この記事はBeeX Advent Calendar 2022の14日目の記事です。
またもや投稿遅刻しました(投稿日12/16)
はじめに
AppFlowでは、フローの実行料金とAppFlowが処理したデータ処理料金の2つが課金対象となっており、東京リージョンでは以下の料金が発生します。
- フロー実行料金:$0.001
- AWS でホストされている宛先のフローのデータ処理料金:$0.09/GB
- 宛先が AWS PrivateLink (AWS または外部でホスト) と統合されているフローのデータ処理料金:$0.09/GB
- 宛先が AWS でホストされておらず、かつ AWS PrivateLink と統合されていないフローのデータ処理料金:$0.09/GB(~1GB)、$0.124/GB(1GB~)
このうち、フロー実行料金はAppFlowフローの実行回数に対する課金なのでわかりやすいのですが、データ処理料金については取得元のデータサイズで計算できるものではないのでランニングコストの試算がざっくりとしか出すことができません。
こちらのドキュメントをみると「料金は、データ処理 (スキーママッピング、フィールド検証、フィルタリング、マスキングフィールド、およびフィールド変換) に対して発生します」と記載があるので、ソースのデータサイズに依存するというよりはフィールド数に依存して処理サイズが増加しそうですが、ドキュメントには具体的に明記まではされていませんでした。
一応AWSサポートに問い合わせてみたところ、AppFlowコンソールの以下の実行履歴に記載されている転送サイズが上記のデータ処理料金の対象になると回答があったので、今回はこれをベースにいくつかパターンを準備して処理サイズがどう増加するかどうか検証をしてみます。

検証内容
条件
ソース元のデータによって変わってくる可能性がありますが、今回は一番わかりやすいS3からS3への連携で試してみます。
ソースデータはフィールド数、レコード数でいくつかパターンを準備していて、データサイズは1GB、10GBなど揃えられなかったので、一旦作成したCSVファイルのサイズを以下のパターン表にそのまま載せています。

AppFlowフローを分割して作成するため、CSVファイルの格納先もフォルダ分けしています。


AppFlow側の設定はFrom/ToはS3の別バケットを指定し、フィールドはフルマッピング、フィルタリングやマスキングは未設定とします。
書き込みデータの形式はCSV、ファイル名にタイムスタンプを追加する設定とします。

また、パーティションは作成せず、全てのレコードを1つのファイルに集約する設定にします。

この記事の検証で分かったこと(S3からS3へのデータ連携の場合)
- データ処理対象となるのはAppFlow上でマッピングされたフィールドのみ(マッピングされてなければ対象外)
- 一度フロー実行してフィールド数・レコード数・転送サイズが分かればそれを元にしたある程度の転送サイズの予測は可能
- フィールド名自体のサイズが転送サイズに大きく影響してそう(詳細な計測はできていない)
検証結果
全部見ると長いので、サッと見たい方はサマリを見てください。
サマリ
まず全体としてみたときに、フィールド数が同じでレコード数だけが増えた場合は、レコード数の増加にほぼ比例してデータ処理サイズも増加するようになっていました。
出力データサイズは※に記載の変換が入っているので若干ソースのCSVよりも増えていますが、レコード数の増加に合わせて出力データサイズもほぼ比例してるように見えます。
APpFlow処理時間は今回検証したフィールド数やレコード数では然程大きな差は出てませんでした。

また、レコード数が同じでフィールド数が増えた場合も、レコードの増加と同じくフィールド数の増加にほぼ比例してデータ処理サイズが増加していました。
ただ、今回はCSVファイルをソースとしていたので、フィールドのデータ型も文字列型で認識されていましたが、これがSalesforceなどになった場合は文字列型以外も含まれるため、その場合はほぼ比例するとは言えない可能性もあります。
これはちょっと検証パターンが良くなかったかもしれません。

※出力サイズが微妙に増えていますが、これは出力されたCSVファイルには""が自動的に付いているので、その分だけサイズが増えたのだと思います。

フィールド数10、レコード数10の場合
(S3からS3に連携する場合はフィールド名の行も1レコードと認識されるのを失念していました。。)
フローを実行すると転送サイズは1.572KB、転送レコードは11レコード、処理時間は6.8秒でした。

フィールド数10、レコード数100の場合
フローを実行すると転送サイズは15.262KB、転送レコードは101レコード、処理時間は6.61秒でした。

フィールド数10、レコード数1000の場合
フローを実行すると転送サイズは161.072 KB、転送レコードは1001レコード、処理時間は6.32秒でした。

フィールド数100、レコード数10の場合
フローを実行すると転送サイズは16.523 KB、転送レコードは11レコード、処理時間は5.97秒でした。

フィールド数100、レコード数100の場合
フローを実行すると転送サイズは159.993 KB、転送レコードは101レコード、処理時間は6.34秒でした。

フィールド数100、レコード数1000の場合
フローを実行すると転送サイズは 1.683793 MB、転送レコードは1001レコード、処理時間は6.51秒でした。

フィールド数1000、レコード数10の場合
フローを実行すると転送サイズは175.834 KB、転送レコードは11レコード、処理時間は8.33秒でした。

フィールド数1000、レコード数100の場合
フローを実行すると転送サイズは1.697294 MB、転送レコードは1001レコード、処理時間は5.88秒でした。

フィールド数1000、レコード数1000の場合
フローを実行すると転送サイズは17.802894 MB、転送レコードは1001レコード、処理時間は11.48秒でした。

追加検証(フィールドとレコードを減らしてみる)
ドキュメントの記載から課金対象のデータ処理は以下の5つだと思いますが、フィルタリングとマスキングは設定していないことから実際に処理されたのは3つではないかと思います。
しかし、ソースデータサイズとAppFlow処理サイズを比べてみると約5倍になっていることから、少なくとも3回以上ソースデータを処理したか、ソースデータ以上のデータを扱う処理が裏側で行われた可能性があります。

- スキーママッピング → 恐らく処理されている
- フィールド検証 → 恐らく処理されている
- フィルタリング → 未設定のため恐らく未処理
- マスキングフィールド → 未設定のため恐らく未処理
- フィールド変換 → 恐らく処理されている
処理名からして、以下のAppFlow上でマッピングされたフィールドの数によって処理データサイズが変動するようになっている気がします。
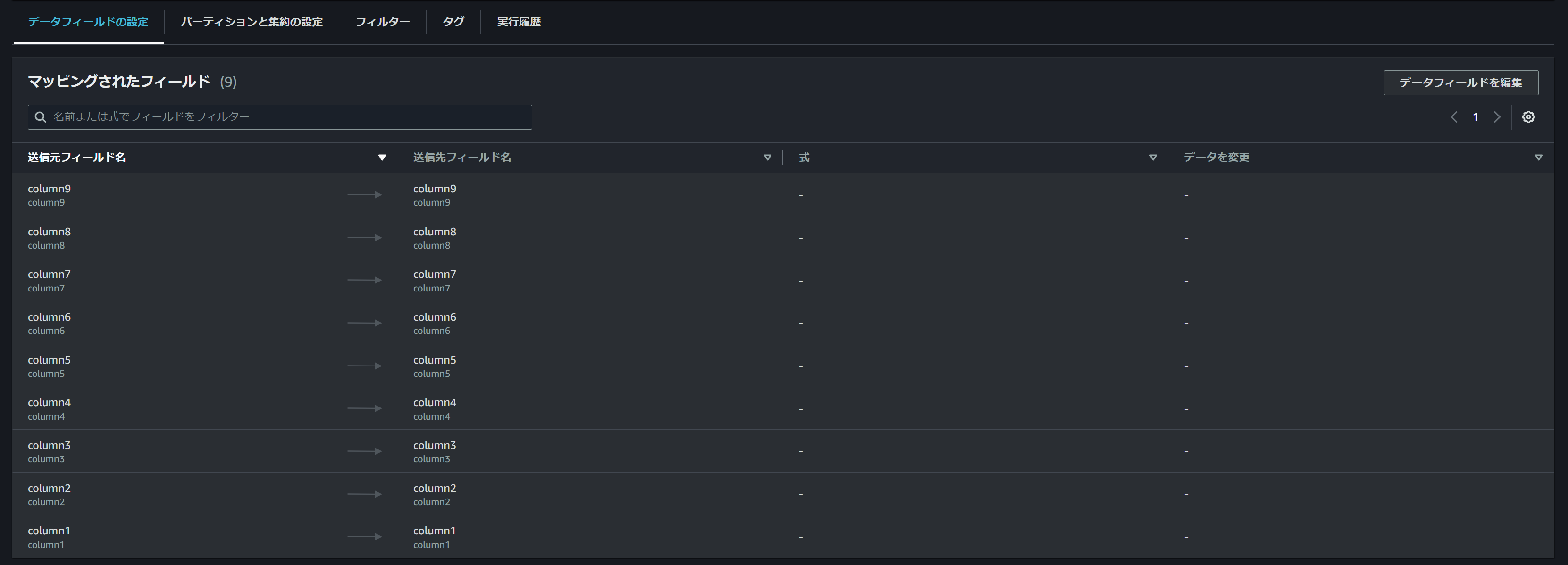
試しにS3上のソースデータは変更せずにAppFlow上のマッピングフィールドを1つ減らして実行したところ、転送サイズも減ったのでAppFlow内で処理する前にマッピングされていないフィールドは処理対象から除外されているようです。

他にも1フィールドずつ減らしていくとどう変化していくかみたところ、1フィールド減らすごとに155B減っていき、10フィールド→1フィールドになった時は10フィールドの10分の1程度の転送サイズになっていました。

更にレコードを11→1に減らして実行してみたところ、転送サイズも10分の1程度の転送サイズになっていました。

以上のことから、データ処理対象となるのはAppFlow上でマッピングされたフィールドのみで、一度フロー実行してフィールド数・レコード数・転送サイズが分かればある程度の転送サイズの予測は可能だと思われます。(一度実行しないといけないというのがネックですが)
追加検証(フィールド名を操作してみる)
1つ考えたのは、データ処理の対象としているのはフィールド周りの検証や変換が主になっているので、フィールド名を変更すればフィールドやレコードを減らさなくても転送サイズを減らせるんじゃないか、と思いました。
そこで以下のようにフィールド名を減らして再度実行してみました。
↓

結果としては想定通りのもので、以下キャプチャの下がフィールド名修正前、上が修正後で、転送サイズが330KBも減っていました。

今度はフィールド1つ、レコード1つの7Bのファイルを作成して実行してみます。尚、7Bはフィールド名5B、改行(LF)1B、レコード1Bの計7Bになっています。

転送サイズが13Bになりました。これだけを見るのであれば、
スキーママッピングとフィールド変換は確実にされていると思うので5B×2=10B
フィールド検証と変換はレコードに対しても行われていると思うので1B×2=2B
改行(LF)1Bは変換時に処理されていると思うので1B×1=1B
合計10B+2B+1B=13B、みたいに想定ができるのでしょうけど、確証までは得られないのと他パターンを試すと当てはまらない気がします。

実際、フィールド名を5文字から10文字に増やして実行してみたところ、上記理論であれば20Bは超えてないとおかしいですが18Bでした。

おわりに
うーん、フィールド名自体のサイズが転送サイズに大きく影響してそうだ、ということはわかりましたが、だからといってフィールド名から転送サイズが推測できるものではなさそうなので、今回はこれぐらいで検証終わります。
AppFlowはネットワークやロジック周りのドキュメントや説明しているものが他のAWSサービスに比べるとかなり少ないので、AppFlow DeepDiveとかあって裏側の仕組みを説明される機会があれば是非聞きに行きたいと思います。
確認した結果よくわからなかったというのがもやもやしますが、また何かわかったことがあれば記事にしたいと思います。
この記事がどなたかの参考になっていれば幸いです。