はじめに
JoeSandboxというマルウェアを解析してレポートを出力してくれるサイトがあります。
https://www.joesandbox.com
JoeSandboxには色々バージョンがありますが、Cloud Basicというバージョンであれば無料でマルウェア解析ができます。
さらにCloud Basicで解析されたレポートは公開されますので、他の人の分析結果レポートを見ることもできます。
今回はマルウェアの分析結果レポートをBeautifulSoup+PythonでWebスクレイピングし、プロセス情報を取得してみたいと思います。
ちなみにCloud Basic以外のバージョンですとWeb APIが利用できますが、Cloud Basicでは利用できないようです。
JoeSandboxについて
分析画面です。この画面でマルウェアを指定し、色々なオプションなどを設定したのちに分析を行います。
分析結果の一覧画面です。
分析結果の詳細画面です。色々な分析結果が出力されていますので、分析結果の一部分の画面キャプチャです。
https://www.joesandbox.com/analysis/175872/0/html#startup
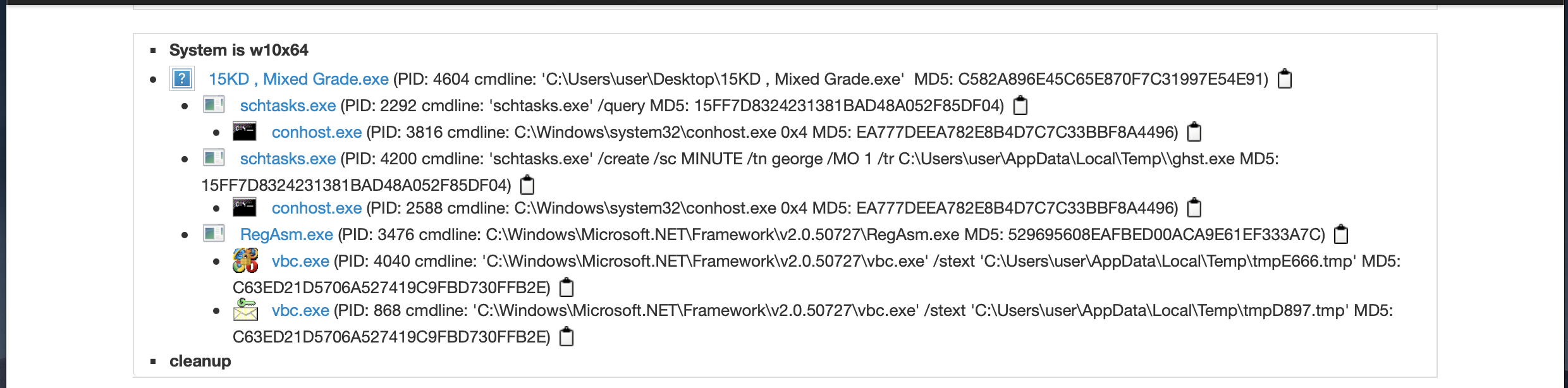
今回やりたいこと
今回は分析結果の詳細画面から、マルウェアのプロセスの一連の流れを抽出したいと思います。
具体的には以下の部分の情報を抽出します。
出力結果は以下のようにしようと思います。プロセスの親子関係がわかるようにインデントをつけた状態で出力しようと思います。
レポート番号:xxxxx 実行日時
15KD , Mixed Grade.exe
schtasks.exe
conhost.exe
schtasks.exe
conhost.exe
RegAsm.exe
vbc.exe
vbc.exe
コード
以下に記載の内容を繋げたら動くようにしています。
必要なライブラリをインポート
BeautifulSoup以外にrequests, os, datetime, pytz もインポートします。
import requests
from bs4 import BeautifulSoup
import os
import datetime, pytz
抽出するレポート番号の指定
複数のレポートから情報を抽出するため、fromとtoを入力するように準備します。ここではテスト用に1つだけ指定しています。
report_num_from = 175872
report_num_to = 175872
指定されたページのクロール
レポートのURLは以下のようになっています。この「175872」の部分がレポート番号のようですので、この番号をループするようにしたいと思います。
https://www.joesandbox.com/analysis/175872/0/html
def find_process_name(report_num_from, report_num_to):
for i in range(report_num_from, report_num_to + 1):
try:
process_names = []
process_names.append('\n[report number]:{} {}'.format(i, datetime.datetime.now(pytz.timezone('Asia/Tokyo'))))
target_url = 'https://www.joesandbox.com/analysis/' + str(i) + '/0/html'
response = requests.get(target_url)
soup = BeautifulSoup(response.text, 'lxml')
JoeSandboxの状態の確認
JoeSandboxはマルウェアの分析結果により、malicious, suspicious, clean, unknownと分けられているようです。
マルウェアのプロセス情報を取得したいので、ここではmaliciousのみ抽出しようと思います。以下はmaliciousの画面例です。
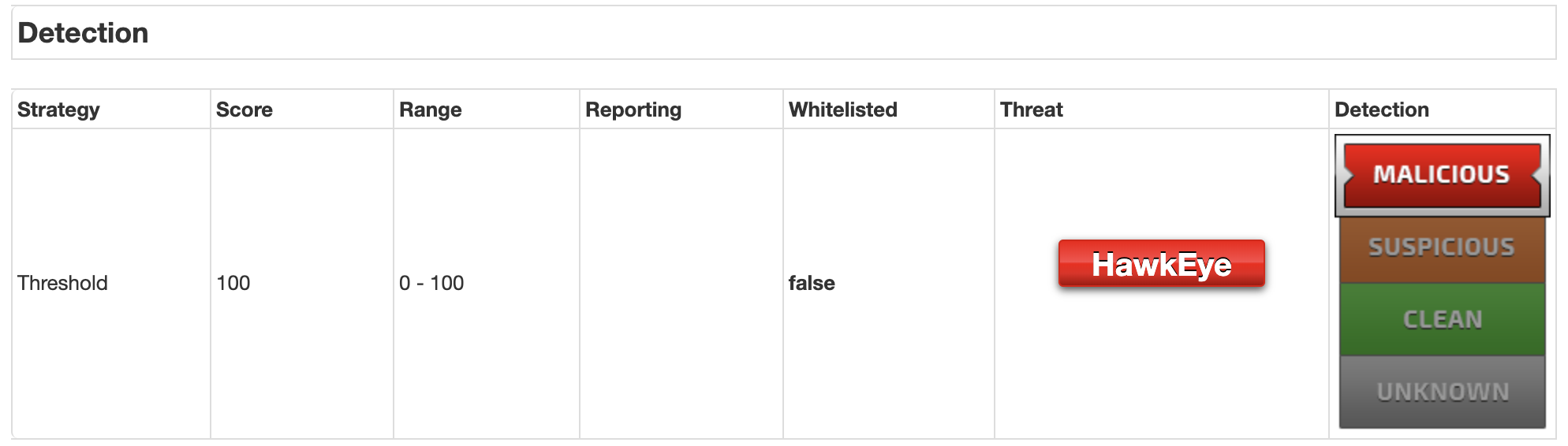
上記のmaliciousの情報を情報を取得してみようと思います。
該当のコードは以下でした。

imgでidがanalysisDetectionStatusのaltに情報が指定されるようです。
この情報を取得するにはsoup.find('img', id='analysisDetectionStatus').get('alt')と記載すれば良いので、それを組み込みます。
detection = soup.find('img', id='analysisDetectionStatus').get('alt')
プロセス情報の取得
以下はプロセス情報の画面例です。
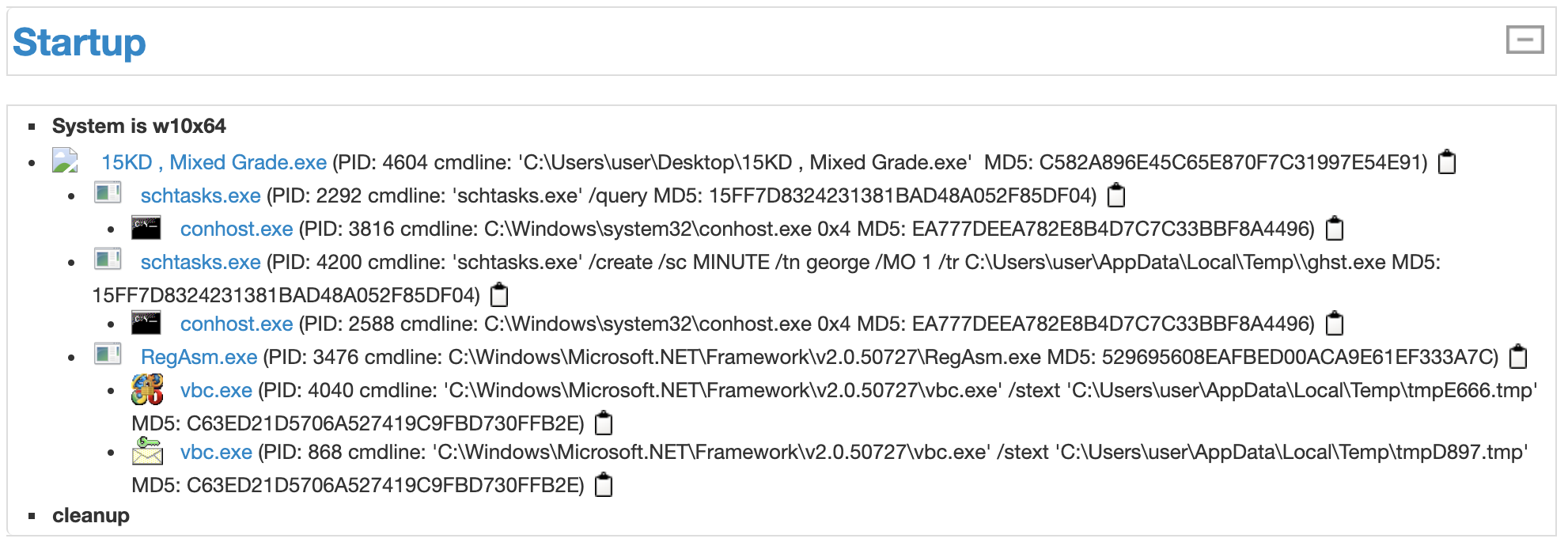
このプロセス情報を取得してみようと思います。
該当のコードは以下でした。
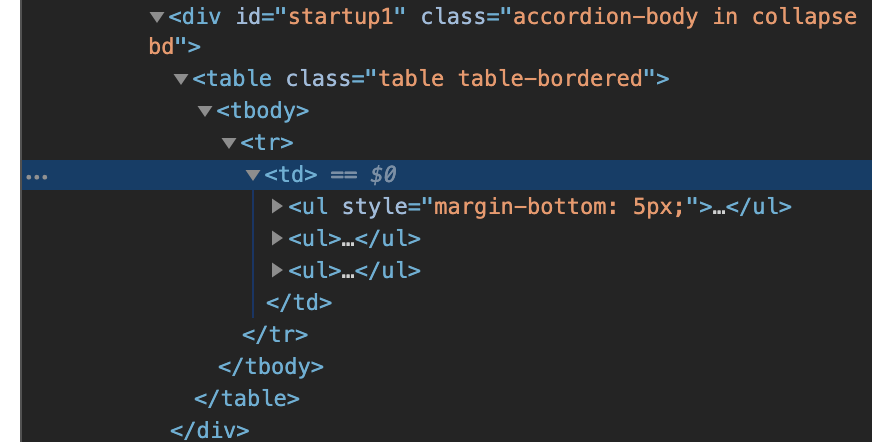
中身を確認してみます。
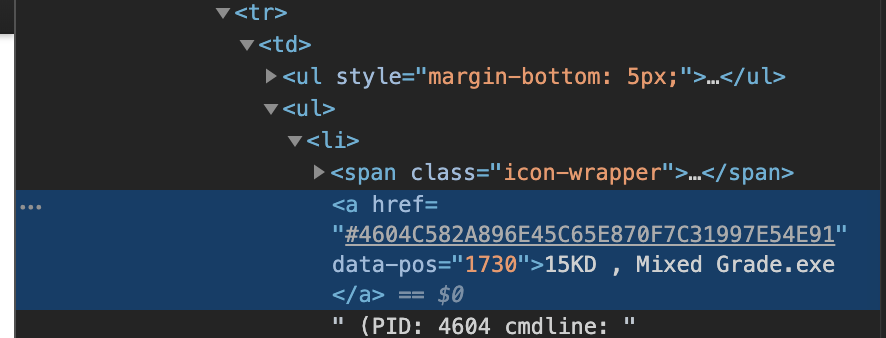
どうやらプロセス情報はテーブルに格納されているようです。
divのidがstartup1の中身を配列に格納して、その中でプロセス情報を取得しようと思います。
ちなみにプロセス情報は<a hrefの次に格納されていましたので、以下のようにしました。
もっとスマートなやり方がありそうですが・・・。
if detection == 'malicious':
startup = soup.find('div', id='startup1')
flag = False
for line in startup.prettify().split('\n'):
if flag == True:
process_names.append(line)
flag = False
if '<a href' in line:
flag = True
else:
process_names.append('not malicious')
例外処理
例外処理の部分も忘れずに記載します。
処理の最後にsave_file関数(この後記載)を呼び出します。
# Report number does not exist
except IndexError as e:
process_names.append('ERROR:{}'.format(e))
except Exception as e:
process_names.append('ERROR:{}'.format(e))
finally:
save_file(process_names)
ファイル書き込み
ファイルに書き込む処理です。
別に関数にしなくても良いですが今後ファイル書き出し以外の処理に変更しようと思うので、書き換えやすいように関数にしました。
同じフォルダにoutput.txtを作成して書き込みます。
def save_file(process_names):
with open('./output.txt', 'a') as f:
for x in process_names:
f.write(str(x) + "\n")
処理の実行
関数を実行します。
これで完了です。
find_process_name(report_num_from, report_num_to)
完成したコード
今までのコードをつなげて、コメントを追加しました。
当たり前のことですがfromとtoで指定する範囲はほどほどにしてください。
# Extract process name from JoeSandbox analysis result.
#
# How to use:
# 1. Enter the first and last report number you want to analyze.
# -> report_num_from and report_num_to
# 2. Result is saved as output.txt in the same folder.
import requests
from bs4 import BeautifulSoup
import os
import datetime, pytz
report_num_from = 175872
report_num_to = 175874
def find_process_name(report_num_from, report_num_to):
"""
Extract process name from JoeSandbox analysis result.
Parameters
----------
report_num_from : int
First report number to analyze
report_num_to : int
Last report number to analyze
"""
for i in range(report_num_from, report_num_to + 1):
try:
process_names = []
process_names.append('\n[report number]:{} {}'.format(i, datetime.datetime.now(pytz.timezone('Asia/Tokyo'))))
target_url = 'https://www.joesandbox.com/analysis/' + str(i) + '/0/html'
response = requests.get(target_url)
soup = BeautifulSoup(response.text, 'lxml')
# check JoeSandbox Detection (malicious, suspicious, clean, unknown)
detection = soup.find('img', id='analysisDetectionStatus').get('alt')
if detection == 'malicious':
# 'startup1' is a table with process names
startup = soup.find('div', id='startup1')
# process name is next to '<a href'
flag = False
for line in startup.prettify().split('\n'):
if flag == True:
process_names.append(line)
flag = False
if '<a href' in line:
flag = True
else:
process_names.append('not malicious')
# Report number does not exist
except IndexError as e:
process_names.append('ERROR:{}'.format(e))
except Exception as e:
process_names.append('ERROR:{}'.format(e))
finally:
save_file(process_names)
def save_file(process_names):
"""
Save the extraction results to a file.
File I/O is a function because it may change.
Parameters
----------
process_names : list of str
List containing process names.
"""
with open('./output.txt', 'a') as f:
for x in process_names:
f.write(str(x) + "\n")
find_process_name(report_num_from, report_num_to)
実行結果
上記のコードを実行すると以下のような結果が得られます。
[report number]:175872 2019-10-12 22:14:58.066360+09:00
15KD , Mixed Grade.exe
schtasks.exe
conhost.exe
schtasks.exe
conhost.exe
RegAsm.exe
vbc.exe
vbc.exe
[report number]:175873 2019-10-12 22:15:04.034550+09:00
not malicious
[report number]:175874 2019-10-12 22:15:11.023350+09:00
EXCEL.EXE
関連
Joe Sandboxに関する詳細な説明は以下にまとめています。
Joe Sandboxでマルウェアの動的解析をする方法
https://qiita.com/hanzawak/items/ec665e0f96dc65f3def3
BeautifulSoup+Pythonで、マルウェア動的解析サイトからPowerShellコマンド取得
https://qiita.com/hanzawak/items/15a88c4953be4f8159da