データ分析における関数の使い方については様々な記事が上がっています。関数を知らなかったり使い方が分からないときは調べればだいたい答えが見つかります。
一方で、実際に分析を始めようとすると、たとえ関数の使い方がわかっていても、データをどのような切り口から何を分析・可視化していけば良いのか困ってしまうことがよくあります。
この記事では、あんちべさんが書いたデータ解析の実務プロセス入門という本をベースに、どのようなデータから何を見たいときにどのような可視化手法を使えばよいのかを、具体例を交えながら整理していきます。
探索的データ解析とは
データ解析のアプローチは、大きく分けて仮説をデータで検証する「仮説検証型」とデータから仮説を生み出す「探索型」に分けられます。
実際にデータ解析を行うときは、仮説検証型と探索型を行き来しつつ知見を見出していきます。
データ解析には検証すべき仮説を設定することが必要で、仮説無しに解析をしても得るものはありません。しかし、仮説を得られないときもあります。そこで、まず仮説を作るためにデータを様々な切り口から眺めて傾向を探る必要があります。
そこで探索的データ解析を行います。
探索的データ解析における可視化手法
生データを眺めただけではデータの傾向を把握することが出来ないので、データを様々な切り口から可視化する必要があります。
データの性質や目的に応じて適切な可視化手法を選択することが大事になってきます。
目的やデータの性質に合わせて可視化手法を整理します。
以下この順番で説明していきます。
- データの分布をみる
- データが連続値
- 比較対象が無いor少ない: ヒストグラム
- 比較対象が多い: 箱ひげ図
- データが離散値
- 大きさの比をみる: 棒グラフ
- 内訳をみる: 帯グラフ
- 大きさの比とその内訳をみる: 積み上げ棒グラフ
- データが連続値
- データの関係をみる
- データが連続値: 散布図
- データが離散値: クロス集計/ヒートマップ
- データの推移をみる
- 傾きの増減とその程度をみる: 折れ線グラフ
- 推移の方向と分布をみる: ロウソク足チャート
最初の環境設定
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('darkgrid')
plt.rcParams['font.family'] = 'IPAPGothic'
plt.rcParams['font.size'] = 18
%matplotlib inline
使用するデータ
具体例としてirisデータを使います。setosa, versicolor, virginicaという3種類のアヤメのがく片(Sepal)と花弁(Petal)の長さを測ったデータです。
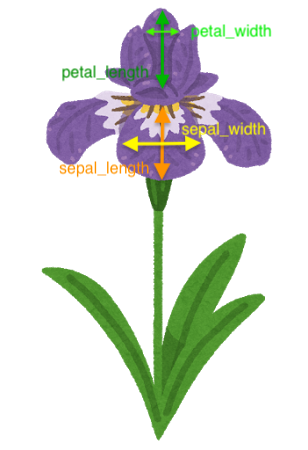
iris=sns.load_dataset("iris")
データの分布をみる
データの分布を確認する可視化手法をまとめます。
見たいデータが連続値の場合
比べる変数が無いor少ない場合: ヒストグラム
データの特徴を把握するのに使います。
例えば、データにどの程度バラツキがあるのか、どの範囲にデータが集まっているのか、ある範囲のデータの個数はどの程度か、などを見たいときです。
ヒストグラムが多峰な場合はクラスタリングが必要かもしれません。
irisのがく片の長さのヒストグラムを書いてみます。
# 描画する枠figを指定
fig = plt.figure(figsize=(12, 8))
# 描画領域を1行1列に分割し、そのうちの1番目の分割領域をaxとする
ax = fig.add_subplot(111)
# axにヒストグラムを描画
ax.hist(x=iris["sepal_length"],
bins=np.arange(4, 8, 0.25),
range=(4, 8),
rwidth=0.9)
ax.set_title("がくの長さのヒストグラム(cm)")
ax.set_xlabel("がくの長さ(cm)")
ax.set_ylabel("出現数")
plt.show()
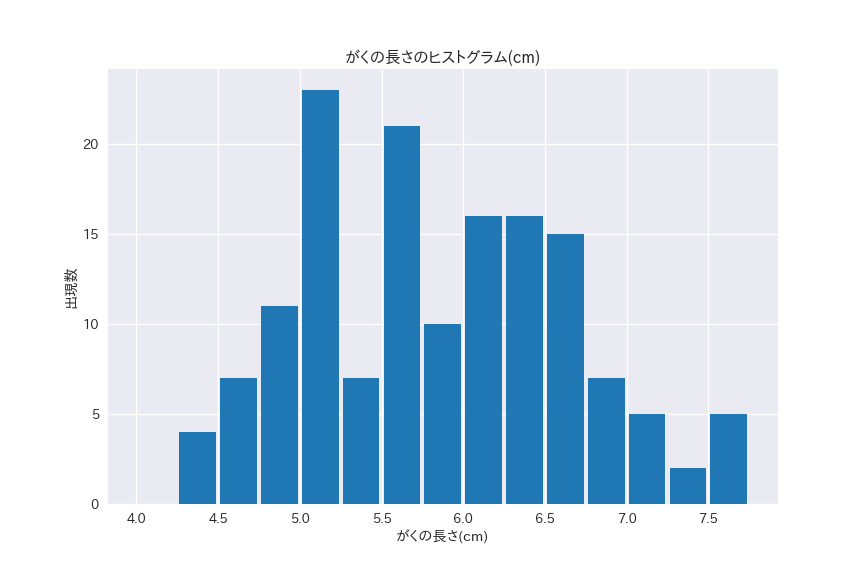
がくの長さは4.25cm~7.5cmの間に分布していることがわかります。
分布の偏りはありませんが、山が3つあることがわかります(多峰)。
上のヒストグラムは全ての品種を同時にプロットしたので、今度は品種ごとにグループ化してみます。
setosa = iris[iris.species=="setosa"]
versicolor = iris[iris.species=="versicolor"]
virginica = iris[iris.species=="virginica"]
fig = plt.figure(figsize=(12, 8))
ax = fig.add_subplot(111)
ax.hist(x=setosa["sepal_length"], bins=np.arange(4, 8, 0.25), alpha=0.6, ec="black")
ax.hist(x=versicolor["sepal_length"], bins=np.arange(4, 8, 0.25), alpha=0.6, ec="black")
ax.hist(x=virginica["sepal_length"], bins=np.arange(4, 8, 0.25), alpha=0.6, ec="black")
ax.set_title("品種毎のがくの長さのヒストグラム(cm)")
ax.set_xlabel("がくの長さ(cm)")
ax.set_ylabel("出現数")
ax.set_yticks([i * 2 for i in range(11)])
ax.legend(prop={'size': 18})
plt.show()
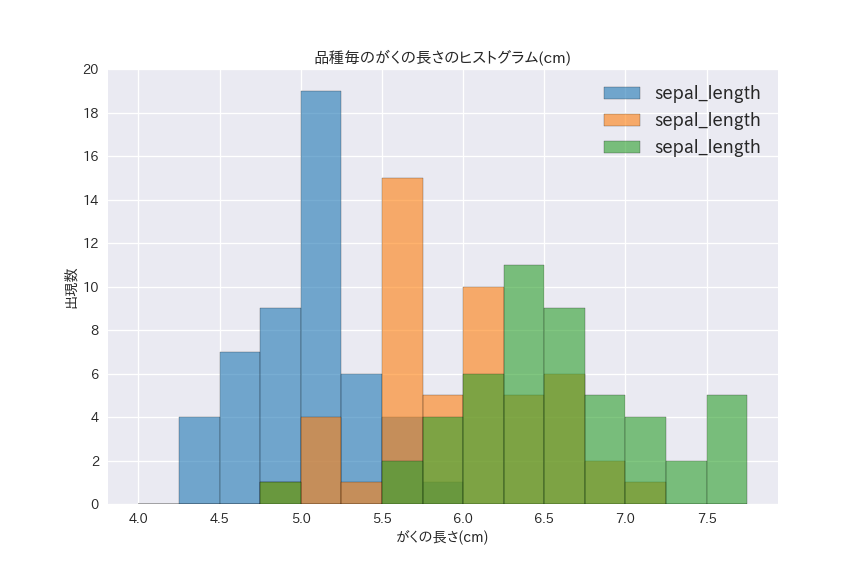
多峰になっていた原因が主に品種による偏りであることがわかります。
setosaは5.0付近、versicolorは5.5付近、virginicaは6.5付近にデータが集まっています。
virginicaのデータの散らばりが大きくてsetosaの散らばりが小さいように見えますが、見かけのデータの散らばりは平均値が大きくなればなるほど大きくなっていくので注意が必要です。
versicolorが5.5, 6.0, 6.5に山があったり、virginicaが7.75で分布が増えているのが気になります。
比較対象が多い場合: 箱ひげ図
ヒストグラムは分布の状態を詳しく分析することができますが、これ以上比較対象が増えると複数のヒストグラムを並べて同時に比較するのが難しくなります。
そこで、箱ひげ図を使ってたくさんの対象を同時に比較します。
labels = []
species_list = []
# 品種ごとのがくの長さをリスト化
for s, df_per_s in iris.groupby(by="species"):
labels.append(s)
species_list.append(df_per_s["sepal_length"].tolist())
fig = plt.figure(figsize=(12, 8))
ax = fig.add_subplot(111)
ax.boxplot(x=species_list,
labels=labels)
ax.set_title("品種毎のがくの長さの箱ひげ図")
ax.set_xlabel("品種")
ax.set_ylabel("がくの長さ")
plt.show()
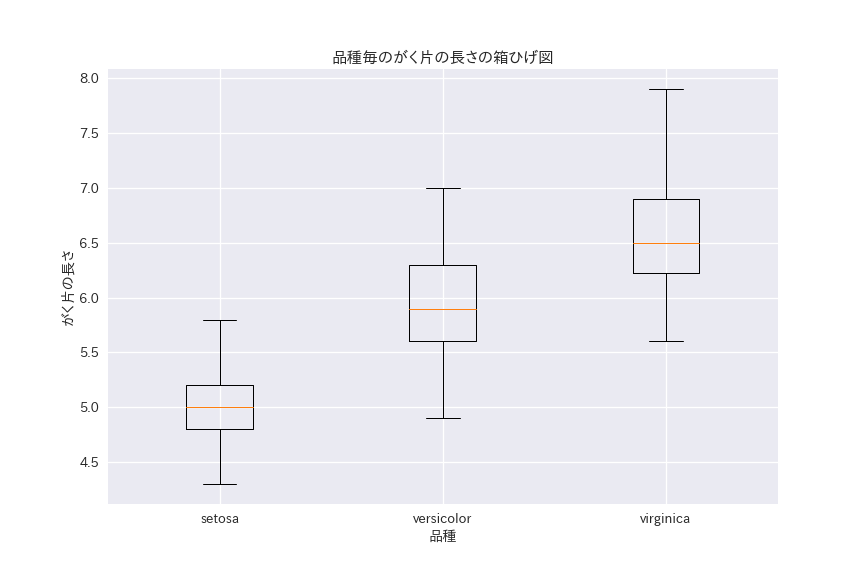
setosaやversicolorに比べてvirginicaが上に裾野が長いことがわかります。
箱ひげ図はたくさんの対象を同時に比較しやすい一方で、ヒストグラムでは見えたversicolorの多峰性が見えなくなるなど、対象一つあたりの情報量は減ってしまいます。
見たいデータが離散値の場合
大きさの比をみる: 棒グラフ
棒グラフは各項目の大きさを比べるのに使います。
比の関係を知りたいので、縦軸の値の一部を省略してはいけません。
品種毎にがく片の長さの平均の比を見ます。
品種はカテゴリカルな変数なので離散値です。
# 品種毎のがく片の長さの平均を計算
data = iris.groupby(by=["species"], as_index=False)[["species", "sepal_length"]].mean()
fig = plt.figure(figsize=(12, 8))
ax = fig.add_subplot(111)
ax.bar(x=data.species, height=data.sepal_length)
ax.set_title("品種毎のがく片の平均の長さ")
ax.set_xlabel("品種")
ax.set_ylabel("がく片の平均の長さ")
plt.show()
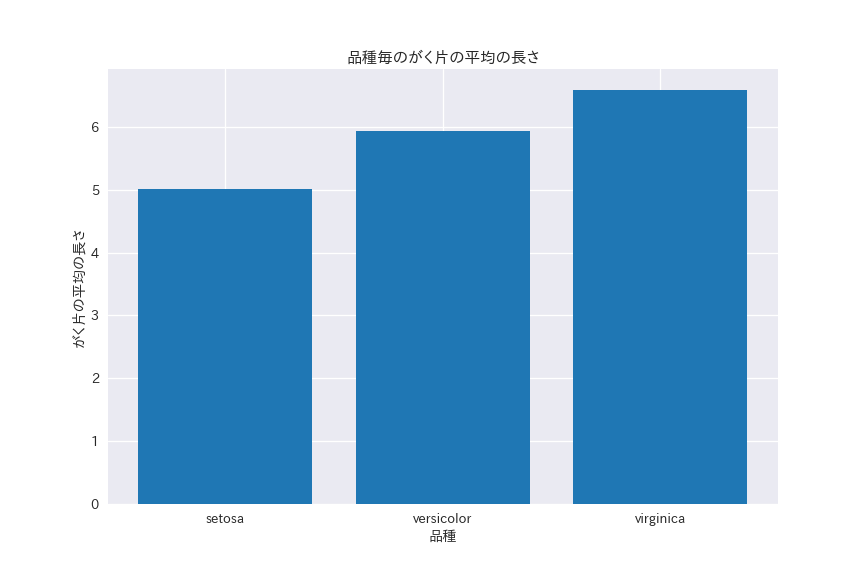
上の棒グラフをみると、setosaに比べてversicolorのがくは約1.2倍、virginicaは約1.3倍長いことがわかります。
内訳をみる: 帯グラフ
帯グラフはデータの内訳とその割合を見るときに使います。
irisに含まれる品種の出現割合を調べてみます。
# matplotlibには帯グラフを描画する関数が無い
# 積み上げ棒グラフを合計値が1になるよう正規化する
s_counts = iris["species"].value_counts()
s_normed = s_counts / s_counts.sum()
bottom = 0
fig = plt.figure(figsize=(15, 4))
ax = fig.add_subplot(111)
for s in range(s_normed.shape[0]):
ax.barh([""], s_normed[s], left = bottom, label = s_normed.index[s]) # barh()ならleft, bar()ならbottomを指定
bottom += s_normed[s]
ax.set_title("品種毎の出現割合の帯グラフ")
ax.set_xlabel("割合")
legend = ax.legend(prop={'size': 18})
# legendの背景を白にしたいんだけどうまく動かない
legend.get_frame().set_facecolor("white")
# 代わりにXの右側のマージンを広くとる
ax.set_xlim(0, 1.25)
ax.set_xticks([0, 0.2, 0.4, 0.6, 0.8, 1.0])
plt.show()
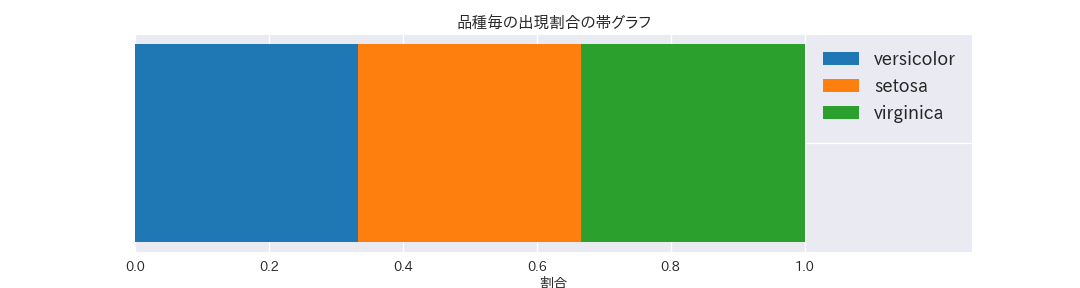
出現割合が3等分されていることがわかります。
帯グラフの描画で参考にしたサイト
matplotで帯グラフ
api example code: legend_demo.py
大きさの比と内訳をみる: 積み上げ棒グラフ
積み上げ棒グラフは棒グラフと帯グラフを合体させたグラフです。
複数のデータの大きさの比とその内訳を同時に表現するときに使います。
主に複数の変数をもつ時系列のデータに使われますが、今回はirisのがく片の長さを短(4~5cm)中(5~7cm)長(7~8cm)で分割して、グループ間の出現数の比と各グループにおける品種の内訳をみてみます。
# irisデータにrank列を付与
ranks = ["short", "medium", "long"]
iris["rank"] = pd.cut(iris["sepal_length"], [4, 5, 7, 8], labels = ranks)
# rankと品種で集計、ピボットテーブル化
iris_grouped = iris.groupby(["rank", "species"]).size().reset_index()
iris_pivoted = iris_grouped.pivot(index="rank", columns="species", values=0)
# 描画
fig = plt.figure(figsize=(12, 8))
ax = fig.add_subplot(111)
rows, cols = iris_pivoted.shape[0], iris_pivoted.shape[1]
x = iris_pivoted.index
for i, s in enumerate(iris_pivoted.columns):
# i列目から最終列までの和を計算
y = iris_pivoted.iloc[:, i:cols].sum(axis=1)
ax.bar(x, y, label=s)
ax.set_title("がく片の長さ別にみた出現頻度の大きさの比と品種の内訳")
ax.set_xlabel("がく片の長さ")
ax.set_xticks(["short", "medium", "long"])
ax.set_ylabel("出現頻度")
ax.legend()
plt.show()
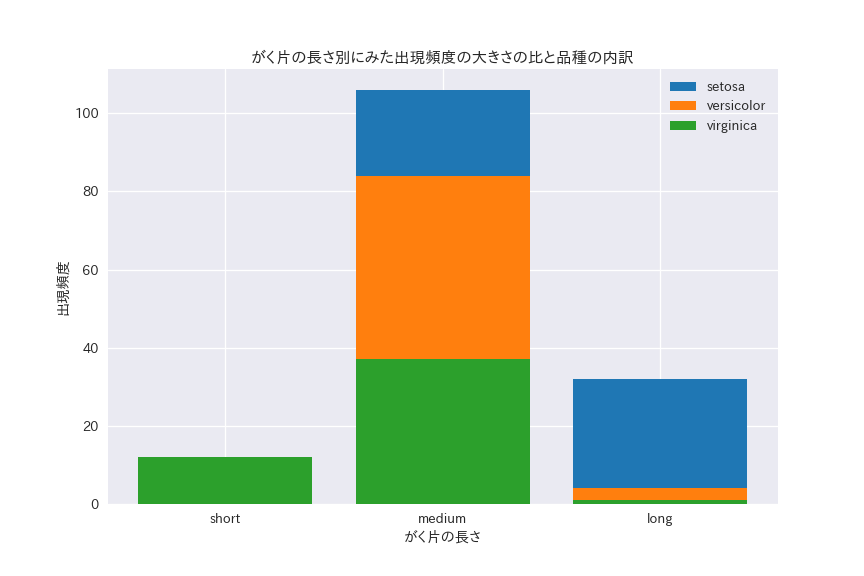
がく片の長さはmediumが一番多くて、longが一番少ないです。
shortはsetosa、mediumはversicolor、longはvirginicaの割合が多いことがわかります。
Pandas Plotを使った方がはるかに楽に描画出来ます。
iris_pivoted.plot.bar(y=["setosa", "versicolor", "virginica"], figsize=(12, 8), stacked=True)
データの関係をみる
データの関係をみたいときの可視化手法をまとめます。
見たいデータが連続値の場合: 散布図
散布図は二つの量的変数の関係を見るのに使います。
正の相関、負の相関があるのかどうかや、その強弱を調べます。
がく片の長さ(Sepal_length)と花弁の長さ(Petal_length)の関係を調べてみましょう。
fig = plt.figure(figsize=(12, 8))
ax = fig.add_subplot(111)
ax.scatter(iris["sepal_length"],
iris.loc["petal_length"])
ax.set_title("がく片の長さと花弁の長さの散布図(cm)")
ax.set_xlabel("がく片の長さ(cm)")
ax.set_ylabel("花弁の長さ(cm)")
plt.show()
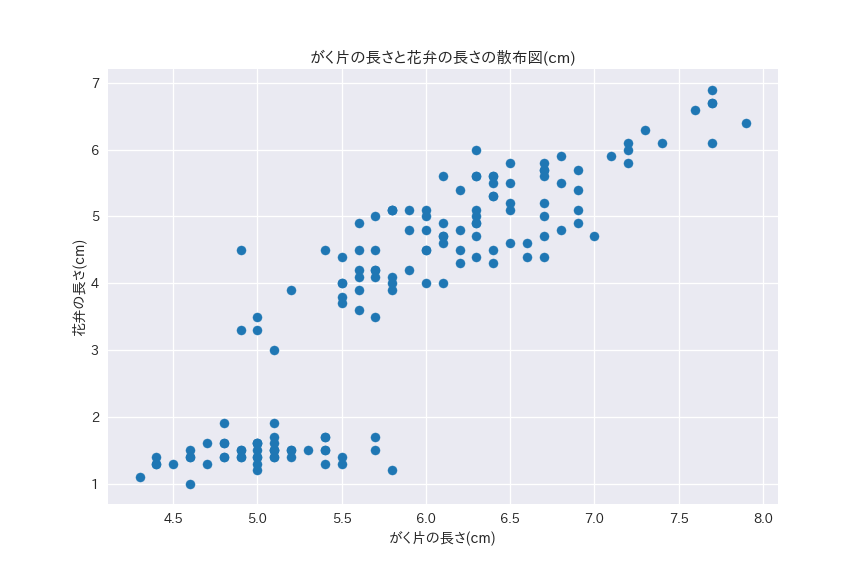
がく辺の長さと花弁の長さに弱い正の相関があることがわかります。
相関の強弱は散布図を見れば大まかにわかりますが、線形の相関の強さを比較したいときには相関係数を用います。
相関係数を調べる際は、散布図がきちんと線形に散らばっているか確認しましょう。
クラス毎に集計することもできます。
fig = plt.figure(figsize=(12, 8))
ax = fig.add_subplot(111)
for s in iris["species"].unique():
ax.scatter(iris.loc[iris["species"] == s, "sepal_length"],
iris.loc[iris["species"] == s, "petal_length"])
ax.set_title("クラス毎のがく片の長さと花弁の長さの散布図(cm)")
ax.set_xlabel("がく片の長さ(cm)")
ax.set_ylabel("花弁の長さ(cm)")
ax.legend(iris["species"].unique(), prop={'size': 18})
plt.show()
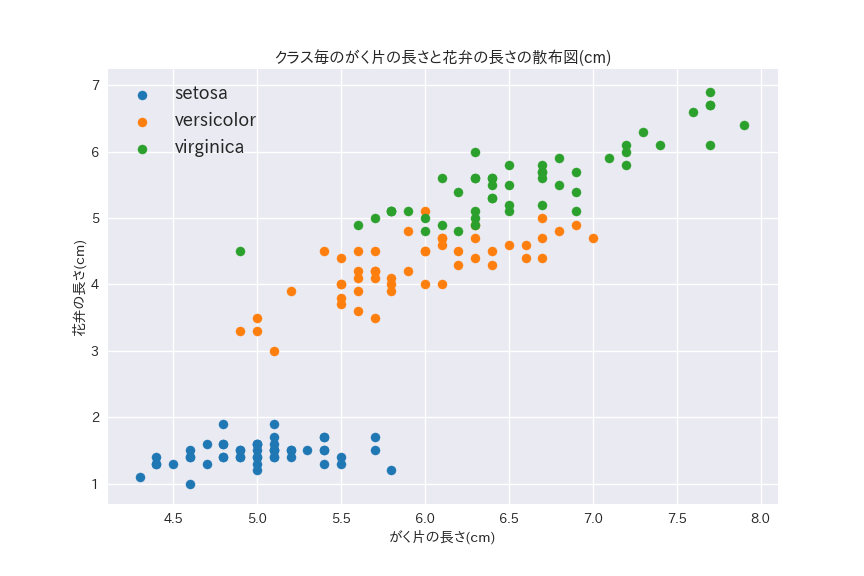
versicolorとvirginicaではがく片の長さと花弁の長さに強い正の相関がある一方で、setosaには相関が無いことがわかります。
複数の変数の関係を同時に見たいときは散布図行列を書きます。
g = sns.pairplot(iris, hue="species", markers=["o", "s", "D"])
plt.subplots_adjust(top=0.95)
g.fig.suptitle("品種毎の散布図行列", fontsize=18)
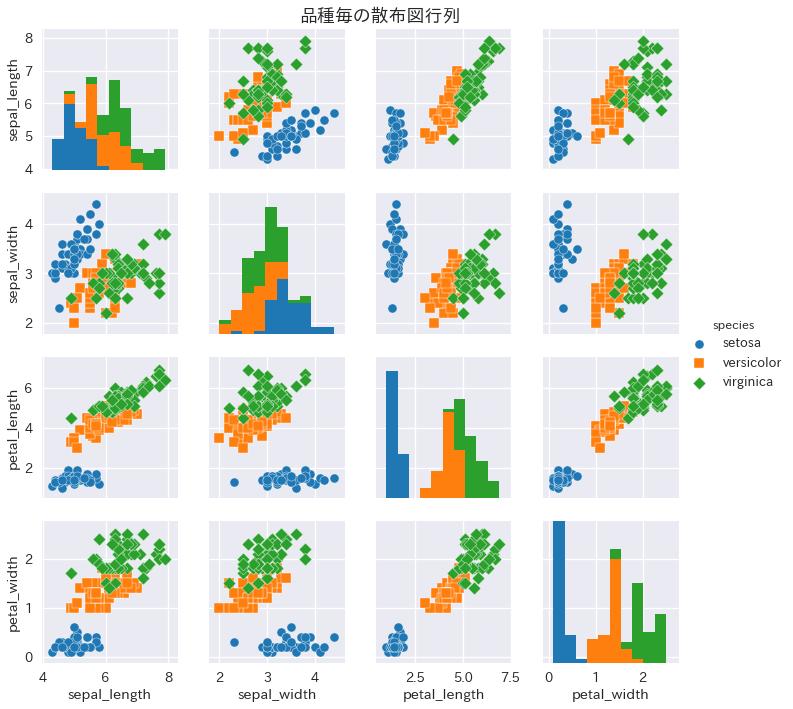
setosaは長さも幅もがく片と花弁の間に相関はないことがわかります。
一方でversicolor, virginicaはがく片と花弁の間に正の相関があり、長さの相関は強く、幅の相関は弱いことがわかります。
見たいデータが離散値の場合: クロス集計とヒートマップ
一方、あるいは両方に質的変数を含む変数同士の関係を見るときに使います。
ヒートマップはクロス集計のセルが多いときに威力を発揮します。
今回はflightsというデータを使います。
これは、1949年から1960年において、ある航空会社の乗客数の推移を表したデータです。
# データのロード
flights = sns.load_dataset("flights")
# クロス集計
flights_crossed = pd.pivot_table(flights, values="passengers", index="month", columns="year", aggfunc=np.mean)
# pd.crosstab(flights["month"], flights["year"], values=flights["passengers"], aggfunc=np.mean)でも可
flights_crossed

# ヒートマップ
fig = plt.figure(figsize=(12, 8))
g = sns.heatmap(flights_crossed, annot=True, cmap="Oranges", fmt='.5g')
g.figure.suptitle("乗客数のヒートマップ", fontsize=18)
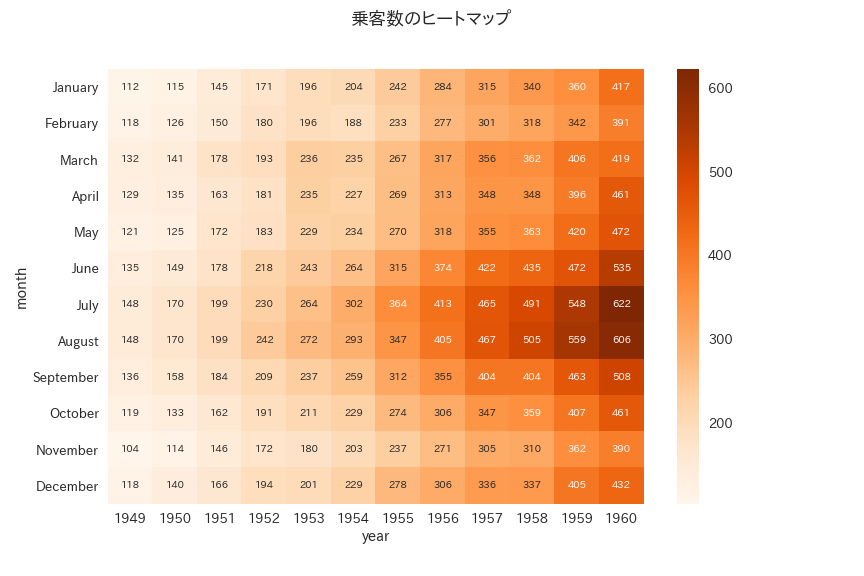
乗客数は1960年の7月が最も多いことがわかります。
また、冬より夏、1949年より1960年に近づくほど乗客数が多いことがわかります。
参考
Python でデータ可視化 - カッコいいヒートマップを描こう
データの推移をみる
主に時系列データに対して、時間的推移を見たいときの可視化手法をまとめます。
傾きの変化とその程度をみる: 折れ線グラフ
折れ線グラフを使うと、折れ線の傾きによって増減の有無とその度合いを一覧出来ます。
変化の程度、つまり変化分の比を見ることが目的である場合は、縦軸の値を省略しても壊れる心配がないため、省略しても構わない(こともあります)。
ただし、折れ線グラフを棒グラフの代わりに使っている場合(値そのものの大きさの比をみる場合)は省略してはいけません。
irisは時系列データではないので、今回もflightsを使います。
月毎の乗客数の推移とその程度を見てみます。
# 前処理
# 日付型を扱うモジュールのインポート
from datetime import datetime, date
# year列とmonth列を結合
flights["year_month"] = flights["year"].astype(str) + flights["month"].astype(str)
# year_month列を文字型からdate型に変換
for i in range(flights.shape[0]):
dt = datetime.strptime(flights.loc[i, "year_month"], "%Y%B") # strオブジェクトをtimeオブジェクトに変換(年-月-日 時:分:秒)
d = date(dt.year, dt.month, dt.day) # timeオブジェクトをdateオブジェクトに変換(年-月-日)
flights.loc[i, "year_month"] = d #dateオブジェクトをflightsに戻す
# 描画
from matplotlib.dates import MonthLocator, DateFormatter
fig = plt.figure(figsize=(15, 8))
ax = fig.add_subplot(111)
ax.plot(flights["year_month"], flights["passengers"])
# date型の表示形式を指定するインスタンス
monthsFmt = DateFormatter("%Y-%m")
# 月毎の区切りを指定するインスタンス
months = MonthLocator(interval=6)
ax.set_title("乗客数の推移の折れ線グラフ(月別)")
ax.set_xlabel("年月")
ax.xaxis.set_major_locator(months)
ax.xaxis.set_major_formatter(monthsFmt)
# X軸の範囲の設定
datemin = date(1949, 1, 1)
datemax = date(1961, 1, 1)
ax.set_xlim(datemin, datemax)
ax.set_ylabel("乗客数(人)")
# X軸の表示(date型)をよしなに整える
fig.autofmt_xdate()
plt.show()
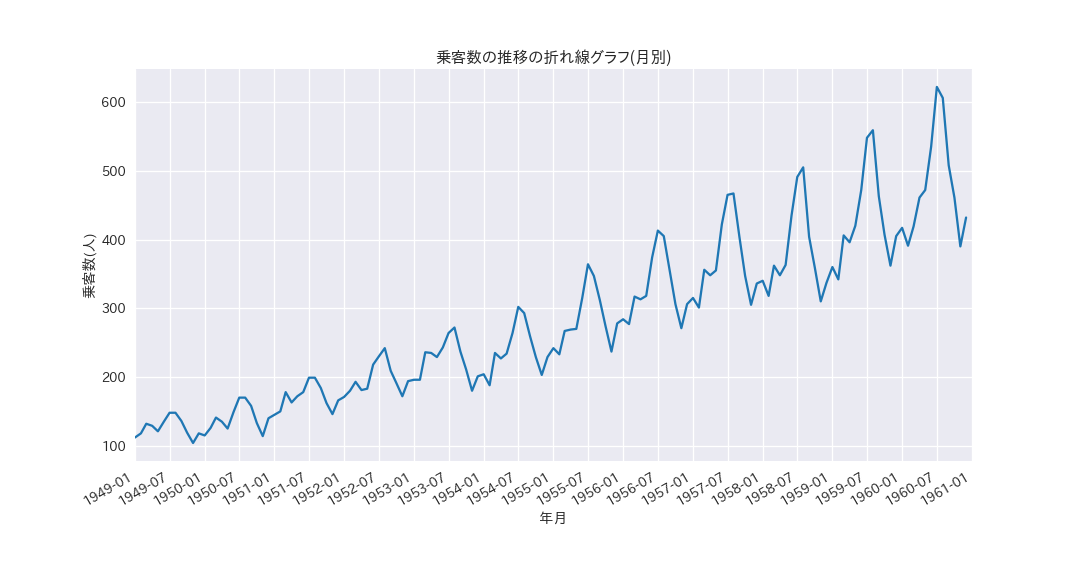
時系列データは、大きく分けてトレンド、季節性、ノイズに区別されます。
上の図を見ると、トレンドは上昇傾向にあり、上昇の度合いがやや増していることがわかります。
季節性は1年単位の周期で、夏にかけて乗客数が上昇し、冬にかけて乗客数が下降しています。また、1月と3月にも小さい上昇が見られます。
推移の方向と分布をみる: ローソク足チャート
ローソク足チャートは、主に金融業界で使われるグラフです。
株価の4本値(始値・高値・安値・終値)を時系列に沿って描画します。
一つ一つのローソク足を、時系列に沿って分布を表現することも出来ます。
flightsで月ごとに集計されていたデータを年ごとにまとめて表現します。
### 折れ線グラフと同様の前処理
# 日付型を扱うモジュールのインポート
from datetime import datetime, date
# year列とmonth列を結合
flights["year_month"] = flights["year"].astype(str) + flights["month"].astype(str)
# year_month列を文字型からdate型に変換
for i in range(flights.shape[0]):
dt = datetime.strptime(flights.loc[i, "year_month"], "%Y%B") # strオブジェクトをtimeオブジェクトに変換(年-月-日 時:分:秒)
d = date(dt.year, dt.month, dt.day) # timeオブジェクトをdateオブジェクトに変換(年-月-日)
flights.loc[i, "year_month"] = d #dateオブジェクトをflightsに戻す
### 年ごとに、最小値、25%点、75%点、最大値を求める
for y, df_per_year in flights.groupby("year"):
flights.loc[flights.year == y, "min"] = np.percentile(df_per_year.passengers, 0)
flights.loc[flights.year == y, "25%"] = np.percentile(df_per_year.passengers, 25)
flights.loc[flights.year == y, "75%"] = np.percentile(df_per_year.passengers, 75)
flights.loc[flights.year == y, "max"] = np.percentile(df_per_year.passengers, 100)
# 毎年1月のデータだけを抜き出す
flights_year = flights.groupby("year", as_index=False).head(1)
### 描画
# ローソク足チャートの描画に必要なモジュールのインポート
import matplotlib.finance as mpf
from matplotlib.dates import date2num, DateFormatter, YearLocator
import matplotlib.ticker as ticker
# 年で表記する
yformat = DateFormatter("%Y年")
# 1年単位で区切る
ylocator = YearLocator()
# ローソク足チャートの描画
fig = plt.figure(figsize=(12, 8))
ax = plt.subplot()
# 描画に必要なデータを揃える
# ローソク足チャートで日付を表示させるには、date2numでdate型をnumに変換する必要がある
ohlc = np.vstack((date2num(flights_year["year_month"]), flights_year[["25%", "max", "min", "75%"]].values.T)).T
# ローソク足チャートの描画
mpf.candlestick_ohlc(ax, ohlc, width=100, colorup='black')
# X軸の範囲の設定
datemin = date(1948, 7, 1)
datemax = date(1960, 7, 1)
ax.set_xlim(datemin, datemax)
# X軸の表記と区切りの設定
ax.xaxis.set_major_formatter(yformat)
ax.xaxis.set_major_locator(ylocator)
# タイトル等々の設定
ax.set_title("乗客数のローソク足チャートに25%, max, min, 75%点を割り当てたグラフ")
ax.set_xlabel("年")
ax.set_ylabel("乗客数")
fig.autofmt_xdate() #x軸のオートフォーマット
plt.show()
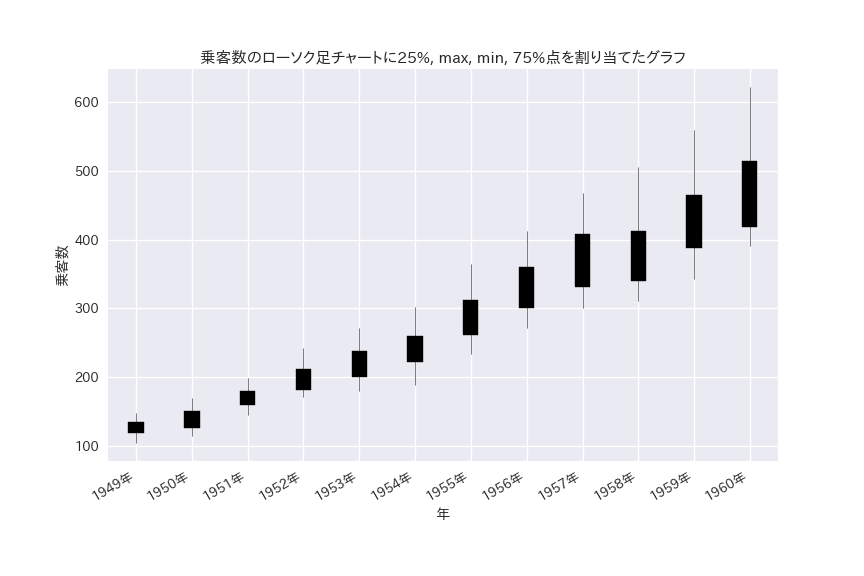
年毎の推移と分布がわかります。
ピーク時の乗客数は毎年伸びている一方で、25%-75%の分布は1958年に少し停滞しています。
使うべきではない可視化手法
データを理解しやすくするのが可視化の目的であり、誤解させてしまう可能性がある可視化手法は使うべきではありません。特に円グラフや3Dグラフには注意が必要です。
円グラフ
円グラフは内訳の構成比を円の弧・面積で表すグラフです。
線の長さに比べて、扇型の面積や弧の長さの大小を人間が正しく比較するのは困難です。
また、各要素が円状に並んでいるため大きさを比較しづらいです。
割合を表したいのなら棒グラフ、帯グラフ、積み上げ棒グラフを使いましょう。
少し極端な例ですが、irisの品種の構成比を円グラフと棒グラフで比較してみます。
まずirisの品種の構成比を若干偏らせます。
# irisを品種ごとに数え上げる
iris_counted = iris.groupby("species").size().reset_index().rename(columns={0: "freq"})
# データに偏りを持たせてみる
iris_counted.loc[0, "freq"] += 5
iris_counted

次に、円グラフと棒グラフで品種の構成比を描画します。
# デフォルトのカラーマップを選択
cmap = plt.get_cmap("tab10")
# 描画
fig = plt.figure(figsize=(17, 8))
# 円グラフ
ax1 = fig.add_subplot(121)
ax1.pie(iris_counted["freq"], labels=iris_counted["species"], startangle=100)
ax1.set_title("品種毎の出現割合")
# 棒グラフ
ax2 = fig.add_subplot(122)
ax2.bar(iris_counted["species"], iris_counted["freq"], color=[cmap(0), cmap(1), cmap(2)])
ax2.set_title("品種毎の出現割合")
ax2.set_xlabel("品種")
ax2.set_ylabel("出現数")
plt.show()
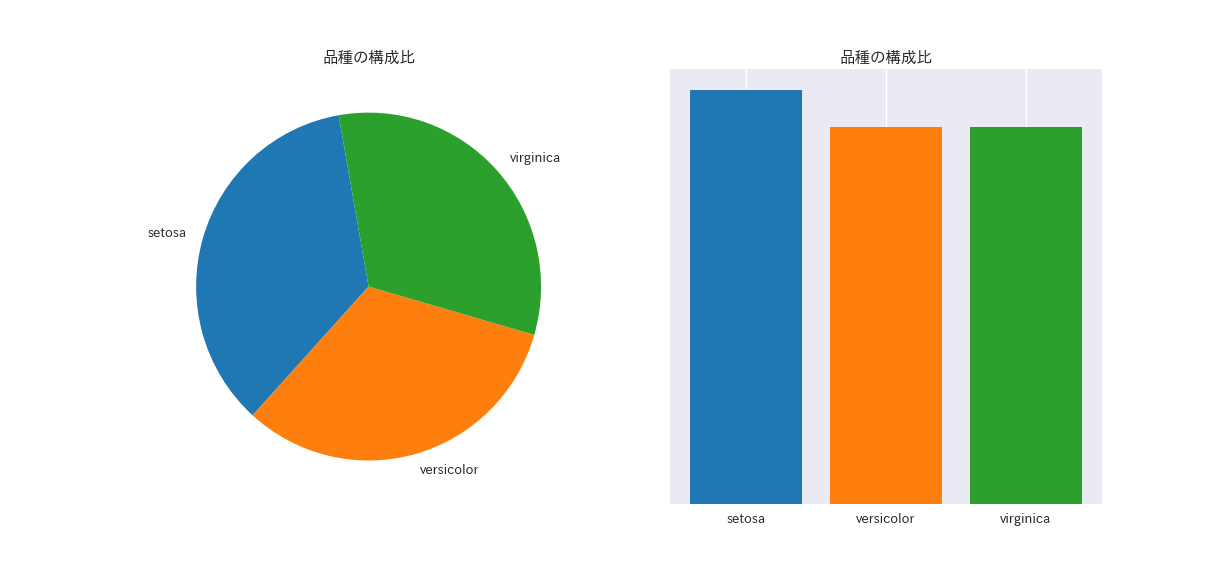
棒グラフではsetosaの出現割合が容易に把握できますが、円グラフでは把握しづらくなっています。
3Dグラフ
3Dグラフは見た目のインパクトが大きいのでよく使われます。
しかし、手前のオブジェクトで奥のオブジェクトが隠れてしまったり、角度によって受ける印象が変わってしまいます。
棒グラフを書いたときと同じように、3D棒グラフでirisの品種毎にがく片の長さの比を図示してみます。
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
data = iris.groupby(by=["species"], as_index=False)[["species", "sepal_length"]].mean()
x = [0, 1, 2]
y = [0]
bottom = np.zeros(3)
width = depth = 1
top = data["sepal_length"]
# setup the figure and axes
fig = plt.figure(figsize=(17, 8))
ax1 = fig.add_subplot(121, projection="3d")
ax1.bar3d(x, y, bottom, width, depth, top, shade=True)
ax1.set_xticks([])
ax1.set_yticks([])
ax1.set_xlabel("setosa versicolor virginica")
ax1.set_title("アヤメ 品種毎のがく片の長さ")
ax1.set_zlabel("がく片の長さ")
ax2 = fig.add_subplot(122)
ax2.bar(x=data.species, height=data.sepal_length)
ax2.set_title("アヤメ 品種毎のがく片の長さ")
ax2.set_xlabel("品種")
ax2.set_ylabel("がく片の長さ")
plt.show()
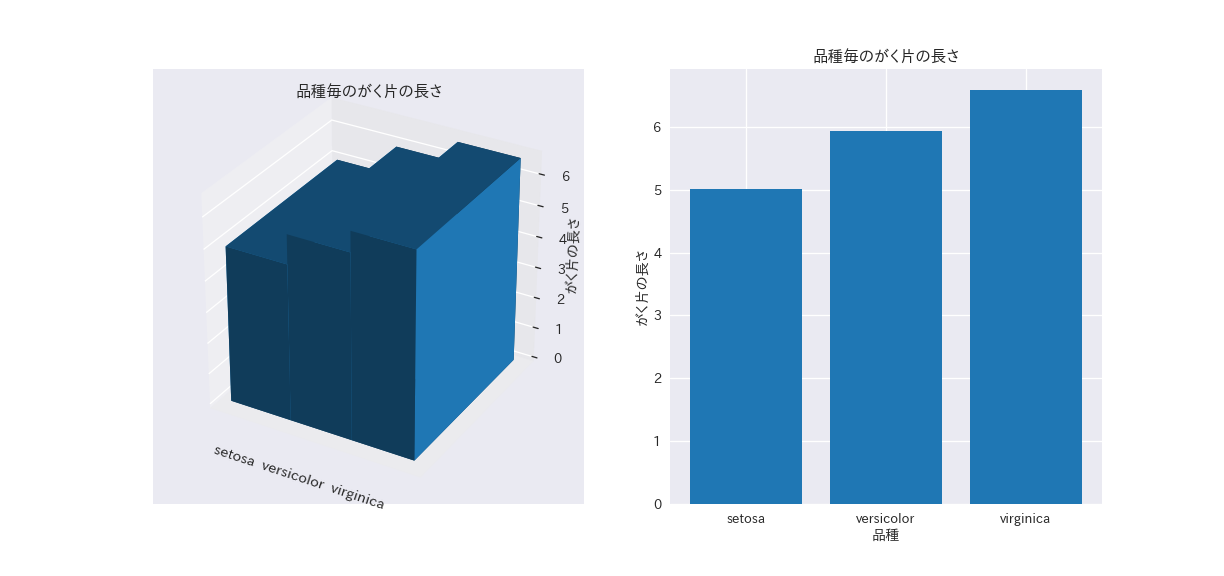
3D棒グラフと2D棒グラフを比べると、3Dの方がvirginicaのがく片の長さが長く見えます。
目盛りのないグラフ
目盛りの上限・下限・幅などを変えると印象が変わってしまいます。
目盛りを書くべきグラフでは必ず軸に目盛りを書きましょう。
irisの品種毎のがく片の長さを比べてみます。
data = iris.groupby(by=["species"], as_index=False)[["species", "sepal_length"]].mean()
fig = plt.figure(figsize=(17, 17))
ax1 = fig.add_subplot(221)
ax1.bar(x=data.species, height=data.sepal_length)
ax1.set_title("品種毎のがく片の長さ(下限調整)")
ax1.set_xlabel("品種")
ax1.set_ylabel("がく片の長さ")
ax1.set_ylim(4, 7)
ax2 = fig.add_subplot(222)
ax2.bar(x=data.species, height=data.sepal_length)
ax2.set_title("品種毎のがく片の長さ")
ax2.set_xlabel("品種")
ax2.set_ylabel("がく片の長さ")
ax3 = fig.add_subplot(223)
ax3.bar(x=data.species, height=data.sepal_length)
ax3.set_title("品種毎のがく片の長さ(下限調整・目盛り無し)")
ax3.set_xlabel("品種")
ax3.set_ylabel("がく片の長さ")
ax3.set_ylim(4, 7)
ax3.set_yticks([])
ax4 = fig.add_subplot(224)
ax4.bar(x=data.species, height=data.sepal_length)
ax4.set_title("品種毎のがく片の長さ(下限調整・目盛り無し)")
ax4.set_xlabel("品種")
ax4.set_ylabel("がく片の長さ")
ax4.set_yticks([])
plt.show()
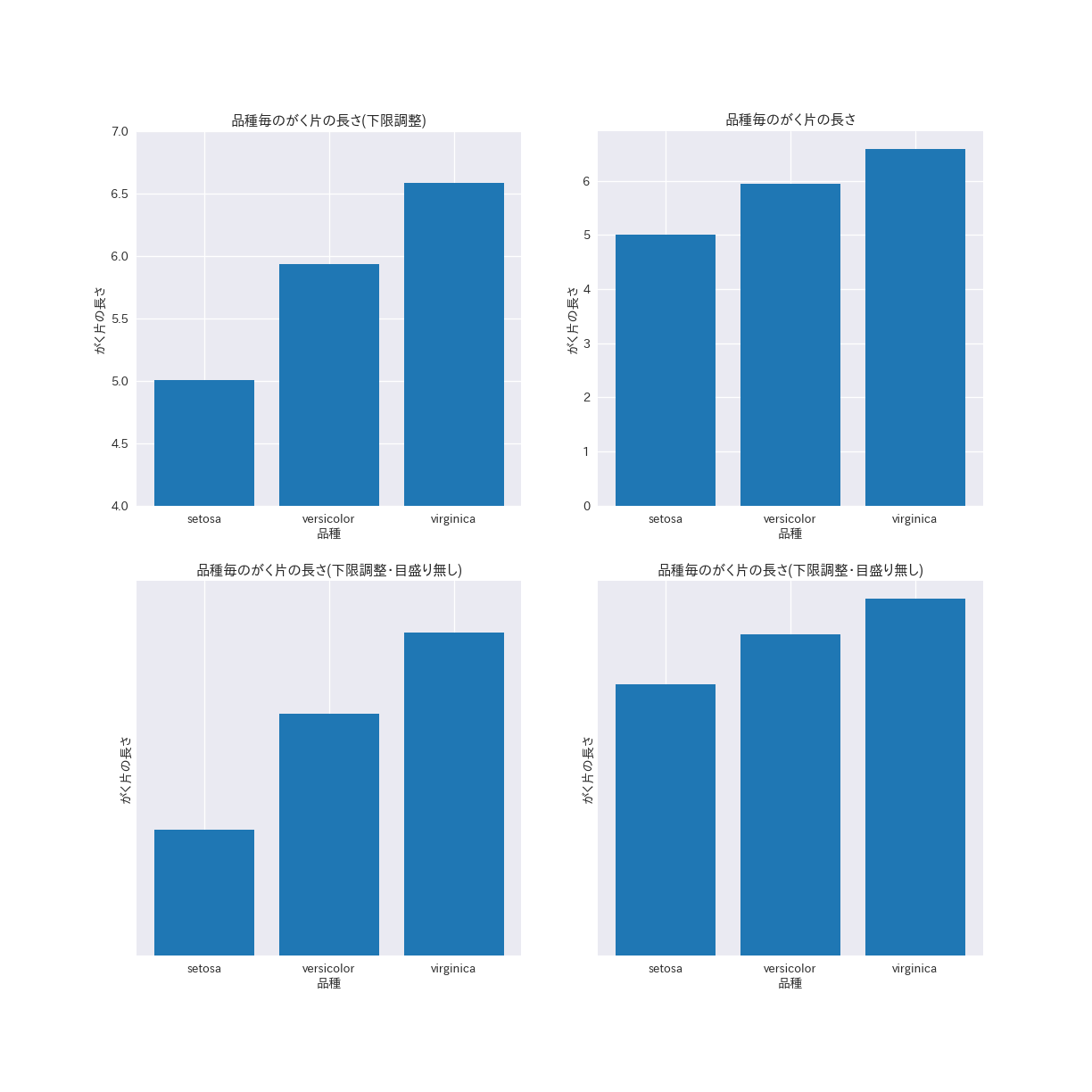
これらの図は全て同じデータを表していますが、上の段の2図を比べると、virginicaがsetosaの2倍以上長く見えます。
それでも目盛りを見れば辛うじて左右の図が同じであることが判別できますが、下の段の2図は目盛りが無いため判別が不可能です。
まとめ
- 探索的データ解析とはデータから何らかの仮説を得るためのアプローチ
- 目的やデータの性質に合わせて可視化手法を使い分ける
- データを理解しやすくするという目的においては、円グラフや3Dグラフ・目盛り無しグラフは避けた方がよい
終わりに
様々な目的やデータの性質に合わせて可視化手法を整理しましたが、必ずしもこの方法に従って可視化しなければいけないわけではありません。
重要なのは、特定の可視化手法を用いること自体を目的にせず、仮説を立てるという目的のために可視化手法を柔軟に使い分けるということです。
参考文献
あんちべ「データ解析の実務プロセス入門」
池内 孝啓, 片柳 薫子, 岩尾 エマ はるか, @driller「PythonユーザのためのJupyter[実践]入門」