こんにちは、ふくちです。
2025/11/30にBedrockナレッジベースのマルチモーダル検索が一般提供開始されたので、試してみました。
最初に結論
どうやら2種類あって、Bedrock Data Automationを使うものとNova Multimodal Embeddingsという新しい埋め込みモデルを使うものがあるようです。
今回はNova Multimodal Embeddingsを試してみました。
AWS構成図を画像検索させたところ、結構精度が良さそうでした。



対応リージョン
現状(2025/12/1)は日本のリージョンでは使えません。
というのも、Bedrock Data Automation(BDA) or Nova Multimodal Embeddingsが使えるリージョンでしか無理だそうです。
詳しくは以下リンク参照ですが、とりあえずバージニア北部リージョンであればどちらでも使えるみたいなのでここでやってみます。
マルチモーダルRAGを作ってみる
早速やっていきましょう。
ナレッジベースを作成する
Bedrockコンソールの「ナレッジベース」から、普通に「ベクトルストアを作成」で進めていきます。
すると、すぐに最初に違いが登場します。注意書きが変わっています。
↓東京・大阪
↓バージニア北部

Select the data source type that you want to configure in the next step. You may add additional data sources once your Knowledge Base is created.
次のステップで設定するデータソースの種類を選択します。ナレッジベースを作成したら、さらにデータソースを追加できます。
つまり、以下の違いがあるようです。
- これまで:ナレッジベース作成段階で複数のデータソースを選択できた(上限は確か5個)
- 最新版 :一旦データソースを1つだけ指定してナレッジベースを作成し、追加したい場合はその後で実施
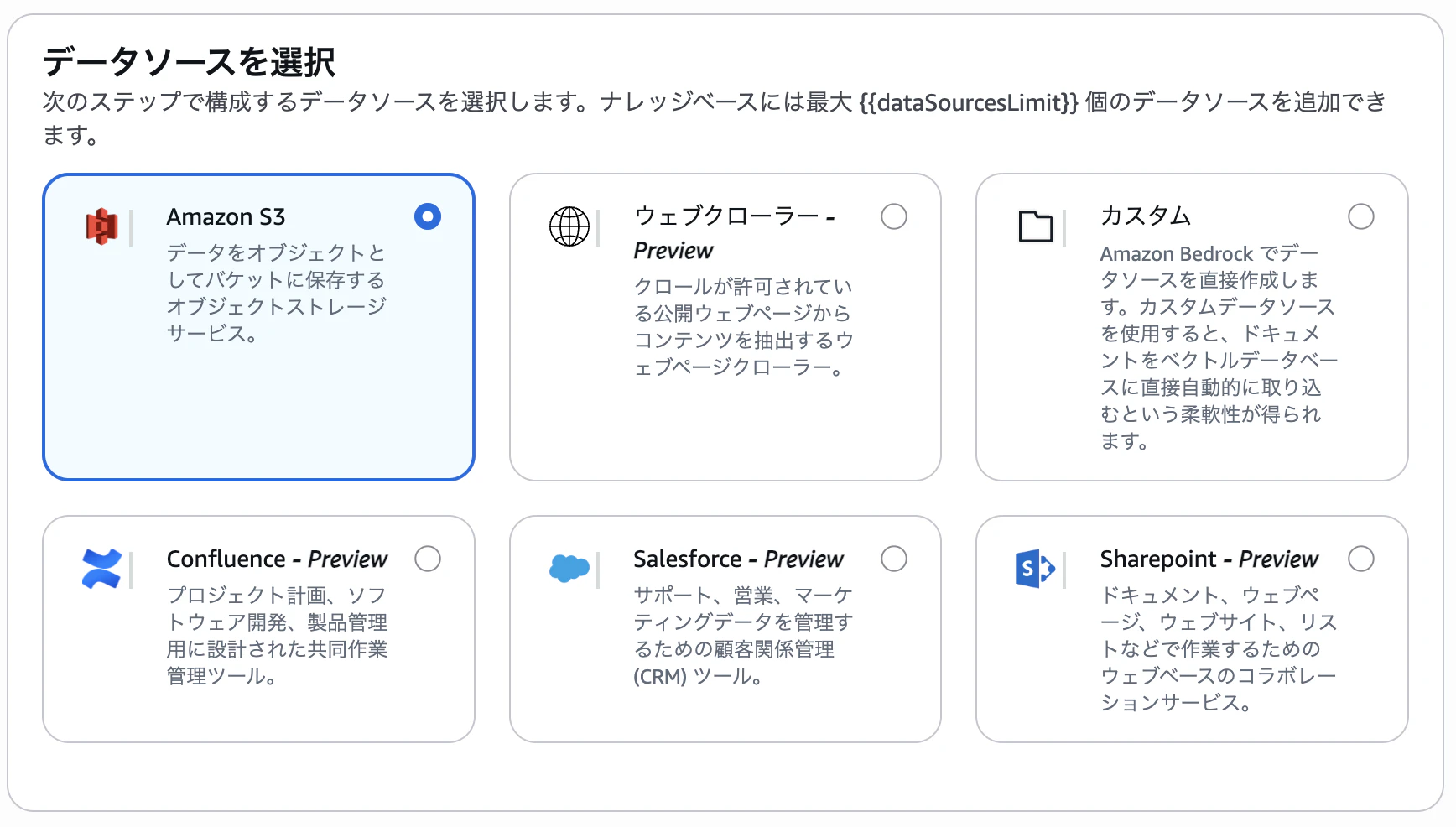
マルチモーダル検索は現在S3データソースでのみ利用可能だそうです。
ここではS3を指定して作っていきます。
その後作成を進めると、Parser戦略(解析戦略)の表示が変わっています。
↓東京・大阪は簡素なのと、BDAが来ていないので2個だけ

↓バージニア北部は詳細な説明が追加された

マルチモーダルRAGにしたい場合はBDA(真ん中)かパーサーとしての基盤モデル(右)を選択します。
それぞれの違いはドキュメントに記載がありました。
Nova Multimodal Embeddings:
画像と音声の類似性マッチングのためにネイティブフォーマットを維持します。画像、音声、動画はテキストに変換されることなく直接埋め込まれます。
Bedrock Data Automation (BDA):
マルチメディアをテキスト表現に変換します。音声は自動音声認識 (ASR) を使用して書き起こし、ビデオはシーンの要約と書き起こしを抽出し、画像はOCRとビジュアルコンテンツの抽出を行います。
そのまま埋め込みをするのがNova、一度文字に書き起こすのがBDAという違いみたいですね。
それぞれの詳細な処理の解説やユースケース・ベストプラクティスもドキュメントに記載があるので、使う際は要チェックです。
| コンテンツタイプ | Nova Multimodal Embeddings | BDA |
|---|---|---|
| 製品カタログと画像 | 推奨 - 視覚的な類似性マッチングと画像ベースのクエリを可能にします | 限定的 - OCR を通じてのみテキストを抽出します |
| 会議の録音と通話 | 発話内容を意味のある形で処理できない | 推奨 - 完全な音声文字変換と検索可能なテキストを提供 |
| トレーニングおよび教育ビデオ | 部分的 - 視覚コンテンツは処理できるが、音声は処理できない | 推奨 - 音声トランスクリプトと視覚的な説明の両方をキャプチャします |
| カスタマーサポートの録音 | 推奨されません - 音声コンテンツを効果的に処理できません | 推奨 - 検索可能な完全な会話記録を作成します |
| 技術図表 | 推奨 - 視覚的な類似性とパターンマッチングに最適 | 限定的 - テキストラベルは抽出できるが、視覚的な関係は抽出できない |
ここでは私たちの業務に大きく関係のありそうな技術図表の方を試すため、Nova Multimodal Embeddingsを使ってみたいと思います。
パーサー戦略は「パーサーとしての基盤モデル」を選択し、以下の設定で進めてみます。

(マルチモーダルの時のチャンキング戦略ってどうすればいいんでしょうね…これはテキストだけだから関係ない?)
後続でようやく埋め込みモデルが選択できます。ここでNova Multimodal Embeddingsを選択。
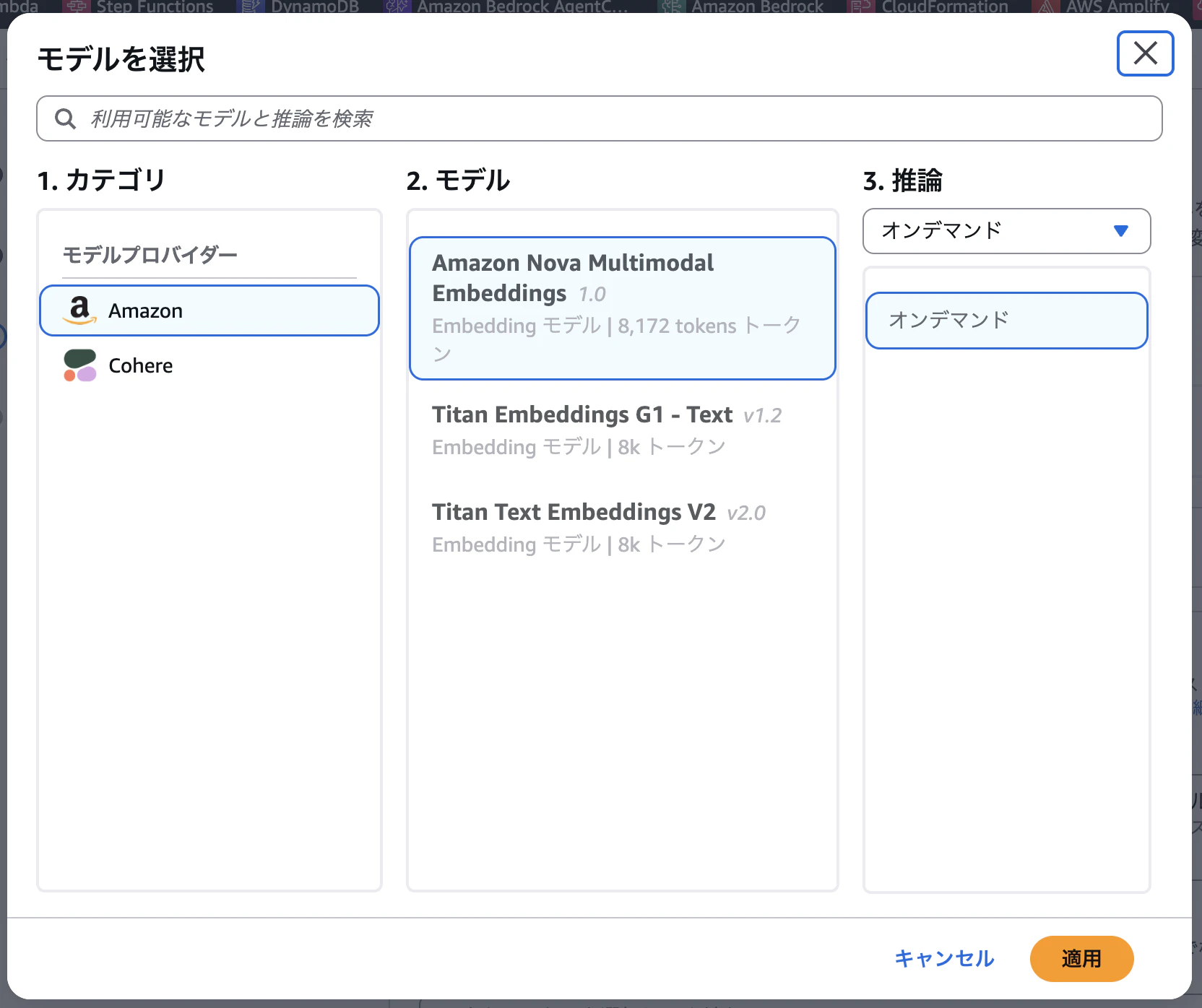
追加設定で、AudioとVideoのチャンキング戦略を設定できます。それぞれ5秒がデフォルトですが、1秒~30秒の間で設定可能なようです。

ちなみにパーサー戦略でBDAを選択し、埋め込みモデルでNova Multimodal Embeddingsを選択することもできます。
ただしこの時、Nova Multimodal Embeddings埋め込みモデルはテキスト埋め込みモデルのように動作するそうです。
つまりどちらも同時に設定すると、マルチモーダル対応できなくなるということだと思います。
先にBDAで文字起こししてから埋め込みするので、理屈でわかる気がしますが、マルチモーダルRAGにする際はうっかりミスに要注意です。
利用可能なベクトルストアはOpenSearch Serverless/S3 Vectors/Aurora Serverless v2の3つだけでした。NeptuneのGraphRAGには対応していないようです。
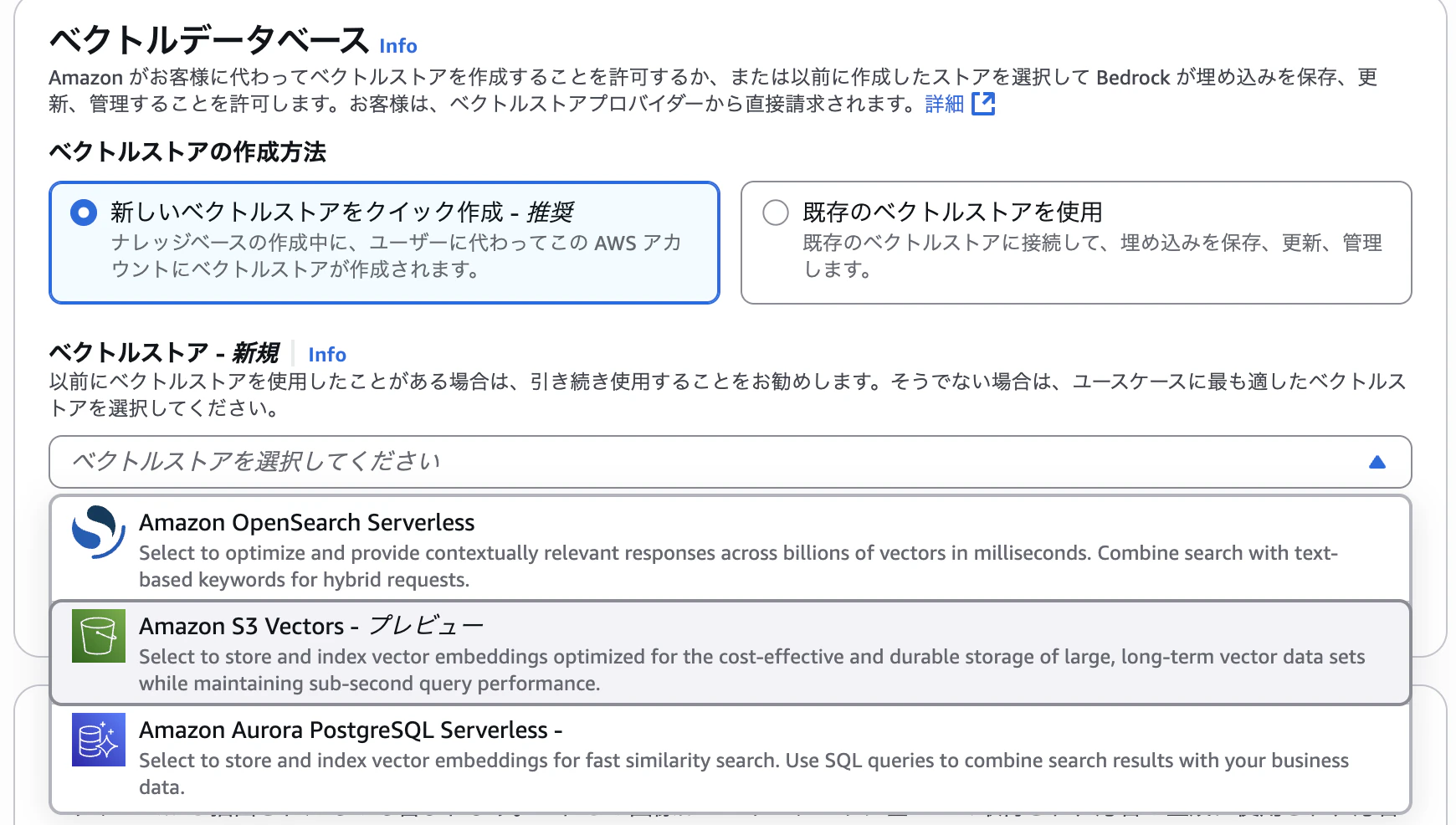
そして「マルチモーダルストレージの保存先」というものが追加されています。
ここにはマルチメディアファイルのコピーが保存され、ソースファイルが変更または削除された場合でも、ファイルの可用性が確保されるようです。
また、データソースのS3バケットとは別のバケットにするのがベストプラクティスなようです。

ここまで設定したら、いよいよ作成です。出来上がったものがこちらになります。
S3にAWS構成図を格納する
続いてデータソースS3にAWSの構成図を入れてみます。できるだけいろんな構成にしてみました。

S3に格納したら、ナレッジベースのデータソースを「同期」を押して少し待ちます。
画像12枚くらいだと、1分程度で終わりました。
ナレッジベースをテストする
いよいよテストです。が、ここで注意点。
Nova Multimodal Embeddingsを用いてマルチモーダルRAGにした場合、Retrieve処理のみ可能なようです。つまり、検索だけ可能ということ。
このNova Multimodal Embeddingsの良いところは、画像や動画をそのまま視覚的に判別することができるところです。なので、画像を用いた類似検索をできることが最大のメリット。
しかし、それはあくまでRetrieve処理のみ。通常のRAGすなわちRetrieveAndGenerateの処理はできないそうです。
ちなみにBDAはRetrieveAndGenerateにも対応しています。
ということでテストする際も、RetrieveとRetrieveAndGenerateで画面が若干異なります。
Retrieve(コンソールだと「取得のみ: データソース」)だと、ファイルアップロードが可能→画像をクエリにできる

RetrieveAndGenerate(コンソールだと「取得と応答生成: データソースとモデル」)だとファイルアップロードできない→画像をクエリにできない

今回はせっかくなので画像クエリをやってみます。
格納した構成図の中にはAgentCore系のもあったので、以下クラメソブログ様から構成図を拝借して試させていただきます🙏
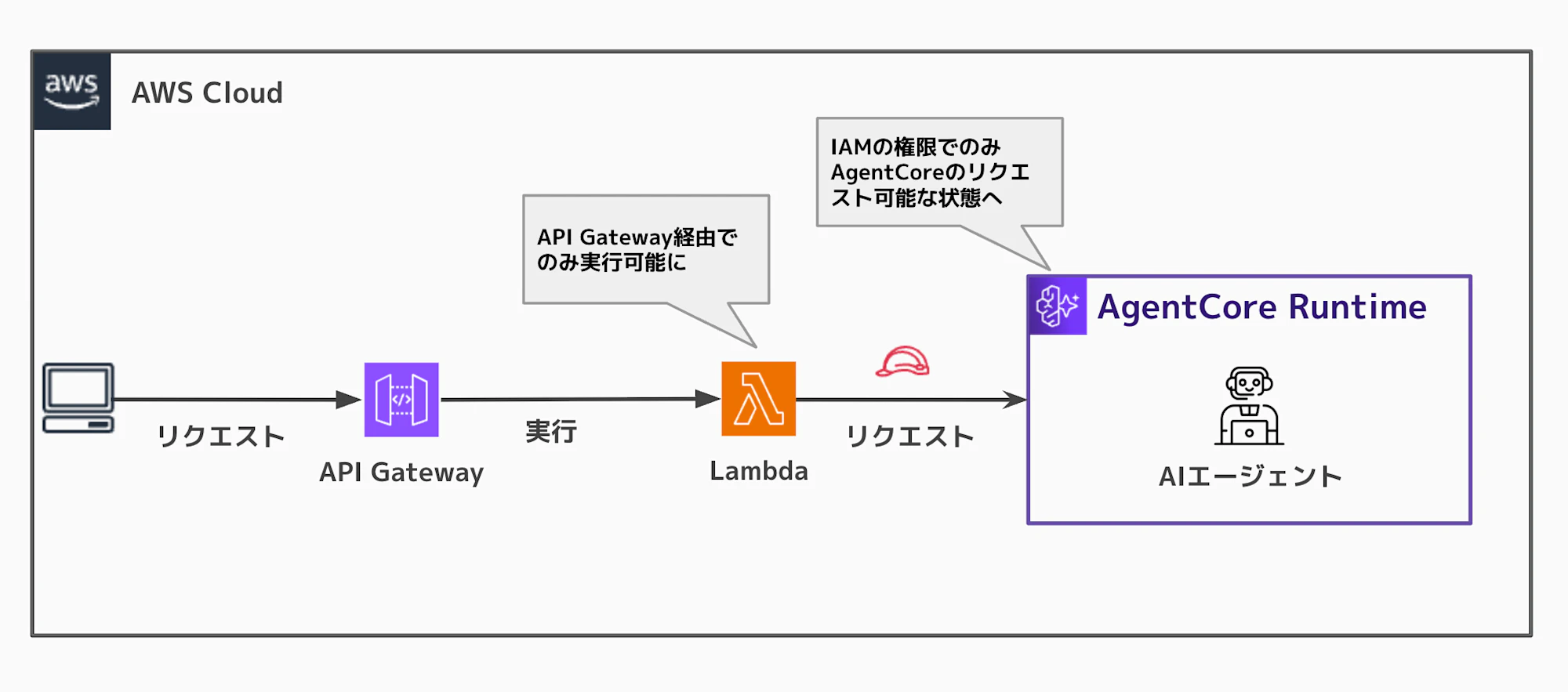
結果は以下のとおりです。コンソール上だとちょっと見づらいw

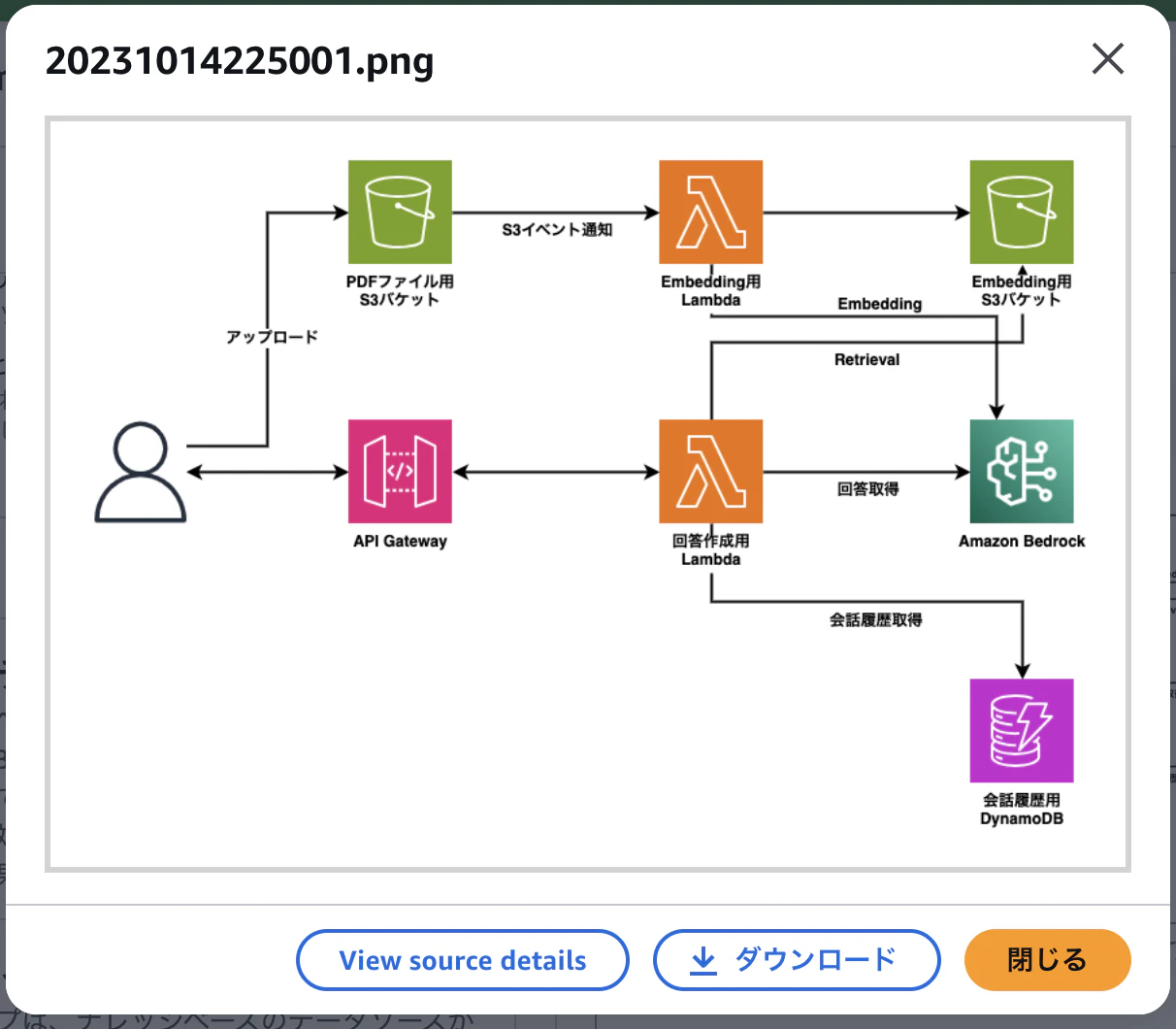

ということで、画像検索できてそうでした。クエリしたのが最新のAPI Gateway+Lambda+AgentCore構成、1件目の答えがCloudFront+Lambda Function URL+AgentCore構成ということで、なかなか良い感じの回答になったのではないでしょうか。
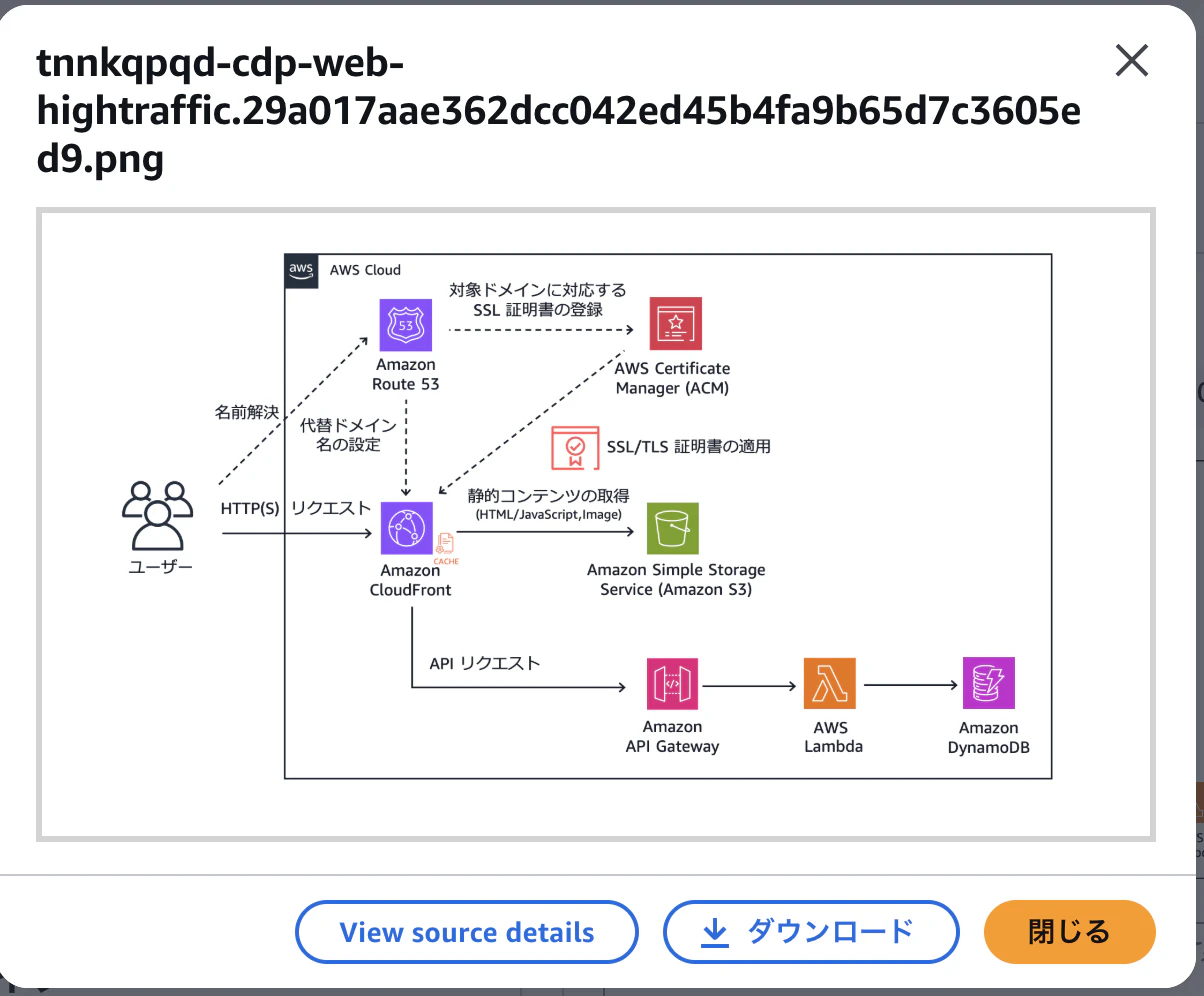
もう1件、全く関係ない画像を上げてみるとどうなるのでしょうか。


すべての結果は省略しますが、返ってはきてしまうみたいですね(そして確かにちょっと色味が似てて面白い)。
さらに偶然の産物なのですが、結構精度が良いことが判明しました。
今の回答もBedrock使ってるんですが、これは完全サーバーレスな構成ではないですよね。ELB+ECS+Bedrockなハイブリッド構成。
でも最初のクエリではこの画像が返ってきていなかったんです。アイコン的に見るとAPI Gateway+LambdaはELB+ECSと色が一緒で似ているのに。AgentCoreとBedrockという違いこそあれど、他の回答ではBedrockのものが引っかかっていたりするのに。
つまり、おそらくはある程度アーキテクチャ図で使われているアイコンも判別した上で検索処理を行えるということ。もちろん画像の解像度やサイズにもよるとは思うのですが、これを見る限りだと結構精度が良さそうでした。
個人的には、これ結構社内の事例検索やアーキテクチャ図検索とかにも使えそうな精度だな… と思えるようなものになっていました!
例えば、こんな感じのものが作れそうでしょうか。
- ユーザーは画像ベースでアーキテクチャ図の検索をする
- システム側はRetrieveだけして、似ている構成図の画像をユーザーに返す
- 裏側でクエリ元の画像とクエリ結果の画像をLLMにインプットして、現状のアーキテクチャとどこがどう違うのか、注意すべき点は何か、その画像と紐づく過去案件ではどんな要件があってこの構成にしたのか、などを踏まえて色んなフィードバックを返す
という疑似RAGみたいなことまでできそうだなと思いました!
まとめ
新しく登場したマルチモーダルRAG、結構良さそうです!
次はエージェントと組み合わせたりして使ってみたいのと、BDAも試してみようと思います!
参考