【注意】FloydHubは2021年8月20日にシャットダウンされます。
TensorFlow Advent Calendar 2017 参加記事です。
ちょうど試す機会が最近あったので FloydHub について書くことにしました。
ところで..みなさんは FloydHub ってご存知ですか?
この記事を書く前に Qiitaを検索してみた のですが、FloydHubの記事が8件でてきたので、知ってる人は知っているというレベルなのかもしれません。
ちなみに、私は Udemy という研修サイトのQ&Aページでこの FloydHub という存在を知りました。
Floyd Hub とは
FloydHub というのは機械学習コードの実行に特化したPaaSです。
機械学習に特化しているため、使い方としては基本的に、 python train.pyといったプログラムをバッチを実行させるか、Jupyter notebook環境によるインタラクティブな開発をおこなうかのどちらかになります。
| 動作モード | 説明 |
|---|---|
job |
デフォルト。CLIツールfloydからpython train.py といった実行させたいコマンドを渡して実行する。動作中の状況はコンソールかCLIツールで確認できる。実行させたプログラムの出力ファイルをダウンロードしたい場合は、プログラム内で/output以下に出力するように記述する。 |
jupyter |
Jupyter Notebooksによるインタラクティブな実行が可能。Terminalも含めすべての機能が動作する(FloydHub実行環境へSSH可能な唯一の方法)。一旦起動したら画面を閉じても動き続けるので、使い終わったら必ず停止させること。 |
serve |
flaskによるREST APIサーバを構築できる。ポートは5000番を使用する。ドキュメントには「このモードは現在プレビュー中で、プロダクションでは使用できません」という注意が書かれている。 |
ユーザは、CLIツールfloydコマンドを使っていずれかの動作モードで実行環境をインスタンス化させます。そして動作中の確認を、floydコマンドやFloydHubコンソール画面を使っておこないます。
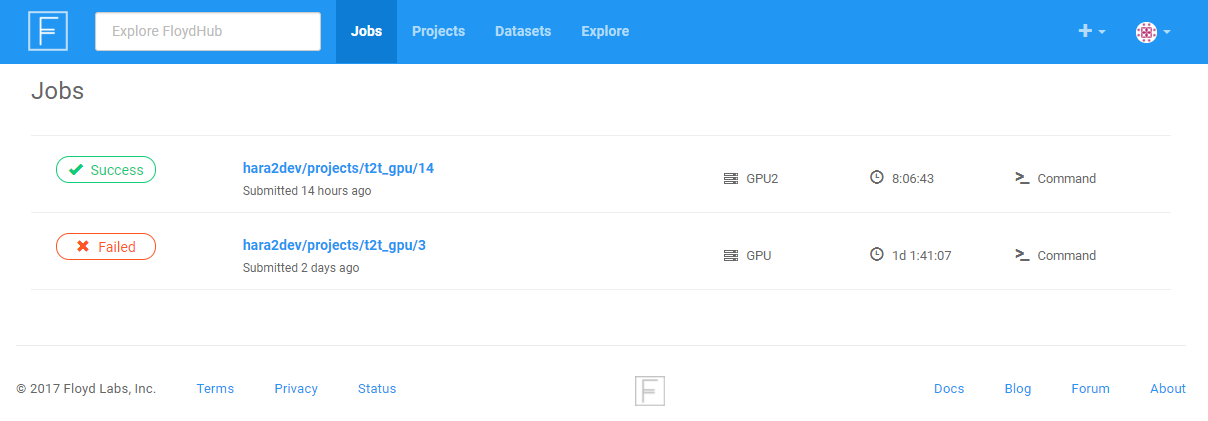
実行環境は以下の中から選択して使用します。
- TensorFlow
- Keras
- Teano
- PyTorch
- Caffe
- Torch
- Chainer1.23/2.0
- MxNet(β)
- Kur
なお、すべての実行環境には以下のパッケージが予めインストールされています。
- h5py
- iPython
- Jupyter
- matplotlib
- numpy
- OpenCV
- Pandas
- Pillow
- scikit-learn
- scipy
- sklearn
最新の実行環境はこちらを確認してください。
アカウントの作成方法やCLIツールのインストールなどの使い方については、本記事では紹介しません。正直それほど難しくありませんので、使ってみたい場合は ほかのQiita記事 を参考にしてください。
この記事では、課金に関する内容を中心にFloydHubを紹介していきます。
料金体系
料金は日本法人がないためすべてドル表示となっており、課金利用する場合は米国でも使用可能なカードが必要になります。換金レートですが、まだ最初の引き落とし明細を受け取っていないため正しくないかもしれませんが、おそらく使用するカード会社の規定準拠になるとおもいます。
料金体系を理解するために必要なFloydHub用語を先に紹介しておきます。
データセット、プロジェクト、ジョブ
FloydHubにはデータセット、プロジェクト、ジョブという論理的な単位があります。
| 論理単位 | 説明 |
|---|---|
| データセット | 学習コーパスを配置する領域。実行環境としてのコンテナが起動する際に、読み取り専用外部ストレージとしてマウントできる。ストレージのみを消費するのでデータをダウンロードする処理時間の課金を減らすことができる。まだ数が少ないが公開データセットもいくつかあるらしい。データセットは必須ではない。定義せずにプロジェクトのみ作成し実行することもできる。 |
| プロジェクト | 機械学習のプログラムを動かすために最初に定義する論理単位。Beginnerプラン(後述)では1つのプロジェクトを複数同時に実行することはできない。プロジェクトを実行するとジョブが生成される。 |
| ジョブ | 1回実行するごとにプロジェクトから作成される。投入したコマンド、標準出力、結果データが内包されている。1つのプロジェクトに対して複数残すことは可能。1つの実行中ジョブから複数のデータセットを同時に参照することも可能。 |
データセットは複数のジョブで共用できるようになっていて、1回アップロードしておけば何度も再利用可能になっています。
プラン
料金体系へ話を戻します。
FloydHub には 3つのプランがあります。
FloydHubアカウントは、いずれかの"プラン"に紐付けされます。

Team というプランはグループ単位での契約ということなので、個人で使用する場合は Beginner か Data Scientist かどちらかを選択することになります。
最初に作成するアカウントは、
Beginnerプランが選択されます。
| Beginner | Data Scientist |
|---|---|
| 同時複数実行できない | 最大8つまで実行可能 |
| パワーアップしていない場合は無料 | パワーアップしていなくても基本料金が毎月かかる |
| 作ったプロジェクトは常に公開される | プライベートプロジェクトが作れる |
BeginnerとData Scientistの最大の違いは、他人の目から隠せるプロジェクトが作成できない点が一番大きいとおもいます。
企業内で作成したデータセットやコードを扱う場合は、Data Scientist を選択せざるをえなくなりますよね![]()
Beginner プランは結局のところ、サンプルコードの実行や柵のないコードを作成しているような機械学習を個人で勉強している人向けということなのだとおもいます。
パワーアップ
FloydHub ではプログラムを動かすための実行環境インスタンス利用時間をソーシャルゲームの課金アイテムのように購入して使います。
インスタンスの種類
FloydHubのインスタンスにはプリエンプティブ(preemptive)型と専用(dedicated)型の2つがあります。
| インスタンスの種類 | 説明 |
|---|---|
| プリエンプティブ(先取り、Preemptive) | プリエンプティブインスタンスは、SLA が98%の実行環境です。この環境で実行されたプロジェクトは、他のより優先度の高いタスクがリソースにアクセスする必要がある場合、FloydHub によってランタイム中の任意の時点でジョブが終了(先取り)される可能性がわずかにあることを意味しています。 |
| 専用(Dedicated) | SLAが 99.95% の実行環境です。クリティカルまたはフォールトトレラントでない場合は、専用のインスタンスをジョブに使用します。 |
プリエンプティブインスタンスの場合、リソースの先取りにあってジョブが止まることが年に2%あるということになります。
FAQ には次のような記述があります。
Note that SLA refers to what we can guarantee. In practice, this happens infrequently. Historically, less than 0.1% of jobs run on FloydHub have encountered interruption. However, you need to be aware that there is the possibility.
SLAとは、保証できるものを指します。実際には、これはあまり起こりません。歴史的に、FloydHub 上で実行されるジョブの 0.1 %未満が中断しました。ただし、可能性があることに注意する必要があります。
おそらく Beginner プランを選択しているうちは、プリエンプティブインスタンスで大丈夫だとおもいます。
利用時間
執筆時点のプリエンプティブインスタンスの料金体系は以下のとおりです。
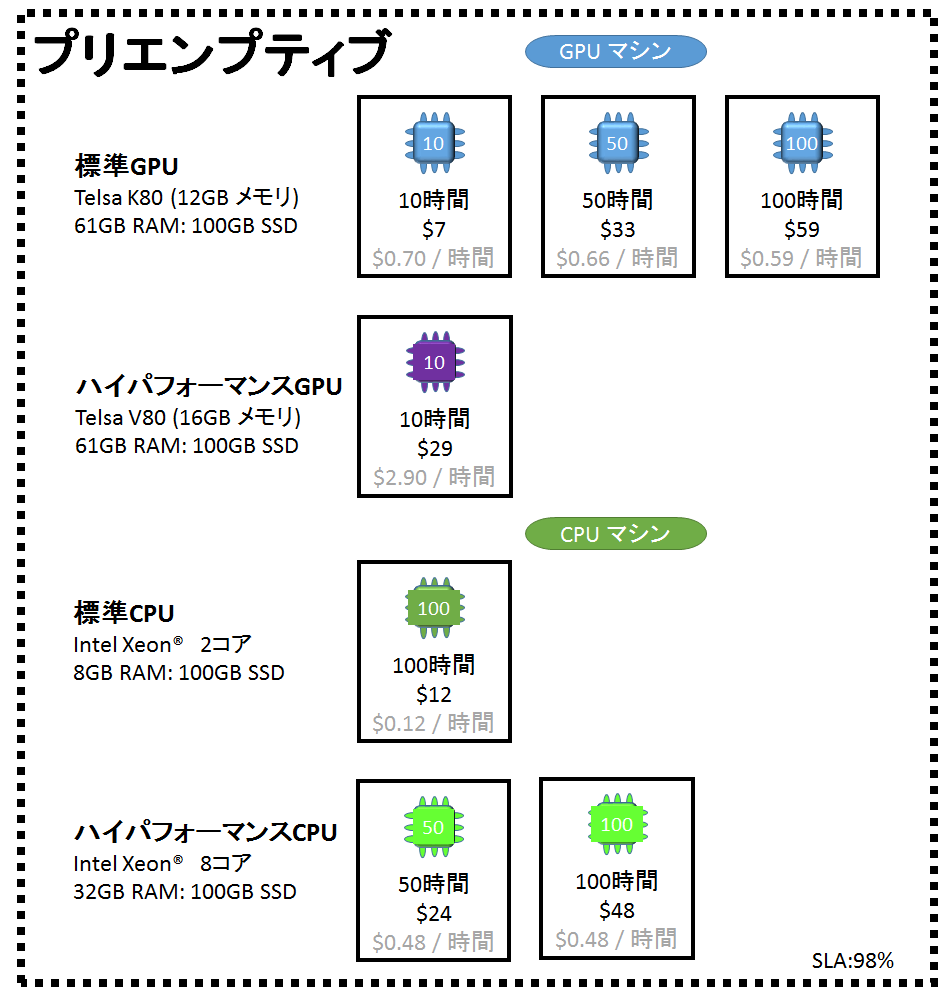
せっかくなので、専用インスタンスの執筆時点の料金体系ものせておきます。
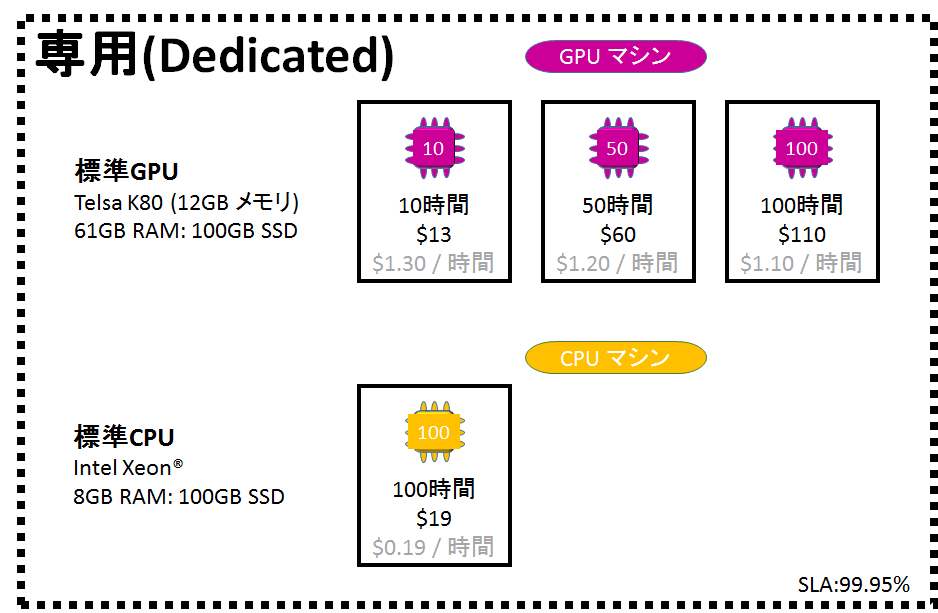
秒単位の課金とうたっていますが、実は10時間、50時間、100時間の単位で買わないといけないのです。
しかも購入した時点で全額カード会社に請求がとびます。
ただし実際に動かしたジョブの実行時間は秒単位で計測されます。
トータル時間計算時に分や時間ではなく秒で切り上げしますよという意味なのです。
ストレージ
無料枠で常時10GMまでストレージが使えます。
10GB以上使用したい方はストレージのパワーアップを使います。
ストレージは、とてもわかり易い月額課金です。
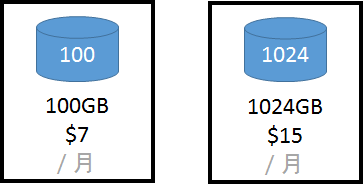
FloydHub のストレージは、プログラムやデータをFloydHubへアップロードした際に消費した容量だけでなく、プログラムが作成するチェックポイントなどの出力ファイルも含みます。
ストレージはデータセットだけでなく、ジョブ側も消費します。
ジョブは、ユーザが消す操作を行わない限りクラウド上に残り続けます。
パラメータの設定ミスとか、ソースの置き忘れなど何度も起動と失敗を繰り返していると、ジョブがどんどん溜まっていきます。
このため多いように見える無料枠の10GBは、意外とあっさり超過してしまいます。
もちろん1ジョブの消費が10GB未満であれば毎回ジョブを削除することでストレージのパワーアップを回避することは可能です。
自動リフレッシュ
処理時間がおもいのほかかかり利用時間をこえてしまううとジョブは タイムアウト となり停止してしまいます。
プログラムの実装が、再実行してもモデルの初期化状態からはじめるよう担っていた場合、消費した利用時間分の課金はまるまる無駄になってしまいます。
タイムアウト時点の出力データはダウンロード可能です。
FloydHub には利用時間が足りなくなった場合、自動的に追加する機能があります。
もし実行対象のプログラムが再実行に対応していない場合は、このオプションを有効にします。
初めてのカキン
初めて課金するのなら、やはりFloydHubが物理マシンとどれくらいの性能差があるか評価につかってみようとおもい、次の実行コードをサンプルに選びました。
実行コード
ニューラルマシン翻訳サンプル T2T のウォークスルーセクションのコードをシェルスクリプト化して動かしました。
TensorFlow 1.4 がリリースされた頃、チュートリアルにて紹介されているSequence-to-Sequence モデルの記述がGitHubへのリンクになっていることに気づいた方まだ少ないと思います。
前のチュートリアルと大きく変わったのが Attention メカニズムについての記述です。T2TではこのAttentionメカニズムを使ったニューラルマシン翻訳モデル The Transformer の実装サンプルコードの名前です。
ちなみに、The Transformer が公開された論文の名前が "Attention is all you need kill" なので、NMT業界はSF映画オタクばっかりなのかもしれません..
ウォークスルーの中で、学習データをダウンロードする部分(以下のコード部)は、予め物理マシンで実行して学習データをローカルマシン上にのこっているのでコメントアウトしました。
# Generate data
t2t-datagen \
--data_dir=$DATA_DIR \
--tmp_dir=$TMP_DIR \
--problem=$PROBLEM
かわりに FloydHub のデータセットhara2dev/datasets/t2t_data/1として個別にアップロードさせておきました。
マウントポイントは/dataとして、コード側も環境変数DATA_DIRのパスを変更しました。
DATA_DIR=/data
FloydHub 上で実行するプログラムが作成したファイルをダウンロードできるようにするには/output以下に置かなくてはなりません。
このため環境変数 $TRAIN_DIRを以下のように変更しました。
TRAIN_DIR=/output/t2t_train/$PROBLEM/$MODEL-$HPARAMS
訓練のためのバッチ実行部分はオプション--hparams='batch_size=1024を付けて動かします。
# Train
# * If you run out of memory, add --hparams='batch_size=1024'.
t2t-trainer \
--data_dir=$DATA_DIR \
--problems=$PROBLEM \
--model=$MODEL \
--hparams_set=$HPARAMS \
--hparams='batch_size=1024' \
--output_dir=$TRAIN_DIR
ちなみに、上記コマンドを動かすと 250000 global_steps バッチが動きます。
あと一部コードに誤りがあったため、最終行のみ以下のように修正しました。
cat $DECODE_FILE.$MODEL.$HPARAMS.$PROBLEM.beam$BEAM_SIZE.alpha$ALPHA.decodes
ここを直さないとトレーニングが成功しても、コンソール画面を見てドキッとしてしまうので..
課金設定
今回は、以下の課金設定で実行しました。
- Beginnerプラン
- パワーアップ
- ストレージ 100GB
- GPU K80 10時間 / 自動更新あり
- GPU V100 10時間 / 自動更新あり
物理マシンで少し動かした段階でストレージは10GBを超えたので、100GB を選択しました。
買ってみてわかったのですが、ストレージは自動更新をオフにできない仕様のようです。
正直、FloydHub でどれだけ時間がかかるかわからなかったので、小刻みに利用時間の課金を刻む作戦で行くことにしました。
ジョブ
以下のコマンドで実行しました。
# 標準GPU (K80)
floyd run --gpu --env tensorflow-1.4 --data hara2dev/datasets/t2t_data/1:/data "bash t2t.sh"
# ハイパフォーマンスGPU
floyd run --gpu2 --env tensorflow-1.4 --data hara2dev/datasets/t2t_data/1:/data "bash t2t.sh"
T2T の README.md では、TensorFlow のバージョンは 1.3.0 だと書いているのですが、ハイパフォーマンスGPUが本当にごく最近リリースされているらしく TensorFlow 1.4.0 しか選択できません。このため、すべて TensorFlow1.4.0/Python3.x で統一しました。
ハイパフォーマンスGPUを使用する場合はfloydコマンドも最新でないとジョブを発行できません。動作しない方は pip uninstall floyd-cli && pip install floyd-cli を実行して再インストールしてください。
結果
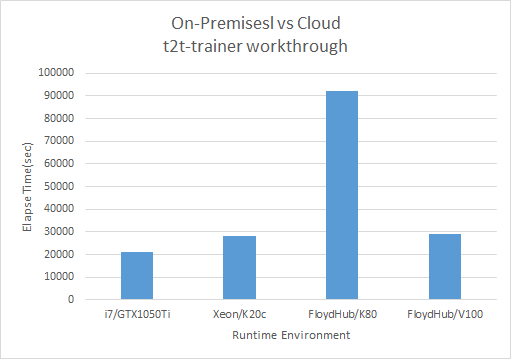
比較のため物理マシンも用意してT2Tのトレーニングプロセスt2t-trainer部分の処理時間を比較してみました。
| 実行環境 |
t2t-trainer 処理時間 |
|---|---|
| i7 8コア,32GBRAM (GPUなし) | N/A |
| i7 8コア,32GBRAM + GTX 1050Ti(4GB) | 5時間54分31秒 |
| Xeon 8コア,16GBRAM + Telsa K20c(5GB) | 7時間52分10秒 |
| FloydHub CPU | Timeout |
| FloydHub GPU K80(12GB) | 25時間33分03秒 |
| FloydHub GPU V100(16GB) | 8時間1分42秒 |
FloydHub を無料枠で CPUのみの環境で実行しましたが、すべての無料枠利用時間を使い切って Timeout で停止してしまいました。CPU枠も課金してみようと思ったのですが..物理マシンのCPUのみ実行性能があまりにもひどいので、青天井にお金が飛んでいきそうでビビってやめました...
その課金を諦めさせた物理マシンCPUのみの環境での実行ですが、2017年11月24日17時4分19秒から開始して、執筆時点(2017/12/1)で250000ステップ中60430ステップしか消化しきれていませんでした。ざっくり計算しても25日以上かかることになりそうなので、諦めました。
そして物理マシンでこの状態なら、課金CPU環境じゃ..って、誰でも怖くなりますよね![]()
処理時間が明確な実行環境のみを秒単位にしてグラフ化してみました。
まとめ
- FloydHub はカード情報さえ登録すれば簡単に課金できる
- 標準GPUは正直使えない、1万7千円のGPU(GTX1050Ti)よりマシ
- ハイパフォーマンスGPUは、2012年末リリースのアクセラレータ(K20)相当の速度
- 物理マシンによる処理時間をFloydHubの見積もりに使うのはキケン
専用インスタンスが、BluemixやAWSのベアメタルマシンなのかはわかりませんが、ひょっとしたら物理マシンに近いパフォーマンスが出せるのもしれません。ただ、個人で試すにはちょっと料金が..
FloydHubがV100のハイパフォーマンスGPUをリリースしたのは、速度面で不満を持つ顧客をなんとかつなぎとめようとしているからなのかもしれませんね。
利用シーンは限定的だとは思いますが、FloydHub は GPU環境が手元にないけど機械学習を勉強したいという人には向いていると思います。興味のある方は、使ってみてはいかがでしょうか。