
LaTeX Lint
概要
LaTeX Lintは、.texおよび.mdファイル用のLaTeXリンターです。
VS Code拡張機能版が利用可能です。
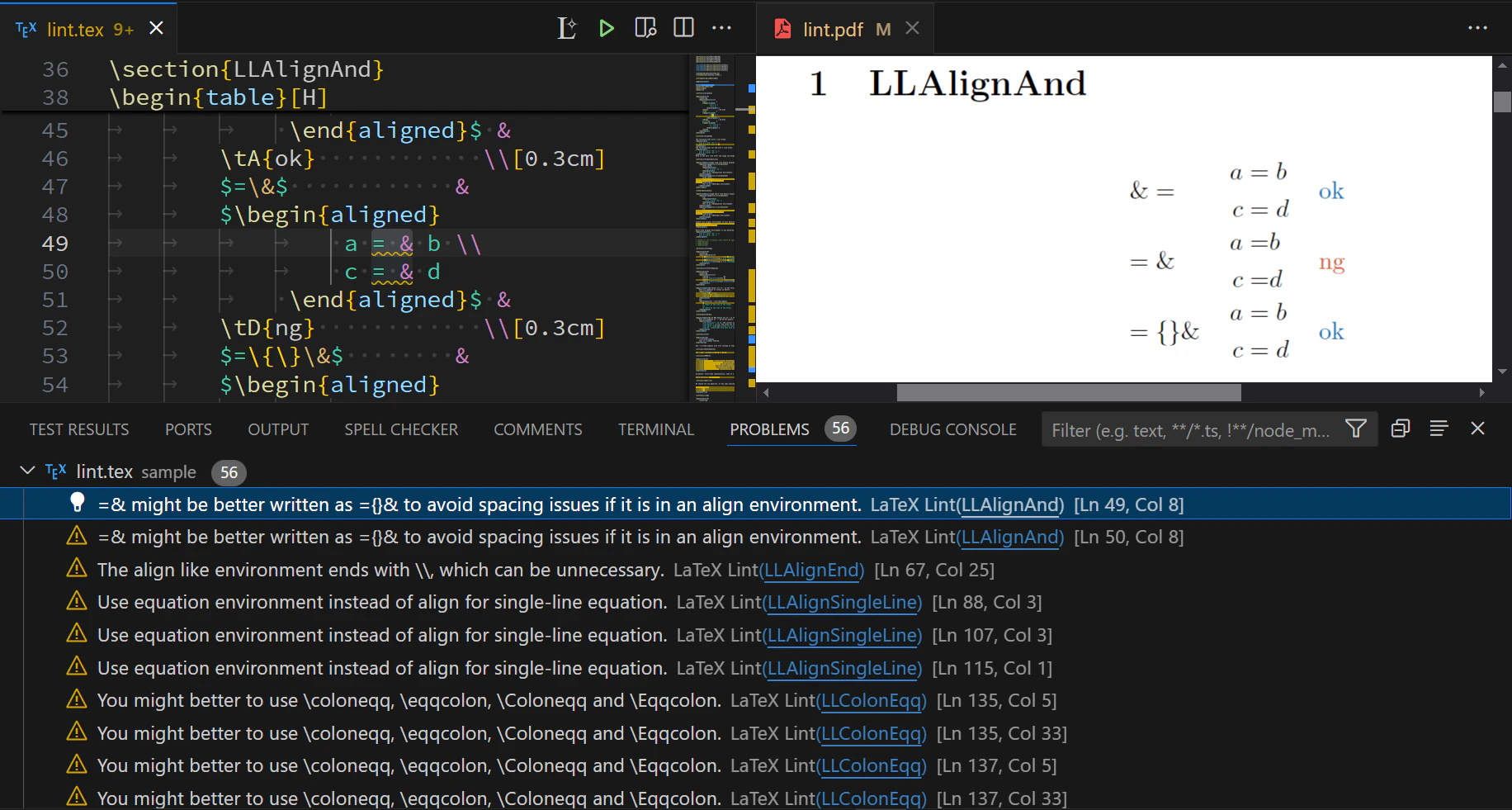
Web版も利用可能です。
ルール
検出するルールの一覧です。
検出するルールは、好みや文体に合わせて選択することを強くお勧めします。 ルールの選択方法については、LaTeX Lint: Choose Detection Rulesをご参照ください。
-
LLAlignAnd (
=&、\leq&、\geq&などを検出) -
LLAlignEnd (
align環境が\\で終わる場合を検出) -
LLAlignSingleLine (
\\のないalign環境を検出) - LLArticle (冠詞の誤用を検出)
-
LLBig (
\cap_、\cup_などを検出) -
LLBracketCurly (
\max{と\min{を検出) -
LLBracketMissing (
^23、_23などを検出 (デフォルトで無効)) -
LLBracketRound (
\sqrt(、^(、_(を検出) -
LLColonEqq (
:=、=:、::=、=::を検出) -
LLColonForMapping (写像に使われた
:を検出) -
LLCref (
\refを検出 (デフォルトで無効)) -
LLDoubleQuotes (
"を検出) -
LLENDash (疑わしい
-(ハイフン)の使用を検出) -
LLEqnarray (
eqnarray環境を検出) - LLErrCompOps (誤った比較演算子の並びを検出)
-
LLFootnote (
\footnoteの前の空白を検出) - LLHeading (見出しレベルのジャンプを検出)
-
LLLlGg (
<<と>>を検出) - LLNonASCII (全角ASCII文字を検出)
- LLNonstandard (非標準的な数学記号を検出)
- LLPeriod (LaTeX中の略語ピリオドを検出)
-
LLRefEq (
\ref{eq:を検出) -
LLSharp (
\#の誤用とおぼしき\sharpを検出) -
LLSI (
\SIなしのKB、MB、GBなどを検出) - LLSortedCites (ソートされていない引用を検出)
- LLSpaceEnglish (英語での空白の不足を検出)
- LLSpaceJapanese (日本語での空白の不足を検出 (デフォルトで無効))
-
LLT (
^Tを検出 (デフォルトで無効)) - LLTextLint (textlintの一部機能)
-
LLThousands (
1,000などを検出) -
LLTitle (
\title{}、\section{}などでの疑わしいタイトルケースを検出) - LLUnRef (参照されていない図表ラベルを検出)
- LLURL (URLの不要な情報を検出)
-
LLUserDefined (
latexlint.userDefinedRules内の正規表現を検出)
必要に応じて、sample/lint.pdfも参照してください。
LLAlignAnd
.texと.mdファイルのalign環境における=&を検出します。
余計な空白を避けるため、&=または={}&を使用してください。
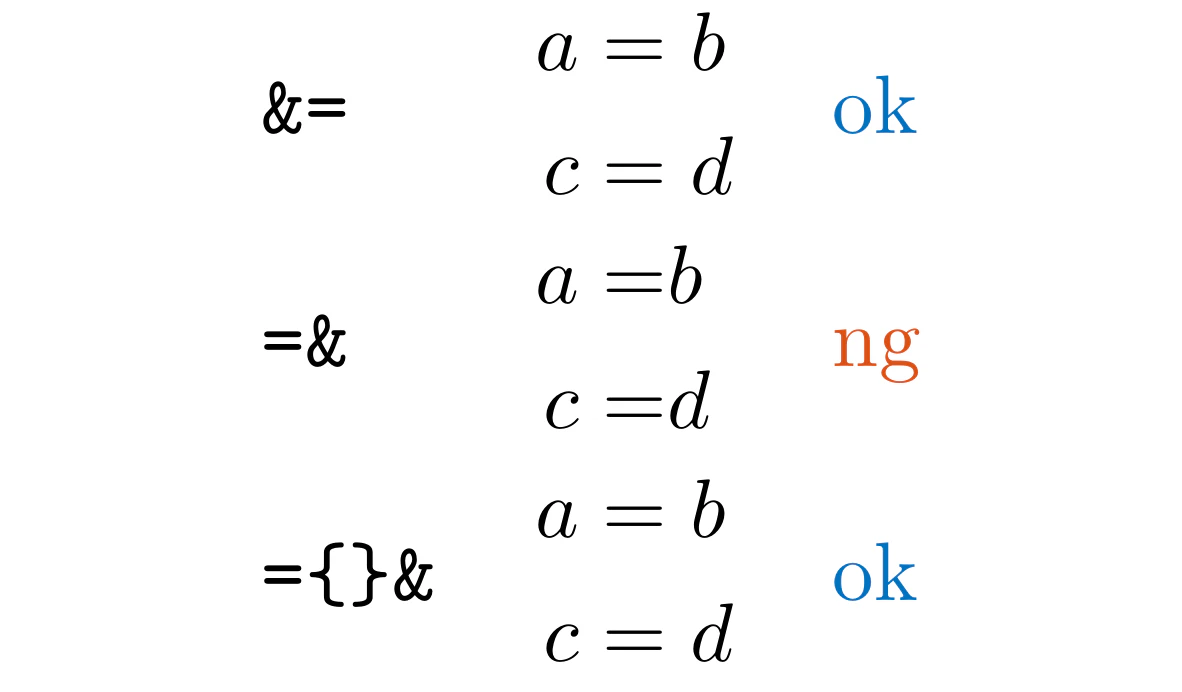
また、\neq&、\leq&、\geq&なども検出します。
参考文献:
Relation spacing error using =& in aligned equations (Stack Exchange)
LLAlignEnd
.texと.mdファイルのalign、gatherなどの環境が\\で終わる場合を検出します。
この\\は不要と思われます。

LLAlignSingleLine
.texと.mdファイルのalign環境で\\がない場合を検出します。
一行だけの数式の場合はequation環境が推奨されます。

align環境の間隔は、1つの式だけの場合、equation環境とは異なります。amsmathパッケージの公式ドキュメントは、1つの式の場合にequation環境を使用することを想定しています。
\\begin{align} ... \\end{align}を\\begin{equation} ... \\end{equation}に書き換えるには、LaTeX Lint: Rename Command or Labelでコマンド名を変更できます。
参考文献:
LLArticle
.texと.mdファイルの冠詞の誤用を検出します。

具体例は以下の通りです。
-
単一文字:
- NG:
a $a$→ OK:an $a$ - NG:
a $n$→ OK:an $n$ - NG:
a $x$→ OK:an $x$ - NG:
an $u$→ OK:a $u$
- NG:
-
略語:
- NG:
a EM→ OK:an EM(Expectation–Maximization) - NG:
a EVD→ OK:an EVD(Eigenvalue Decomposition) - NG:
a FFT→ OK:an FFT(Fast Fourier Transform) - NG:
a NP-hard→ OK:an NP-hard(Non-deterministic Polynomial-time hard) - NG:
a LSTM→ OK:an LSTM(Long Short-Term Memory) - NG:
a LTI→ OK:an LTI(Linear Time-Invariant) - NG:
a MLE→ OK:an MLE(Maximum Likelihood Estimation) - NG:
a MSE→ OK:an MSE(Mean Squared Error) - NG:
a ODE→ OK:an ODE(Ordinary Differential Equation) - NG:
a RNN→ OK:an RNN(Recurrent Neural Network) - NG:
a RKHS→ OK:an RKHS(Reproducing Kernel Hilbert Space) - NG:
a SDE→ OK:an SDE(Stochastic Differential Equation) - NG:
a SVD→ OK:an SVD(Singular Value Decomposition) - NG:
a SVM→ OK:an SVM(Support Vector Machine) - NG:
a XOR→ OK:an XOR(Exclusive OR)
- NG:
-
LaTeXのコマンド:
- NG:
a $\mathbb{R}$-valued→ OK:an $\mathbb{R}$-valued - NG:
a $L^1$→ OK:an $L^1$ - NG:
a $\ell^2$→ OK:an $\ell^2$ - NG:
a $\mathcal{L}^\infty$→ OK:an $\ell^\infty$
- NG:
参考文献:
Should individual letters be preceded with "an"? (Stack Exchange)
LLBig
.texと.mdファイルの\cap_、\cup_、\odot_、\oplus_、\otimes_、\sqcup_、uplus_、\vee_、\wedge_を検出します。
代わりに\bigcap、\bigcup、\bigodot、\bigoplus、\bigotimes、\bigsqcup、\biguplus、\bigvee、\bigwedgeを使用すべきです。

参考文献:
Formatting the union of sets (Stack Exchange)
LLBracketCurly
.texと.mdファイルの\max{と\min{を検出します。
代わりに\max(と\min(を使用するか、\max {または\min {のようにスペースを追加して明確にしてください。

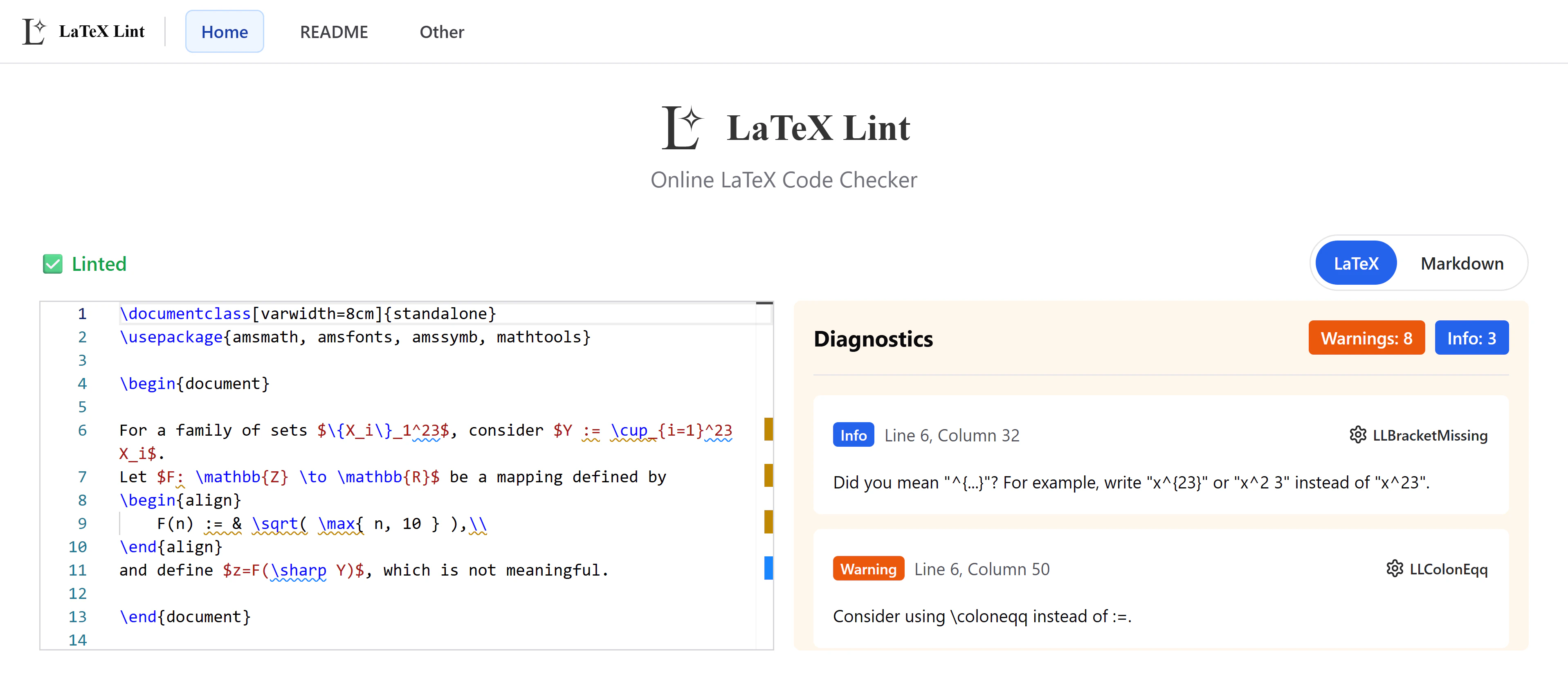
LLBracketMissing
.texファイルの^23、_23、^ab、_abなどのケースを検出します。{}または空白を追加して上付き文字と下付き文字の範囲を明確にしてください。
このルールはデフォルトで無効です。
\includegraphics{figure_23}や\url{http://example.com/abc_123}のようなファイル名/URL/ラベルは無視されます。
このルールはプリアンブル(\begin{document}より前、存在する場合のみ)の部分では無効です。

LLBracketRound
.texと.mdファイルの\sqrt(、^(、_(を検出します。
代わりに\sqrt{、^{、_{を使用すべきです。

LLColonEqq
.texと.mdファイルの:=、=:、::=、=::を検出します。
代わりにmathtoolsパッケージの\coloneqq、\eqqcolon、\Coloneqq、\Eqqcolonを使用すべきです。

:=ではコロンがやや低いですが、\coloneqqでは垂直方向に中央揃えされています。
参考文献:
How to typeset $:=$ correctly? (Stack Exchange)
What is the latex code for the symbol "two colons and equals sign"? (Stack Exchange)
LLColonForMapping
.texと.mdファイルの写像用に使用されていると思われる:を検出します。
代わりに\colonを使用することをお勧めします。

\colonは写像用の記号として推奨されています。:は1:2のような比率に使用されます。
\to、\mapsto、\rightarrowが見つかった場合、いくつかのヒューリスティックによって偽陽性を抑制しながら、このルールは最も近い:を見つける為に最大10語まで逆方向に見ていきます。
参考文献:
Using \colon or : in formulas? (Stack Exchange)
LLCref
.texファイルの\refを検出します。
代わりにcleverefパッケージの\crefまたは\Crefを使用すべきです。
このルールはデフォルトで無効です。
このパッケージが推奨される理由は、「Sec.」や「Fig.」のようなプレフィックスを自動的に追加でき、参照形式の一貫性を保つことができるからです。
このルールはプリアンブル(\begin{document}より前、存在する場合のみ)の部分では無効です。
LLDoubleQuotes
.texファイルの"を検出します。二重引用符には、代わりに``XXX''を使用してください。

“XXX”については、ほとんどの場合に問題ないので検出はしませんが、一貫性のために``XXX''を使用することを推奨しています。
csquotesパッケージで\enquote{XXX}を使用することもできます。
参考文献:
What is the best way to use quotation mark glyphs? (Stack Exchange)
LLENDash
.texと.mdファイルの疑わしいハイフンの使用を検出します。
ハイフンの代わりに--でen-dashを、---でem-dashを使用すべきです。

このルールは本質的に「正しい」ものとは言い切れませんが、多くの場合、en-dashの方が好ましいとされています。
例えば、以下を検出します。
-
Erdos-Renyi(ランダムグラフ、Erd\H{o}s--R\'enyi) -
Einstein-Podolsky-Rosen(量子物理学、Einstein--Podolsky--Rosen) -
Fruchterman-Reingold(グラフ描画、Fruchterman--Reingold) -
Gauss-Legendre(数値積分、Gauss--Legendre) -
Gibbs-Helmholtz(熱力学、Gibbs--Helmholtz) -
Karush-Kuhn-Tucker(最適化、Karush--Kuhn--Tucker)
ただし、例外として以下は検出しません。
-
Real-Valued/Two-Dimensionalのような一般的な単語ペアは、両方の単語が認識された一般語彙である場合、スキップされます。 -
Fritz-John(最適化、人名) - (今後、さらなる例外を追加する可能性があります。)
ページ範囲を示すために、-の代わりに--を使用すべきです。例えば、123-456ではなく123--456です。多くのBibTeXファイルがこのルールに従っています。これは単なる減算である可能性があるため、検出しません。
LLEqnarray
.texと.mdファイルのeqnarray環境を検出します。
代わりにalign環境を使用すべきです。
eqnarray環境は空白に問題があるため、推奨されていません。
参考文献:
Why not use eqnarray? (TeX FAQ)
LLErrCompOps
.tex と .md ファイルで、誤植と思われる比較演算子の並びを検出します。
<=, \\le =, \\leq =などが検出の対象です。
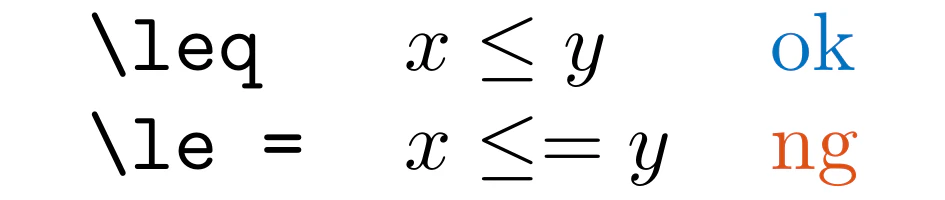
Markdown では <= と => は検出しません。
LLFootnote
.texファイルの\footnoteコマンドの前の不要な空白を検出します。
\footnoteの前の空白を削除するか、前の行の末尾にパーセント記号%を追加して、出力に不要な空白が入らないようにすべきです。

脚注マーカーを句読点の前後に配置するかどうかはスタイルの選択に依ります。そのため、特定のスタイルを強制してはいません。
参考文献:
Where do I place a note number in relation to punctuation? (MLA Style Center)
Best practice for source editing of footnotes (Stack Exchange)
How to properly typeset footnotes/superscripts after punctuation marks? (Stack Exchange)
LLHeading
.texファイルの不適切な見出しの階層を検出します。
このルールは、\sectionから\subsectionを経由せずに直接\subsubsectionに飛ぶなど、見出しレベルのジャンプがある場合に警告します。
ルールは以下の見出しレベルをチェックします:
\chapter\section\subsection\subsubsection
LLLlGg
.texと.mdファイルの<<と>>を検出します。
代わりに\llと\ggを使用すべきです。

次のような<<は検出しません。
I like human $<<<$ cat $<<<<<<<$ dog.
LLNonASCII
.texと.mdファイルのすべての全角ASCII文字を検出します。
以下の文字を検出します。
!"#$%&'*+-/0123456789:;
<=>?@ABCDEFGHIJKLMNOPQRS
TUVWXYZ[\]^_`abcdefghijk
lmnopqrstuvwxyz{|}~
以下の正規表現を使用します。
[\u3000\uFF01-\uFF07\uFF0A-\uFF0B\uFF0D\uFF0F-\uFF5E]
Range U+FF01–FF5E reproduces the characters of ASCII 21 to 7E as fullwidth forms. U+FF00 does not correspond to a fullwidth ASCII 20 (space character), since that role is already fulfilled by U+3000 "ideographic space".
Wikipedia
さらに、U+3000 は全角スペースに使用されます。
以下の文字は、日本語ドキュメントで頻繁に使用されるため、検出しません。
- U+FF08
( - U+FF09
) - U+FF0C
, - U+FF0E
.
LLNonstandard
.texと.mdファイルの、正式な学術文献では一般的に使用されない非標準的な数学記号を検出します。

このルールは以下の表記法を検出します。
「iff」という単語
"iff"(if and only if)はラフな文章では一般的に使用されていますが、正式な学術文章では完全に書き出されることが好まれます。
\therefore と \because コマンド
これらの記号は、フォーマルな場面では一般的に使用されていません。
\fallingdotseq と \risingdotseq コマンド
これらは非標準的な記号です。フォーマルな執筆では\approxが推奨されます。
組み合わせの {}_n C_k 表記
組み合わせの{}_n C_k表記は日本でよく使用されていますが、国際学術文献では標準ではありません。代わりに標準的な二項記号 \binom{n}{k} を推奨します。
このルールは、偽陽性を避けるために正確なマッチのみを検出します。
参考文献:
While it is not generally used in formal writing, it is used in mathematics and shorthand.
数学英語 (河東泰之, Japanese article):
∀ や ∃ の記号は数理論理学でない限り,黒板などに書く時の略記法なので論文では使わないとされている.実は私の論文で ∀ が使われている例がいくつかあるのだが,それは共著者が書いたものを直し切れなかったのだ.これと同様のものとして,if and only if の意味の iff も略記法であって論文には不適切とされている
(The symbols ∀ and ∃ are considered shorthand notations for writing on blackboards, etc., and are not used in papers unless in mathematical logic. In fact, there are some examples of ∀ being used in my papers, but that is because I couldn't fully correct what my co-authors wrote. Similarly, the abbreviation "iff" for "if and only if" is also considered a shorthand notation and is inappropriate for use in papers.)
∵という記号は今ここに書いている通り JIS コードにもあるし,TeX でも \because という名前がついているのだが,私の知っている限り欧米ではほとんど使わない.(∴のほうはこれよりは使われている.) これを日本人が黒板に書いて,「それは何か」と聞かれているところを見たことが何度もある.同じく欧米で使わない数学記号として≒がある.「大体等しい」ことを表すのによく使われる記号は≈である.
(The symbol ∵ is included in the JIS code and is named \because in TeX, but as far as I know, it is rarely used in Western countries. (The symbol ∴ is used more than this.) I've seen Japanese people write this on blackboards and ask "What does that mean?" many times. Another mathematical symbol that is not used in Western countries is ≒. The symbol commonly used to represent "approximately equal" is ≈.)
組合せ (数学) (Japanese Wikipedia):
ピエール・エリゴン(フランス語版)が1634年の『実用算術』で ${}_n C_k$ の記号を定義した。ただし、この数は数学のあらゆる分野に頻繁に現れ、大抵の場合 $\binom{n}{k}$ と書かれる。
(Pierre Hérigone defined the ${}_n C_k$ notation in his 1634 work "Practical Arithmetic". However, this number appears frequently in all areas of mathematics and is usually written as $\binom{n}{k}$.)
LLPeriod
LaTeXファイル中の略語ピリオドを検出します。
このルールは、空白が続く e.g., i.e., i.i.d., w.r.t., w.l.o.g., resp. を検出します。
LaTeXはこれらの略語のピリオドを文の終わりとみなすため、余分なスペースが生じることがあります。
e.g.\ のように \ を使って空白の問題を回避するか、e.g., のようにコンマを追加してください。

参考文献:
Is a period after an abbreviation the same as an end of sentence period? (Stack Exchange)
LLRefEq
.texファイルの(\ref{eq:を検出します。代わりに\eqref{eq:を使用した方が適切です。このコマンドは参照の周りに自動的に括弧を追加します。
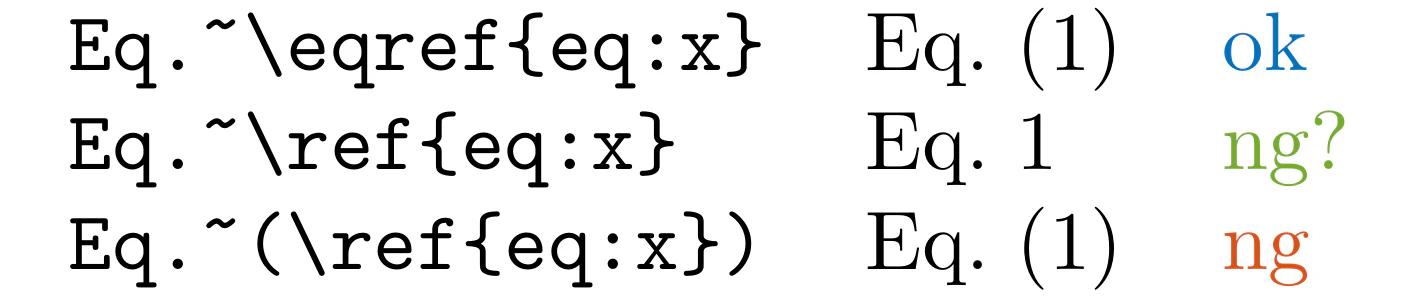
実のところ、本当に我々が検出したいのは、例えば次のような打ち間違いです。
From Fig.~\ref{fig:sample} and Eq.~\ref{eq:sample}, we can see that...
From Fig. 1 and Eq. 1, we can see that...
多くの場合、数式番号は以下のように(1)などと括弧で括られた形式で参照されることが期待されます。これは標準的なスタイルであり、amsmathパッケージや多くの論文や書籍で一般的に使用されています。
From Fig.~\ref{fig:sample} and Eq.~(\ref{eq:sample}), we can see that...
From Fig.~\ref{fig:sample} and Eq.~\eqref{eq:sample}, we can see that...
From \cref{fig:sample} and \cref{eq:sample}, we can see that...
From Fig. 1 and Eq. (1), we can see that...
しかし、全ての\ref{eq:が誤りというわけではなく、意図的に使用される場合もあります。その為、このようなケースを機械的に検出するのは望ましくありません。
そこで予防的な意味合いとして、(\ref{eq:を検出し、\eqref{eq:の使用を促すことを目的としています。
そうすれば、検出されない\ref{eq:のケースを手動で確認し、意図的なものかどうかを判断することができます。
不完全ではありますが、このアプローチはそのような間違いを見落とす可能性を減らすのに役立ちます。
LLSharp
.texと.mdファイルの\sharpを検出します。
番号記号には、代わりに\#を使用すべきです。

\sharpは音楽記号に使用されます。このルールはいくつかのヒューリスティックな条件を満たす場合にのみ報告します。
LLSI
.texファイルで\SIなしのKB、MB、GB、TB、PB、EB、ZB、YB、KiB、MiB、GiB、TiB、PiB、EiB、ZiB、YiBを検出します。
siunitxパッケージの\SI{1}{\kilo\byte}(10^3 byte)や\SI{1}{\kibi\byte}(2^{10} byte)のように、\SIを使うとよいです。

| Prefix | Command | Symbol | Power |
|---|---|---|---|
| kilo | \kilo | k | 3 |
| mega | \mega | M | 6 |
| giga | \giga | G | 9 |
| tera | \tera | T | 12 |
| peta | \peta | P | 15 |
| exa | \exa | E | 18 |
| zetta | \zetta | Z | 21 |
| yotta | \yotta | Y | 24 |
m、s、kg、A、K、mol、radなどの単位にも\SIを使うとより良いでしょう。
LLSortedCites
.texファイルでソートされていない複数引用を検出します。
\cite{b,a}のような複数引用は、ソート順の[1,2]ではなく[2,1]と表示されることがあります。これは、unsrtスタイルのような出現順に番号を付けるスタイルを使用しているかどうかとは無関係の話であることに注意してください。
このルールはそのようなケースをヒューリスティックに検出します。一般には、\usepackage{cite}を使ったり、\usepackage[sort&compress]{natbib}を使ったりすることで解決できます。

このルールはヒューリスティックに基づいた検出を行うため、偽陽性が含まれる可能性があります。
参考文献:
Numbered ordering of multiple citations (Stack Exchange)
Biblatex, numeric style, multicite: Order of references (Stack Exchange)
LLSpaceEnglish
.texと.mdファイルの日本語・英語の文字とインライン数式の間の空白の不足を検出します。\

ただし、対象のトークンの直後がthである場合(例: \(n\)th)や、対象のトークンの直前がコマンドである場合(例: $\backslash$n)はスキップします。
LLSpaceJapanese
.texと.mdファイルの日本語文字と数式の間の空白の不足を検出します。
このルールはデフォルトで無効です。
LLT
.texと.mdファイルの^Tを検出します。
行列やベクトルの転置を表すには、代わりに^\topや^\mathsf{T}を使うのが望ましいです。
このルールはデフォルトで無効です。
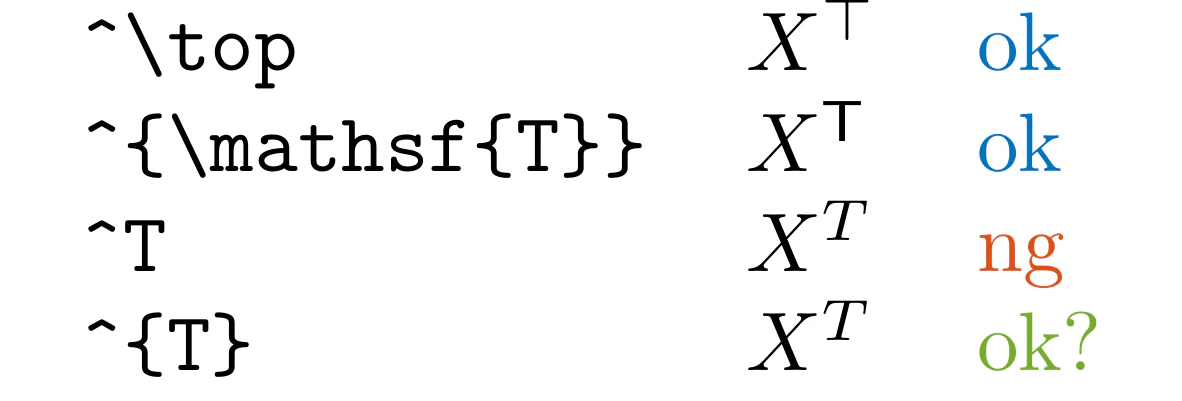
そうしないと、変数Tによる累乗と転置を区別できません(累乗には^{T}を使えます)。
また、\sum_{i=1}^T や \prod_{i=1}^T などもエラーとして検出しません。
参考文献:
What is the best symbol for vector/matrix transpose? (Stack Exchange)
LLTextLint
.texと.mdファイルの疑わしいテキストを検出します。
Web版では、textlintというOSSで用いられている校正ルールを援用し、いくつかの日本語に関する誤りを検出しています。
VSCode版では、主に動作の高速化のために、いくつかのパターンマッチングのみを使用して、誤りと思われるテキストを検出しています。

LLThousands
.texファイルで1,000のように桁区切りのカンマが誤って使われているケースを検出します。
1{,}000を使うか、icommaパッケージを利用するのがよいでしょう。

参考文献:
avoid space after commas used as thousands separator in math mode (Stack Exchange)
LLTitle
.texファイルの\title{}、\section{}、\subsection{}、\subsubsection{}、\paragraph{}、\subparagraph{}で不適切なタイトルケースを検出します。
例えば、
The quick brown fox jumps over the lazy dog
はタイトルケースでは
The Quick Brown Fox Jumps Over the Lazy Dog
であるべきです。このようなケースを検出します。
例外やスタイルが多いため、すべての非タイトルケースを検出するのは困難です。好みのスタイルに変換するには、Title Case ConverterやCapitalize My Titleの利用を強く推奨します。
文字列がto-title-case(to-title-caseを基に実装)によるtoTitleCase適用で不変かをテストしています。偽陽性や偽陰性が発生する可能性があります。
参考文献:
Title Case Capitalization (APA Style)
LLUnRef
.texファイルで、図表環境内の\label{...}が\ref{...}や\cref{...}で参照されていない場合を検出します。
このルールは、あくまで既に図にlabelが付けられていない場合のみ、その参照漏れを検出します。図にlabelが付けられていないこと自体は検出しません。
全ての図表をテキスト内でも明示的に参照することが求められるのは、一般的な媒体物における慣習と異なるので、少々不自然に感じるかもしれません。しかし、学術的な文書では、多くのスタイルガイドやジャーナルで実際に求められています。詳細は参考文献もご覧ください。一例として、以下にAPA 7th Editionのスタイルガイドからの引用を示します。
General guidelines
All figures and tables must be mentioned in the text (a "callout") by their number. Do not refer to the table/figure using either "the table above" or "the figure below."
(Citing tables, figures & images: APA (7th ed.) citation guide)
参考文献:
Is it normal to require to reference all figures and tables in the text? (Academia Stack Exchange)
LLURL
.texと.mdファイルで、クエリ文字列を含むURLを検出します。
以下のクエリ文字列は不要とみなします:
- ?utm_...=(Wikipedia参照)
- ?sessionid=...
以下のクエリ文字列は許可されます:
-
?user=...(e.g., Google Scholar profile URLs) -
?q=...(e.g., search queries) ?page=...?lang=...
LLUserDefined
.texと.mdファイルで検出する独自の正規表現を定義できます。
詳しくはLaTex Lint: Add Custom Detection Ruleを参照してください。
以下にいくつか例を挙げます。
例1: 英字には\mathrm を使う
数式中で説明のために英字を使う場合、\mathrmを使うべきです。
例えば文字aが変数ではなくattractive forceのような意味を持つなら、f^a(x)はf^{\mathrm{a}}(x)と書くべきです。

ただし文脈なしでの検出は難しいです。そこで、このようなパターンを検出するためにf\^aというルールを自分自身で定義することができます。
例2: 適切に定義した演算子を使う
演算子を使うときは\DeclareMathOperatorで定義するべきです。
例えば\Boxをinfimal convolutionとして使うなら、演算子として定義すべきです。
\DeclareMathOperator{\infConv}{\Box}

その後、\Boxの代わりに\infConvを使えます。そして、\\Boxを正規表現として定義して、このパターンを検出できます。
ルールの無効化
ルールを無効化するには、エラーが発生する行の先頭に、LaTeXの場合は% LLDisable、Markdownの場合は<!-- LLDisable -->を追加してください。
Some error contained line. % LLDisable
Some error contained line. <!-- LLDisable -->
ルール全体の有効・無効を切り替えるには、LaTeX Lint: Choose Detection Rulesを使用してください。
その他の機能
VS Codeでは以下の機能も利用できます。これらのコマンドはエディタのツールバー上のアイコンから実行できます。
LaTeX Lint: Add Custom Detection Rule
独自の検出ルールを追加します。例えば、次の手順でf^aを検出できます。
1. 検出したい文字列を選択(任意)
2. コマンドを実行(Add Custom Detection Rule)
アイコンをクリックするか、コマンドパレット(Ctrl+Shift+P)でLaTeX Lint: Add Custom Detection Ruleと入力して実行します。
3. 指示に従う
stringを選ぶと入力文字列そのものを検出し、Regexを選ぶと正規表現でパターンを検出します。
その後、独自のルールを定義できます。
LaTeX Lint: Choose Detection Rules
検出するルールを選択します。検出したいルールにチェックを入れてください。

LaTeX Lint: Rename Command or Label
\begin{name}、\end{name}、\label{name}上でF2を押すと名前を変更できます。

Go to Label Definition
\ref{xxx}、\cref{xxx}、\Cref{xxx}上でF12を押すと、対応する\label{xxx}の定義へジャンプします。
この機能は、現在のファイル内で一致する\label{xxx}を検索し、コメントではない最初の一致箇所にジャンプします。
LaTeX Lint: Query Wolfram Alpha
式を解くためにWolfram Alphaへクエリを送信します。
1. 解きたい式を選択

2. コマンドを実行(Query Wolfram Alpha)
アイコンをクリックするか、コマンドパレット(Ctrl+Shift+P)でLaTeX Lint: Query Wolfram Alphaと入力して実行します。

3. Wolfram Alpha のページを確認
結果はWolfram Alphaのページで確認できます。式を送信する際、不要なコマンドは一部削除します。

注記
ルールに記載されているように、偽陽性と偽陰性が発生することがあります。いかなるフィードバック、ご提案、プルリクエストも歓迎しています。
論文を作成する際は、学術会議や出版社で指定されているスタイルに従っていることを確認してください。
この拡張機能が、皆様の学術執筆に役立つことを願っています。
ライセンス
このプロジェクトは複数のコンポーネントで構成されており、異なるライセンスを使用しています:
-
メイン拡張機能 (ルートディレクトリ)
MIT Licenseの下でライセンスされています。
詳細はLICENSEファイルを参照してください。(ライブラリto-title-caseもMIT Licenseです。)
-
Web コンポーネント (web/ディレクトリ)
Apache License 2.0の下でライセンスされています。
詳細はweb/LICENSEファイルを参照してください。Webコンポーネントには以下を含みます:
- textlint (MIT License)
- kuromoji.js (Apache License 2.0)
謝辞
当拡張機能でこれらのツールを直接利用しているわけではありませんが、一部の機能は以下の優れたLaTeXチェックツールに着想を得ています。
- LaTeXパッケージ chktex(GNU General Public License version 2 以降)
- LaTeX向けリンター latexcheck(MIT License)
また、一部の機能は以下のVS Code拡張機能とも共通点があります。
- VS Code拡張機能 Markdownlint
- VS Code拡張機能 LaTeX Begin End Auto Rename
これらのツールの開発者の皆様に、心より感謝いたします。