バーチャルのじゃロリ狐娘Youtuberおじさんって誰?
バーチャルYoutuberの火付け役となった、けもみみが大好きなおじさんです。

そもそもバーチャルYoutuberって何?
3Dの CGキャラクターに生身の人間の声を当てて配信する新しい形のYoutuber、それがバーチャルYoutuberです。(言葉の定義自体がまだ定まってませんが、こんな感じであってると思います。)
2016年12月にキズナアイというキャラクターが誕生して以来、ミライアカリ、電脳YoutuberシロなどのバーチャルYoutuberが誕生しましたが、最近まで注目されることはありませんでした。しかし2017年12月、あるブログがバズって以来、バーチャルYoutuber界隈は日に日に盛り上がりをみせています。
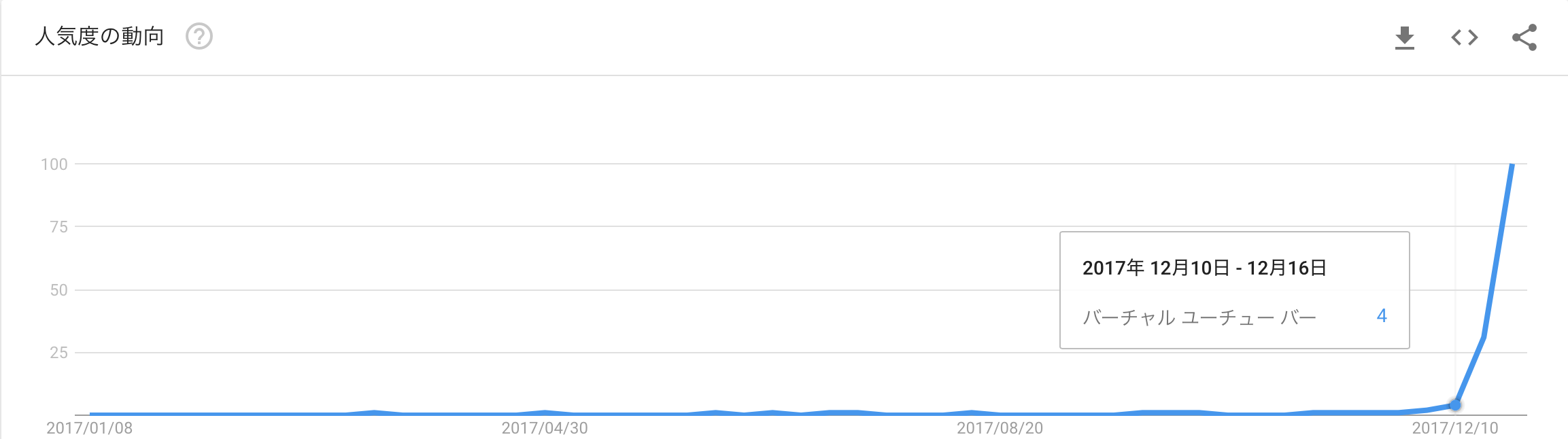
そのブログで紹介されていたバーチャルYoutuberが、バーチャルのじゃロリ狐娘Youtuberおじさん(ねこます)です。2017年11月にYoutubeアカウントを開設して以来、2018年1月3日時点でチャンネル登録者数14.5万人という驚異のスピードで支持を伸ばしています。
バーチャルのじゃロリ狐娘Youtuberってどんな人
なぜオッサンはかわいいに憧れるのか 「バーチャルのじゃロリ狐娘YouTuberおじさん」独占インタビュー(前編)やキミは「バーチャルのじゃロリ狐娘Youtuberおじさん」を知っているか!?を読んでもらえればわかるのですが、ザクっと説明すると
- 外見は可愛い狐娘
- 中身は(元)コンビニバイトのおっさん
- 声もおっさん
という独自のスタイルが支持を集めてます。
Youtube:バーチャルのじゃロリ狐娘Youtuberおじさん(ねこます)
Twitter:@nek0masu
見た事ない人は、今すぐバーチャル狐娘Youtuberおじさん。はじまります。【001】を見ましょう。新しい世界が広がっています。タイトルに「のじゃロリ」が入ってないのは気にしないで下さい。
本題
ダイマが色々と長くなってしまいましたが、そろそろ本題に入りましょう。
今回は、そんな不思議なおじさんバーチャルYoutuberに惹かれる人は一体どのような人たちなのか気になったので、バーチャルのじゃロリ狐娘Youtuberおじさんのフォロワーを集めて、自己紹介文の出現単語をWordCloudで可視化しようと思います。PCはmacを使います。
必要なもの
| 項目 | 内容、URLなど |
|---|---|
| Twitter垢 | アカウントidとパスワード |
| Python | anacondaを使うと便利 |
| selenium | Twitterをクローリングする。PythonでSeleniumを使ってスクレイピング (基礎)などを参照 |
| beautifulsoup | htmlから自己紹介文を抽出する。PythonとBeautiful Soupでスクレイピングなどを参照 |
| MeCab | 自己紹介文を単語に分解する。Python3からMeCabを使うなどを参照 |
| word_cloud | 単語の出現頻度を可視化する。Word Cloudで文章の単語出現頻度を可視化する。[Python]などを参照 |
| tqdm | forループの進捗を表示する。【Python】tqdmを使ったプログレスバーによる進捗表示などを参照 |
seleniumでゴリ押しするよりTwitterAPIを使った方がスマートなのですが、設定が少々面倒なのでまた後日。
URLを飛べば先人達がインストール方法や使い方を丁寧に書いてくださってるので、適宜参照してください。
1.各種ライブラリのインストール
Pythonは省略
1-1.selenium
selenium本体のインストール
pip install selenium
あと、公式サイトのdownloadページからchromedriverをDLして、任意の場所に置いておいてください。
1-2.beautifulsoupのインストール
pip install beautifulsoup4
1-3.MeCab
MeCab本体(+neologdという追加辞書)のインストール
brew install mecab mecab-ipadic git curl xz
git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git
cd mecab-ipadic-neologd
./bin/install-mecab-ipadic-neologd -n
あと、python3でMeCabを使うためのツールをインストールします
pip install mecab-python3
細かい設定は公式ページを参照してください。
分かち書きツールとしてはMeCab以外にもJUMAN++というRNNを使った新しい形態素解析器があるのですが、今回分析するTwitterの自己紹介文は固有単語が多いので、新語をどんどん取り込んで更新されているneologdが使えるMeCabを使います。
やはりjumanppよりmecab+neologの方が強い
— hanon (@h_dtpn) 2017年12月29日
左:jumannpp 右:mecab+neolog pic.twitter.com/3F8HAN359d
今調べていたらneologdをjuman++で使う方法があるらしいので、そのうち使ってみたいですね。
neologd辞書をjuman/juman++で使えるようにするスクリプト作った
1-4.word_cloud
pip install word cloud
1-5.tqdm
これは無くてもいいのですが、クローリングは結構時間かかるのであると便利。
pip install tqdm
2.WordCloudの作成
以下の順番で進めていきます。
- ライブラリのインポート
- Twitterへログイン
- フォロワーのhtmlを抜き取る
- htmlから自己紹介文に登場する単語のリストを抽出
- WordCloudを描画
# ライブラリのインポート
import matplotlib.pyplot as plt
import MeCab
from selenium import webdriver
from bs4 import BeautifulSoup
from wordcloud import WordCloud
from tqdm import tqdm
%matplotlib inline
%config InlineBackend.figure_formats = {'png', 'retina'} #出力画像の解像度を上げる
# seleniumのchromedriverでTwitterにログイン
def login_twitter(twitter_id, password):
# インスタンスの作成
# chromedriverのパスを指定、PC環境毎に変わるので注意
driver_path = '../../chromedriver'
driver = webdriver.Chrome(driver_path)
# Twitter接続
driver.get('https://twitter.com')
time.sleep(10)
# ログインページに移動
try:
driver.find_element_by_xpath(
'//*[@id="doc"]/div/div[1]/div[1]/div[2]/div/a').click()
except:
driver.find_element_by_xpath(
'//*[@id="doc"]/div[1]/div/div[1]/div[2]/a[3]').click()
time.sleep(10)
# ログイン
try:
driver.find_element_by_xpath(
'//*[@id="page-container"]/div/div[1]/form/fieldset/div[1]/input').send_keys(twitter_id)
driver.find_element_by_xpath(
'//*[@id="page-container"]/div/div[1]/form/fieldset/div[2]/input').send_keys(password)
driver.find_element_by_xpath(
'//*[@id="page-container"]/div/div[1]/form/div[2]/button').click()
except:
driver.find_element_by_xpath(
'//*[@id="login-dialog-dialog"]/div[2]/div[2]/div[2]/form/div[1]/input').send_keys(twitter_id)
driver.find_element_by_xpath(
'//*[@id="login-dialog-dialog"]/div[2]/div[2]/div[2]/form/div[2]/input').send_keys(password)
driver.find_element_by_xpath(
'//*[@id="login-dialog-dialog"]/div[2]/div[2]/div[2]/form/input[1]').click()
time.sleep(10)
return driver
htmlの構造が変わったら動かなくなるので注意です。
将来的にはTwitterAPI使った方が絶対良いです。
# フォロワーのhtmlを抜き取る
def get_follower_html(driver, twitter_id, scroll=100):
# ユーザー検索
driver.find_element_by_id('search-query').send_keys(twitter_id)
time.sleep(10)
# 検索ボタンをクリック
driver.find_element_by_xpath(
'//*[@id="global-nav-search"]/span/button').click()
time.sleep(10)
# 検索条件:ユーザータブをクリック
driver.find_element_by_xpath(
'//*[@id="page-container"]/div[1]/div[2]/div/ul/li[3]/a').click()
time.sleep(10)
# ユーザータブの中から該当するユーザーをクリック
# リンク候補を持って来て(trend+user)、textが検索userであるリンクを選択してクリックする
links = driver.find_elements_by_class_name("u-linkComplex-target")
for item in links:
if item.text == twitter_id[1:]:
item.click()
break
else:
continue
time.sleep(10)
# ユーザーページからフォロワータブをクリック
driver.find_element_by_xpath(
'//*[@id="page-container"]/div[1]/div/div[2]/div/div/div[2]/div/div/ul/li[3]/a/span[3]').click()
time.sleep(10)
# 任意の長さまでスクロール
for i in tqdm(range(scroll)):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(8)
# htmlを抜き出す
html = driver.page_source
# driverを閉じる
driver.close()
return html
引数のscrollは画面をスクロールする回数です。
たくさんスクロールして、画面上に沢山フォロワーを表示させた状態でhtmlを抜きます。
# htmlから自己紹介文に登場する単語のリストを抽出
def get_bio_words(html):
# BeautifulSoupインスタンスの作成
soup = BeautifulSoup(html, 'lxml')
#bioが含まれている場所を抜く
bios = soup.find_all('p', class_ = 'ProfileCard-bio u-dir')
# bioの文字列のみを抜き出す
for bio in range(len(bios)):
bios[bio] = bios[bio].string
# bioを繋げて1つのtextにする
# joinはintを繋げないので、strに変換してから繋ぐ
bios_list = list(bios)
# 抽出したアカウント数を表示させる
print('使用するアカウント数:{}'.format(len(bios_list)))
for index, item in enumerate(bios):
bios_list[index] = str(item)
bios_text = ' '.join(bios_list)
# MeCabで分かち書き
# 辞書はneologdを使用
# neologdのパスを指定、PC環境で変わる場合があるので注意
mecab = MeCab.Tagger('-d /usr/local/lib/mecab/dic/mecab-ipadic-neologd')
mecab.parse('') # MeCab内部のdecodeエラーを回避する行、原因はよくわからないけど1ブロック目に空白を入れると良いらしい
# mecab.perseToNode()はstrを渡す、unicode文字(u"str"とか"str".encode('utf-8')とか)は渡せない
node = mecab.parseToNode(bios_text)
# wordを格納するlistを作る
word_list = []
while node:
# 単語と品詞を取得
word = node.surface
word_type = node.feature.split(',')[0]
# 名詞なら格納
# 名詞が含まれているlistに名詞以外の品詞を追加すればそれも取れる
if word_type in ['名詞']:
word_list.append(word)
# 次の単語に進める
node = node.next
if node is None:
break
return word_list
decodeエラーについては気になる方は以下などを参照してください。
【MeCab】Python3で解析時にbuiltins.UnicodeDecodeError【Flask】
# WordCloudを描画
def create_wordcloud(text, output_pass=None):
# PC環境に合わせて任意のフォントのパスを指定する
fpath = '/Users/hogehoge/Library/Fonts/ipagp.ttf'
# ストップワード(wordcloudに描画しない単語)の指定
stop_words = ['/', 'None']
# ワードクラウドの描画
wordcloud = WordCloud(background_color="white", font_path=fpath,
width=900, height=500, stopwords=set(stop_words)).generate(text)
# 描画と出力
plt.figure(figsize=(15,12))
plt.imshow(wordcloud)
plt.axis("off")
# もし出力パスを指定した場合は、そのパスにイラストを保存する
if output != None:
fname = str(output_pass)
plt.savefig(fname, dpi=300, format='png')
これで必要な関数が定義出来たので、バーチャルのじゃロリ狐娘Youtuberおじさんのフォロワーの自己紹介文に出てくる名詞の出現頻度をこれらの関数を使って描画してみましょう。
driver = login_twitter('@my_account', 'my_account_password')
html = get_follower_html(driver, '@nek0masu', 100)
word_list = get_bio_words(html)
create_wordcloud(" ".join(word_list), '../output/nekomasu.png')

上手く描画出来ました!属性情報は「東方」や「FGO」、「艦これ」などサブカル要素の強いアニメやゲームの名前が多いですね。年齢情報は「社会人」や「成年済み」が多そうです。性別は明示されていないものの、男性が好みそうな趣味が並んでいます。バーチャルYoutuberというジャンルがまだ定着していないせいか「Youtuber」という単語は小さいです。
試しにバーチャルじゃないYoutuberと比較してみます。
driver = login_twitter('@my_account', 'my_account_password')
html = get_follower_html(driver, '@hikakin', 100)
word_list = get_bio_words(html)
create_wordcloud(" ".join(word_list), '../output/hikakin.png')

「Youtuber」が前に出て来ましたね。属性情報は部活やディズニーなど、アクティブさが伺えます。年齢情報は「高校」、「〜年」から学生が多そうです。眩しいですね。性別は「女子」がそこそこ居そうです。「Youtuber」、「Youtube」という単語がかなり大きいことから、Youtuberはすっかり市民権を得ていることがわかります。
まとめ
- バーチャルのじゃロリ狐娘Youtuberおじさんにハマる人は、主に社会人のコアな男性オタク層
- バーチャルyoutuberというジャンルはまだ定着していない
注意点・改善点・展望
- クローリング・スクレイピング
- TwitterAPIを使った方が良い
- 何度も実行するとTwitter垢がBANされるので注意(クローリング用の垢を作った方が安全)
- 何度も実行するとグローバルIPもBANされるので注意(防ぎようがないので、クローリングは程々に)
- BANされても何も通知来ないので気をつけてください
- 単語の分解(形態素解析)
- 分類器自体の性能はJUMAN++の方が良さげなので、JUMAN++とneologdの組み合わせを試したい
- 名詞以外は落としたので、他の品詞もTwitter属性として使えそうなものは採用した方が良いかも
- WordCloud
- 文字の色や形状、描画全体の形を変えられるらしいのでより直感的な描写を目指すのもあり
- 微妙に解像度が上がらないので何とかしたい
終わりに
今回やりたかった「Twitterの自己紹介文から属性推定」を 達成するために一番手軽な方法としてWordCloudを試しましたが、他のよい方法があれば誰か教えてくださると嬉しいです。
バーチャルYoutuberは間違いなく2018年のトレンドになるので、今後も注視していこうと思います。