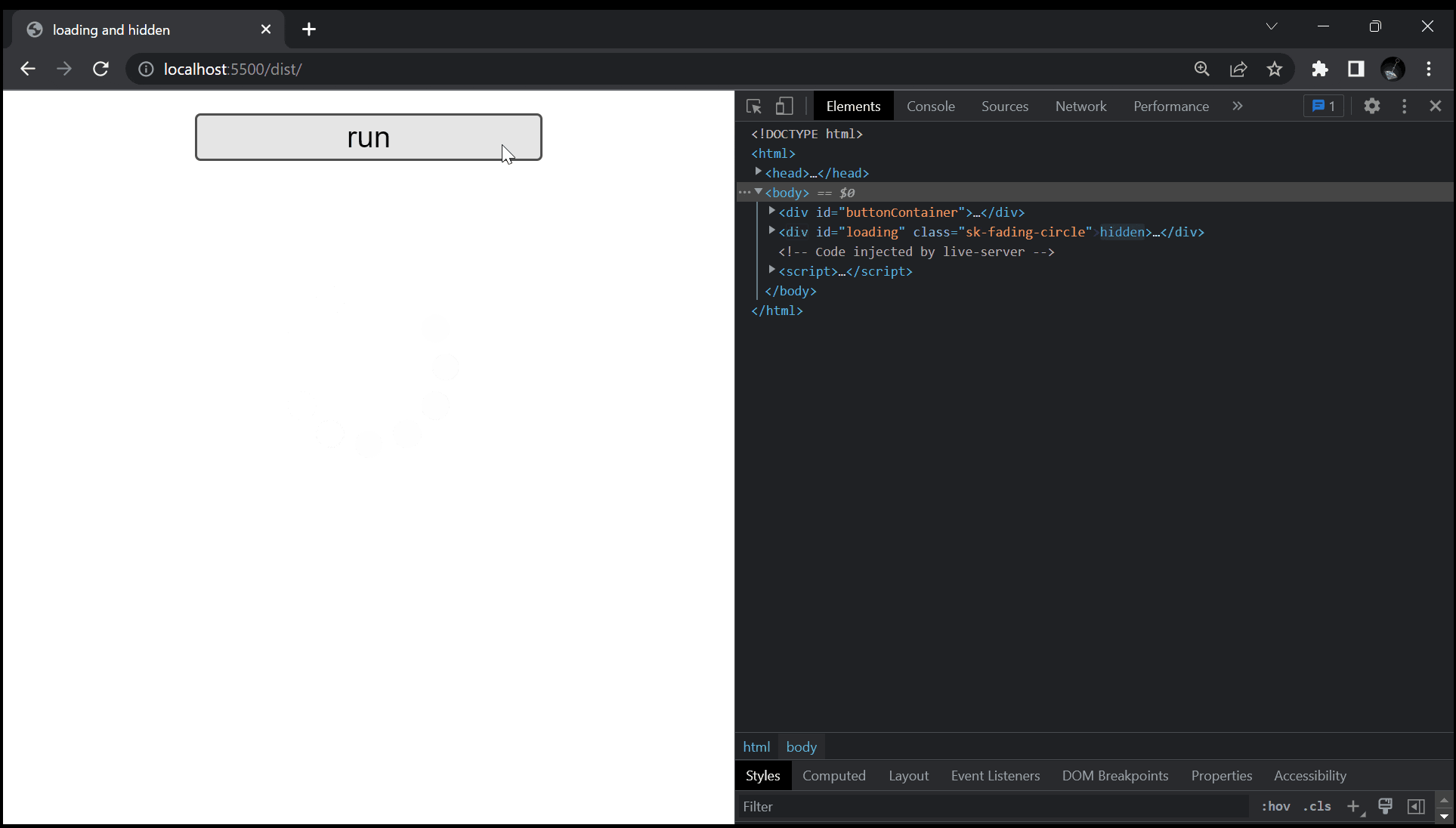
こちらを見てもらえれば大体察しが付くかもしれませんが、今回扱う問題は、何らかの処理が走るボタンを押した時に、今が処理中であることをユーザーの方に伝える為、ローディング画面などでよく見るグルグルを表示させよう、というものです。
このグルグルの表示 / 非表示を切り替える手段は多くあるかと思いますが、今回は要素の hidden の真偽を切り替えるという方法で実現させています。
さて、私はこれを実現させようと、以下のようなコードを書きました。(注記: 例示目的の為、以下は あまり良くない書き方 です。)
const BUTTON = document.getElementById("trigger") as HTMLButtonElement;
const LOADING = document.getElementById("loading") as HTMLDivElement;
BUTTON.addEventListener("click", () => {
LOADING.hidden = false; // グルグルを表示させる
// 何らかの非常に重い処理(の代わり)
for (let i = 0; i <= 100000000; i++) {
if (i % 10000000 == 0) console.log(`progress: ${i / 1000000}%`);
Math.random();
}
console.log("done.");
LOADING.hidden = true; // グルグルを非表示にさせる
});
さて、hidden の切り替えもばっちり書けたので、これで想定通りに動いてくれるかと思う訳なのですが……
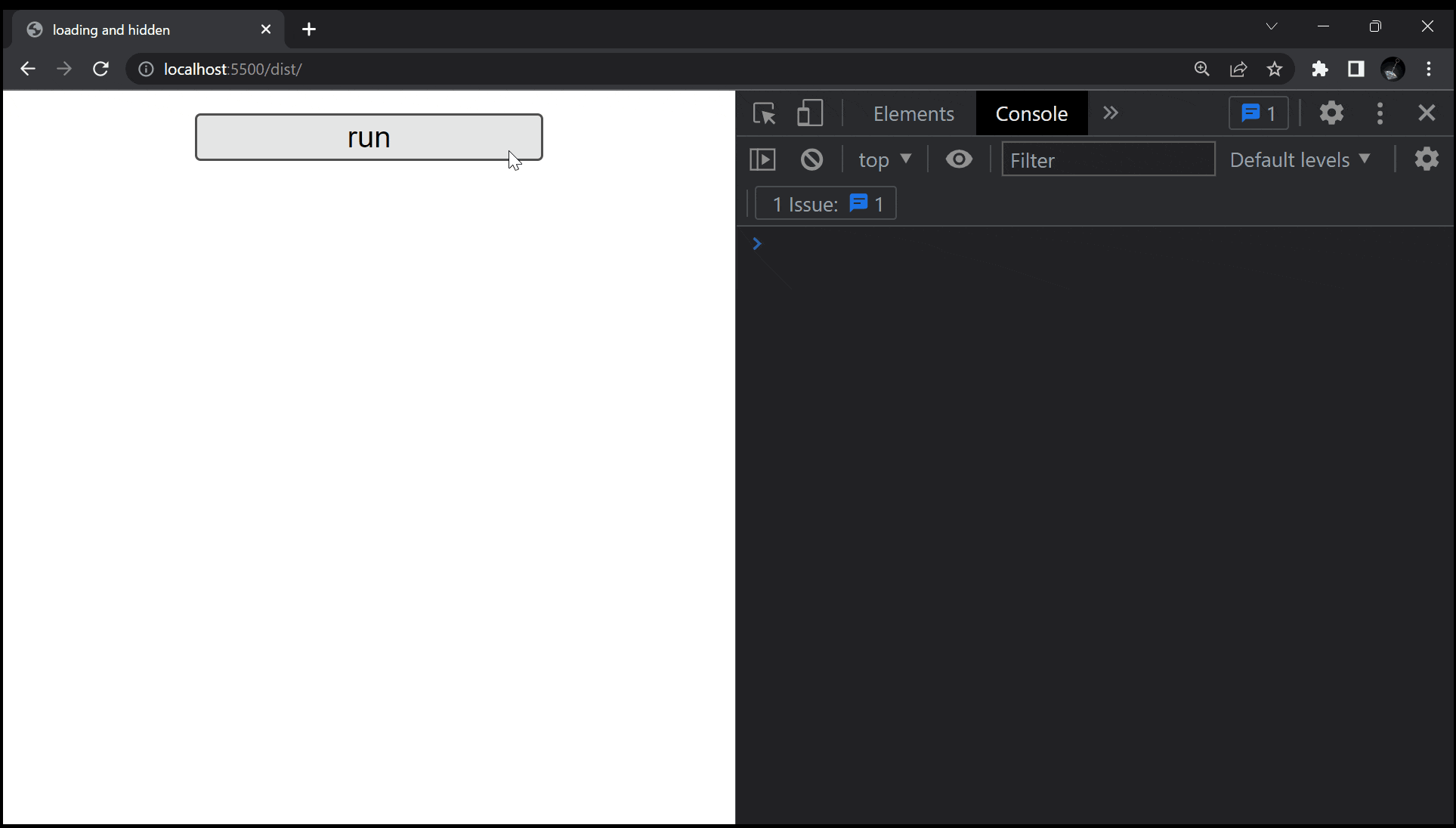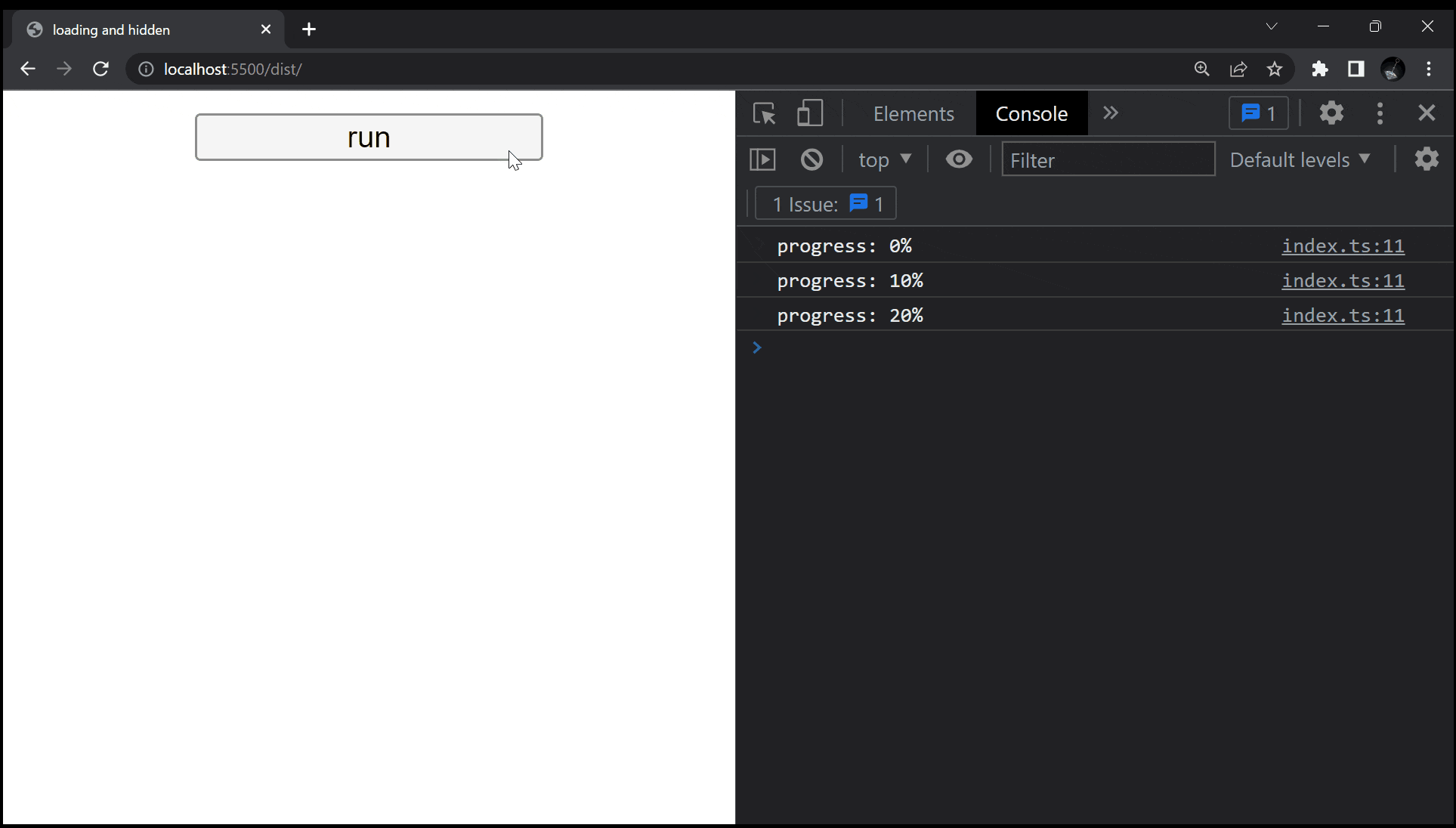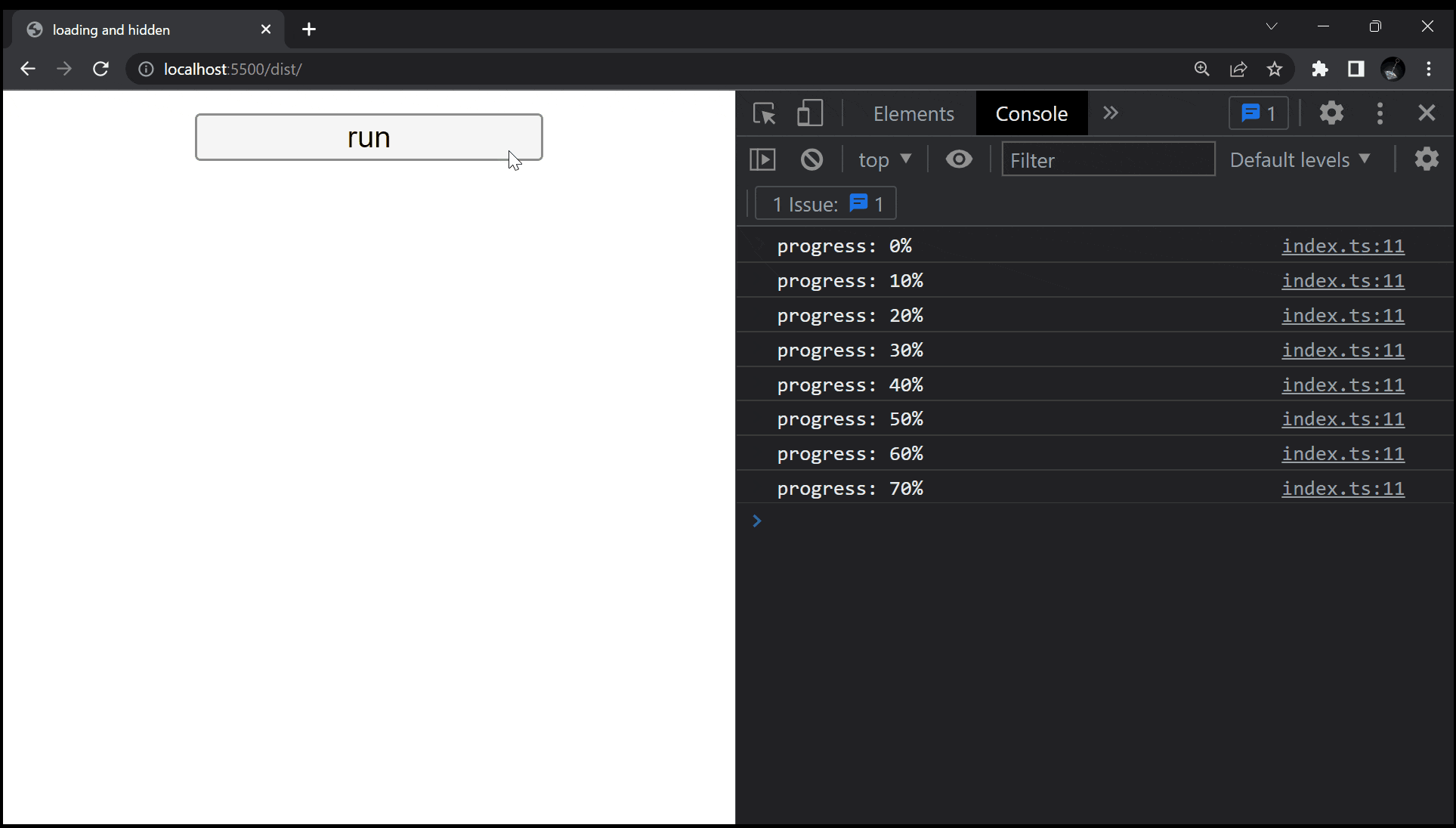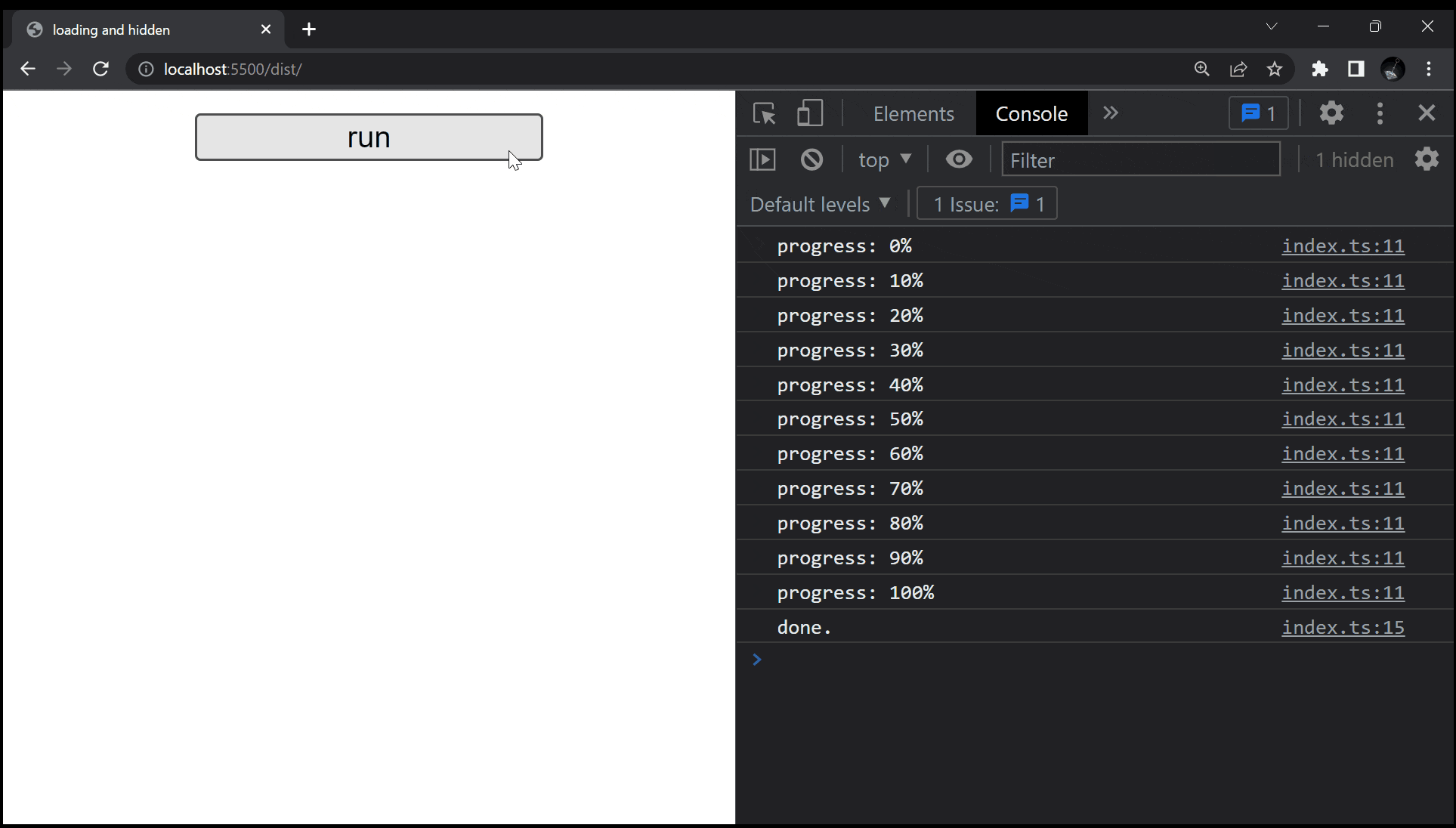
残念ながら処理が走っているにもかかわらず、画面には何も表示されません。
理由を極めて大雑把に述べるだけなら、これは大して難しい話ではなく、要は固まっている、ということです。
Stack Overflow などでも言及されている解決策として、setTimeout(() => {/* ここに処理とhiddenの切り替え */}, 100);などと書くと、一応の応急処置は出来ます。
ところで、このような現象が起こるという事実はもう分かったのですが、一体何故このような動作になるのでしょうか? そして、何故setTimeoutでこれが改善されるのでしょうか?
このようなことを厳密に理解しようとすると、 それが実は案外難しい ということに気付きます。私自身、全てを理解している自信は皆無です。一つ確実に言えることとしては、 イベントループ 、 レンダーキュー という概念などがキーになるということです。気になる方は是非以下の参考資料を参照してみてください。
関連参考資料_7
PADAone さんという方による「イベントループとプロミスチェーンで学ぶ JavaScript の非同期処理」という題で Zenn にて公開されている記事です。今回の話は特にその第一章に関連があります。
また、この記事で繰り返し出てくる動画というのが以下の Philip Roberts 氏による『What the heck is the event loop anyway?』という動画です。
非常に分かりやすい動画でした。素人の私からしても、一見の価値がある動画だと断言できます。22:30 辺りからが、今回の問題と特に関連があります。
また、MDN の参考資料も以下に挙げます。
このページは 2023 年 1 月現在、日本語版には載っていない情報(Zero delays)も、英語版の方では載っているので、そちらのリンクを掲載しています。
メインスレッド は、ブラウザーがユーザーのイベントや描画を処理するところです。既定では、ブラウザーは単一のスレッドを使用してページ内のすべての JavaScript を、レイアウト、再フロー、ガベージコレクションなどと同様に実行します。つまり、実行に時間がかかる JavaScript 関数がスレッドをブロックし、ページが反応しなくなり、使い勝手が悪くなります。
(出典: Mozilla. "Main thread (メインスレッド)". MDN. 2022 年 10 月 1 日. https://developer.mozilla.org/ja/docs/Glossary/Main_thread, (最終閲覧日: 2023 年 1 月 13 日))
正に、今回の状況を指し示している言葉です。
8.等価性比較について
==と===が違う意味を持っているということは、この記事を読まれる多くの方がご存じかと思われます。ただ、これら等価性比較についてその 厳密な 仕様はかなり複雑です。
全てをここで列挙する訳には行きませんが、MDN の該当ページへのリンクを以下に記しておきます。Object.isによる同値比較も合わせて中々ややこしいかと思われます。
一例を挙げると、
console.log(null == undefined); // true
console.log(null === undefined); // false
console.log(NaN == NaN); // false
console.log(NaN === NaN); // false
console.log(Object.is(NaN, NaN)); // true
console.log(+0 == -0); // true
console.log(+0 === -0); // true
console.log(Object.is(+0, -0)); // false
などです。
また、Map などのオブジェクトにおけるキーの等価性比較は(NaNを除き) ===の意味に従って行われる 事には注意が必要です。
先述の通り、nullとundefinedは異なるキーとして扱われます。
また、一例として、Map のキーとして[1,2,3]などの配列を使うことを考えてみます。
C++におけるstd::mapだと、以下のようにkey_aとkey_bは中身が同じであれば返される値は同じです。
#include <iostream>
#include <map>
#include <vector>
int main() {
std::vector<int> key_a{1, 2, 3};
std::vector<int> key_b{1, 2, 3};
std::map<std::vector<int>, int> m{{key_a, 4}};
std::cout << m[key_b] << std::endl;
// 出力結果: 4
return 0;
}
Python におけるdictだと、そもそも list は hashable ではないので Error が出ます。
key_a = [1, 2, 3]
key_b = [1, 2, 3]
m = {key_a: 4}
# Exception has occurred: TypeError
# unhashable type: 'list'
print(m[key_b]) # これはそもそも実行されない
そして、TypeScript ではトランスパイルこそ正常に通るものの、C++と異なる挙動を示してundefinedを返します。
const key_a = [1, 2, 3];
const key_b = [1, 2, 3];
const m = new Map<number[], number>([[key_a, 4]]);
console.log(m.get(key_b));
// 出力結果: undefined
これはkey_a===key_bではないからです。
ちなみに、key_a==key_bですらありません。
(JSON.stringify(key_a)==JSON.stringify(key_b)ではあります)
これら言語間の違いには、十分注意したいところです。
そして、これはたとえ分かっていたとしても、あるいは気を付けていたとしても、ついついやってしまうミスだと思います。
関連参考資料_8
9.for 文の使い分け
この節では for 文を扱います。
for 文などと言うとプログラミングの基本中の基本なので、豆知識というよりは基礎知識といった感じですが、手癖で書いていたり他言語の思い込みがあったりで、意外に盲点があると思っています。
まず、MDN の「文と宣言」には
の 4 つがページとして存在しており、また、標準組み込みオブジェクト Array のメソッドとして
というページが存在し、「チュートリアル」には
というページがあります。
これらの中から、特に盲点になりそうな点を列挙すると、
- forEach のコールバック関数は、第一引数に要素の値、 第二引数に要素のインデックス 、 第三引数に操作されている配列 がとれる
- forEach は break に相当する操作が(ほぼ)不可能だが、 for...of などは break が可能
- forEach はコールバック関数内でプリミティブ値を変更しても元の要素は変わらないが、 非プリミティブ値を変更すると元の要素も変わることがある (6 番目のお話と同じことです)
const twoDimArray = [
[0, 1, 2],
[4, 5, 6],
[7, 8, 9],
];
// 第一引数elem, 第二引数idx, 第三引数array
twoDimArray.forEach((elem, idx, array) => {
// continueはreturnで出来るが、breakは困難
if (idx === array.length - 2) return;
// 非プリミティブ値に変更を加えると……
elem.push(3 + (7 * idx) / 2);
});
console.log(twoDimArray);
// 結果: 要素にも変更が反映されている!
// [0, 1, 2, 3]
// [4, 5, 6]
// [7, 8, 9, 10]
4. for...of は第一引数だけを取る forEach に対して(break が出来るという意味で、ほぼ)上位互換で、特に ジェネレーター関数 が使用可能
5. for...in は オブジェクトの(列挙可能)プロパティ に対して反復処理を行う
6. for は 文を持たない for 文が書ける(for(;;){expr;}でなく、for(;;);と、for のすぐ後に;を書く)(が、使い道は少なそう)
などが挙げられると思います。
また、 labeled statement があります。勝手に Rust とか Java だけだと思い込んでいたのですが、JavaScript / TypeScript にもあって驚きました。
// label付きのfor文 (ここでは"outer"を指す)
outer: for (let i = 1; i <= 5; i++) {
console.log(`outer loop: ${i}`);
console.group();
for (let j = 1; j <= 3; j++) {
console.log(`inner loop: ${j}`);
if (i == 3 && j == 2) {
console.groupEnd();
// ↓ break (label名); と書くと、
break outer;
}
}
console.groupEnd();
}
// 多重ループを一気に抜けられる
console.log("done.");
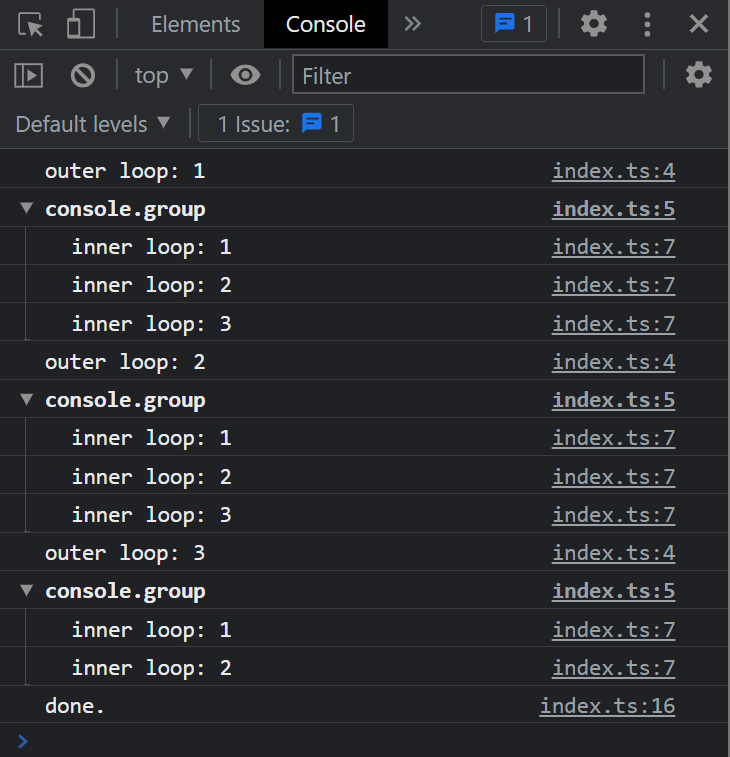
たかが for 文、されど for 文。奥が深いです。
関連参考資料_9
10.その他豆知識
最後に、いくつかの細かい話題をまとめて、それを10個目とさせて頂きます。
主に参考資料に頼る形ではありますが、興味を引くものがあれば幸いです。
- Type Manipulation
TypeScript 限定の話ではありますが、型の操作に関するお話です。日本語の解説記事も世に溢れていますが、公式ドキュメントもかなり分かりやすく記述が丁寧です。読んだことがない方は読んでみると面白いかも知れません。自分は-readonly(readonly という属性をなくす)という書き方などを知りませんでした。
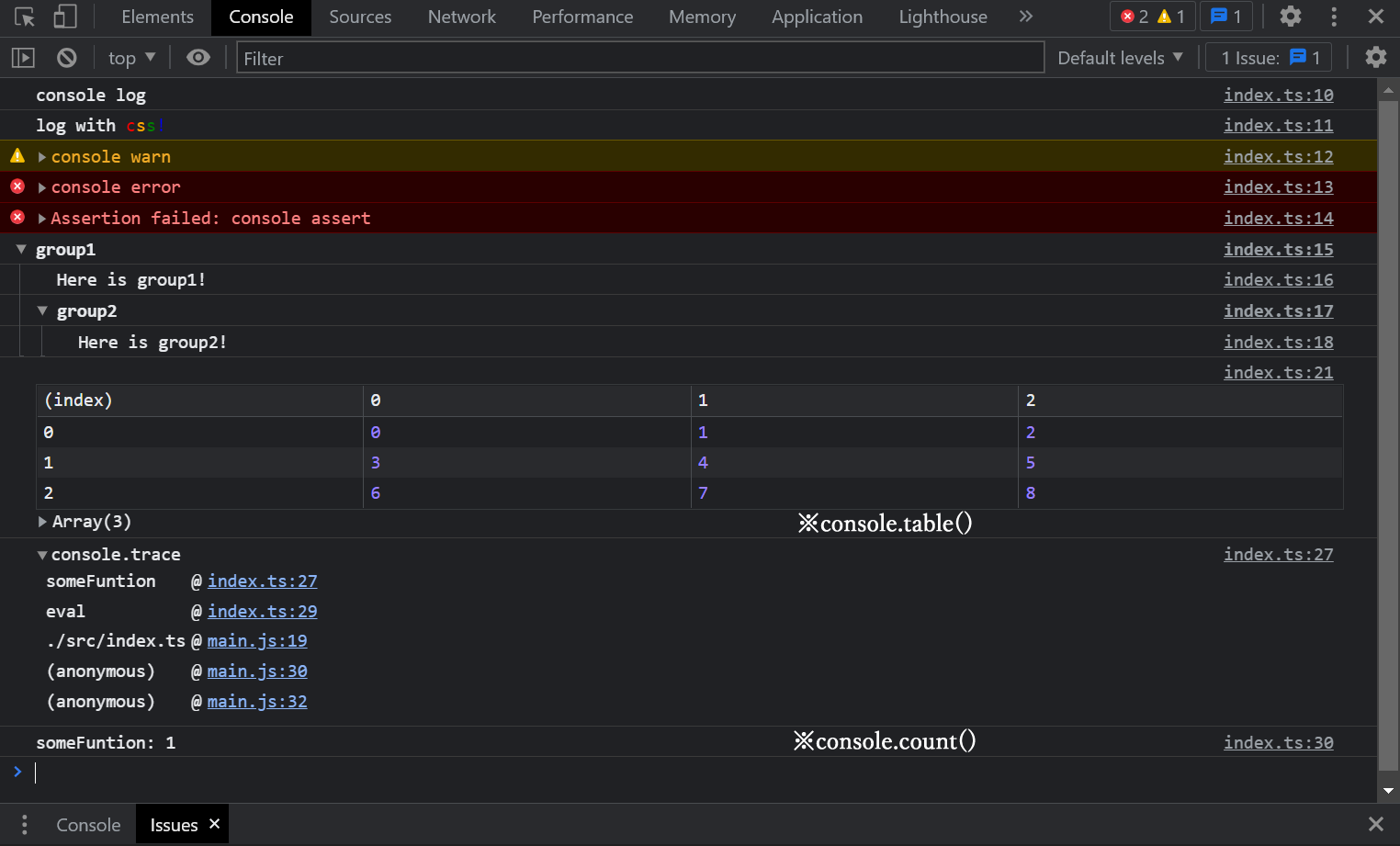
- Console API
console.group()、console.table()、console.trace()、console.count()あたりが小ネタとしてよく紹介されている印象があります。実際、使いこなせると便利ですね。
- innerText と textContent の違い
style="display:none"と設定した element 内の文字列は、一方では含まれて他方では含まれません。どちらがどちらか分かりますでしょうか?
答え
答えは、
- textContent では"display:none"も 含まれる
- innerText では "display:none"は 含まれない
です。他にもいくつか違いがありますが、MDN 曰く、
基本的に innerText はテキストがレンダリングされる表示を意識しますが、 textContent はそうではありません。
とのことです。
- debugger
(利用可能な場合は)ブレークポイントの設定などが可能になり、debug で便利です。
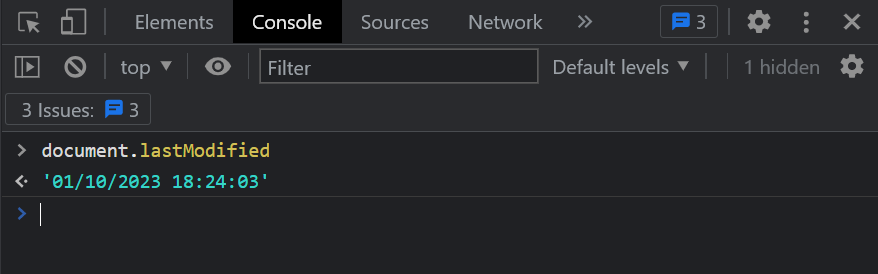
- document.lastModified
任意のウェブページの、最後に更新された日付と時刻が分かります。サイトに最終更新日が記載されているならば、それを優先して見るべきでしょうが、レポートなどで出典を書くときなどに便利ですね。実は、この記事の執筆に際しても利用しました。
以上、豆知識まとめでした。
おまけ
JavaScript / TypeScript には関係ないので 10 選からは除外しましたが、HTML5 や CSS にも、意外な発見などが多くあって楽しいです。
その中でも、CSS のcursorは特に面白いと思ったので少しだけ触れます。
PC の人は以下の ブロックにカーソルをおいて みて、そうでない人は(残念ながらカーソルは出てこないので) ブロックをクリック することで、本来はどんなカーソルが出てくるのかをご覧下さい。
あまりカーソルの種類は知らない、なんて方ならば、想像以上に沢山の種類のカーソルが存在することにビックリされるかもしれません。
See the Pen CSS Cursor by hari64 (@hari64boli64) on CodePen.
(いくつか環境依存な面もあるようなので、context-menu などは多くの場合出てこないかも知れません)
私は、alias と copy に関して、どちらも恐らく調べて初めて存在を知りました。 col-resize とかは、そんなの見たことない、と思いがちかも知れませんが、実はよく見ると、PC 版 Slack などのサイズ可変ウィンドウとかにこっそり使われています。知識を得てから改めて世の UI を見返すと、案外色々な発見が溢れて面白いです。
「そんな機能あったんだ」という気持ちになって頂ければ嬉しい限りです。
最後に
本記事はこれで以上となります。
最後までお読み頂きありがとうございました。