はじめに
以下登壇資料の詳細解説です。
もともとやりたかったこと
AgentCoreをイベント駆動/スケジュール駆動で動かそうと考えていました。
ただ、EventBridgeからAgentCoreは直接コールできませんでした。
そうなると、Lambdaを挟まないといけないのかー嫌だなー…というのが正直なところでした。
(Lambdaの実行時間制限に引っ張られたり、AgentCoreからのレスポンスを待たなきゃいけなかったり…というのが個人的にネックだと感じています。)
AgentCoreだけを独自実行できたら、もしくはそれに準じたことができたら嬉しいなぁ…
と、AgentCoreのドキュメントを漁っていると…
AgentCoreの非同期実行処理
こんなドキュメントがありました。
こいつが個人的には超絶救世主!
これがあれば、EventBridge→(一瞬だけLambda→)AgentCoreが実現可能なのです!
非同期実行で何が変わる?
この非同期実行処理は、いわゆるバックグラウンド実行が可能になるもの、とご理解いただければよいのかなと思います。
公式ドキュメントいわく、
非同期タスクにより、エージェントはクライアントへの応答後も処理を継続し、応答をブロックすることなく長時間実行オペレーションを処理できます。非同期処理により、エージェントは以下のことが可能になります。
- 数分または数時間かかる可能性のあるタスクを開始する
- ユーザーに「作業を開始しました」とすぐに返信する
- バックグラウンドで処理を続行
- ユーザーが後で結果を確認できるようにする
ということで、長時間タスクを非同期的に=バックグラウンドで進められるようになる、というのがこの説明だと私は認識しています。
つまり、呼び出し元を待たせることなくバックグラウンドでエージェントを動かすことができるようになったということです。
少し具体例を見ていきましょう。
普通の同期エージェントの場合、当然ですがユーザーはエージェントの動作が終わるまで待つ必要があります。そして、その待たせる時間を長く感じさせないためにストリーミングレスポンスなどの工夫を入れ込んでいると思います。
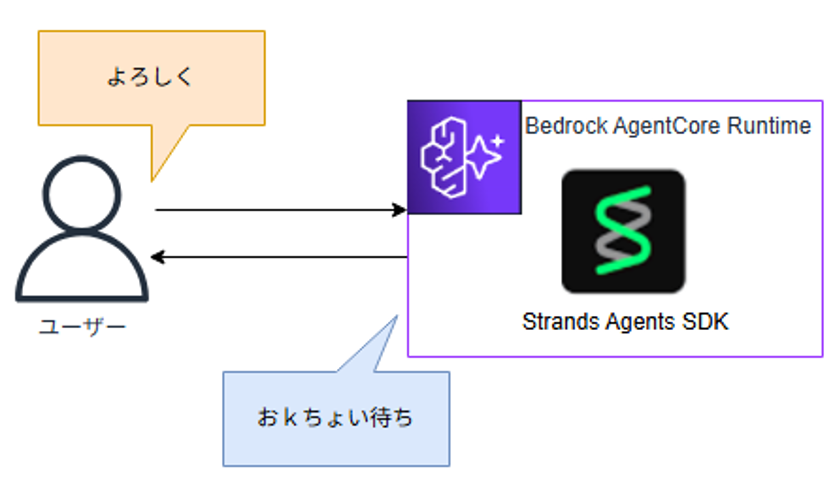
それに対して非同期エージェントの場合、エージェントは処理を受け付けたらユーザーに即レスポンスを返して、バックグラウンドで処理を実行します。
その後、処理が完了したらユーザーに通知したりして確認を行うという流れになります。
(※通知を行うなどの処理は別途実装する必要がありますが)
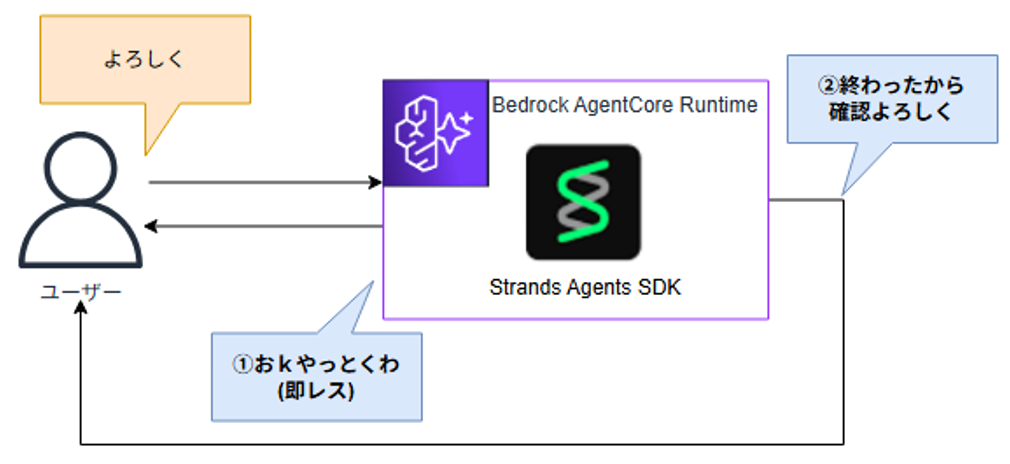
非同期実行のメリットは?
AWS上でAmbientなAgentが作れるようになるんじゃないかな、と思っています。
スケジュール駆動・イベント駆動で動作し、バックグラウンドでエージェントがタスクを完遂する、というようなものが作れたりしないかなと。
ただし冒頭にも述べた通り、EventBridgeからAgentCore Runtimeを直接動かすことは難しいようです。直接指定しての実行ができませんでした(2025年10月18日現在)。
また、EventBridge→Lambda→AgentCoreにするのもなんだかなーという感じです。
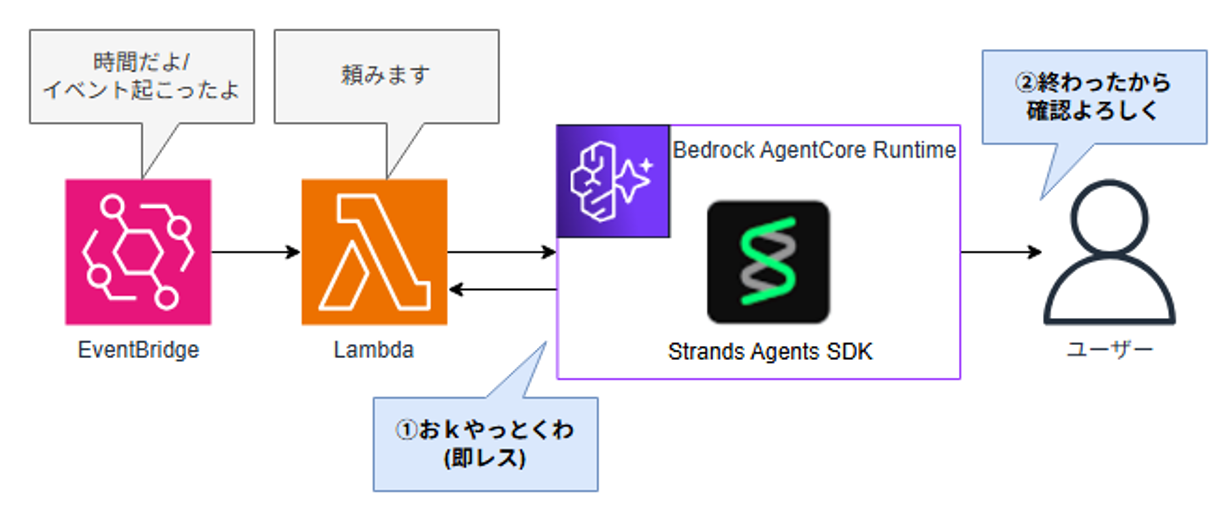
そこで、この非同期実行です。
EventBridgeからLambdaをトリガーし、LambdaはAgentCore Runtimeへinvokeする。
Runtimeは処理を受け付けたらLambdaに即レスを返してLambda側の処理完了。
その後はRuntimeだけが独立して動き続ける…というような仕組みが可能になりました。
また、ここのエージェントで次のタスクを実行するEventBridgeを作成するツールなども与えておけば、エージェントが自分で次のタスク実行開始処理なども設定してくれるはずです。
そうすると次の実行開始時間も自分で設定してくれて、単発の処理で終わらないような仕組みなんかも作れたりしそうです。
何はともあれ、非同期実行処理ができるおかげで、AmbientなAgentが作れそうな予感がしてきますね!
Runtime側の処理は中身が見えづらく、若干ブラックボックスになる分、エラーハンドリングはめちゃくちゃ考えないといけないです。
失敗した際の継続/エラー通知処理にとどまらず、失敗した箇所・原因などその時点でのコンテキストをどうしておくかなども考えて設定してあげる必要があります。
また、Observabilityの仕組み(CloudWatch, Langfuse, LangSmith…)は必須なので、必ず何か1つだけでも設定しておきましょう。
Runtimeのセッション管理
非同期実行、すなわち裏側で自動的に処理が動くわけですが、そのステータス管理ってどうやるんでしょうか?
例えば「リクエスト受付可能状態」なのか、「裏側で処理実行中」なのか、など。
そこは/pingヘルスステータスを使用して処理状態を伝えるようです。通常の"HealthyBusy"はエージェントがバックグラウンドタスクの処理でビジー状態であることを示し、"Healthy"はアイドル状態(リクエスト受付待機中)であることを示します。
ただし、アイドル状態が15分間続くと、セッションは自動的に終了するようです。
逆に言うと、"HealthyBusy"の状態だと、8時間連続のセッションが可能なのではないかなと妄想しています。そんなに長い時間稼働したらトークン消費量えらいことになってそうですが…
また、この/pingヘルスステータスにピンと来た方がいたかもしれません。
これはAgentCore Starter Toolkitを使わない時のカスタム実装で設定する/pingエンドポイントです。
この/pingのカスタムハンドラーを作成することもできます。@app.pingデコレータを使って実装するそうです。
@app.ping
def custom_status():
if system_busy():
return PingStatus.HEALTHY_BUSY
return PingStatus.HEALTHY
非同期処理の実装方法
この非同期実行はBedrock AgentCore SDKを用いて実装可能です
具体的な実装方法は2つあります。
1.APIベースのタスク管理
非同期化したい処理の前後に、add_async_taskとcomplete_async_taskを入れます。
非同期化したい処理をサンドイッチするイメージです。
# 非同期タスク実行マーク
task_id = app.add_async_task("data_processing")
# 非同期化したい処理
# 非同期タスク完了マーク
app.complete_async_task(task_id)
2.非同期タスクデコレータ
非同期関数に@app.async_taskデコレータを付与するだけで、自動でトラッキングしてくれるようになります。
# 自動で非同期タスクをトラッキングしてくれるようになる
@app.async_task
async def background_work():
await asyncio.sleep(10) # ステータスが"HealthyBusy"になる
return "done"
@app.entrypoint
async def handler(event):
asyncio.create_task(background_work())
return {"status": "started"}
簡易実装サンプル(非同期ツール実行)
AWS公式ドキュメントに記載されているサンプルとしては、以下のような形です。
import threading
import time
from strands import Agent, tool
from bedrock_agentcore.runtime import BedrockAgentCoreApp
app = BedrockAgentCoreApp()
@tool
def start_background_task(duration: int = 5) -> str:
"""指定された時間だけ実行される簡単なバックグラウンドタスクを開始します。"""
# 非同期タスクをトラッキング開始
task_id = app.add_async_task("background_processing", {"duration": duration})
# タスクをバックグラウンドスレッドで実行する関数
def background_work():
time.sleep(duration) # 非同期タスクを実行する、ここではサンプルとしてsleep
app.complete_async_task(task_id) # 非同期タスクの完了サイン
threading.Thread(target=background_work, daemon=True).start()
return f"バックグラウンドタスク(ID: {task_id})を{duration}秒間開始しました。エージェントの状態はBUSYになりました。"
# エージェントに上記のバックグラウンドタスクを与えて初期化
agent = Agent(tools=[start_background_task])
@app.entrypoint
def main(payload):
"""メインのエントリーポイント、ユーザーメッセージを処理します。"""
user_message = payload.get("prompt", "Try: start_background_task(3)")
return {"message": agent(user_message).message}
if __name__ == "__main__":
app.run()
ただ、これってあくまでエージェントがツールを非同期的に実行しているに過ぎないと認識しています。もちろん、ツールの実行にひたすら時間がかかる場合はこれで良いんだと思います。
例えばバッチ処理とか、Nova Reelで動画を生成するとか…
簡易実装サンプル(非同期エージェント実行)
とはいえ、個人的には非同期的にエージェントを動かしたい。
ということで実際にやってみると、できました(多分ドキュメントには記載されていません)。
import os, asyncio, logging
from typing import Dict, Any
from strands import Agent
from strands.models.bedrock import BedrockModel
from bedrock_agentcore import BedrockAgentCoreApp
from tools import http_get, sleep_seconds, current_time
log = logging.getLogger("AsyncAgent")
logging.basicConfig(level=logging.INFO)
app = BedrockAgentCoreApp()
# --- モデルとエージェント定義 ---
MODEL_ID = os.environ.get("BEDROCK_MODEL_ID", "jp.anthropic.claude-sonnet-4-5-20250929-v1:0")
model = BedrockModel(model_id=MODEL_ID)
SYSTEM_PROMPT = (
"You are a pragmatic research agent.\n"
"- Think step by step.\n"
"- Use tools when helpful (http_get, current_time, sleep_seconds).\n"
"- Keep outputs concise unless asked.\n"
)
# Strands Agent(ツールセット登録)
agent = Agent(
model=model,
tools=[http_get, sleep_seconds, current_time],
system_prompt=SYSTEM_PROMPT,
)
# --- バックグラウンドで動作する本処理 ---
async def _background_run(task_id: int, payload: Dict[str, Any], context):
try:
job_id = payload.get("job_id", "mvp")
seconds = int(payload.get("seconds", 0) or 0)
if seconds > 0:
await sleep_seconds(seconds)
user_input = payload.get("input") or "Say hello and show current_time."
log.info("[AsyncAgent] job=%s | start background | input=%s", job_id, user_input)
# Strands Agent 呼び出し(同期APIなのでスレッドにオフロード)
result = await asyncio.to_thread(agent, user_input)
log.info("[AsyncAgent] job=%s | completed", job_id)
except KeyError as e:
log.error("[AsyncAgent] job=%s | OpenTelemetry instrumentation error: %s", job_id, e)
except Exception as e:
log.exception("[AsyncAgent] job failed: %s", e)
finally:
# 必ず complete してセッションを解放
app.complete_async_task(task_id) # 非同期タスク完了マーク
# --- AgentCore用エントリポイント ---
@app.entrypoint
async def main(payload: Dict[str, Any], context=None):
"""
初回: {"action":"start","job_id":"...", "input":"..."} を渡すと、
すぐ {"status":"started","task_id": "..."} を返し、裏でエージェント処理を継続。
"""
if payload.get("action") == "start":
task_id = app.add_async_task("agent_job", {"job_id": payload.get("job_id")}) # タスク開始
asyncio.create_task(_background_run(task_id, payload, context))
return {"status": "started", "task_id": task_id}
return {"status": "noop"}
if __name__ == "__main__":
app.run()
また、ツールとして以下を作成し、設定してみました。
from strands import tool
import asyncio
from datetime import datetime
from zoneinfo import ZoneInfo
import httpx
from typing import Optional
@tool
async def http_get(url: str, timeout_sec: int = 10, max_bytes: int = 50_000) -> str:
"""URL検索を行うツール。
Args:
url: Target URL (http/https)
timeout_sec: Request timeout seconds
max_bytes: Max bytes to read to avoid huge payloads
Returns:
Response text (truncated to max_bytes)
"""
async with httpx.AsyncClient(timeout=timeout_sec, follow_redirects=True, headers={
"User-Agent": "AgentCore-Strands-MVP/1.0"
}) as client:
r = await client.get(url)
r.raise_for_status()
content = r.text
if len(content) > max_bytes:
content = content[:max_bytes] + "\n...[truncated]..."
return content
@tool
async def sleep_seconds(seconds: int = 3) -> str:
"""指定された秒数sleepし、その後報告するツール"""
await asyncio.sleep(max(0, int(seconds)))
return f"Slept {seconds} seconds"
@tool
def current_time(tz: str = "Asia/Tokyo") -> str:
"""日本の現在時刻を返すツール"""
return datetime.now(ZoneInfo(tz)).isoformat()
コードの解説などは後続で行います。
動作確認
これを実際に動かしてみます。イメージは以下です。
まずは先程のエージェントとツールをまとめてAgentCore Runtime上へデプロイしておいてください。
続いてLambda関数を用意します。
以下の形で、AgentCore Runtimeを呼び出したらすぐに終了するLambda関数を作成します。
import os, json, uuid, boto3, logging
from botocore.config import Config
logger = logging.getLogger()
logger.setLevel(logging.INFO)
cfg = Config(connect_timeout=2, read_timeout=5, retries={"max_attempts": 1})
client = boto3.client("bedrock-agentcore", config=cfg)
RUNTIME_ARN = os.environ["AGENT_RUNTIME_ARN"]
def lambda_handler(event, context):
session_id = event.get("runtimeSessionId") or f"cron-{uuid.uuid4()}"
payload = json.dumps(event.get("payload", {"task": "daily"})).encode()
resp = client.invoke_agent_runtime(
agentRuntimeArn=RUNTIME_ARN,
runtimeSessionId=session_id,
payload=payload,
)
# ストリーミングなら最初の data 行だけ受けて終了
if resp.get("contentType","").startswith("text/event-stream"):
body = resp["response"]
for line in body.iter_lines():
if line: # 1行受け取れれば「起動成功」の目安
break
body.close()
logger.info("AgentCoreを起動しました。タスクを終了します。")
return {"ok": True, "mode": "fire-and-return"}
環境変数には作成したAgentCore RuntimeのARNを設定しておいてください。
最後にEventBridge Schedulerを用意します。
適当にスケジュールを設定し、ターゲットは先程のLambda関数を指定。
入力ペイロードには以下を入力し、エージェントには指定したURL検索をしてもらいます。
ここで設定したruntimeSessionIdをAgentCore Runtimeにも渡すのですが、32文字以上でないとエラーになるので注意です。
{
"runtimeSessionId": "cron-2025-10-14-daily-7f0a2b0b5e6a4a35b4f2d1c8d9e0a1bc",
"payload": {
"action": "start",
"job_id": "daily-research",
"input": "Fetch https://qiita.com/har1101/items/cd6b92f1967a0d262c4a and summarize in 5 bullets.",
"seconds": 2
}
}
また、EventBridgeのサービスロールにinvokeFunctionを許可するポリシーを設定されていることを確認しておきましょう。
そしてEventBridgeに設定した時刻が来ると、自動でエージェントが起動します。
Lambda関数やAgentCore Runtimeのログを確認してみましょう。
まずはLambda関数のログ。数秒で動作完了しているのがわかると思います。
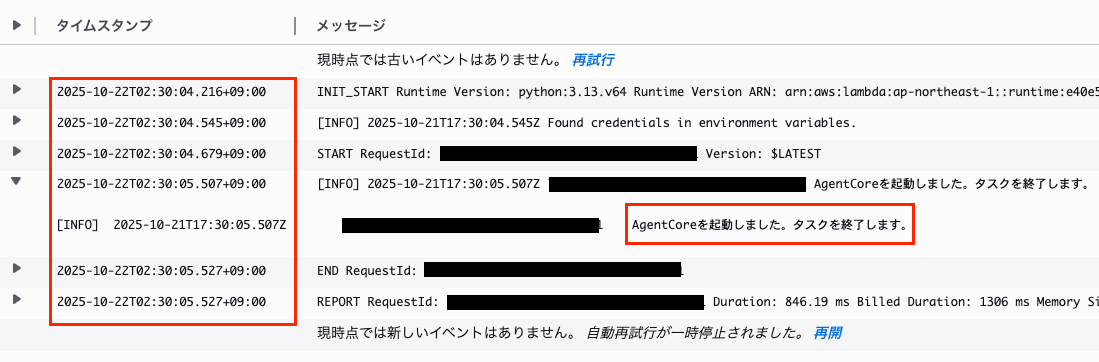
続いて、AgentCore Runtimeのログを確認すると、以下のような形でトレースが確認できるはずです。
INFO:bedrock_agentcore.app:Async task started: agent_job (ID: ******)
INFO:bedrock_agentcore.app:Invocation completed successfully (0.000s)
INFO:AsyncAgent:[AsyncAgent] job=daily-research | start background | input=Fetch https://qiita.com/har1101/items/cd6b92f1967a0d262c4a and summarize in 5 bullets.
I'll fetch that Qiita article and summarize it for you.
Tool #1: http_get
INFO:httpx:HTTP Request: GET https://qiita.com/har1101/items/cd6b92f1967a0d262c4a "HTTP/1.1 200 OK"
I'll summarize the article in 5 bullets:
**Summary of "AgentCore Gateway's Target Type now includes 'MCP server'!"**
• **New Feature Announcement**: AWS added "MCP server" as a new target type for AgentCore Gateway, alongside the launch of Bedrock AgentCore in Tokyo region.
• **Simplified Integration**: Previously, connecting to external MCP servers required coding each connection individually into AI agents; now Gateway can handle MCP server configurations centrally, eliminating the need to modify code each time servers change.
• **Remote MCP Server Support**: The feature supports external MCP servers accessible via URL (not localhost), allowing connection to publicly available remote MCP servers or AWS-hosted endpoints with proper authentication.
• **Authentication Options**: Supports OAuth2 (2-legged) or NoAuth for outbound authentication, with NoAuth available for specific servers like AWS Knowledge MCP server that don't require authentication.
INFO:AsyncAgent:[AsyncAgent] job=daily-research | completed
{
"timestamp": "2025-10-21T17:30:20.398Z",
"level": "INFO",
"message": "Async task completed: agent_job (ID: *******, Duration: 14.91s)",
"logger": "bedrock_agentcore.app",
"requestId": "******",
"sessionId": "cron-2025-10-14-daily-7f0a2b0b5e6a4a35b4f2d1c8d9e0a1bc"
}
INFO:bedrock_agentcore.app:Async task completed: agent_job (ID: ******, Duration: 14.91s)
ということでLambdaが起動した後、AgentCore Runtimeがバックグラウンドで動き続けていた様子がわかると思います。
今回はWeb検索を行うだけのエージェントでしたが、もっと色んな処理やツールを入れ込んであげると、裏側で自動的にタスクを実行し続けてくれるAmbientなAgentが作れそうです!
エラーハンドリングとエラー通知・再実行の仕組み・ステータスの可視化など、本番導入する場合に考えなければいけないことは多いです。
個人的にはre:Invent辺りでAgentCore Triggerみたいな追加機能や、LangChainのAgent Inboxみたいなものが出てくると嬉しいなと…
コードの実装解説
バックグラウンドでエージェントを動かせる仕組みについて解説しておきます。
※間違っているところなどあればコメントでご指摘ください。
全体のフロー
大まかな流れとしては以下のとおりです(図はClaudeが作ってくれましたが中身は確認し、修正しています)。
┌─────────────────────────────────────────────────────────────┐
│ Lambda関数(クライアント) → AgentCore Runtimeのエントリーポイント │
│ (POST /invocations エンドポイント) │
│ {"action":"start", "job_id":"test", "seconds":3} │
└─────────────────┬───────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ @app.entrypoint async def main(...) │
│ 1. task_id = app.add_async_task("agent_job", {...}) │
│ → Runtime が「処理中タスク」として登録 │
│ → /ping が "HealthyBusy" を返すようになる │
│ │
│ 2. asyncio.create_task(_background_run(...)) │
│ → イベントループにタスクをスケジュール │
│ │
│ 3. return {"status": "started", "task_id": ...} │
│ → 即座にクライアントに返却(main関数とLambda関数は終了) │
└─────────────────┬───────────────────────────────────────────┘
│
│ main関数は終了するが...
│
▼
┌─────────────────────────────────────────────────────────────┐
│ イベントループは継続中(app.run()が走っている) │
│ │
│ async def _background_run(task_id, payload, context): │
│ ├─ result = await asyncio.to_thread(agent, user_input) │
│ │ → Strandsエージェント実行(同期APIなのでスレッド化) │
│ └─ finally: app.complete_async_task(task_id) │
│ → ランタイムに「完了」を通知 │
│ → /ping が "Healthy" に戻る │
└─────────────────────────────────────────────────────────────┘
エージェントを非同期で呼び出す処理
ここでは、バックグラウンドでエージェントが動作する仕組みをお話します。以下の部分が該当します。
# --- バックグラウンドで動作する本処理 ---
async def _background_run(task_id: int, payload: Dict[str, Any], context):
try:
job_id = payload.get("job_id", "mvp")
seconds = int(payload.get("seconds", 0) or 0)
if seconds > 0:
await sleep_seconds(seconds)
user_input = payload.get("input") or "Say hello and show current_time."
log.info("[AsyncAgent] job=%s | start background | input=%s", job_id, user_input)
# Strands Agent 呼び出し(同期APIなのでスレッドにオフロード)
result = await asyncio.to_thread(agent, user_input)
log.info("[AsyncAgent] job=%s | completed", job_id)
except KeyError as e:
log.error("[AsyncAgent] job=%s | OpenTelemetry instrumentation error: %s", job_id, e)
except Exception as e:
log.exception("[AsyncAgent] job failed: %s", e)
finally:
# 必ず complete してセッションを解放
app.complete_async_task(task_id) # 非同期タスク完了マーク
前提として、async def _background_run()関数は非同期処理を行う関数です。
その中でStrandsエージェントを呼び出す処理を実行しています。
ただしエージェントを呼び出す処理自体は同期処理のため、result = agent(user_input)のように書いてしまうと_background_run()関数のイベントループが止まってしまいます。
そうなると他のタスクが走らなくなってしまうため、/pingのハンドラーなども止まってしまい、AgentCore Runtimeの正しい挙動を保てなくなります(恐らく)。
なので、エージェントを呼び出す処理自体を非同期化してあげる必要があります。
そこで色々調べていると、Bedrock Agentsを非同期的に実行している方がいらっしゃいました。
これと同じ手法が使えるのでは、と思って色々調べてみました。
await asyncio.to_thread()を用いることで、イベントループのブロックを回避しながらエージェントを動かせるようになります。
もう少し具体的に話すと、asyncioはasync/await構文を使い並行処理のコードを書くためのライブラリだそうです。
次にto_thread()関数によって同期関数を別スレッドで非同期的に実行します。
そしてawaitでその非同期的処理の完了を待つことができるようになります。
ただし同期処理を直接実行したときとは違って、完了を待っている間にも別のタスクが実行できるようになっている(=イベントループを止めない)という仕組みです。
すなわち、await asyncio.to_thread(agent, user_input)としておくことで、
Strandsエージェントの呼び出しを非同期的に行い
その完了を待っている間は別のタスクが動き続け
最終的にはエージェントの実行が終わるまで待ち続けてくれる
というような処理の流れになります。
本来であれば別の処理などを同時並行で動かしたり、あるいは直列実行したりというところに繋げていくのだと思いますが、ひとまず非同期処理の中でもエージェントを動かせますよということで。
invoke_async()関数でもできる
と、ここまで試したところで思い出したのですが、Strandsエージェントはinvoke_async()関数を使えば非同期で呼び出すことができるのでした。
なのでこれを使っても同じようなことができました。
import os, asyncio, logging
from typing import Dict, Any
from strands import Agent
from strands.models.bedrock import BedrockModel
from bedrock_agentcore import BedrockAgentCoreApp
from tools import http_get, sleep_seconds, current_time # ← ツールはそのまま
log = logging.getLogger("AsyncAgent")
logging.basicConfig(level=logging.INFO)
app = BedrockAgentCoreApp()
MODEL_ID = os.environ.get("BEDROCK_MODEL_ID", "jp.anthropic.claude-sonnet-4-5-20250929-v1:0")
# streamingは無効化しておく必要がありそう
model = BedrockModel(model_id=MODEL_ID, streaming=False)
SYSTEM_PROMPT = (
"You are a pragmatic research agent.\n"
"- Think step by step.\n"
"- Use tools when helpful (http_get, current_time, sleep_seconds).\n"
"- Keep outputs concise unless asked.\n"
)
agent = Agent(
model=model,
tools=[http_get, sleep_seconds, current_time],
system_prompt=SYSTEM_PROMPT,
)
# --- 裏で回る本処理(invoke_async でネイティブに実行)---
async def _background_run(task_id: int, payload: Dict[str, Any], context):
try:
job_id = payload.get("job_id", "mvp")
seconds = int(payload.get("seconds", 0) or 0)
if seconds > 0:
await asyncio.sleep(seconds)
user_input = payload.get("input") or "Say hello and show current_time."
log.info("[AsyncAgent(SDK)] job=%s | start background | input=%s", job_id, user_input)
# --- ここが変更点:to_thread → invoke_async(非同期ネイティブ) ---
# タイムアウトを付けたい場合は wait_for(...) でラップ
result = await agent.invoke_async(user_input)
log.info("[AsyncAgent(SDK)] job=%s | completed | result=%s", job_id, str(result)[:1000])
except Exception as e:
log.exception("[AsyncAgent(SDK)] job failed: %s", e)
finally:
app.complete_async_task(task_id) # セッション解放(必須)
# --- 即レスするエントリポイント ---
@app.entrypoint
async def main(payload: Dict[str, Any], context=None):
if payload.get("action") == "start":
task_id = app.add_async_task("agent_job", {"job_id": payload.get("job_id")})
asyncio.create_task(_background_run(task_id, payload, context))
return {"status": "started", "task_id": task_id}
return {"status": "noop"}
if __name__ == "__main__":
app.run()
先程to_threadを使って非同期化していた部分をinvoke_async()に置き換えるだけです。簡単ですね。
ただ、Bedrockのストリーミングレスポンスは無効化しておかないとエラーが出そうです。
私の環境では以下のエラーが出ました。
"exception.message": "An error occurred (ServiceUnavailableException) when calling the ConverseStream operation (reached max retries: 4): Too many connections, please wait before trying again."
このエラーはConverseStream API使用時のスロットリングエラーです。コネクション繋ぎ過ぎだよって起こられてます。
調べてみると、以下ドキュメントに記載がありました。
対策としてはリトライ処理・クロスリージョン推論・プロビジョンドスループットなどが記載されています。
が、ここではストリーミング処理を無くすだけでも解消できそうです。
前提として、Strandsエージェントはデフォルトでストリーミングレスポンスしてくれます。
このとき、裏側ではConverseStream APIが用いられているのだと思います。
それを無効化する際には、BedrockModelの定義においてstreaming=Falseを指定します。これによってConverse APIの使用に切り替わるはずなので、上記のエラーも緩和される…と思っています。
まとめ
これがあればAmbient Agentが作れそう!!
でもまどろっこしいので、AgentCore Trigger的な機能が追加されるといいなーと思っています!
他の参考資料