はじめに
ドキュメントデータベースかリレーショナルデータベース、どちらを選ぶか。
この選択で、アプリケーションのパフォーマンス、コスト、コードの可読性など幅広い影響が出るため、慎重な判断が必要です。この記事では、自分が思う「考慮すべきポイント」を解説したいと思います。
考慮すべきポイント
1. どのデータモデルがアプリケーションコードに最適か
スキーマ制約を課さずに、データレコードをドキュメント(つまりJSONオブジェクト)として保存すべきか?それともスキーマを正規化してデータをいくつかのテーブルに分けるべきか?
このような判断をするために、開発しているアプリケーションのモデルの関係性(例: UserとTaskの関係が1:N)と、一度に読み込むデータの種類を見た方がいいです。
ドキュメントDBがおすすめの時
アプリケーションのデータは、以下のような木構造で表現できますか?普段そのデータを一度に読み込んでいますか?
両方の答えが「Yes」なら、そのデータを単一の「ドキュメント」としてまとめてドキュメントDBに格納する方が、それを利用するアプリケーションコードがシンプルになります。
木構造で表現できて、普段一度に読み込むデータは、ドキュメントDBとの相性がいい
{
"id": "bbc16639-c082-47e8-b9c0-2d59579c7336",
"first_name": "taro",
"last_name": "momo",
"lastLoggedIn": "2022-07-31T06:03:37+00:00",
"email": "taro@example.com",
"skills": [
{"name": "python"},
{"name": "golang"},
{"name": "英語"}
],
"work_history": [
{
"company": "ENECHANGE",
"position": "Software Developer",
"start_date": "2018-03-26",
"end_date": null
},
{
"company": "Company Inc.",
"position": "Software Developer",
"start_date": "2016-01-06",
"end_date": "2018-03-20"
}
]
}
RDBがおすすめの時
アプリケーションのデータレコードは、以下のような多対多の関係になっていますか?
もしそうなら、RDB(またはグラフDB)の方がアプリケーションに適している可能性が高いです。なぜかというと、ドキュメントDBでは、JOIN文の概念がほとんどなく、アプリケーション側で結合処理を行う必要があるからです。JOINが多く見込まれるようなアプリケーションにドキュメントDBを(主要のデータベースとして)導入すると、結合処理でコードが複雑になってしまいます。
一方、RDBでは、データベース内で結合処理を行ってくれます。JOIN文が多いからと言って、アプリケーションコードの可読性が悪くなることはないはずです。
2. スキーマの柔軟性は必要?
一般的なドキュメントDBは、レコードに対してスキーマ制約やデータ型制約を課しません。任意の構造のドキュメントを自由に追加できます。一方、RDBでは、レコードを INSERT すると同時に、データ型や他レコードとの関係が細かくチェックされます。
ドキュメントDBがおすすめの時
ドキュメントDBは、 schema-on-read と呼ばれます。なぜなら、データをデータベースから取得して初めて「スキーマ」が生まれるからです。スキーマが動的(か、そもそも不明)な場合は、ドキュメントDBの柔軟性が役に立ちます。
「スキーマが不明なデータ」とは、どんなときに出会うものでしょうか?
例えば、家庭用スマートデバイス(プラグ、サーモスタット、エアコンなど)のステータスログを保存するIoTアプリケーションを作っているとします。常にたくさんのIoTデバイスに対してステータス確認リクエストを飛ばし続けるようなイメージです。
スマートプラグは、ONかOFFでステータス情報がシンプルですが、サーモスタットには温度や湿度が付いているので、持っている情報が違います。2016年に製造されたエアコンには温度・風向き・風量などの設定情報しかなかったものの、最近のエアコンには消費電力量やCO2排出量センサーが付いていたりします。メーカーによってAPIの仕様やスキーマももちろん違いますね。そして、これからどんな新しいスマートデバイスが登場するのか、誰も分かっていません。
こんか状況で、スキーマの「正規化」は難しいですよね?
//
// 各レコードが同じようなものだけど、スキーマが違う
//
[
// スマートプラグ
{
"id": "ac63decb-87c8-4f28-a5a0-64a1afd71ed9",
"type": "smart_device",
"name": "smart_plug",
"power_status": true,
"timestamp": "2022-07-31T12:34:56+00:00"
},
// サーモスタット
{
"id": "d8e7e28a-49d6-4a63-9c13-ca5e2cc2b70d"
"type": "smart_device",
"name": "thermostat",
"temperature_actual": 24.2,
"temperature_setting": 24.5,
"humidity": 0.45,
"timestamp": "2022-07-31T12:34:56+00:00"
},
// エアコン(2016年製)
{
"id": "7810f3ef-cc90-45ab-8954-553066b84b02",
"type": "appliance",
"name": "ac",
"device_id": "d8e7e28a-49d6-4a63-9c13-ca5e2cc2b70d",
"model_name": "ナパソニック2016",
"timestamp": "2022-07-31T12:34:56+00:00"
},
// エアコン(2022年製) << 使用電力量や室温が分かる最新モデル
{
"id": "5580355b-6d14-46a6-abb5-c4ba4f10d0d7",
"type": "appliance",
"name": "ac",
"device_id": "d8e7e28a-49d6-4a63-9c13-ca5e2cc2b70d",
"power_usage_kw": 1.1,
"temperature": 24.3,
"model_name": "ナパソニック2022",
"timestamp": "2022-07-31T12:34:56+00:00"
}
]
ドキュメントDBを使うと、1つのコレクション(つまりテーブル)に上記レコードをすべて格納できます。新型のスマートデバイスや家電製品が登場した際の CREATE TABLE クエリーも不要なので、スキーマを維持するためのメンテナンス作業が発生しません。
RDBを使う場合は、スキーマの「正規化」を追求するために、スマートデバイスや家電製品ごとのテーブルを作ろうとするかもしれません。しかし、こうすると多くのテーブルができてしまい、新しいデバイスの追加によるスキーマ変更でメンテナンスが必要となり、負担が大きくなります。つまり、正規化する方がデメリットが大きい場合があるわけです。
ドキュメントDBを使うときは、データ型をチェックする責任がアプリケーションにあるため、PythonやRubyのようなインタプリタ型言語と似ています。
RDBがおすすめの時
RDBは、レコードを INSERT すると同時に、データ型、一意性、外部キーによるレコード間の関係など諸々チェックするので、schema-on-write と呼ばれます。もし、1. データの構造を事前に分かっていて、2. すべてのレコードが同じ構造を持つことが予想されるなら、RDBがもたらすデータ完全性や「スキーマのドキュメント化効果」が役に立つと思います。
RDBを使うときは、データ型や外部キーのチェックがDBの責任なので、JavaやGoのようなコンパイル型言語と似ています。
3. スケーラビリティの要件
世の中のアプリケーションには、数百万人のユーザーの同時アクセスをサポートし、1万件以上の同時書き込みを行い、レコードの取得速度に影響を与えることなくテラバイト単位のデータを保存しなければいけないようなものがあります。
一方で、10人のユーザーをサポートし、読み書きの速度は「ストレスを与えない程度」で問題ありませんが、人の命に関わるため、データが絶対に矛盾した状態にならないようにしなければいけないアプリケーションもあります。
データベースを選定する際に、以下のようなスケーラビリティ要件を考慮するといいです。
- 予想される最大同時コネクション数
- データの完全性と可用性のどちらがより重要か
- レコードの取得速度は最重要課題か
ドキュメントDBがおすすめの時
10,000以上のホストから同時に接続する必要はありますか?データがどんなに大きくなっても、レコードの取得時間の SLA は死守する必要はありますか?答えが「Yes」なら、ドキュメントDBの方がニーズに合うかもしれません。
ドキュメントデータベースは一般的に スケールアウト (Horizontal Scaling) できるように構築されています。つまり、DBホスト数を追加することで、パフォーマンスと可用性を高めることができます。DynamoDB、Firestore、MongoDB AtlasのようなマネージドドキュメントDBは、需要に合わせてスケーリングしてくれます。
ドキュメントDBの使い道で例に挙げやすいパターンを言うと、多くのLambda関数から一度にデータを書き込むという点です。バッチ処理や分散カウンターを作るのに、Lambda x ドキュメントDBの組み合わせが便利です。
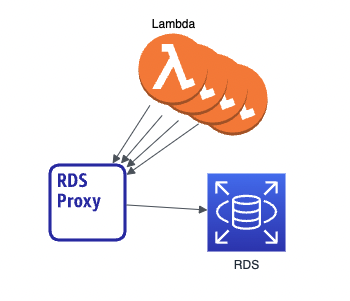
1,000個のLambda関数からRDBにデータを書き込もうと思ったら、最低限 PgBouncer や RDS proxy のような「コネクションプーラー」と呼ばれる大量の接続を処理するミドルウェアを使う必要があります。しかし、お金がかかりますし、メンテナンス負担も増えます。
![]()
![]()
![]()
一方、DynamoDB や Firestore のようなマネージドドキュメントDBでは、設定をいじる必要もなく、同時に数千以上の書き込みに対応してくれます。例えば、Firestore では、同時コネクション数は100万まで、書き込み数は1秒あたり1万回まで可能です。将来的にはこの制限を撤廃する予定もあるそうです。
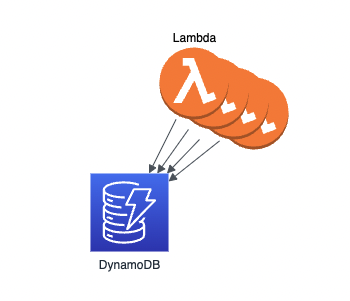
そして冒頭でお伝えした通り、ドキュメントDBはJOIN文が一般的にサポートされないため、自己完結したオブジェクトとしてデータを保存することが多いです。そのため、1レコードの取得で済む場合も多く、データの追加でシャード数がどんなに増えても、レコードの取得時間がさほど変わらないはずです。
RDBがおすすめの時
あなたのアプリケーションで、同時にデータベースに接続しているのは、ウェブサーバー3台くらいですか?お客さまの請求明細を計算するようなロジックを実装していますか?答えが「Yes」なら、RDBが適切かもしれません。
RDBは、何よりもデータの完全性を優先します。お金の計算や予約を管理するようなシステムは、マスターデータが間違っているとクレームにつながるかもしれませんよね。
データが矛盾した状態になるより、一時的にデータベースが落ちていた方がいいようなアプリケーションは、RDBを使いましょう。
このため、RDBは、一般的にドキュメントDBよりもスケーリングが難しく、コストが高くなりやすいです。RDBは、マシンの性能を上げることでスケーリングすることが一般的です。これを スケールアップ (Vertical Scaling) と言います。
データを複製(Replicate)することでスケールアウトすることも可能ですが、コピー先のデータの完全性を保つためのオーバーヘッドが発生します。また、一部のテーブルだけ別のDBサーバーに分ける「シャーディング」と呼ばれるスケールアウト方法もありますが、ネットワークを辿らないといけなくなるため、JOIN文のパフォーマンスが低下する可能性が高いです。
しかし、お金さえあれば 128 vCPUs x 4TBメモリーを持つ超高スペックなマシンをワンクリックで手に入れられる時代なので、RDBのスケーラビリティ問題を(ほとんどの場合)札束で解決できるのではないかと思います。
このベンチマークテストでは、12コアのマシンで1秒間に3万トランザクションに近いパフォーマンスをPostgreSQLで出せました。この PostgreSQL 12.1 のベンチマークテストでは、GCPの8コアのマシンで1秒間に4000トランザクションに近いパフォーマンスを得ることができました。さらにパラメータをOttertuneのようなツールでチューニングすれば、パフォーマンスをさらに伸ばすことができると思いいます。
4. 予算はどのくらい?
お金を払ってくれている顧客はいますか?趣味でアプリを開発していますか?
お金を極力かけたくない(全員ですよね…)のであれば、DynamoDB や Firestore のようなドキュメントDBを使った方が、RDS や Cloud SQL のようなマネージド RDB より安く運用できると思います。
RDSだと、東京リージョンで 2 vCPU x 4GB メモリのPostgreSQLインスタンスを1時間あたり$0.101($72/月)で借りなければいけません。趣味で作っているアプリケーションにはちょっと高いですよね?
一方、Firestoreでは、1日あたり5万回の読み込み、2万回の書き込み、2万回の削除を無料で提供し、ストレージ代は1GBあたり$0.115/月程度です。DynamoDBも、25GBまでのストレージが無料で、1,000,000回のオンデマンドリードと1,000,000回の書き込みを〜$10で提供してくれます。
本当にお金をかけたくない場合は、DynamoDB や Firestore のようなマネージドドキュメントDBをおすすめします。
終わりに
以上、ドキュメントDBとRDBの選定において、自分が思う「考慮すべきポイント」を紹介しました。お役に立てたら嬉しいです。
私と一緒に働きませんか?
ENECHANGEでは、大量な電力時系列データの分析を中心に、様々なアプリケーション企画/開発を行なっています。例えば、こんなことやっています…
- 電気の市場価格に応じて、一般家庭の家電を遠隔操作するようなサービス開発
- 大量の世帯/ビジネスの電気消費業のクラスター分析や需要予測
- Airflowを活用したデータパイプライン開発
- Elastic Container Serviceを1,000+ Fargateノードまでスケーリングする
等々。
学習意欲が高く、技術的なチャレンジがほしいPythonエンジニアを募集していますので、カジュアル面談でお気軽に話しましょう。