はじめに
この記事はほぼ自分のメモ用です。
結論としてはDocker+GCPを使ってGPUが動くkaggle環境(kaggle notebookと同じ)を作ります。
突然ですが
最近のkaggleのコンペ、データがめっちゃくちゃ多くてメモリが足りなかったり、cudf必須で無限のGPU時間が必要だったり、notebookコンペで訳わからんsubmission errorが出たり、しんどくないですか??????
そのしんどさを少しでも軽減できればなと思いDocker+GCPでの環境構築をはじめました。
この記事の嬉しさは以下かなと思います。
・この記事だけで全て完結する
・どんなにメモリが必要なコンペでも可変的に対応することができる
・gpu時間が無制限(お金はかかる)
・kaggle notebookと全く同じ環境を作れるのでsubmission errorの原因が少なくなる
またこの記事は実行場所が
・ローカル
・GCEインスタンス
・コンテナ
と目まぐるしく入れ替わります。
コードブロックの左上にどこで実行すればいいか記載しているので注意してください。
ちなみに
既存のQiitaの記事をうまく3~4個くらい合わせれば同じことができるんで車輪の再発明と言われればそうなんですが、一つの記事で構築できた方が楽かなと思いこの記事を書いてます。(というか自分が複数の記事を参照しながらやっててめんどくさかった)
完全に自分用の備忘録です。
データセットの扱い方とか、もっといい方法があればコメントで教えてください。
目次
| 目次 |
|---|
| GCEインスタンスを建てる |
| CloudSDKを使ってローカルから接続 |
| cudaのverを合わせる |
| GCEインスタンス上でDockerを利用しkaggle環境を構築 |
| 分析データをコンテナ内に展開しコンテナに入る |
| コンテナ内で動作確認 |
| 再開方法 |
| おまけ(自動補完) |
GCEインスタンスを建てる
まずGCPのアカウントを作ってください。以下のリンクから飛べます。
https://cloud.google.com/gcp/
そうしたら新しくプロジェクトを作成し、左上のメニューからMarketplaceを選択します。

ここで適当に「deep」などと検索し、以下を選択します。

GCEからもっとカスタマイズしてインスタンスを建てる方が良いのかもしれませんか、コマンドやDockerを使ったりするための環境構築がめんどくさいので「deep Learning VM」を使用します。

運用開始をクリックすると以下のような設定画面が現れます。

自分が好きなように設定しましょう。なお、自分は以上のように構築しました。
後からCUDAを上書きするのでFrameWorkはなんでも大丈夫です。(ここが綺麗じゃないので気になる人はGCEから適切にインスタンスを建てた方がいいと思いますが、自分はめんどくさかったのでこの方法を使っています。)
ここで2点注意があります
1.SSDのサイズを100GB以上にしましょう
kaggle公式imageがかなり大きいので、100GBより小さいとビルドに失敗するケースがあります。(友人に試してもらったところ80GBで失敗しました)
2.CuDFを使用したい方はGPUの選択に気をつけてください。
以下はhttps://github.com/rapidsai/cudfの画像ですがCuDFを動かす場合、「Pascal architectureかより良いもの(>= P100)」を使用する必要があります。(k80とかだと動きません)
なのでP100を選択するのが無難です。
各GPUと対応しているregionについては下記のサイトで確認することができます。
"https://cloud.google.com/compute/docs/gpus"

なお、最初はGPUの割り当て上限が0になっているので、警告から割り当てページにとんで上限を編集してください。

申請を行うとメールが届き、その後10分くらいで上限が変更されます。
以上の設定が終わったらデプロイをクリックしましよう。
これでGCEインスタンスを建てることができました!
CloudSDKを使ってローカルから接続
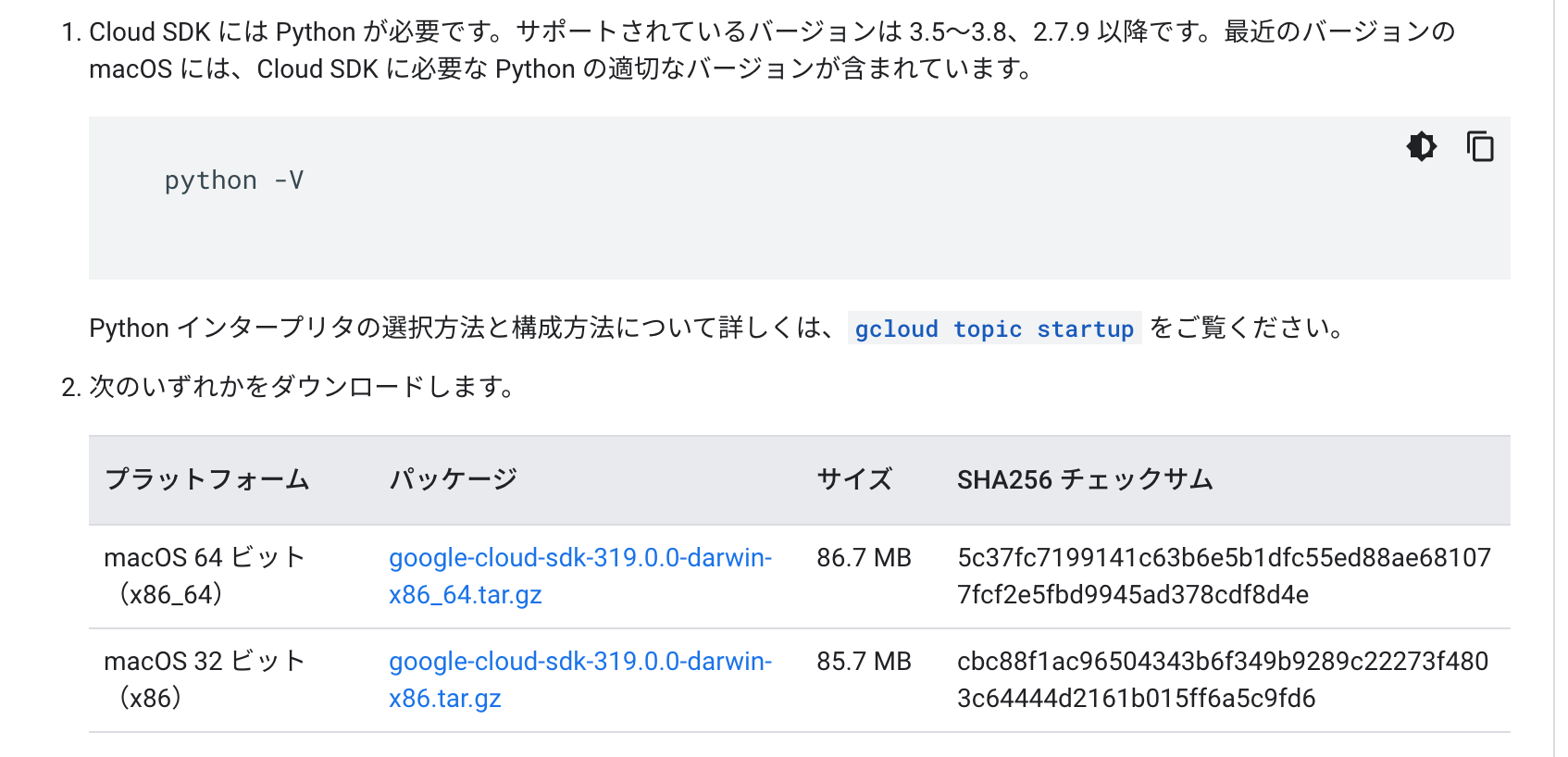
次にcloud SDKを使って先ほど建てたGCEインスタンスに接続します。以下のサイトを参照にすれば問題なく可能ですが、一応mac版だけ手順を示します。
(どう考えても公式の説明の方がわかりやすく正しいので、スキップ推奨です完全に自分用に書いています。)
https://cloud.google.com/sdk/docs/install
まず上記のサイトに行き、macOS 64bit版をダウンロードしましょう。(なお上記のページにも書いてありますが、Pythonが必要です。ない場合は各自インストールしてください)
 n
n
./google-cloud-sdk/install.sh
を実行し、パスを通して、
./google-cloud-sdk/bin/gcloud init
を実行し、指示に従いGoogleアカウントやプロジェクトへの紐付けを行います。(プロジェクトの変更や、googleアカウントの変更の時もこのコマンドを利用します。)
そうするとgcloudコマンドが使えるようになっているので、以下のようにコマンドをターミナルで実行し、ssh通信を行ってください。
gcloud compute ssh [インスタンス名] --zone [ゾーン名]
ちなみに自分の場合は以下のようなコマンドを実行することになります。
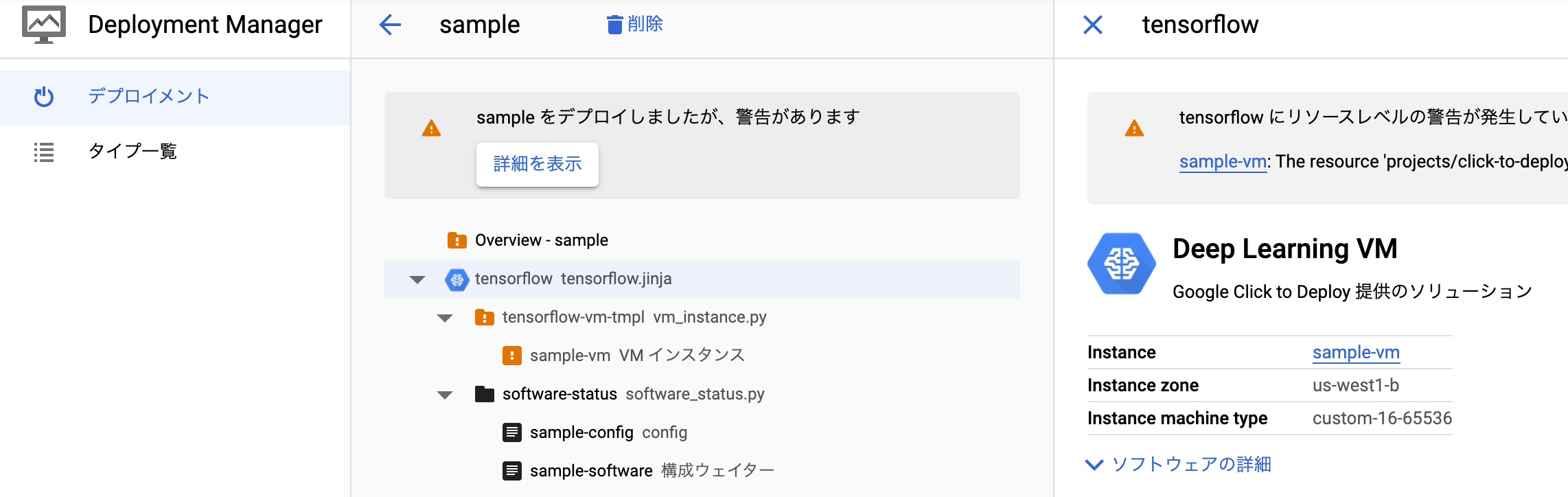
gcloud compute ssh sample-vm --zone us-west1-b
これでGCEインスタンスに接続することができました。
なお、初回接続時にはnvidiaのドライバを入れるかどうか聞かれますが、次の節で入れるので「no」で大丈夫です。(一応「yes」verも試してみましたが、綺麗に上書きされるようで動作しました。)
次はDocekrを利用し、kaggle環境をコンテナ内で再現していきます。
cudaのverを合わせる
今回は公式の以下のレポジトリを利用してコンテナを作成していきます。
https://github.com/Kaggle/docker-python
ここでgpu.Dockerfileを見てみましょう。
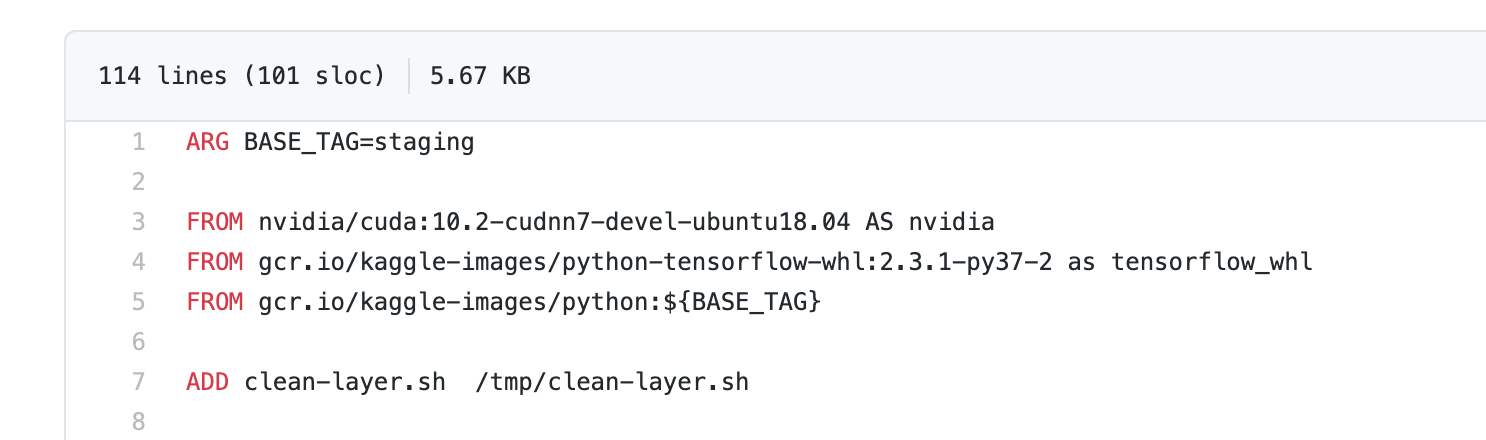
そう!cuda10.2なんです!
本当はGCEインスタンスを建てる時cuda10.2対応のFrameworkを使用するのが楽なんですが、なんと現在10.2だけ対応していません...

なのでhost側(GCEインスタンス)にもcuda10.2をいれる必要があります。
「cudaを自分でいれる」と聞いて苦虫を潰したような顔になっているかもしれませんが、とても簡単です。(自分も最初ver合わせないといけないことに気づいた時絶望しました)
二行のコマンドを実行するだけです。以下のリンクからnvidiaの公式サイトに入り、
https://developer.nvidia.com/cuda-toolkit-archive
対応しているverをクリックしましょう。(今回だと10.2)

そうすると以下のような画面が出てくるので、
linux→x86_46→Ubuntu→18.04→runfile[local]
の順で選択します。
そうするとBase Installerコマンドが出てくるのでこれをコピーして実行するだけです。

現在GCEインスタンスの中にgcloudコマンドで入っていると思うのでそのままコピーして実行します。
$ wget https://developer.download.nvidia.com/compute/cuda/10.2/Prod/local_installers/cuda_10.2.89_440.33.01_linux.run
$ sudo sh cuda_10.2.89_440.33.01_linux.run
なお、下記のような表示が出てきますが、accept→一番下まで行ってSelect→Yesで大丈夫です。($ sudo sh cuda_10.2.89_440.33.01_linux.run は少し時間がかかりますが心配しないでください)



インストールが終わったら以下のコマンドを実行して、GPUが認識されているか、指定したverのcudaが入っているか確認しましょう。
$ export LD_LIBRARY_PATH=/usr/local/cuda/lib64
$ nvidia-smi
 自分の場合、cuda10.2が入っており、P100が認識されているため上手く行ったようです。
自分の場合、cuda10.2が入っており、P100が認識されているため上手く行ったようです。
GCEインスタンス上でDockerを利用しkaggle環境を構築
次にGCEインスタンス上にDockerを利用し、kaggle環境を構築します。
と言っても簡単で、以下のコマンドを実行し終わりです。
なお、ビルドにかなりの時間がかかることに注意してください。(30~60分程度)
$ git clone https://github.com/Kaggle/docker-python.git
$ cd docker-python
$ ./build --gpu
$ docker images
なお、GCEインスタンスの起動中はお金がかかるので、ビルドしてるのを忘れて寝たりしなしでください!
docker imagesで以下のように表示されていたら成功です。

分析データをコンテナ内に展開しコンテナに入る
次に分析データをコンテナ内に展開し、コンテナに入ります。
手順としては以下の手順で行います。
ローカルのデータをGCEインスタンスにコピーする→コンテナを作成し、GCEインスタンスのデータをマウント
kaggle apiを使っても良いですが、ローカルのデータを分析したり、外部データを使用する時などに必要になってくるのでこの手順を踏みます。(逆にデータの大きさが100GBとかの場合はkaggle apiからデータを入れた方がいいです。)
まずサンプルとして以下のような適当なdatasetをダウンロードします。
https://www.kaggle.com/c/titanic/data
適当なディレクトリを作成し、そこにダウンロードしたデータを入れましょう。(今回はsample_datasetとします)

次にGCEインスタンスの中にデータを入れるためのディレクトリを作成します。今回はデモなので必要最低限で行います。
$ mkdir kaggle
$ cd kaggle
$ mkdir dataset
次に別のタブを開き以下でファイルを移動させます。
$ gcloud compute scp --recurse ローカルのファイルパス GCEインスタンス名:コピー先パス --zone "ゾーン名"
今回の場合だと(自分の場合)
$ gcloud compute scp --recurse ~/Desktop/sample_dataset sample-vm:~/kaggle/dataset --zone=us-west1-b
そうするとこのようにGCEインスタンス上にデータセットがコピーされています。

次にDockerのコンテナを起動させて、コンテナの中に入りましょう。
$ docker run -itd --runtime=nvidia -p 8888:8888 -v ~/kaggle/dataset/sample_dataset:/home/kaggle --name kaggle-gpu -h host kaggle/python-gpu-build /bin/bash
$ docker container start kaggle-gpu
$ docker container attach kaggle-gpu
ちなみにここで重要なのは -v ~/kaggle/dataset/sample_dataset:/home/kaggleの部分で、~/kaggle/dataset/sample_datasetがマウント元、/home/kaggleがマウント先になります。
ファイル編集などはマウントされているディレクトリで行うようにしましょう。
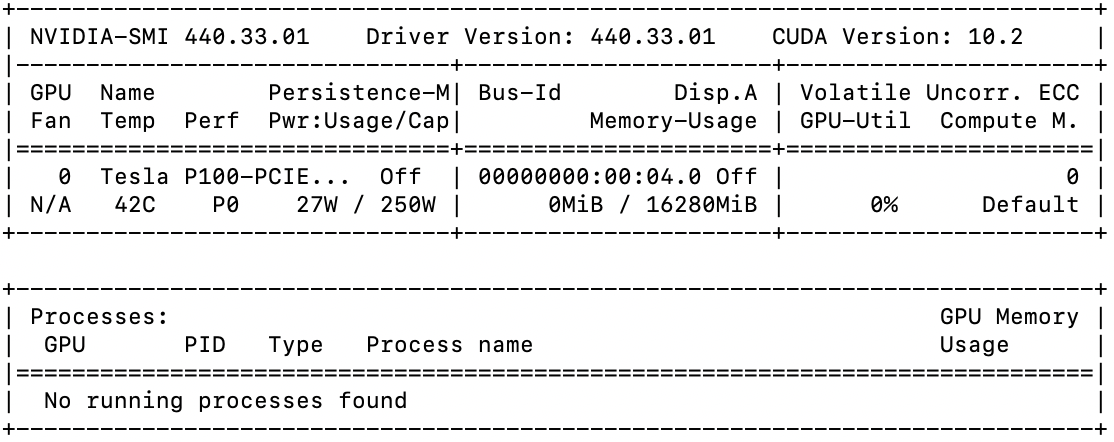
コンテナ内に入ったらパスを通してgpuが使えるかどうか確認しましょう。
$ export LD_LIBRARY_PATH=/usr/local/cuda/lib64
$ nvidia-smi
自分の環境では以下のように表示され、cudaのverが10.2で、GPUがP100と表示されていることから上手く使えていることがわかります。
次にコンテナ内からjupyter notebookを起動しましよう。
$ cd home
$ jupyter notebook --port 8888 --ip=0.0.0.0 --allow-root
次に別タブを開き、以下のコマンドで http://localhost:28888 からコンテナ内で起動させたノートブックに接続できるようにします。
$ gcloud compute ssh インスタンス名 --zone ゾーン名 -- -N -f -L 28888:localhost:8888
なお、自分の場合だと以下のようになります。
$ gcloud compute ssh sample-vm --zone us-west1-b -- -N -f -L 28888:localhost:8888
ブラウザからhttp://localhost:28888にアクセスし以下のような画面が表示されれば成功です
お疲れまでした!

なお、windows環境だと-fがいらず、で接続可能です。
$ gcloud compute ssh sample-vm --zone us-west1-b -- -N -L 28888:localhost:8888
コンテナ内で動作確認
それでは最後にGPUが動くかどうか試してみましょう。
以下のようにP100が使われています。
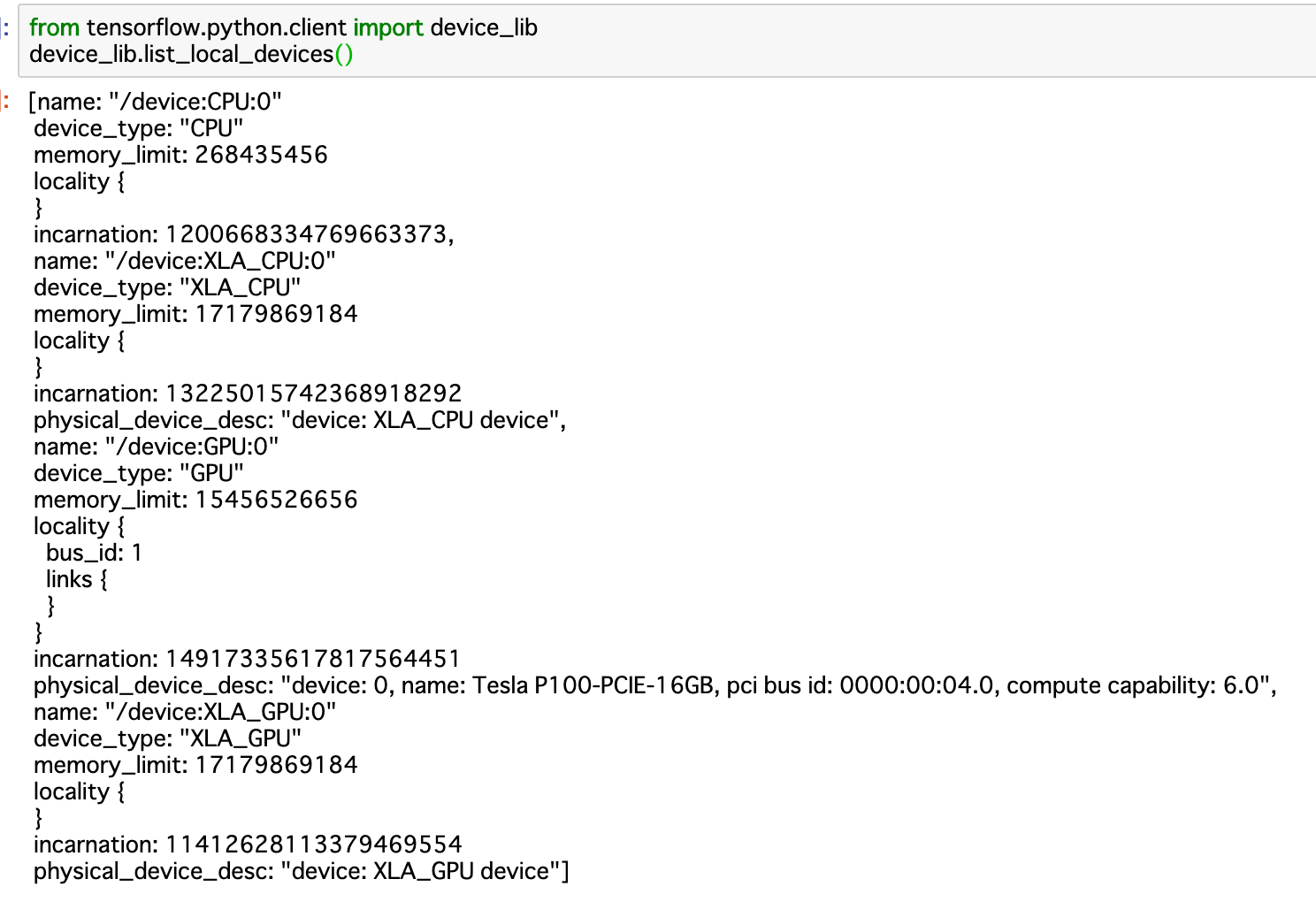
また,以下のようにCuDFが使えていることがわかります。
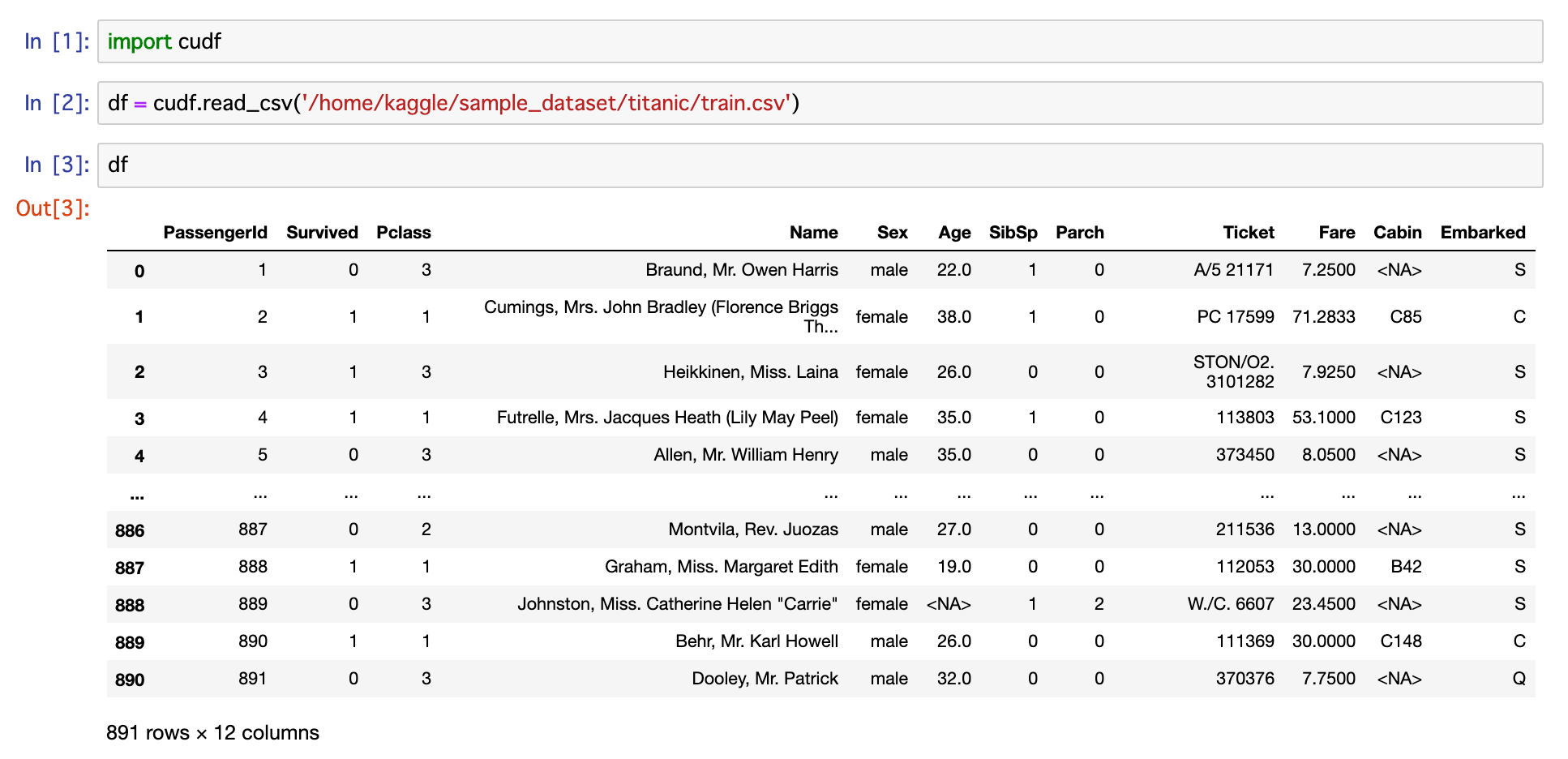
これでDocker+GCPを使ってGPUが動くkaggle環境(kaggle notebookと同じ)が完成しました!
なお、GCEインスタンスの起動中はお金がかかるので、こまめに止めることを気をつけてください!
お疲れ様でした!
また、適当にnotebookを作成してみてください。
GCEインスタンスを止めた後でも反映されたかを試すために利用します。
自分はsample_dataset以下にsample.ipynpを作成しました。
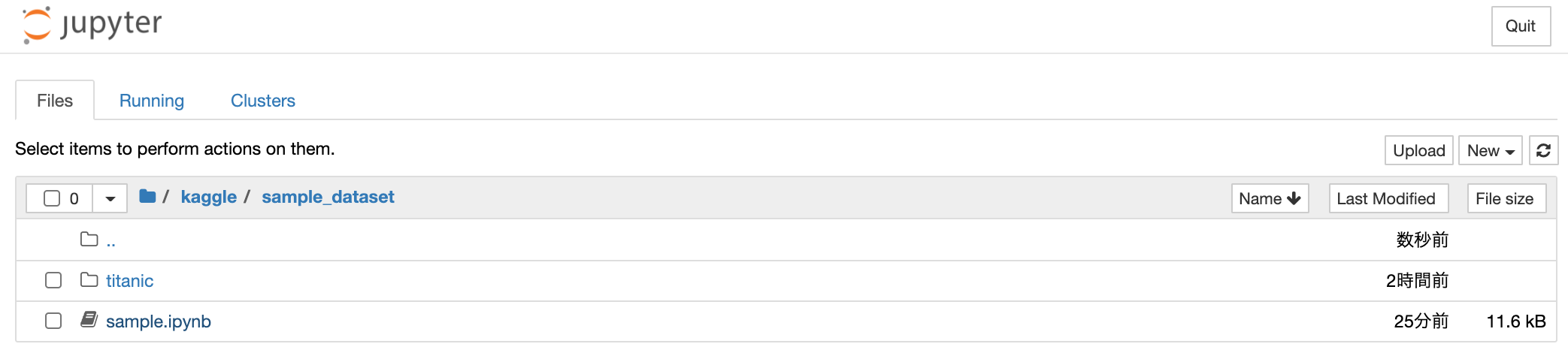
再開方法
最後に一度停止させたGCEインスタンスに入り、コンテナを起動する方法を紹介します。
まずGCPのプロジェクトからGCEインスタンスを再起動させます。
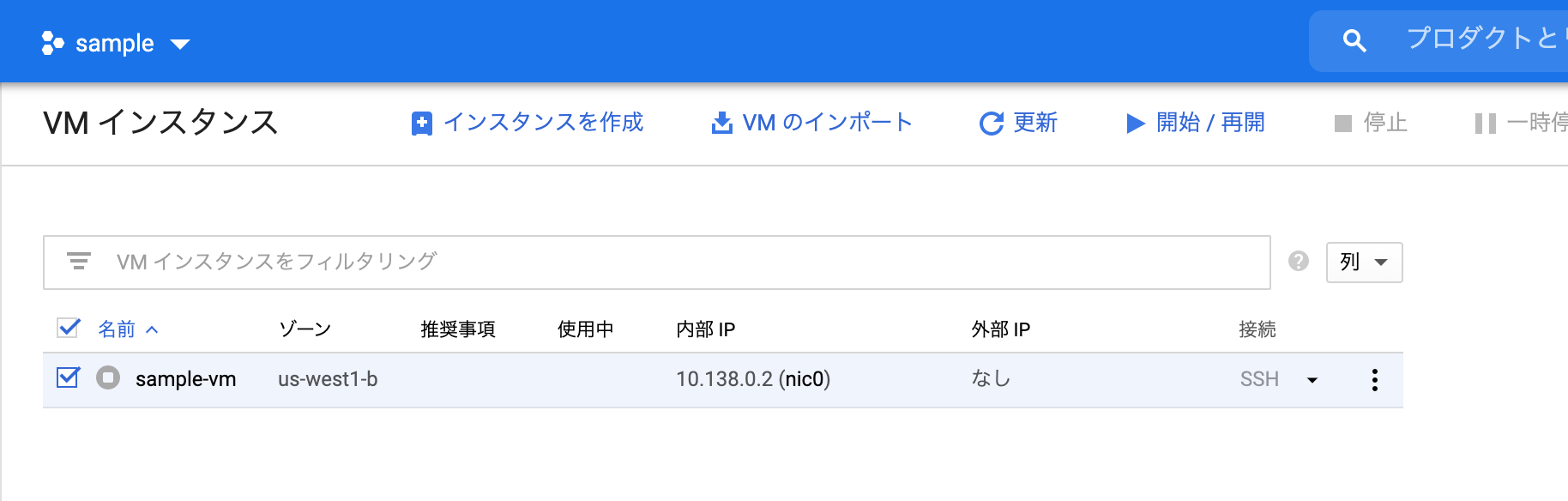
次にインスタンスの再起動に成功したら以下のコマンドでローカルからインスタンス内に入ります。
$ cloud compute ssh sample-vm --zone us-west1-b
以下のコマンドでコンテナの状態を確認しましょう。
$ docker ps -a
以下のように表示されていればOKです。

以下のコマンドでコンテナをrestartし、コンテナ内に入りましょう。
$ docker container restart kaggle-gpu
$ docker container attach kaggle-gpu
その後コンテナ内でhomeディレクトリに移動し、jupyter notebookを起動します。
$ cd home
$ jupyter notebook --port 8888 --ip=0.0.0.0 --allow-root
さらに別タブを開いて以下のコマンドでhttp://localhost:28888で開けるようにします。
$ gcloud compute ssh インスタンス名 --zone ゾーン名 -- -N -f -L 28888:localhost:8888
なお、自分の場合だと以下のようになります。
$ gcloud compute ssh sample-vm --zone us-west1-b -- -N -f -L 28888:localhost:8888
http://localhost:28888にアクセスするとjupyter notebookにアクセスすることができます。
GCEインスタンス停止前に作成したnotebookがあることを確認してください。(マウントしているのでGCEインスタンスからでも確認することができます)
以上で再開方法は終わりです。
ちなみに作業を終えるときはctrl+cでnotebookを終了し
$ exit
で抜けることができます。(再開時はやはりrestart&attachです)
何度もいいますが。お金がかかるのでこまめにGCEインスタンスは停止してください
おまけ(自動補完)
おまけにデフォルトの設定のままでは非常に使いにくいのでjupyter notebookに自動補完機能をつける方法を説明します。
コンテナの中に入り以下のコマンドを実行します。
$ pip install jupyter-contrib-nbextensions
$ pip install jupyter-nbextensions-configurator
$ jupyter contrib nbextension install
$ jupyter nbextensions_configurator enable
次にkaggle notebookを開き、タブのところに「」という項目が増えているのでNbextensionsからHinterlandを有効にします。
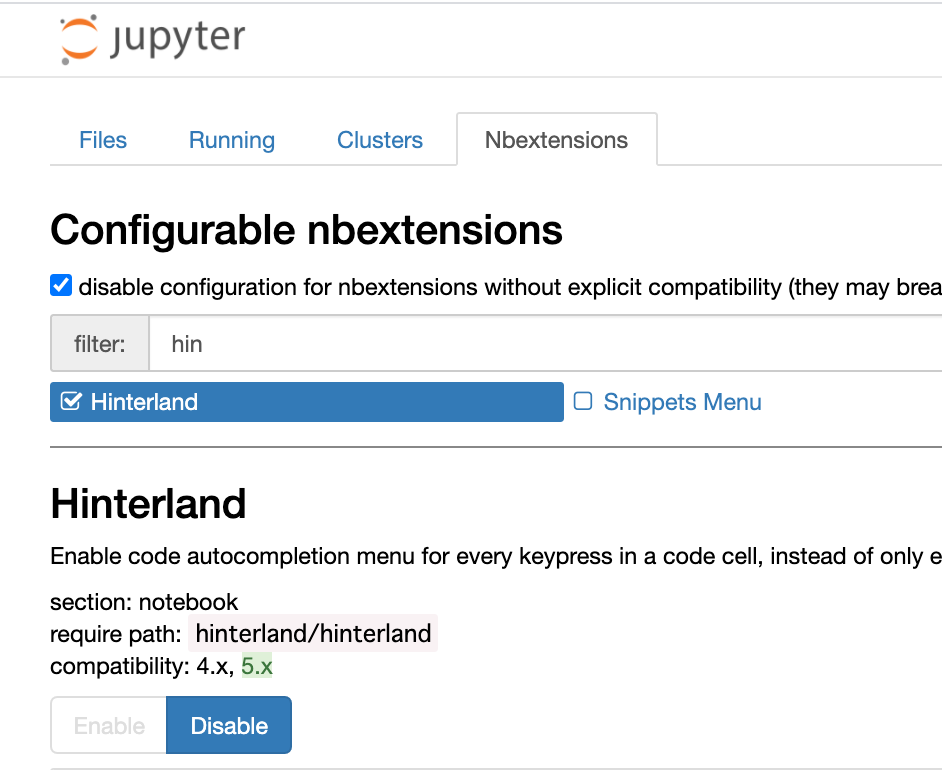
これで自動補完が可能になります。
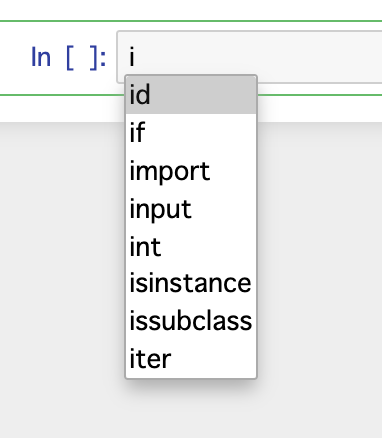
以上で備忘録は終わりです!
動かないところがあったらコメントで教えてください!
よろしくお願いします!