はじめに
ワークフローを作成、実行、監視するためのプラットフォーム「Airflow」が、近年人気を集めていて、多くの企業に利用されています。Airflow Summit 2022 のようなグローバルイベントも開催されるようになり、世界中から2000人以上のコントリビュータ(私もその1人)が貢献しているアツいプロジェクトです。
この記事で Airflow を使う意味と主要コンセプトを説明します。最後に、100行未満で実装できる本格的なデータパイプラインの実例をお見せしたいと思います。
Airflowとは
概要
Airflowは ワークフロー を作成、実行、監視するためのプラットフォームです。ここで言う「ワークフロー」は、依存関係にある複数の タスク を、下図のように繋いだ形で、パイプラインとして実行していくものと思ってください。
Airflowを使うと、より早く、よりロバストなワークフローが実装しやすくなります。この後に説明する「Operator」を使用すると、Eメール送信、VMの起動、コンテナの実行など、様々なタスクを少ないコードでサクッと実装できます。そして、ワークフローの途中でタスクがコケても、依存しないタスクを正常に稼働させ続けることができます。
Airflowは Python で実装されています。使う時も Python コードを書く必要がありますが、詳しくなくても、基本的な文法さえ分かればなんとかなります。タスクをコンテナ化すれば、Ruby や Go など、様々な言語で書いたスクリプトを一つのパイプラインとして繋ぎ合わせることができます。
Airflowのソースコードには、2000人以上が貢献しています。26,000以上のGitHub星を誇るOSSプロジェクトで、何百もの企業が使っています。一般公開されている範囲だけを見ても、このような企業が使っています:
- Airbnb
- Dropbox
- GitLab
- メルカリ
- PayPal
- 楽天
- SmartNews
- SMAP Energy << 我が社
- Tesla
- 等々...
また、Amazon Managed Workflows for Apache Airflow、Cloud Composer、Astronomer など、マネージドサービスとしても提供されています。
解決する問題
データパイプラインの開発において様々な課題があります。下記の表で、いくつかの課題について「スクラッチで実装した場合」と「Airflowを使って実装した場合」の対応方法を比較します。
| 課題 |
|
|
|---|---|---|
| タスクの依存関係を明確にする | ドキュメントやコメントで書く | 作ったワークフローが勝手にフローチャートとして表示される |
| エラーが起きた箇所を特定する | 追跡できるようなログを出力する | ダッシュボードから、エラー表示のタスクをクリックしてログやスタックトレースを確認する |
| タスクを同時に実行する | multiprocessing や asyncio で頑張る |
依存関係がないタスクは同時に実行される |
| スケールアウトする | 可能なところは、AWS Lambda などの外部プラットフォームや、複数のノードに処理を分散させることができるライブラリー(例:Dask)を使う | ワーカー数を増やす |
| 進捗状況を監視する | 進捗状況が追跡できるようなログを出力する | ダッシュボードから、ワークフローのタスクの表示色で目視確認する |
| 失敗しがちな処理を3回までリトライする | リトライ用のデコレーター関数を使う | タスクの「最大リトライ数」を設定する |
| スケジュールで実行する | CRON や AWS EventBridge などスケジューラーを導入する | CRON文法で、ワークフローのメタデータにスケジュールを設定する |
| 非エンジニアに実行してもらう | コマンドラインの操作方法を教える |
必要なワークフローだけ実行できるユーザーアカウントを発行する |
ざっくりどうやって使う?
Airflowの開発環境の構築に、公式 docker-compose.yml を強くおすすめします。構築が簡単で、環境の問題が発生する確率が低いからです。docker をインストールしていない方は、ここからダウンロードできます。
mkdir -p ./dags ./logs ./plugins # Linux のみ
echo -e "AIRFLOW_UID=$(id -u)" > .env # Linux のみ
wget https://airflow.apache.org/docs/apache-airflow/stable/docker-compose.yaml
docker compose up
環境が立ち上がったら、http://localhost:8080 にあるウェブサーバーにログインしましょう。ユーザー名とパスワードは両方とも airflow です。ログイン後に、以下のような一覧画面が表示されます。
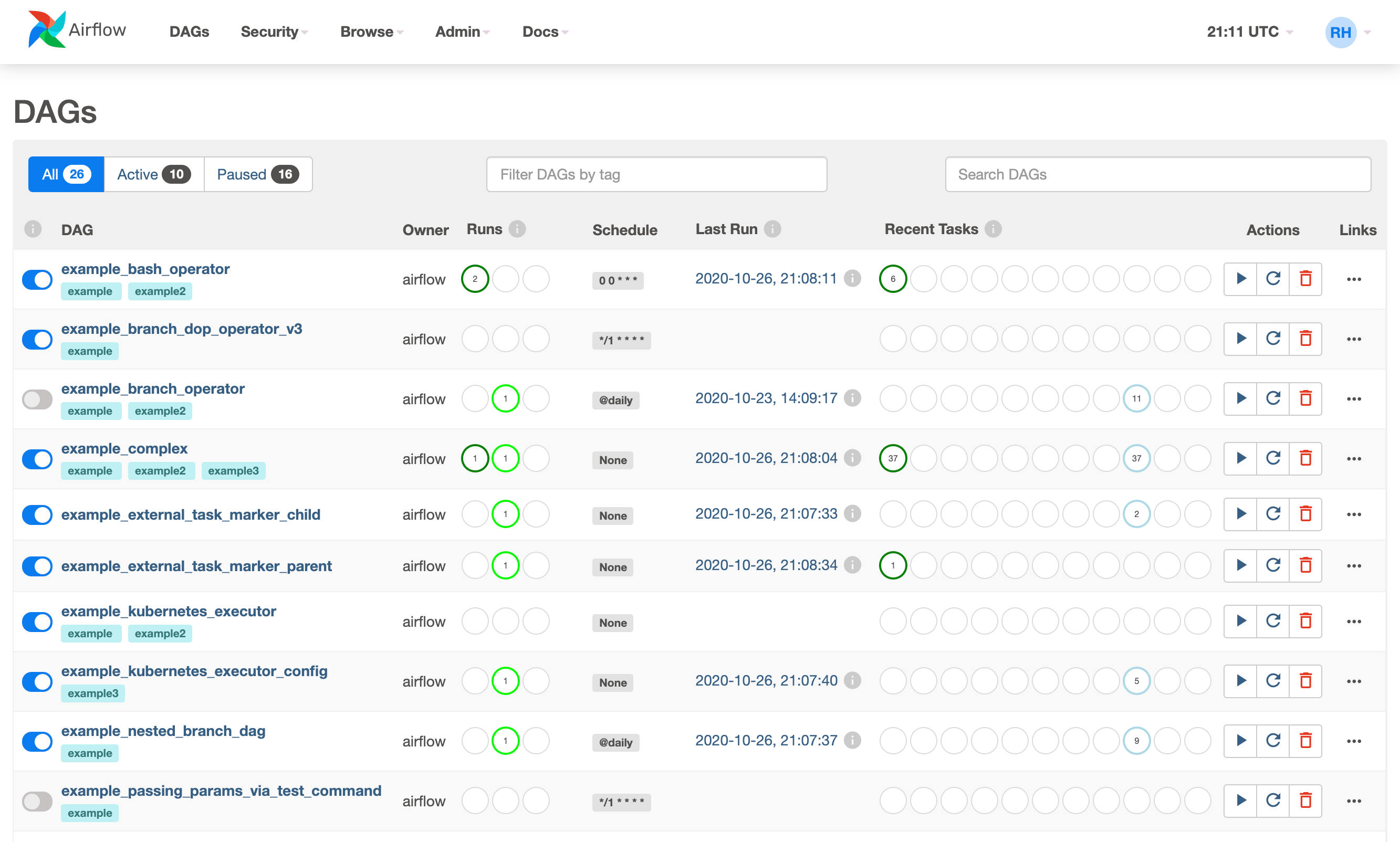
この画面には、DAG と呼ばれるワークフローが一覧で表示されます。それぞれのワークフローの名前、有効状態、実行回数、スケジュール、最後の実行された時刻など確認できます。左側のDAG名(例:example_bash_operator)をクリックするとグラフビュー(Graph View)に遷移します。
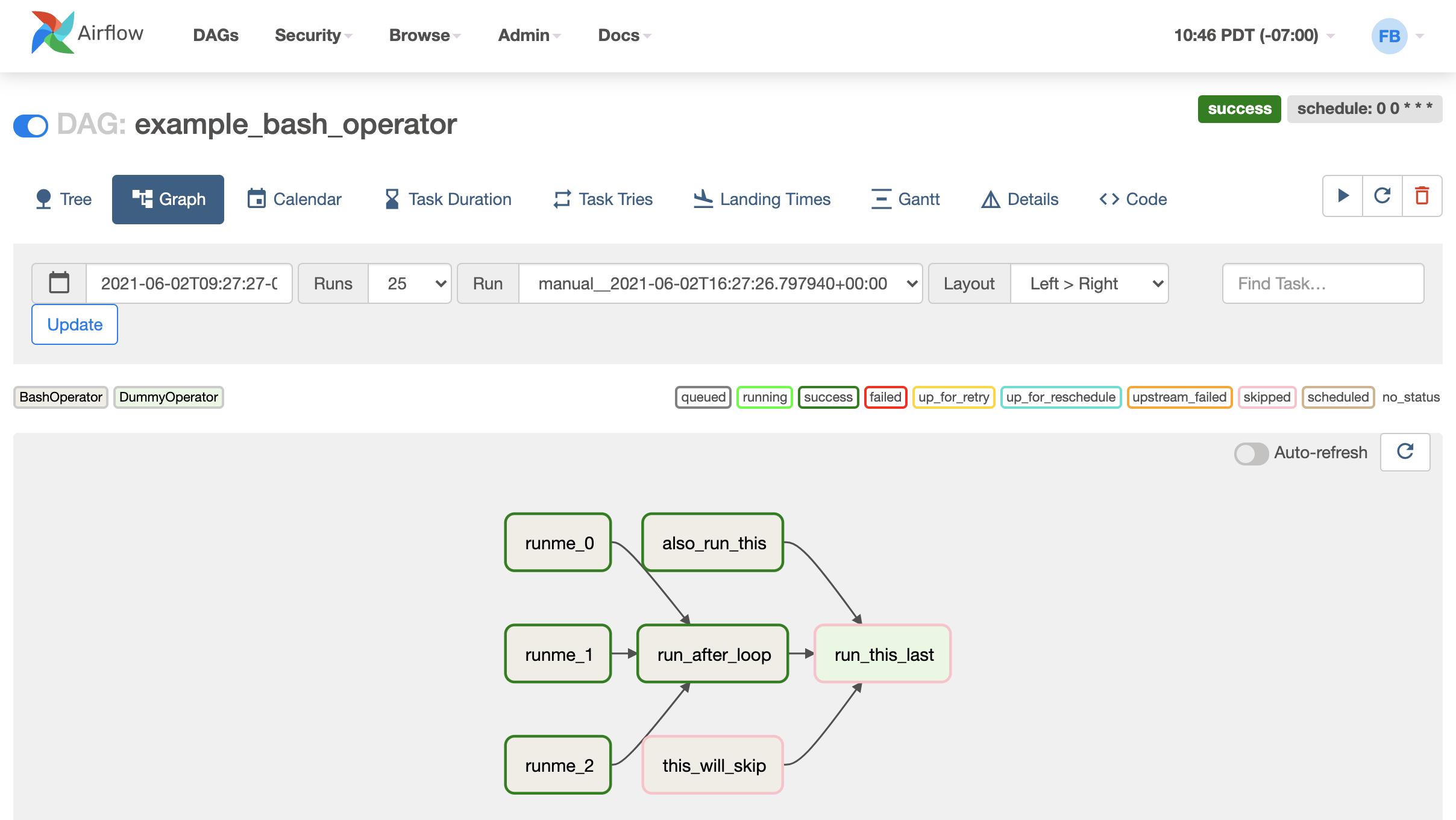
Graph Viewには、タスクの依存関係がフローチャートのように表示されます。それぞれのタスクの実行ステータスが色で見分けできるようになっています(例:緑=成功、赤=失敗)
右上の矢印アイコンを押すと、閲覧中のワークフローを実行するための吹き出しが表示されます。「Trigger DAG w/config」でパラメータを指定して実行することもできます。
起動中のコンテナ、作成された DB ボリュームとコンテナイメージを完全に削除するために、以下のコマンドを実行してください。
docker compose down --volumes --rmi all
コンセプト
アーキテクチャー
Airflowは、以下のコンポーネントで構成されています。
| コンポーネント | 役割 |
|---|---|
| スケジューラー | ワークフローとタスクの状態を監視し、依存関係を考慮してタスクの実行タイミングを決める |
| ワーカー | スケジューラーから言われたタスクを実行する |
| ウェブサーバー | ワークフロー/タスクの管理、実行、デバッグをしやすくする UI |
| メタデータ・データベース | スケジューラー、ワーカー、ウェブサーバーの状態を保存する |
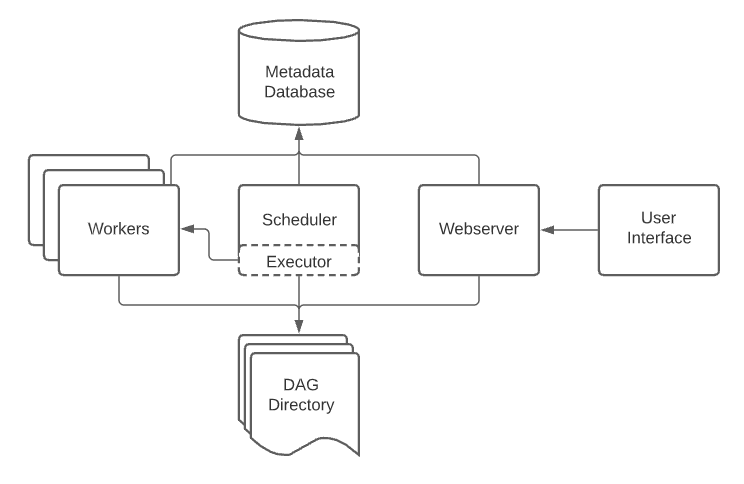
(DAG Directory とは、ユーザーが提供する「ワークフロー定義」のコードのことで、記事の最後に事例があります。)
DAGs
DAGとは「Directed Acyclic Graph」の略で「依存関係にあるタスクをどの順番で実行するか」を示すものです。Airflowのもっとも中心的な概念と言えます。以下のDAGは、4つのタスクがあり、矢印で依存関係と実行の流れが見て分かります。
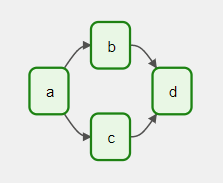
あなたの会社で、このようにフローチャートとして可視化して、自動化したいプログラムはありませんか?
Tasks
DAGは、Task(タスク)で構成されています。タスクは、Python関数、Rubyのコンテナ、Bashスクリプトなど、様々な形態で用意できるものです。実行する順番を示すために、上流や下流にある他のタスクとの依存関係を持つことができます。DAGを定義する際、以下のような書き方でタスクの依存関係を示します。
task1 >> task2 >> task3
タスクには「状態」が保存され、実行結果や上流のタスクの状態によって下図のように変わっていきます。AirflowのUIから、どのタスクがどの状態にあるのか、色やメタデータで示されるため、ピンポイントで確認しやすいです。
Operators
Operatorは、定義済みのタスクのテンプレートのようなものです。OOPに例えると「Operator=クラス」「Task=インスタンス」というイメージです。多くの場合、EC2インスタンスの起動やSlackメッセージの投稿など、よく行われるタスクがコミュニティーOperatorとして実装されています。自分はDAGの開発において、カスタムタスクの実装より、既存Operatorをつなぎ合わせる作業の方が多い場合がよくあります。
例えば、このようなOperatorがあります。
- BashOperator(Bashコマンドを実行)
- EC2StartInstanceOperator(EC2インスタンスを起動する)
- PythonOperator(Python関数を実行)
- EmailOperator(Eメールを送信する)
- SimpleHttpOperator(HTTPリクエストを実行する)
- DockerOperator(コンテナを実行)
- SlackAPIPostOperator(Slackにメッセージを投稿する)
以下のようなコードで、EC2インスタンスを起動してからSlackにメッセージを送信することができます。VMの起動処理と、SlackのAPIコールはOperatorが行ってくれるので、DAGの実装者は適切なパラメータを与えてつなぎ合わせればいいです。
start_instance = EC2StartInstanceOperator(
task_id="start_instance",
instance_id="***",
)
send_slack_alert = SlackAPIPostOperator(
task_id="send_slack_alert",
token="***",
text="起動しました!",
channel="#dev_monitoring",
)
start_instance >> send_slack_alert
Sensors
Sensor(センサー)は Operator の一種で「とある条件が満たされるまで待つ」役割を担います。その「条件」は「ファイルが現れるまで」や「1時間が経ったら」など、様々な指定方法があります。また、Operatorと同じように、コミュニティーが用意した以下のような Sensor がたくさんあります。
- BashSensor(Bashコマンドが成功するまで待つ)
- PythonSensor(Python関数が True を返すまで待つ)
- S3KeySensor(S3キーが現れるまで待つ)
- GCSObjectExistenceSensor(GCSにオブジェクトが現れるまで待つ)
- DayOfWeekSensor(指定の曜日まで待つ)
せっかくなので、上記のコード例に「EC2インスタンスの起動を待つ」センサーを追加しましょう。
start_instance = EC2StartInstanceOperator(
task_id="start_instance",
instance_id=instance_id,
)
+
+ wait_until_running = EC2InstanceStateSensor(
+ task_id="wait_until_running",
+ instance_id="***",
+ target_state="running"
+ )
+
send_slack_alert = SlackAPIPostOperator(
task_id="send_slack_alert",
token="***",
text="起動しました!",
channel="#dev_monitoring",
)
- start_instance >> send_slack_alert
+ start_instance >> wait_until_running >> send_slack_alert
Variables
Airflowには、任意の値を保存できるKey-Valueストアが用意されています。このKey-Valueストアに保存される値は「Variable」と呼ばれ、タスクから取得したい設定や秘密情報(例:APIトークン)の管理に使います。Variable は一般的に UI から設定しますが、CLI や JSONファイルからのインポートなど、設定方法がいくつかあります。
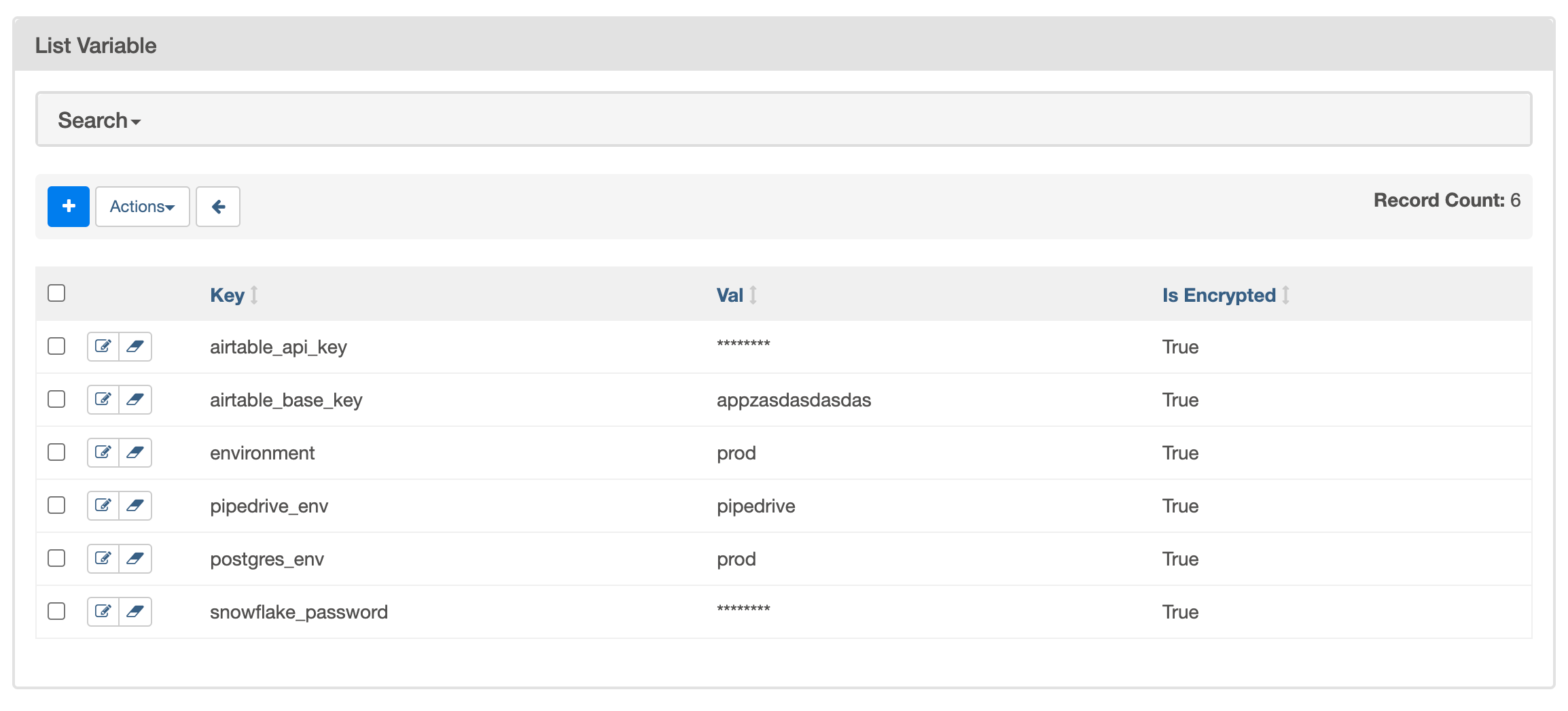
Variable はテキストとしてメタデータ・データベースに保存されますが、Airflow の環境設定で fernet_key を指定すると、保存前に暗号化してくれます。また、Secret Backend を有効にすると、AWS Secret Manager や GCP Secret Manager から Variable を取得することも可能です。設定方法の実例は以下のリンクをご参考ください。
そういうば、さっきからSlackトークンやEC2インスタンスのIDをベタ書きしていましたね… せっかくなので Variableで置き換えましょう!
+ instance_id = Variable.get("INSTANCE_ID")
+ slack_token = Variable.get("SLACK_TOKEN")
+
+
start_instance = EC2StartInstanceOperator(
task_id="start_instance",
- instance_id="***",
+ instance_id=instance_id,
)
wait_until_running = EC2InstanceStateSensor(
task_id="wait_until_running",
- instance_id="***",
+ instance_id=instance_id,
target_state="running"
)
send_slack_alert = SlackAPIPostOperator(
task_id="send_slack_alert",
- token="***",
+ token=slack_token,
text="起動しました!",
channel="#dev_monitoring",
)
start_instance >> wait_until_running >> send_slack_alert
Connections & Hooks
Airflowでは、外部システム(例:AWS、GCP)と接続することがよくあるため、外部システムとやりとりするための認証情報を保存する「Connection」と呼ばれる仕組みがあります。Connection には、ユーザー名、パスワード、ホスト名といった接続情報と、外部システムの種類(例:PostgreSQL)や conn_id と呼ばれる識別子(例:prod_db)があります。Variable と同じように UI や CLI から管理できて、Secret Backend から取得することも可能です。
Hookは、外部プラットフォームとのハイレベルなインターフェースです。外部プラットフォームのAPIを直接叩いたり、botocore のようなライブラリーで低レベルのコードを書くことなく、簡単にやりとりするためのクライアントライブラリー(つまり Facade)です。AWS のプロバイダーパッケージにある S3Hook を以下のように使うことができます。
hook = S3Hook(conn_id="aws_default")
content = hook.read_key(key="この記事が参考になったら", bucket_name="LGTMよろしくお願いします")
既存 Operator や Sensor を使わないでタスクを実装する時に、Hook を活用すべし!
Task Logging
Airflow のとても便利なところは、タスクのログを UI から個別に確認できるところです。下図は example_bash_operator という DAG における run_after_loop タスクのログを表示しています。タスクがリトライされた場合、実行ごとのログを見ることもできます。(ちなみに右下の "Download" ボタンは私が開発したものです)
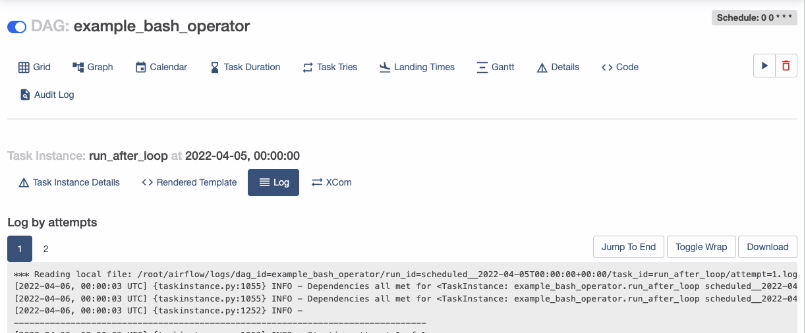
タスクのログは、デフォルトでローカルディスクに書き込まれますが、ちょっと設定をいじれば、以下のような外部サービスに転送することもできます。自分は本番環境では、大体 S3 に書き込んでいます。
- Writing logs to S3
- Writing logs to Cloudwatch
- Writing logs to Google Cloud Storage
- Writing logs to Azure Blob Storage
- Writing logs to Elasticsearch
(Elasticsearch との連携に興味ある方、以下の記事で解説していますのでご参照ください。)
Metrics
Airflow は StatsD にメトリック情報を送るように設定できます。実行中のタスク数や DAG ファイルをパースするプロセス数など、Airflow の内部メトリックを細かくトラッキングできます。
[metrics]
statsd_on = True
statsd_host = localhost
statsd_port = 8125
statsd_prefix = airflow
スケジューラーと同じ環境に AWS の CloudWatch エージェントをインストールすれば、StatsD メトリックを CloudWatch に転送することも可能です。
また、開発環境では statsd-exporter と組み合わせて、メトリックの時系列を Prometheus や Graphana で可視化することもできます。docker-compose の事例は以下を参考にしていただければと思います。
REST API
Airflowは、基本的な CRUD を行うための REST API を提供します。プログラムによる DAG のトリガー、Variable の追加、ヘルスチェックなど、様々な用途があります。
例えば、自社の業務システムに「レポート発行機能」を実装したいと仮定しましょう。ユーザーが UI にあるボタンを押したら、ウェブサーバーから Airflow REST API 経由で DAG をトリガーして、データ取得やEメール送信を非同期的に行うようなワークフローが可能です。
【実例】100行未満の本格的なデータパイプライン
さて、開発環境ができたので、ちょっとした DAG を書いてみましょう。この DAG で BigQuery にあるデータを S3 にバックアップしたいと思います。まず、AWS と GCP にアクセスするための認証情報を Credential に、Slackトークンを SLACK_TOKEN という Variable に保存します。
次は、dags フォルダーにファイルを追加して、以下の通り DAG を実装します。
- BigQueryInsertJobOperator で BigQuery からデータを出力する
- BigQueryToGCSOperator で Google Cloud Storage に転送する
- GCSToS3Operator でデータを Google Cloud Storage から S3 に転送する
- SlackAPIPostOperator で完了の連絡を Slack に通知する
import pendulum
from airflow.models import Variable
from airflow.providers.google.cloud.operators.bigquery import BigQueryInsertJobOperator
from airflow.providers.google.cloud.transfers.bigquery_to_gcs import BigQueryToGCSOperator
from airflow.providers.amazon.aws.transfers.gcs_to_s3 import GCSToS3Operator
from airflow.providers.slack.operators.slack import SlackAPIPostOperator
BACKUP_SQL = """
SELECT
*
FROM
example_dataset.example_table
WHERE
date >= '{{ data_interval_start }}'
"""
S3_BUCKET_NAME = Variable.get("S3_BUCKET_NAME")
S3_DEST_KEY = "s3://{{ var.value.S3_BUCKET_NAME }}/{{ ts_nodash }}"
BQ_DATASET = Variable.get("BQ_DATASET")
BQ_TABLE_ID = "{{ ts_nodash }}" # 例)20180101T000000
GCS_BUCKET = Variable.get("GCS_BUCKET")
GCS_PREFIX = "{{ ts_nodash }}"
GCS_DEST_URI = f"gs://{GCS_BUCKET}/{GCS_PREFIX}.csv"
SLACK_TOKEN = Variable.get("SLACK_TOKEN")
with DAG(
"example_backup",
start_date=pendulum.datetime(2021, 1, 1, tz="Asia/Tokyo"), # このDAGが有効になる日
schedule_interval="0 9 1 * *", # 毎月1日の9時に実行する
catchup=False # start_date〜現在の分を実行しない
):
# (1)
bigquery_export = BigQueryInsertJobOperator(
task_id="bigquery_export",
gcp_conn_id="google_cloud_default",
configuration={
"query": {
"query": BACKUP_SQL,
"destinationTable": {
"datasetId": BQ_DATASET,
"tableId": BQ_TABLE_ID,
}
}
},
)
# (2)
bigquery_to_gcs = BigQueryToGCSOperator(
task_id="bigquery_to_gcs",
source_project_dataset_table=f"{BQ_DATASET}.{BQ_TABLE_ID}",
destination_cloud_storage_uris=[GCS_DEST_URI],
)
# (3)
gcs_to_s3 = GCSToS3Operator(
task_id="gcs_to_s3",
bucket=GCP_BUCKET,
prefix=GCS_PREFIX,
dest_s3_key=S3_DEST_KEY,
dest_aws_conn_id="aws_default",
gcp_conn_id="google_cloud_default",
)
# (4)
post_slack_message = SlackAPIPostOperator(
task_id="post_slack_message",
channel="#team_dev",
token=SLACK_TOKEN,
text="データ転送が完了しました"
)
bigquery_export >> bigquery_to_gcs >> gcs_to_s3 >> post_slack_message
この DAG の素晴らしいところをまとめましょう:
- 75行で3つの外部プラットフォーム(AWS、GCP、Slack)と連携するデータパイプラインを作った
- botocore や gcloud のようなライブラリーを触らなかった
- 認証情報を安全な場所に保存した
- CRON文法で実行スケジュールを定義した
- SQLやファイル名に
datetime.now()を使わず、あとから値を変更できる{{ data_interval_start }}のようなテンプレート変数を使ったので、過去の日付に対して実行できる(例:一年前のバックアップを取ることができる)
終わりに
冒頭で伝えた通り、Airflowは広いコミュニティに支えられ、多くの企業に利用されているプラットフォームです。データパイプラインのみならず、機械学習、サーバー監視、データ品質管理、営業レポート作成など、用途が多岐にわたります。そして、一部のワークフローの実行権限を非エンジニアに与えることで、エンジニアへの依頼を減らす効果も期待できます。
もっと詳しく知りたい方、コミュニティとつながりたい方、以下のリンクが参考になれたらと思います。
- Tokyo Apache Airflow Meetup
-
Airflowの公式Slackチャンネル(
#users-japanは日本語で話せるよ!) - Airflow (GitHub)
- Airflow 公式ドキュメント