本記事の内容は以下の通りです。
https://databricks.com/jp/blog/2021/12/07/introduction-to-databricks-and-pyspark-for-sas-developers.html [2021/12/15時点]の翻訳
- SAS技術者としての個人的な感想
- 実際にSAS技術者がDataBricks、PySparkに触れてみて感じたこと
※翻訳引用箇所は全てこの段下げで表現します。
また、サンプルコードは全て上記リンク先記事からの引用となります。
SAS開発者のためのDatabricksとPySpark入門
この記事は、DatabricksとWiseWithDataの共同記事です。WiseWithDataの創設者兼社長のIan J. Ghent様、Pre-Sales Solutions R &D責任者のBryan Chuinkam様、Migration Solutions R&D責任者Ban (Mike) Sunに感謝します。
SAS®主導のデータ分析の時代から、技術は大きく進歩しました。
レイクハウスアーキテクチャは、データチームがさまざまなユースケース(データサイエンス、機械学習、リアルタイム分析、あるいは従来のビジネスインテリジェンスやデータウェアハウス)のために、あらゆる種類のデータ(構造化、半構造化、非構造化)を、1つのデータのコピーから処理できるようにします。
パフォーマンスと機能、そしてエレガントさとシンプルさが融合し、今日の世界で他に類を見ないプラットフォームが誕生したのです。
PythonやApache Spark™などのオープンソース言語が、データエンジニアやデータサイエンティストの第一言語となったのは、それらがシンプルでアクセスしやすいということが大きな理由です。
多くのSASユーザーは、スキルセットの近代化に果敢に取り組んでいます。
DatabricksとPySparkは覚えやすいように設計されてはいますが、SAS経験豊富な技術者にとっては試行錯誤の連続となる可能性があります。
Databricksはオープンでシンプルなプラットフォームアーキテクチャをコンセプトとしており、最新のデータおよびAIクラウドプラットフォームでソリューションを構築したい人なら誰でも簡単に利用できることは、SAS技術者にとってもメリットになってきます。
この記事では、新旧のデータ分析の構成要素をマッピングしていきます。
SASとDataBricksの共通項
SASとDatabricksは、下記のような共通点があります。
- 統一されたプラットフォームとして、一から設計されていること
- SQLと他言語といった複数のプログラミングパラダイムの混在を柔軟に行えること
- 組み込みの変換とデータ集計機能をサポートしていること
- 線形回帰、ロジスティック回帰、決定木、ランダムフォレスト、クラスタリングなどのハイエンドな分析機能をサポートしていること
- 基盤となるデータソースの詳細を抽象化するセマンティックデータレイヤーをサポートしていること
ここからはこの共通項について掘り下げていきます。
SAS DATAステップとDataFramesの比較
SAS DATAステップは、SAS言語の中で最も強力な機能であると言っても過言ではありません。
論理和、結合、フィルタリング、列の追加、削除、修正に加え、条件付きやループといったビジネスロジックをわかりやすく記述することができます。
熟練のSAS開発者は、これらを活用して大規模なDATAステップパイプラインの構築や、コードの・I/Oの最適化を行っています。
PySparkのDataFrame APIも、これと同じ機能をほとんど持っています。
多くのユースケースにおいて、DataFrameパイプラインは同じデータ処理パイプラインをほぼ同じ方法で表現することができます。
重要なのは、DataFrameは超高速でスケーラブルであり、クラスタ全体で並列に動作することです(並列処理を管理する必要はありません)。
data df1;
set df2;
x = 1;
run;
data df1;
df1 = (
df2
.withColumn('x', lit(1))
)
SASにおいても、Viyaのインメモリ処理やDIの機能を利用したり、もしくは明示的にコーディングしたりすることで並列処理は実現できます。ただ、ViyaだとCASへのアップロードが必要だったり、DIのループ機能における並列処理は別のSASプロセスを立ち上げてその終了を待機する形だったりと何かしらの細工をする必要があり、「何も意識せずそのまま使える」といった類のものではない印象です。
もちろんそれぞれの特性を押さえて活用することは私もこれまでしてきましたしできるかと思いますが、意識しないでコーディングしても自動的に並列処理されるというのは大きな違いであるように感じました。
SAS PROC SQLとSparkSQLの比較
SQLは業界標準としてほぼすべてのツールである程度サポートされています。
SASでは、PROC SQLと呼ばれるSQLを使用できる明確なツールがあり、SASを全く知らない多くの人にとっても馴染みのある方法でSASデータソースと対話することができます。
PySparkでも、spark.sql()を呼び出すだけで、SQLを使用できます。
Apache Spark™では、SQL式の構文はDataFrame API内の多くの場所でサポートされています。
SQLエディタを備えたDatabricks SQLによってSQLクエリを高いパフォーマンスで実行することができます。
proc sql;
create table sales_last_month as
select
customer_id
,sum(trans_amt) as sales_amount
from sales.pos_sales
group by customer_id
order by customer_id;
quit;
sales['sales'].createOrReplaceTempView('sales')
work['sales_last_month'] = spark.sql("""
SELECT customer_id ,
sum(trans_amt) AS sales_amount
FROM sales
GROUP BY customer_id
ORDER BY customer_id
""")
上記を読んで真っ先に思うのは、「SASではPROC SQL内でSAS関数が使える」といった事かと思います。
ただこのあたりは(spark.sqlではなくDataFrame側にはなりますが)同様の関数が大体用意されているので、さほど困らないでしょう。
Base SASのPROCとPySpark DataFrame変換の比較
SASでは、あらかじめ用意された機能の多くをプロシージャ(PROC)にパッケージしています。
これには、データ集計や要約統計などの変換や変形、インポート/エクスポートなどが含まれます。
これらのPROCは、大規模なジョブにおける明確なステップまたはプロセスの境界を表します。
一方、PySparkにおける変換は、DataFrameパイプライン内でもどこでも使用でき、より柔軟な実装が可能となっています。(もちろん、個別のステップに分割することも可能です。)
proc means data=df1 max min;
var MSRP Invoice;
where Make = 'Acura';
output out = df2;
run;
df2 = (
df1.filter("Make = 'Acura'")
.select("MSRP", "Invoice")
.summary('max','min')
)
SASのPROCはそれこそ色々な事ができますが、プロシジャごとに設定項目が違うのを毎回調べながらやる形になるのが玉に傷です。(バグっぽいのを踏み抜く事もあります。)
PySparkはその点「やりたいことを実装できるだけの関数は用意しているから、うまく活用して手組みしてね」というスタンスに感じます。
PROCで書かれたコード自体の単純移植となると物によっては難しいですが、設計段階での思想に立ち返ることができればどちらも(好みこそあれ)大きな違いはないかなとは思います。
遅延実行 - SASの"run"ステートメントとPySparkのActionの比較
Sparkの遅延実行モデルは、非常に多くの最適化の基礎であり、PySparkがSASよりも非常に高速であることを可能にしています。
実はSASも(50年以上前に設計された言語にも関わらず)遅延実行をサポートしています。
SASで書かざるを得ない"run","quit"ステートメントがそれに当たります。
SASでは命令を複数定義することができますが、定義した命令は"run"が呼ばれるまで実行されません。
SASとPySparkの主な違いは、遅延実行ではなく、それによって可能になる最適化です。
SASでは残念ながら実行エンジンも遅延となるため、性能に貢献しないためほとんど使用されません。
PySparkの遅延実行モデルに戸惑ったときは、SASと同様にほとんど使用されないということを思い出してください。
PySparkのActionは、SASのrunステートメントのようなものです。
実際、PySparkでrun文のようにすぐに実行を開始したい場合(そして中間結果をディスクに保存したい場合)には、そのためのActionとして".checkpoint() "が用意されています。
data df1;
set df2;
x = 1;
run;
df1 = (
df2
.withColumn('x', lit(1))
).checkpoint()
実際のところ私はPySparkを学び始めてからcheckpoint周りは必要性があまり分からず、理解しないまま進めてしまっていました。
(他の言語から参入した人もそうなのかはあまり分かりませんが)
恐らく入門段階では特段意識する必要はないということなのでしょう。
高度な解析とSpark ML
過去45年間、SAS言語は統計学と機械学習のための重要な機能を蓄積してきました。
SAS/STATプロシージャは膨大な量の機能をパッケージ化しています。
一方、SparkMLには、STATの最新のユースケースの多くをカバーする機能が含まれていますが、よりまとまりのある一貫した方法になっています。
この2つのパッケージの顕著な違いの1つは、遠隔測定と診断に対する全体的なアプローチです。
SASでは、機械学習タスクを実行すると、あらゆる統計的測定の完全なダンプが得られます。
これは、現代のデータサイエンティストにとっては非効率的なものになっています。
一般的に、データサイエンティストは、モデルを評価するために使用したいモデル診断のうちの一部だけを必要とします。
そのため、SparkMLでは、それらの診断を要求に応じて取得できるAPIを提供することで、これまでとは異なる、よりモジュール化されたアプローチをとっています。
大規模なデータセットの場合、このアプローチの違いは、使い道のない統計量を計算するのを避けることで、パフォーマンスに大きな影響を与える可能性があります。
また、PySpark MLライブラリに含まれるものはすべて並列化されたアルゴリズムなので、より高速であることも特筆すべき点です。
シングルスレッドのロジスティック回帰モデルの方が若干適合度が高いように、全てのモデルが並列化した方が良いわけではないのは事実です。
しかし本質はそこではありません。より速いモデル開発は、より多くの反復と実験を意味し、それはより良いモデルにつながるのです。
proc logistic data=ingots;
model NotReady = Heat Soak;
run;
vector_assembler = VectorAssembler(inputCols=['Heat', 'Soak'], outputCol='features')
v_df = vector_assembler.transform(ingots).select(['features', 'NotReady'])
lr = LogisticRegression(featuresCol='features', labelCol='NotReady')
lr_model = lr.fit(v_df)
lr_predictions = lr_model.transform(v_df)
lr_evaluator = BinaryClassificationEvaluator(
rawPredictionCol='rawPrediction', labelCol='NotReady')
print('Area Under ROC', lr_evaluator.evaluate(lr_predictions))
上記のPySparkの例では、VectorAssembler APIを用いて入力列「Heat, Soak」を1つの特徴ベクトルにまとめています。
そして、SparkMLライブラリのLogisticRegressionアルゴリズムを用いて、変換されたデータフレームに対してロジスティック回帰モデルを学習しています。
AUC指標を表示するために、BinaryClassificationEvaluatorを使用し、学習済みモデルからの予測と実際のラベルを入力として使用します。
このモジュールを使用したアプローチは、選択したモデルのパフォーマンスメトリクスの計算において、より良いコントロールを提供します。
このあたりは、分析に詳しくないうちは何でも出してくれるSASの方が助かる面もある気はします。
(SASはSASで分析結果のテーブルへのアクセス方法がドキュメンテーションにも書いていなくてコード書いて漁らないといけなかったりするので、完勝ではないですが・・・)
最終的には「必要な部分だけ明示的に計算させる」方がパフォーマンスで優れるというのは確かかと思います。
SASとDataBricksの違い
SASとPySparkにはこれまで述べてきたような多くの共通点がある一方で、多くの相違点もあります。
SASの技術者がPySparkを学習する場合、これらの違いのいくつかは、ナビゲートが非常に困難な場合があります。
それらをいくつかの異なるカテゴリに分類してみましょう。
PySparkでネイティブに利用できないSASの機能もありますし、PySparkで別のツールやアプローチを必要とするものもあります。

エコシステムの違い
SASのプラットフォームは、買収した製品や社内で開発した製品の集合体であり、比較的うまく連携して動作しています。
Databricksはオープンスタンダードに基づいて構築されているため、何千ものツールを簡単に統合することができます。
Databricksで利用可能なSASベースのツールや機能の中から、同様のユースケースに対応したものをいくつか見てみましょう。
まずはSAS® Data Integration Studio (DI Studio)について見ていきます。
DI Studioは、複雑なメタデータ駆動型モデルを搭載し、SASエコシステムにおいて重要な役割を担っています。
DI Studioは主に、ETLワークロードの本番ジョブフローオーケストレーション機能を提供します。
Databricksでは、データエンジニアリングパイプラインはノートブックとジョブを使用して開発およびデプロイされます。
データエンジニアリングのタスクは、Apache Spark(ビッグデータETLのデファクトスタンダード)を使用しています。
DatabricksのDelta Live Tables(DLT)とジョブオーケストレーションは、Lakehouseアーキテクチャ上でのETLパイプラインの開発をさらに簡素化します。
DLTは、従来の手続き的な変換順序に代わって、ETLパイプラインを宣言的に作成する信頼性の高いフレームワークを提供します。
つまり、ユーザーは、結果に到達するために実行しなければならない順序付けられたステップを明示的に列挙することなく、パイプラインの望ましい結果を記述することができるのです。
DLTエンジンは、コンピュートフレームワークがこれらのプロセスを「どのように」実行すべきかを賢く判断します。
DI Studioが担うもう1つの重要な役割は、データのリネージ(系統)追跡機能です。しかしこの機能は、すべてを正しく設定し、すべてのコードノードにメタデータを手動で入力した場合のみ正しく機能します(非常に手間のかかる作業です)。これに対してDLTでは、生成されたパイプラインが自動的にデータセット間の依存関係を把握し、更新を行う際の実行順序の決定や、パイプラインのイベントログへの系統情報の記録に利用されるようになっています。
データサイエンティストの多くは非常に優れたコーダーですが、中にはポイント&クリックのデータマイニングツールを好む人もいます。
このような人たち(分析的でありながら深い技術的な知識を持っていない人たち)を指す言葉として「市民データサイエンティスト」という呼び方も出てきています。
SASでは、コーディングせずにモデルを構築するための非常に高価なツール、SAS® Enterprise Minerがあります。
このツールを利用することで、ユーザーはSASデータのサンプリング、探索、修正、モデル化、評価をマウス操作で行うことができます。
SASのもう一つのポイント&クリックツールは、SAS® Enterprise Guideと呼ばれ、SASプログラミングとポイント&クリック分析の両方に対する最も一般的なインターフェースです。
SASは構文が複雑なため、多くの人がポイント&クリックツールを活用してSASコードを生成し、それを自分のニーズに合わせて変更する形で利用しています。

PySparkでは、APIがよりシンプルで一貫しているため、ヘルパーツールの必要性が低くなっています。
Databricks Notebookは、データのグラフ化のようなポイント&クリックでできるタスクをコーディングを不要で行うことができます。
Databricksでのデータの探索的分析とモデル開発は、Databricks NotebooksからDatabricks ML Runtimeを使って行われます。
Databricks AutoMLを使用すると、ポイント&クリックで素早くモデルをトレーニングしてデプロイすることができます。
Databricks AutoMLは、MLflow Trackingとベストプラクティスを統合したベースラインモデルを含む編集可能で共有可能なノートブックを生成し、新しいプロジェクトの出発点とする「ガラスボックス」的アプローチを採用しています。
8080 Labsの買収により、Databricksのノートブックとワークスペースにローコード/ノーコードによるデータ探索と分析の実行が新機能として追加されます。
8080 Labsのbamboolibパッケージは、ポイント&クリックで実行されるユーザーアクションのPythonコードを自動的に生成します。
DatabricksのオープンソースDelta Lakeを利用したLakehouseアーキテクチャは、データアーキテクチャを簡素化し、すべてのデータをデータレイクに一旦保存して、そのデータに対して直接AIやBIを実行することを可能にします。
上の図は、AWS上に展開されたDatabricksのリファレンスアーキテクチャを示しています(GCP,Azureといった他のクラウドプラットフォームでも同様のアーキテクチャとなります)。
データエンジニアは、Apache ParquetやORCなどのオープンファイル形式を簡単に利用でき、パフォーマンスの最適化、トランザクションのサポート、スキーマの適用、ガバナンスも組み込まれています。
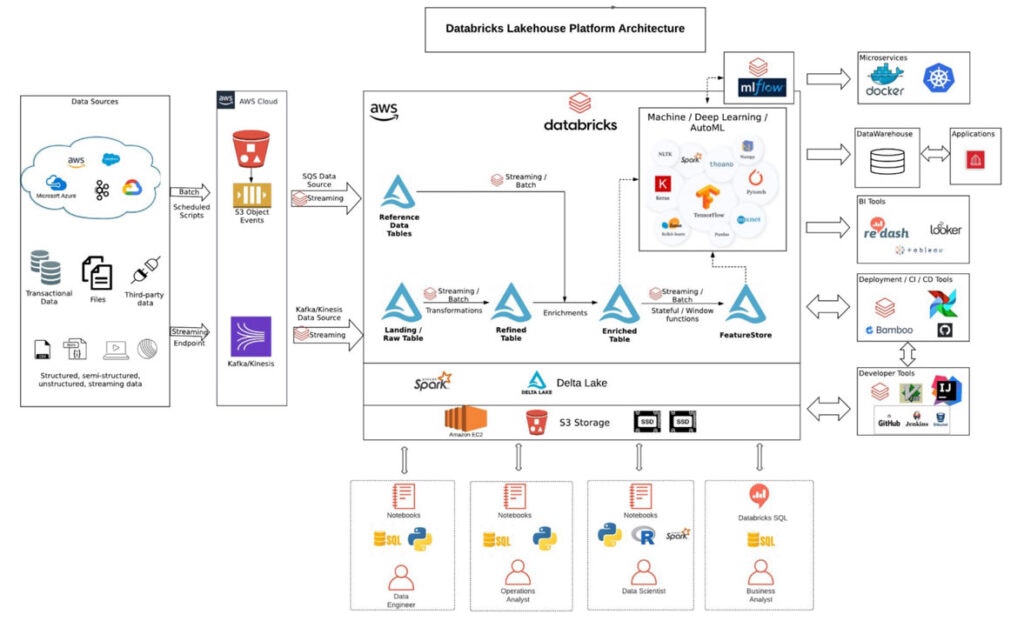
データエンジニアは、構造化ストリーミングとDelta Lakeテーブルが組み込まれたストリーミングデータを使用するために、配管作業を減らし、コアデータ変換に集中する必要があります。
MLはレイクハウスの一級市民であり、データサイエンティストはダッシュボードを共有するためにサブサンプリングやデータ移動に無駄な時間を費やす必要がありません。
データアナリストと運用アナリストは、他のデータ関係者と同じデータレイヤーで作業し、使い慣れたSQLプログラミング言語を使ってデータ分析を行うことができます。
アプローチの違い
SASプログラミングの機能の多くはPySparkにも存在しますが、いくつかの機能は全く異なる方法で使用されることを意図しています。
ここでは、PySparkで効果的に使用するために適応する必要があるタイプの違いの例をいくつか紹介します。
手続き型SASとオブジェクト指向型PySparkの違い
SASでは、ほとんどのコードがDATAステップまたはプロシージャとして終わります。
どちらの場合も、使用する入力データセットと出力データセットを常に明示的に宣言する必要があります。
一方、PySparkのDataFrameはオブジェクト指向のアプローチを採用しており、DataFrameの参照がその上で実行可能なメソッドに付加されています。
ほとんどの場合、このアプローチの方がはるかに便利で、現代のプログラミング技術に適合しています。
しかし、特にオブジェクト指向のプログラミングをしたことがない開発者にとっては、慣れるまで少し時間がかかるかもしれません。
proc sort data=df1 out=dedup nodupkey;
by cid;
run;
dedup=df1.dropDuplicates(['cid']).orderBy(['cid'])
SASでも%sysfuncを用いたマクロ変数の計算とかは近い性質を持っていると思うので、それがデータセットにも適用されるだけだと思えばそこまで困らないような気もします。
(大体の人はオブジェクト指向言語も触っているでしょうし。。)
データの変形
例えば、SASでよく行われるデータの変形(概念的には "proc transpose")について考えてみましょう。
proc transpose(転置)は、残念ながら、単一のデータ系列に限定されているため、厳しい制限があります。
つまり、実用的な用途では、何度もそれを呼び出して、できたデータを結合する必要があるのです。
小さなSASデータセットであれば許容範囲かもしれませんが、大きなデータセットでは何時間も追加処理をすることになりかねません。
この制限のため、多くのSAS開発者は独自のデータ変形技術を開発し、多くはretain、配列、マクロループを持つDATAステップをいくつか組み合わせて使用しています。
この変形コードは100行以上のSASコードになってしまうことも多いですが、SASで変換を実行するには最も効率的な方法です。
DATAステップで実行可能な低レベルの操作の多くは、PySparkでは使用できません。
その代わり、PySparkは、複数のデータ系列を同時にサポートするgroupBy().pivot()変換によるデータ再形成のような一般的なタスクに対して、よりシンプルなインターフェイスを提供します。
proc transpose data=test out=xposed;
by var1 var2;
var x;
id y;
run;
xposed = (test
.groupBy('var1','var2')
.pivot('y')
.agg(last('x'))
.withColumn('_name_',lit('y'))
)
列指向とビジネスロジック指向の比較
PySparkを含むほとんどのデータ処理システムでは、ビジネスロジックを1つの列のコンテキストで定義します。
それに対して、SASはより柔軟性があります。
DATAステップの中でビジネスロジックの大きなブロックを定義し、そのビジネスロジックの枠の中で列の値を定義することができるのです。
この方法は柔軟性がありますが、デバッグに問題がある場合もあります。
列指向に考え方を変えることは、それなりの時間はかかりますが難しくはありません。
SQLに熟練している人なら、かなり簡単にできるはずです。
それよりも問題なのは、既存のビジネスロジックのコードをカラム指向の世界に適応させることです。
DATAステップの中には、何千行ものビジネスロジック指向のコードが含まれているものもあり、それを手作業によって翻訳するのは非常に困難が伴います。
data output_df;
set input_df;
if x = 5 then do;
a = 5;
b = 6;
c = 7;
end;
else if x = 10 then do;
a = 10;
b = 11;
c = 12;
end;
else do;
a = 1;
b = -1;
c = 0;
end;
run;
output_df = (
input_df
.withColumn('a', expr("""case
when (x = 5) then 5
when (x = 10) then 10
else 1 end"""))
.withColumn('b', expr("""case
when (x = 5) then 6
when (x = 10) then 11
else -1 end"""))
.withColumn('c', expr("""case
when (x = 5) then 7
when (x = 10) then 12
else 0 end"""))
)
こういったSASコードの他言語への移植は非常に厄介で、何も考えずに移植するのすら険しいケースもあります。
「元の設計意図に立ち返って俯瞰的に見て移植をしたら、動きは同じだけど当初のコードと全く違うものになった」みたいな事も結構ありました。言語のコンセプトレベルから違う感じなので、ある意味仕方ない部分かと思います。
PySparkには存在しない機能
SASには、PySparkには存在しない強力で重要な機能が数多くあります。
以下にSASにのみ存在する機能を列挙します。
SAS DATAステップの高度な機能
例えば、条件付きで新しい行を生成したい、前の行の計算結果を保持したい、条件付きロジックを組み込んだ合計や小計を作成したい、といったケースについて考えます。
これらはすべて、反復的なSAS DATAステップAPIでは比較的簡単なタスクですが、PySpark DataFrameでは簡単に処理できるようにはなっていません。
データ処理タスクの中には、行ごとに反復する考え方でプロセス全体を完全に細かく制御する必要があるものもあります。
このようなタスクは、行が互いに完全に独立して処理できることを前提としたPySparkのshared-nothing MPPアーキテクチャとは相性が良くありません。
行間依存性を処理するためのAPIは、ウィンドウ関数など限られたものしかありません。
PySparkでこれらの問題の解決策を見つけるには非常に時間がかかることがあります。
data df2;
set df;
by customer_id seq_num;
retain counter;
label = " ";
if first.customer_id then counter = 0;
else counter = counter+1;
output;
if last.customer_id then do;
seq_num = .;
label = "Total";
output;
end;
run;
###カスタムフォーマットとインフォーマット
SASのフォーマットは、そのシンプルさと有用性において注目に値します。
これらは、1つのツールでデータを再フォーマット、再マッピング、表現するメカニズムを提供します。
組み込みのフォーマットは、日付の文字列を出力するような一般的なタスクを処理するのに便利ですが、数値や文字列のコンテキストでも便利です。
PySparkには、これらのユースケースのために利用できる同様のツールがあります。
カスタムフォーマットやインフォーマットの概念は、また別の話です。これらは、キーと値のペアの単純なマッピングだけでなく、範囲によるマッピングもサポートし、デフォルト値もサポートします。
いくつかのユースケースはjoinを使うことで回避できますが、SASが提供する便利で簡潔な構文フォーマットは、PySparkでは利用できないものになってきます。
proc format;
value prodcd
1='Shoes'
2='Boots'
3='Sandals'
;
run;
data sales_orders;
set sales_orders;
product_desc = put(product_code, prodcd.);
run;
ライブラリコンセプトとアクセスエンジン
PySparkを使用するSAS開発者からの最も一般的な不満の1つに、コアエンドユーザーAPI(すなわちPythonセッション)に直接統合されたセマンティックデータレイヤーがないことがあります。
SASデータライブラリのコンセプトは非常に馴染みがあり、そこから離れるのは難しいです。
PySparkには比較的新しいCatalog APIがありますが、これには常にストアにコールバックして、欲しいものにアクセスする必要があります。
論理的なデータストアを定義して、各テーブルのDataFrameオブジェクトを一度に取得する方法はありません。
PySparkに乗り換えるSAS開発者の多くは、データベースの各テーブルにアクセスするためにspark.read.jdbcを呼び出さなければならないことを好みません。
彼らは、データベース内のすべてのテーブルが手元にある、アクセスエンジンライブラリの概念に慣れているのです。
libname lib1 ‘path1’;
libname lib2 ‘path2’;
data lib2.dataset;
set lib1.dataset;
run;
確かにどのパスにどんなテーブルがあるかが分からないというのは不便に感じる事はありますが、ライブラリ定義をする=同一フォルダ上に配置していくということなので、同じようなテーブル管理自体はできそうなものでもあります。
(このあたりは私のPySparkやDataBricksでの経験がまだ浅いのでなんとも言えないです。)
※ここまでがSASとPySparkの共通項、違いに関する内容で、以降は元記事の共同著者であるWiseWithData社が開発したプラグインの宣伝になっていますが、PySparkでSASの便利機能を扱えるというSAS技術者からするとなかなかに魅力的で捨て置けないような内容になっているのでそのまま載せておきます。お問い合わせは元記事からお願いします。
新しいスキル領域を広げるという意味でも個人的には自分が開発をする際にはできればPySparkでの実現方法を都度考える方向で行きたいところですが、そうでないケースも出て来うるかと思いますので。
##違いを解決する - SPROCKETランタイム
SAS言語のコンセプトの多くはもはや過去のものですが、上述の不足している機能については確かに非常に便利で、慣れてしまっていると必須レベルですらあります。
そのため、WiseWithDataはDatabricksとPySparkの特別なプラグインを開発し、それらの馴染み深く強力な機能を現代のプラットフォームに取り込みました、それがSPROCKET Runtimeです。これは、WiseWithDataが1対1のコード変換体験を提供しながら、SASコードをDatabricksとPySparkに驚くべきスピードで自動的に移行することができる方法の重要な部分なのです。
###SPROCKETライブラリとデータベースアクセスエンジン
SPROCKETライブラリは、SAS言語ライブラリのコンセプトと同様に、データソースへのアクセスを簡素化することで、分析の高速化を実現します。この強力なSPROCKET Runtime機能は、データパスやJDBCコネクターに煩わされることなく、1行のコードで全てのデータにアクセスできることを意味します。ライブラリを登録するだけで、関連する全てのDataFrameをすぐに利用することができます。
libname lib ‘path’;
lib.dataset;
register_library(‘lib’, ‘path’)
lib[‘dataset’]
###カスタムフォーマットとインフォーマット
SPROCKETランタイムは、カスタムフォーマットとカスタムインフォーマットのパワーとシンプルさを活用して、データを変換することができます。
SAS環境で行っていたように、カスタムフォーマットを使用してPySpark DataFrame内でデータを変換します。
proc format;
value prodcd
1='Shoes'
2='Boots'
3='Sandals'
;
run;
data sales_orders;
set sales_orders;
product_desc = put(product_code, prodcd.);
run;
value_formats = [
{'fmtname': 'prodcd', 'fmttype': 'N', 'fmtvalues': [
{'start': 1, 'label': 'Shoes'},
{'start': 2, 'label': 'Boots'},
{'start': 3, 'label': 'Sandals'},
]}]
register_formats(spark, 'work', value_formats)
work['sales_orders'] = (
work['sales_orders']
.transform(put_custom_format(
'product_desc', 'product_code', ‘prodcd'))
)
###マクロ変数
マクロ変数はSAS言語における強力なコンセプトです。PySparkにも似たようなコンセプトはありますが、同じものではありません。
そのため、WiseWithDataはSPROCKET Runtimeにこの概念を持ち込み、PySparkでそれらの概念を簡単に使えるようにしました。
%let x=1;
&x
“value_&x._1”
set_smv(‘x’, 1)
get_smv(‘x’)
“value_{x}_1”.format(**get_smvs())
###先進的なSAS DATAステップと行反復処理言語(RIPL API)
SAS DATA step言語の柔軟性は、SPROCKET Runtime内のPySpark APIとして利用可能です。
RIPL APIを使ってグループ別処理、retainされた列、doループ、配列を実装できます。
Pythonでおなじみのif/else条件ブロックでビジネスロジックを表現できます。
Pythonの使いやすさとPySparkのパフォーマンスとスケーラビリティを活用しましょう。
data df2;
set df;
by customer_id seq_num;
retain counter;
label = " ";
if first.customer_id then counter = 0;
else counter = counter+1;
output;
if last.customer_id then do;
seq_num = .;
label = "Total";
output;
end;
run;
def ripl_logic():
rdv['label'] = ' '
if rdv['_first_customer_id'] > 0:
rdv['counter'] = 0
else:
rdv['counter'] = rdv['counter']+1
output()
if rdv['_last_customer_id'] > 0:
rdv['seq_num'] = ripl_missing_num
rdv['label'] = 'Total'
output()
work['df2'] = (
work['df']
.transform(ripl_transform(
by_cols=['customer_id', 'seq_num'],
retain_cols=['counter'])
)
SAS®およびその他すべてのSAS Institute Inc.の製品名またはサービス名は、米国およびその他の国々におけるSAS Institute Inc.の登録商標または商標です。
スキルベースにSASが強くある人でも、簡単とは言わないまでも習得できる余地は多分にあると個人的には感じています。