本記事の内容は以下の通りです。
- https://databricks.com/blog/2022/03/16/how-to-speed-up-data-flow-between-databricks-and-sas.html [2022/4/5時点]の翻訳
- 一部私の方で補足
※翻訳引用箇所は全てこの段下げで表現します。
DatabricksとSAS間のデータフローを高速化するには
この記事は、DatabricksとT1Aの共同投稿です。T1Aのソリューションアーキテクト、Oleg Mikhov氏の寄稿に感謝します。
本記事は、Databricks Lakehouse PlatformとSASを連携させる際のベストプラクティスに関するブログシリーズの最初の記事です。
以前のDatabricksブログポストでは、SASの開発者にDatabricksとPySparkを紹介しました。
参考
前回ブログ記事:Introduction to Databricks and PySpark for SAS Developers
上記の和訳:SAS開発者のためのDatabricksとPySpark入門
今回の記事では、SASとDatabricks Lakehouse Platformの間でデータをやり取りする方法と、データの流れを高速化する方法について説明します。
今後の記事では、両テクノロジーを組み合わせた効率的なデータおよび分析パイプラインの構築についてご紹介していきます。データドリブンな企業は、絶えず高まるビジネス需要に対応するため、Lakehouseプラットフォームを急速に導入しています。
Lakehouseプラットフォームは、データプラットフォームやアーキテクチャの構築を望む企業にとってニューノーマルとなっています。
近代化には、データ、アプリケーション、またはその他のビジネス要素をクラウドに移行することが伴います。
しかし、クラウドへの移行は徐々に行われるものであり、レガシー投資をできるだけ長く活用し続けることがビジネスクリティカルなのです。
このような背景から、多くの企業では、複数のデータおよび分析プラットフォームを持ち、それらのプラットフォームが共存・補完し合う傾向にあります。
その1つが、SASとDatabricks Lakehouseの組み合わせです。
2つのプラットフォームを効率的に連携できるようにすることで、以下のような多くのメリットがあります。
- クラウドプラットフォームの大規模でスケーラブルなデータストレージ機能
- 並列処理機能でネイティブに構築されたApacheSpark™などのテクノロジーを使用した、より優れた計算能力
- Delta Lakeによるデータガバナンスと管理で、より高いコンプライアンスを実現
- シンプルなアーキテクチャでデータ分析基盤のコストを低減
いくつかの一般的なデータサイエンス・データ分析のユースケースおよび観察された理由は次のとおりです。
- SASの実践者は、コア統計パッケージにSASを活用して、データ管理、ELTタイプの処理、およびデータガバナンスにDatabricks Lakehouseを使用しながら、規制要件を満たす高度な分析出力を開発します。
- SASで開発された機械学習モデルは、LakehouseプラットフォームのApacheSparkエンジンの並列処理アーキテクチャを使用して大量のデータでスコアリングされます。
- SASデータアナリストは、Databricks SQLエンドポイントと高帯域幅コネクタを使用して、アドホック分析とレポート作成のためにLakehouseプラットフォームの大量のデータにすばやくアクセスできます。
- クラウドアーキテクチャとオンプレミスのSASプラットフォームの両方を含むハイブリッドワークストリームを確立することにより、クラウドの近代化と移行を容易にします。
しかし、この共存のための重要な課題は、2つのプラットフォーム間でどのようにデータを性能よく共有するかということです。
本ブログでは、T1Aがお客様向けに実施したベストプラクティスと、DatabricksとSAS間のデータ移動の異なる方法を比較したベンチマーク結果を紹介します。シナリオ
最も一般的なユースケースは、SASの開発者がLakehouseのデータにアクセスしようとする場合です。
両テクノロジーを含む分析パイプラインでは、DatabricksからSASに移動するデータと、SASからDatabricksに移動するデータの両方向のデータフローが必要です。
- SASからDelta Lakeにアクセスする:SASユーザーは、SASプログラミング言語を使用してDelta Lakeのビッグデータにアクセスしたいと考えています。
- DatabricksからSASのデータセットにアクセスする:Databricksユーザーは、SASデータセット(一般的にはsas7bdatデータセット)にDataFrameとしてアクセスし、Databricksパイプラインで処理するか、Delta Lakeに格納して企業全体でアクセスすることを希望しています。
今回のベンチマークテストでは、以下の環境設定を使用しました。
- クラウドプラットフォームとしてMicrosoft Azure
- SAS 9.4M7 on Azure (シングルノード Standard D8s v3 VM)
- Databricks runtime 9.0, Apache Spark 3.1.2 (2ノード Standard DS4v2クラスタ)
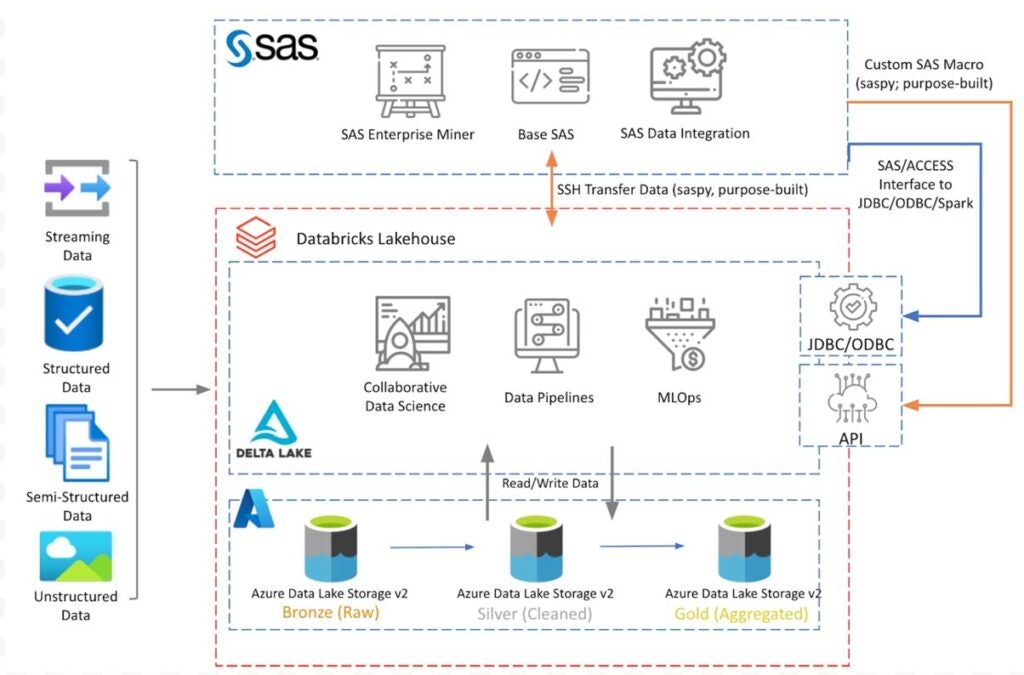
下記の図は、説明したコンポーネントを用いたアーキテクチャの概念図です。
Databricks Lakehouseは、Delta LakeのメダリオンアーキテクチャでAzure Data Lakeストレージ上に設置されています。
Azure VMにインストールされたSAS 9.4は、以下のセクションで説明する接続オプションを使ってDatabricks Lakehouseに接続し、データの読み取り/書き込みを行います。
上図は、Azure上に展開されたDatabricksの概念的なアーキテクチャを示したものです。
他のクラウドプラットフォームでも同様のアーキテクチャになります。
このブログでは、SAS 9.4プラットフォームとの連携についてのみ説明します。
後日のブログポストでは、SAS ViyaからLakehouseデータにアクセスするために、この議論を拡張する予定です。SASからDelta Lakeへのアクセス
SAS プログラムで処理する必要のある Delta Lake のテーブルがあると想像してください。
このテーブルにアクセスする際、データの整合性やデータ型の互換性の問題を回避しつつ、最高のパフォーマンスを発揮させたいと思います。
データの整合性と互換性を実現するには、さまざまな方法があります。以下では、いくつかの方法を取り上げ、使いやすさとパフォーマンスについて比較します。
テストでは、KaggleのeCommerce behaviorデータセット(5.67GB, 9 columns, ~ 42 million records)を使用しました。
データソースクレジット:マルチカテゴリーストアのeコマース行動データとREES46マーケティングプラットフォーム。テスト方法
1. SAS/ACCESS インターフェースコネクタの使用方法
従来、SASユーザーはSAS/ACCESSソフトウェアを活用して、外部データソースに接続していました。Databricksクラスタを指すSAS LIBNAMEステートメントを使用するか、SQLパススルー機能を使用するかのどちらかです。
現在、SAS 9.4では、3つの接続オプションが用意されています。SAS/ACCESS Interface to Sparkに、Databricksクラスタ専用の機能が追加されました。
このビデオで簡単なデモをご覧ください。ビデオではSAS Viyaについて触れていますが、SAS 9.4でも同じことが言えます。
これらのコネクタの使用方法に関するコードサンプルは、こちらのgitリポジトリに掲載されています:T1A Git - SAS Libraries Examples2. saspyパッケージの使用
SAS Instituteのオープンソースライブラリであるsaspyを使用すると、Databricks Notebookユーザはノートブック内のPythonセルからSASサーバ内のコードを実行したり、SASデータセットからPandas DataFrameへのデータのインポートとエクスポートを行ったりすることができるようになります。
このセクションの焦点は、SASプログラマがSASプログラミングを使ってLakehouseデータにアクセスすることなので、この方法は次に述べる目的別統合方法と同様にSASマクロプログラムでラップされています。
このパッケージでより良いパフォーマンスを得るために、char_lengthオプションを定義した構成でテストしました(詳細はこちら)。
このオプションにより、データセットの文字フィールドの長さを定義することができます。
このオプションを使用したテストでは、さらに15%の性能向上が見られました。
環境間のトランスポート層には、SASサーバーにSSH接続した状態でsaspyの設定を使用しました。3. 専用プログラムを書く
上記の2つの方法にはそれぞれ長所がありますが、次節(テスト結果)で述べるように、これまでの方法のいくつかの欠点を解決することで、さらに性能を向上させることができます。
そこで、SASユーザーのための性能と使いやすさを第一に考え、SASマクロベースの統合ユーティリティを開発しました。
SASマクロは、DatabricksプラットフォームやApache Spark、Pythonに関する知識がなくても、既存のSASコードに簡単に統合することが可能です。
このマクロは、Databricks APIを使用して多段階の処理をオーケストレーションするものです。
- 提供されたSQLクエリに従ってデータをクエリおよび抽出し、Spark SQL分散処理機能に依存して、結果をDBFSにキャッシュするようにDatabricksクラスターに指示します。
- データセットを圧縮して、SSH経由でSASサーバー(GZIPのCSV)に安全に転送します。
- データを解凍してSASにインポートし、SASライブラリでユーザーが利用できるようにします。
このステップでは、Databricksデータカタログの列メタデータ(列の種類、長さ、形式)を活用して、SASでの一貫性のある正確で効率的なデータ表示を実現します。可変長データ型については、統合は、以下のようなユーザー要件に最も合うものに応じて、異なる設定オプションをサポートすることに注意してください。
- 構成可能なデフォルト値を使用する
- 最大値を特定するため先頭10,000行(+行頭)を読み込む
- 最大値の特定するためにデータセットの列全体を読み込む
コードの簡易版はこちら:T1A Git - SAS DBR Custom Integration
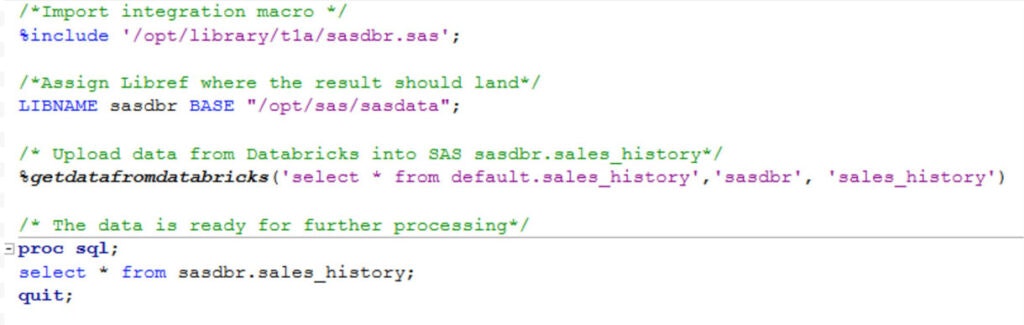
このSASマクロのエンドユーザーによる使用法は次のようになり、次の3つの入力が必要です。
- Databricks からデータを抽出するためのSQLクエリ
- データが到達する必要があるSASライブラリ参照名
- SASデータセット名
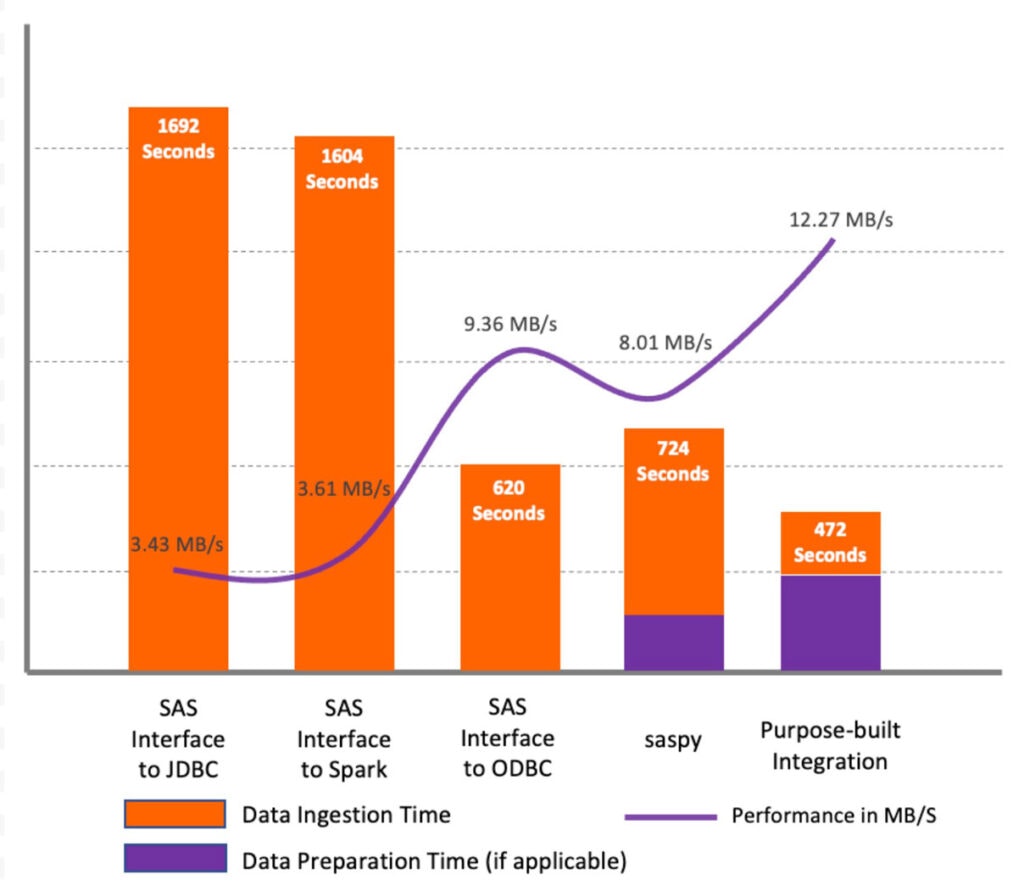
テスト結果
上のプロットに示すように、テストデータセットでは、SAS/ACCESS Interface to JDBCとSAS/ACCESS Interface to Apache Sparkが同様の性能を示し、他の手法と比較して低いパフォーマンスであることを示しています。
その主な理由は、JDBCのメソッドは、SASデータセットに適切な列長を設定するために、データセット内の文字列をプロファイルしないことです。
その代わりに、すべての文字列タイプ(StringとVarchar)のデフォルトの長さを765シンボルとして定義しています。
そのため、最初のデータ検索時だけでなく、その後のすべての処理でパフォーマンスの問題が発生してしまい、さらにストレージも大量に消費されます。
私たちのテストでは、5.6GBのソースデータセットに対して、WORKライブラリに216GBのファイルを作成して終了しました。
しかし、SAS/ACCESS Interface to ODBCでは、デフォルトの長さが255シンボルであったため、パフォーマンスが大幅に向上する結果となりました。SAS/ACCESS Interfaceのメソッドを使用することは、既存のSASユーザーにとって最も便利なオプションです。これらのメソッドを使用する場合、いくつかの重要な考慮事項があります。
- どちらのソリューションも暗黙のクエリパススルーをサポートしていますが、いくつかの制限事項があります。
- SAS/ACCESS Interface to JDBC/ODBC は、PROC SQL 文のパススルーのみをサポートします。
- SAS/ACCESS Interface to Apache Sparkは、PROC SQLのパススルーに加え、ほとんどのSQL関数のパススルーをサポートしています。
この方法では、一般的なSASプロシージャをDatabricksクラスタにプッシュすることも可能です。- 以前説明した文字列の長さ設定に関する問題があります。
回避策として、DBSASTYPEオプションを使用して、SASテーブルのカラム長を明示的に設定することをお勧めします。
これは、データセットのさらなる処理に役立ちますが、Databricksからのデータの最初の取得には影響しません。- SAS/ACCESS Interface to Apache Spark/JDBC/ODBC では、パススルー機能により、異なる libname として割り当てられた異なる Databricks データベース(スキーマ)のテーブルを同じクエリで結合(join)することができません。
その代わり、SASでテーブル全体をエクスポートし、SASで処理することが発生します。
回避策として、異なるデータベース(スキーマ)のテーブルに基づくビューを含む専用のスキーマをDatabricksで作成することをお勧めします。SAS/ACCESS Interface to JDBC/Spark方式と比較すると、saspy方式は若干性能が良いです。
しかし、saspyライブラリはpandas DataFrameしか扱えず、Apache Sparkドライバープログラムへの負荷が大きく、DataFrame全体をメモリ上に引き込む必要があることが大きな欠点と言えます。専用プログラムの使用は、テストした他の手法と比較して、最も優れた性能を示しました。
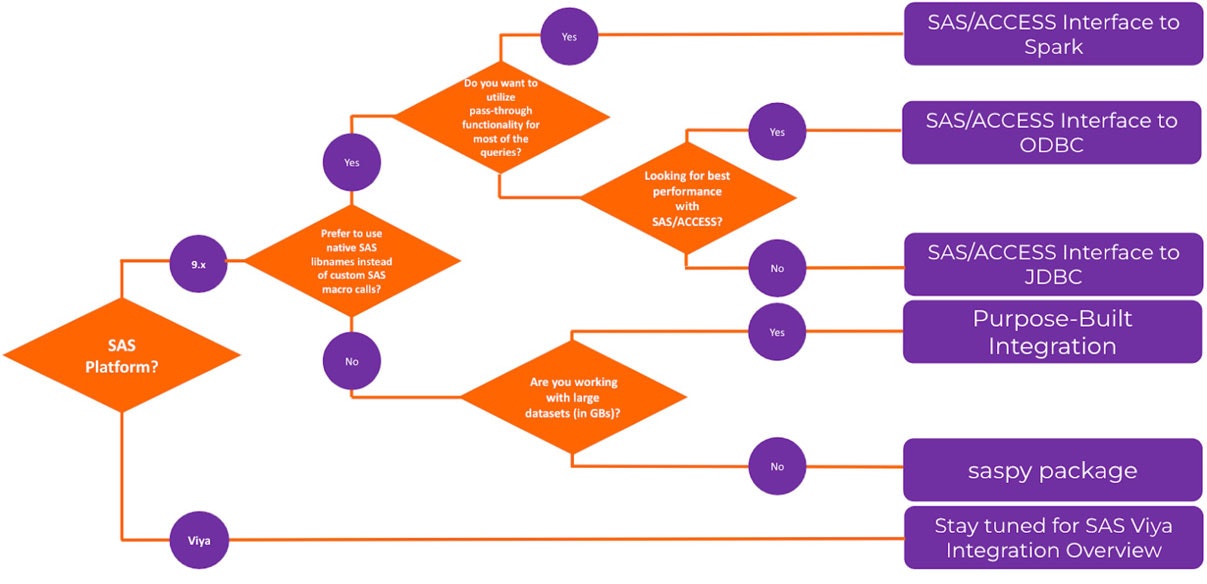
下記の図は、議論された手法の中から選択する際のハイレベルなガイダンスを示したフローチャートです。
DatabricksからSASデータセットにアクセスする
このセクションでは、Databricks開発者がSASデータセットをDelta Lakeに取り込み、Databricksでビジネスインテリジェンス、ビジュアル分析、その他の高度な分析のユースケースに利用できるようにしたいというニーズに対して、(これまでに説明したいくつかの方法はここで適用できますが)いくつかの追加方法について説明します。
テストでは、SASサーバー上のSASデータセット(sas7bdat形式)から開始し、最終的にこのデータセットをSpark DataFrameとしてDatabricksで利用できるようにしています(遅延呼び出しが適用できる場合は、DataFrameにデータをロードして全体の時間を測定するように強制しています)。
このシナリオでは、前のシナリオで使用したのと同じ環境と同じデータセットを使用しました。
このテストでは、SASユーザーがSASプログラミングを使用してDelta Lakeにデータセットを書き込むというユースケースは考慮していません。
これには、クラウドプロバイダーのツールや機能を考慮する必要がありますが、これについては後日のブログポストで説明します。テスト方法
1. SASのsaspyパッケージの使用
saspyライブラリのsd2dfメソッドは、データ転送にSSHを使用し、SASデータセットをpandas DataFrameに変換するものです。
転送中のステージングストレージ(Memory、CSV、DISK)にはいくつかのオプションがあります。
我々のテストでは、PROC EXPORT csv fileとpandas read_csv()メソッドを使用するCSVオプションが、大きなデータセットに推奨されるオプションであり、最高の性能を示しました。2. pandasのメソッドの使用
pandasは初期のリリースから、pandas.read_sas APIを使用してsas7bdatファイルを読み込むことができました。
SASファイルは、pythonプログラムからアクセス可能である必要があります。
一般的には、FTP、HTTP、またはS3などのクラウドオブジェクトストレージに移動する方法が使用されます。
我々はむしろ、SCPを使用してリモートのSASサーバーからDatabricksクラスタにSASファイルを移動する、よりシンプルな方法を使用しました。3. spark-sas7bdatの使用
Spark-sas7bdatは、Apache Spark専用に開発されたオープンソースのパッケージです。
pandas.read_sas()メソッドと同様に、SASファイルがファイルシステム上に存在する必要があります。
今回は、リモートのSAS ServerからSCPを利用してsas7bdatファイルをダウンロードしました。4. 専用プログラムを書く
また、利便性と性能のバランスを重視し、従来の手法を用いる方法も検討されました。
この方法は、コアな統合機能を抽象化し、Databricks Notebookから実行されるPythonライブラリとしてユーザーが利用できるようにしたものです。
- saspyパッケージを使用して、以下を実行するSASマクロコードを(SASサーバー上で)実行する。
- SASコードでsas7bdatをCSVファイルに書き出す。
- CSVファイルをGZIPに圧縮する。
- 圧縮ファイルをDatabricksクラスタドライバノードへSCPで移動する。
- CSV ファイルを解凍する。
- CSV ファイルを Apache Spark DataFrame に読み込む。
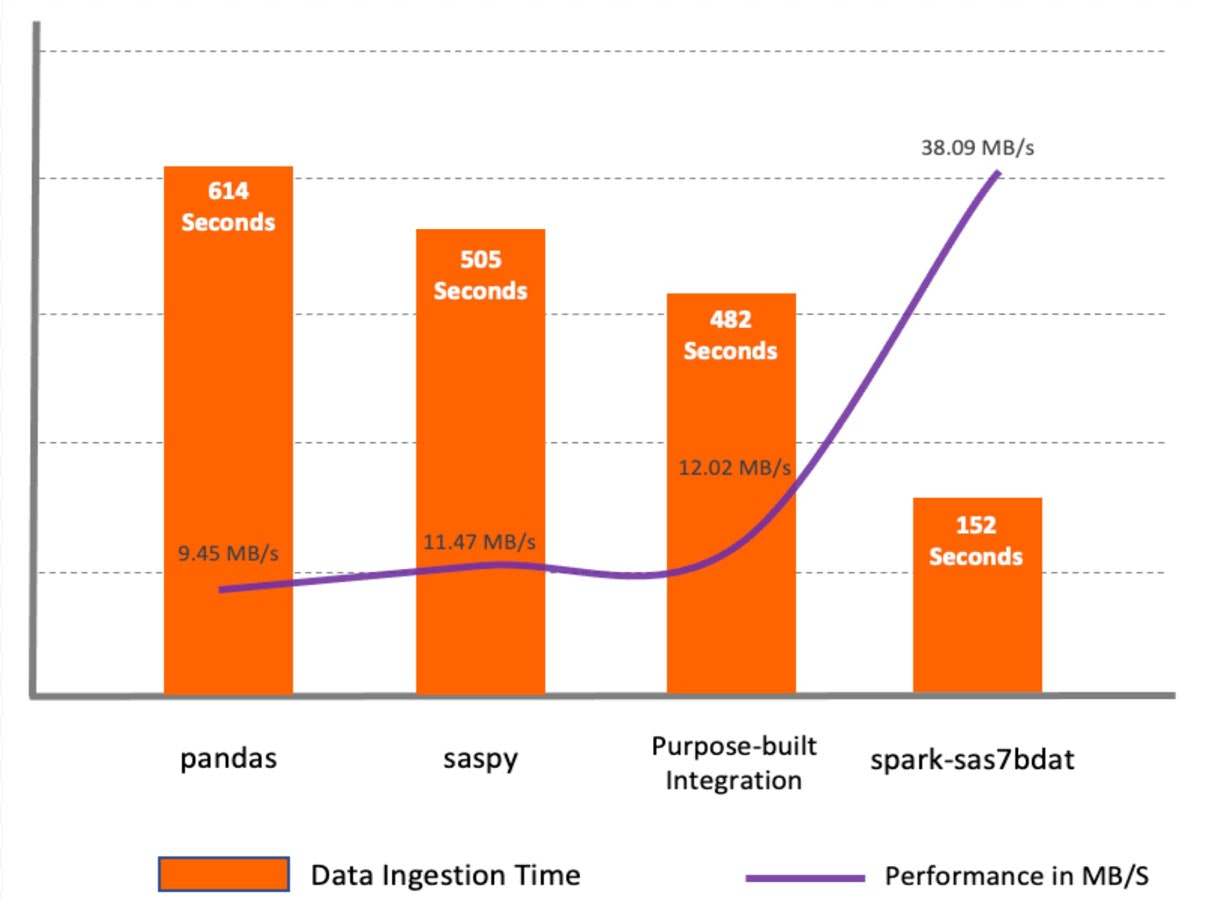
テスト結果
spark-sas7bdatは、すべての手法の中で最も高い性能を示しました。
このパッケージは、Apache Sparkの並列処理をフルに活用したものです。
sas7bdatファイルのブロックをワーカーノードに分散して配置します。
この方式の大きな欠点は、sas7bdatが独自のバイナリ形式であり、このバイナリ形式をリバースエンジニアリングしてライブラリを構築したため、すべての種類のsas7bdatファイルをサポートしていないことと、公式(商用)ベンダーサポートがされていないことです。saspyとpandasのメソッドは、どちらも単一ノード環境向けに構築されており、pandas DataFrameにデータを読み込む際に、Spark DataFrameとしてデータを利用する前に追加のステップを必要とするという点で類似しています。
専用プログラムの使用は、CSVからApache Spark APIを通じてデータを読み込むため、saspyやpandasと比較してより良いパフォーマンスを示しました。
spark-sas7bdatパッケージの性能には勝てませんでしたが、SASサーバー上で中間データ変換を追加できるため、場合によっては便利な方法です。まとめ
Databricks Lakehouseを構築する企業が増えており、Lakehouseから他のテクノロジーを介してデータにアクセスする方法が複数存在します。
このブログでは、SASの開発者、データサイエンティスト、その他のビジネスユーザーがLakehouse内のデータを活用し、その結果をクラウドに書き込む方法について説明していきます。
今回の実験では、DatabricksとSASの間でデータを読み書きする方法をいくつか試しました。
これらの方法は、性能だけでなく、利便性や提供される追加機能によっても異なります。このテストでは、SAS 9.4M7プラットフォームを使用しました。SAS Viyaは、議論されているアプローチのほとんどをサポートしていますが、追加のオプションも提供しています。ここで取り上げた手法やその他の特殊な統合アプローチについてもっと知りたい場合は、Databricksまたはdatabricks@t1a.comまでお気軽にご連絡ください。
このブログシリーズの今後の記事では、SASとDatabricksを使用した統合データパイプライン、エンドツーエンドワークフローの実装におけるベストプラクティス、およびDatabricksクラスタにおけるSASモデルのスコアリングにSAS In-Databaseテクノロジーを活用する方法についてご紹介する予定です。
SAS®およびその他すべてのSAS Institute Inc.の製品名またはサービス名は、米国およびその他の国々におけるSAS Institute Inc.の登録商標または商標です。®は米国での登録商標です。
はじめましょう
Databricks Academyのコース「Databricks for SAS Users」で、SASプログラミング言語コンストラクトのPySparkプログラミングの基本的なハンズオンを体験してください。
また、SASチームのETLワークロードのDatabricksへの導入とベストプラクティスを可能にするための支援方法については、弊社にお問い合わせください。
(注)訳時点でDatabricks Academyの「Databricks for SAS Users」コースはリンク切れになっていました。
Partner-Academy上では見つけることができたので参考として記載します。(要アカウント)
Databricks for SAS Users (Persona-Based Resources for Databricks Customers)