この記事はBeeX Advent Calendar 2023の7日目の記事です。
はじめに
今年もラスベガスでAWSのグローバルイベントのre:Invent 2023開催されました。
今回は数あるAWSアップデートの中でも、特に気になったAmazon S3 Express One Zoneストレージクラスについて、実際に触りながら見ていきたいと思います。
※検証したままを書いているので、多少読みづらいかもしれません。
Amazon S3 Express One Zoneストレージクラスとは
公式のリリースには以下のように記載されていました。
Amazon S3 Express One Zoneストレージクラスは、一貫した1桁ミリ秒のリクエストレイテンシーを必要とするパフォーマンスクリティカルなアプリケーション向けに、最速のクラウドオブジェクトストレージを提供することを目的として構築されています。
S3 Express One Zoneは、S3 Standardと比較して、データアクセス速度を10倍向上させ、リクエストコストを50%削減することができ、最も頻繁にアクセスされるデータセットに対して毎分数百万のリクエストを処理できるように拡張できます。機械学習トレーニング、インタラクティブ分析、メディアコンテンツ作成などのワークロードで、高い耐久性と可用性を備えた1桁ミリ秒のデータアクセス速度を実現します。
以下のドキュメントにある通り、このアップデートが出るまでは、S3のレイテンシーをミリ秒に抑えたい場合、CloudFront等のコンテンツのキャッシュが可能なサービスとの組み合わせが必要となっていました。
例えば、HTTP 接続ごとの転送レートを高めたい場合やレイテンシーをミリ秒単位に抑えたい場合は、Amazon CloudFront または Amazon ElastiCache を Amazon S3 のキャッシュとして使用します。
今回発表された「Amazon S3 Express One Zoneストレージクラス」を利用することで、他のAWSサービスやアプリケーションは1桁ミリ秒のリクエストレイテンシーでオブジェクトストレージを利用することができる、という内容でした。
利用時の注意点
利用時の注意点として、通常S3は格納されたデータを複数のAZに複製して保管するような仕組みになっているので高い耐久性を持つことで知られますが、この「S3 Express One Zone」では単一のAZのみに保管することになるため、耐久性はStandardクラスに比べると下がってしまうというデメリットがあります。
ただ、ドキュメントを読むと「データは単一のアベイラビリティゾーン内の複数のデバイスに冗長的に保存されます」とあるので、単一のAZの中では常に複数のデバイスに冗長化される仕組みとなっているようです。
S3 Express One Zoneでは、AWS Region内の特定のAWS Availability Zoneを選択してデータを保存することができます。さらにパフォーマンスを最適化するために、ストレージとコンピュートリソースを同じAvailability Zoneに配置することができます。
ユースケース
ユースケースとしては、SageMakerのモデルトレーニングやAthenaやEMR、GlueなどでのS3アクセスの高速化が上げられておりました。
S3 Express One Zoneを使用すると、Amazon SageMaker Model Training、Amazon Athena、Amazon EMR、AWS Glue Data Catalogなどのサービスを使用して、AI/MLおよび分析ワークロードを高速化できます。
利用可能リージョン(2023/11/28時点)
発表時点では、東京を含む一部リージョンでのみ利用可能となっていました。
S3 Express One Zoneは通常、米国東部(バージニア州北部)、米国西部(オレゴン州)、欧州(ストックホルム)、アジア太平洋(東京)のAWSリージョンで利用できる。
S3バケット作成
ドキュメントを確認したところで、東京リージョンで実際に構築してみようと思います。
S3コンソールにアクセスして、「バケットを作成」から作成画面に遷移すると、バケットタイプが複数選択できるようになっていました。
これまで利用していた「Standard」クラスを使いたい場合は"汎用"タイプ、「S3 Express One Zone」クラスを使いたい場合は"ディレクトリ"タイプを選択します。
"ディレクトリ"タイプで構築したS3はディレクトリバケットと呼ぶようです。

バケットタイプを選択したら、構築先のAZを選択します。
検証時点(2023/11/30)で指定できるAZは、AZ-AとAZ-Cの2つのみのようです。

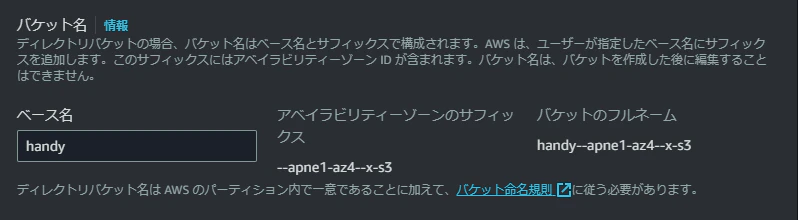
AZを選択したら、次にバケット名を入力します。
バケット名には、自動的にサフィックスとしてAZ IDが含まれるようになっているようです。
AWSのパーティション内で一意にする必要があるのは通常のS3と変わらないようです。
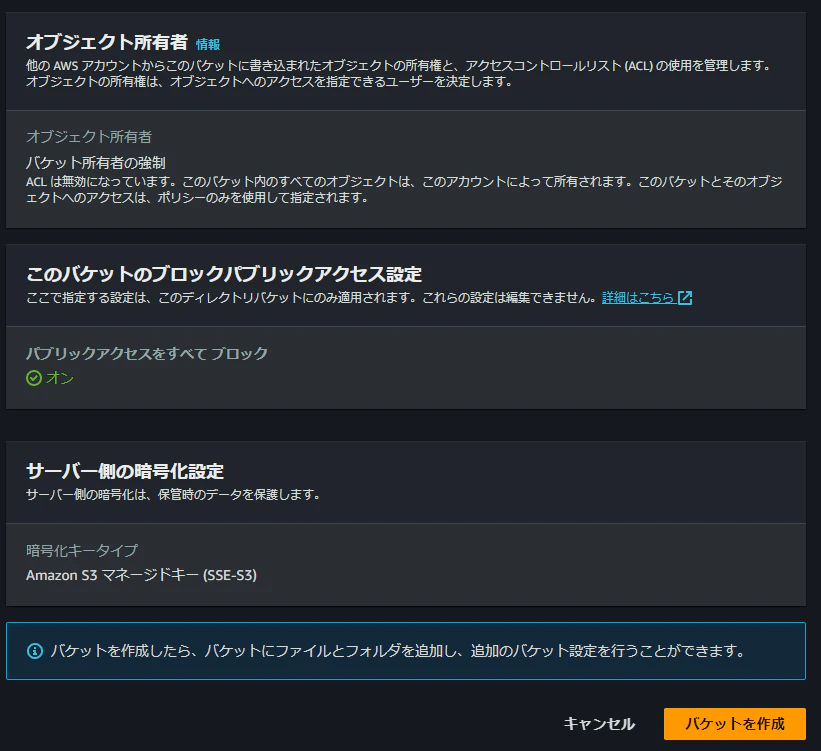
残りの項目として、オブジェクト所有者、ブロックパブリックアクセス、暗号化設定がありました。
ただ、いずれ設定できるようになるのかもしれませんが、検証時点ではいずれも選べないようになっていました。
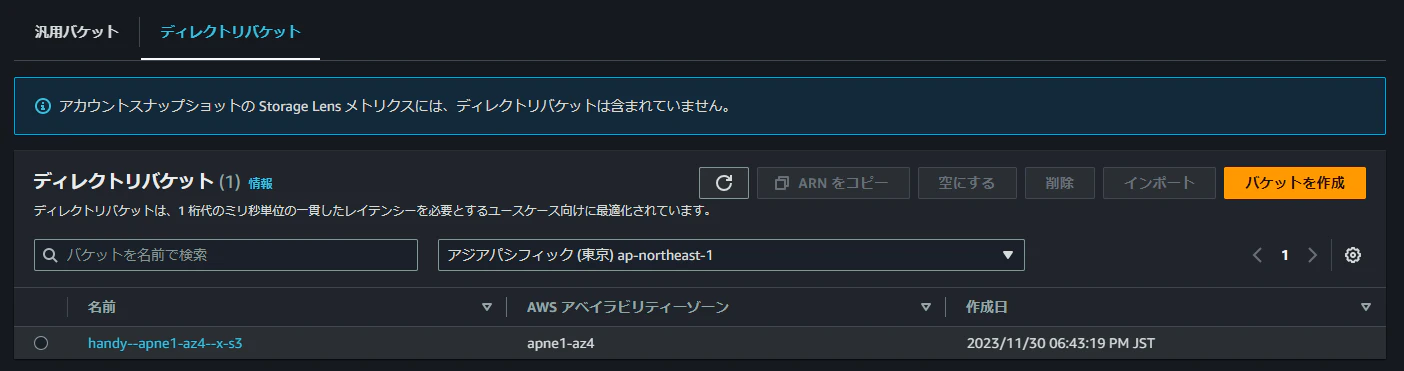
ディレクトリバケットが作成できると、バケットの一覧から確認することができます。
一覧画面では、汎用バケットタブとディレクトリバケットタブに分かれていました。
タイプごとに分けて確認できるので、これは嬉しいですね。
作成リソース確認
バケット名を押下して、画面を確認してみます。
オブジェクトタブは通常のS3と変わりませんでした。
プロパティタブの項目はかなり少ないです。
リージョンとAZ、あとは暗号化設定とARNぐらいしか表示されていませんでした。

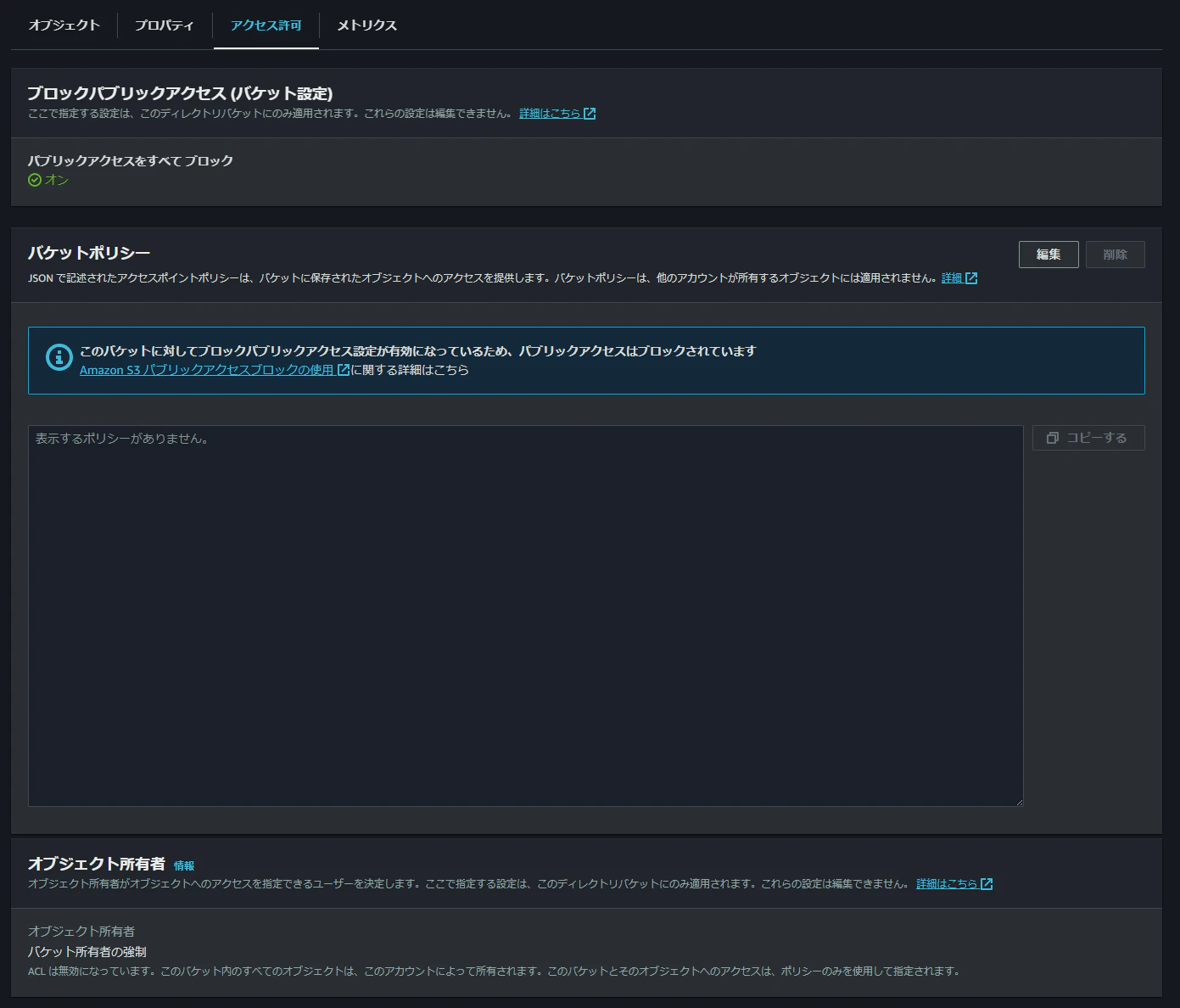
アクセス許可タブの項目もかなり少ないです。
ただ、バケットポリシーの設定項目はあったので、これまでのS3と同じようにポリシーによるアクセス制御はできそうです。
メトリクスタブでは、合計バケットサイズとオブジェクト合計数が確認できました。

コンテンツアップロード
ディレクトリバケットが作成できたので、実際にコンテンツをアップロードしてみます。
通常のS3と同じようにコンソールのアップロードボタンからでもファイルアップロードができるのですが、今回は敢えてディレクトリバケットのインポート機能を利用して、オブジェクトを既存の別のS3バケットから取り込んでみます。

対象のディレクトリバケットを選択して、インポートボタンを押下すると、インポートを行う画面に遷移します。
そこで、インポート元のS3バケット、インポートに利用するIAMロールの2つを入力もしくは選択します。
送信先やオブジェクトの設定は自動で入力されていました。

Batch Operations のコピーオペレーションは、最大 5 GB のサイズのオブジェクトをサポートします。5 GB を超えるソースオブジェクトはこのジョブには含まれません。
と、書かれていたので、裏側ではBatch Operationsが利用されているようです。
インポートを実行すると、バッチオペレーションの画面に遷移しました。
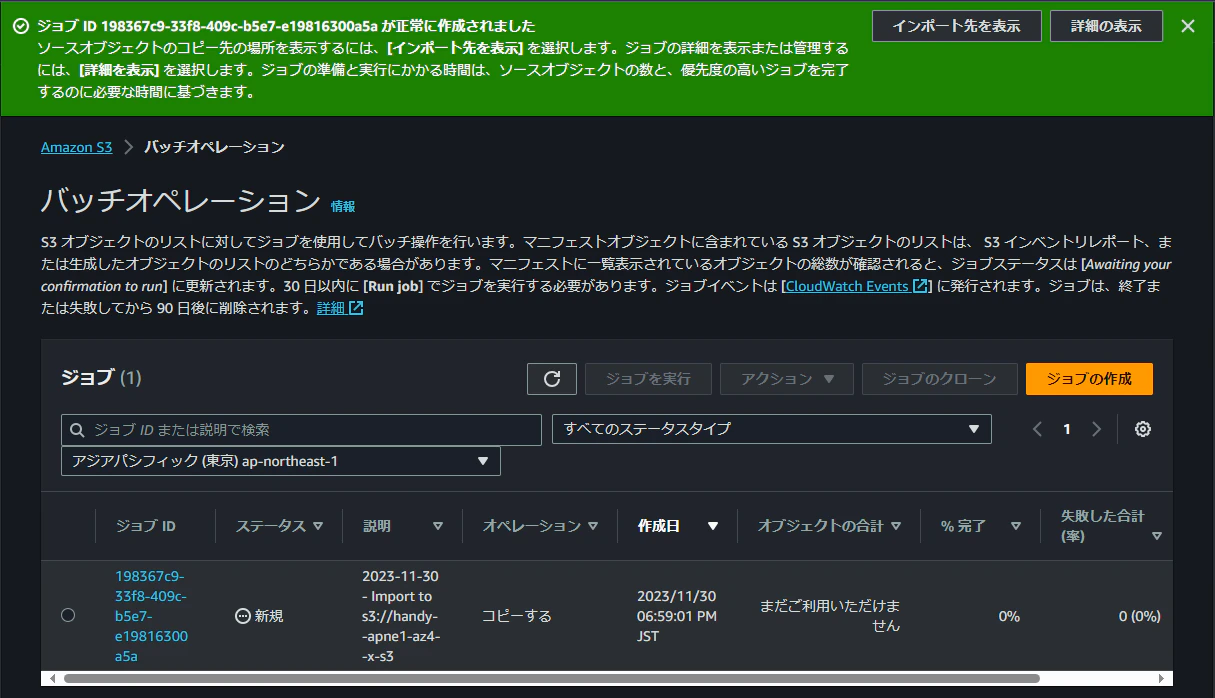
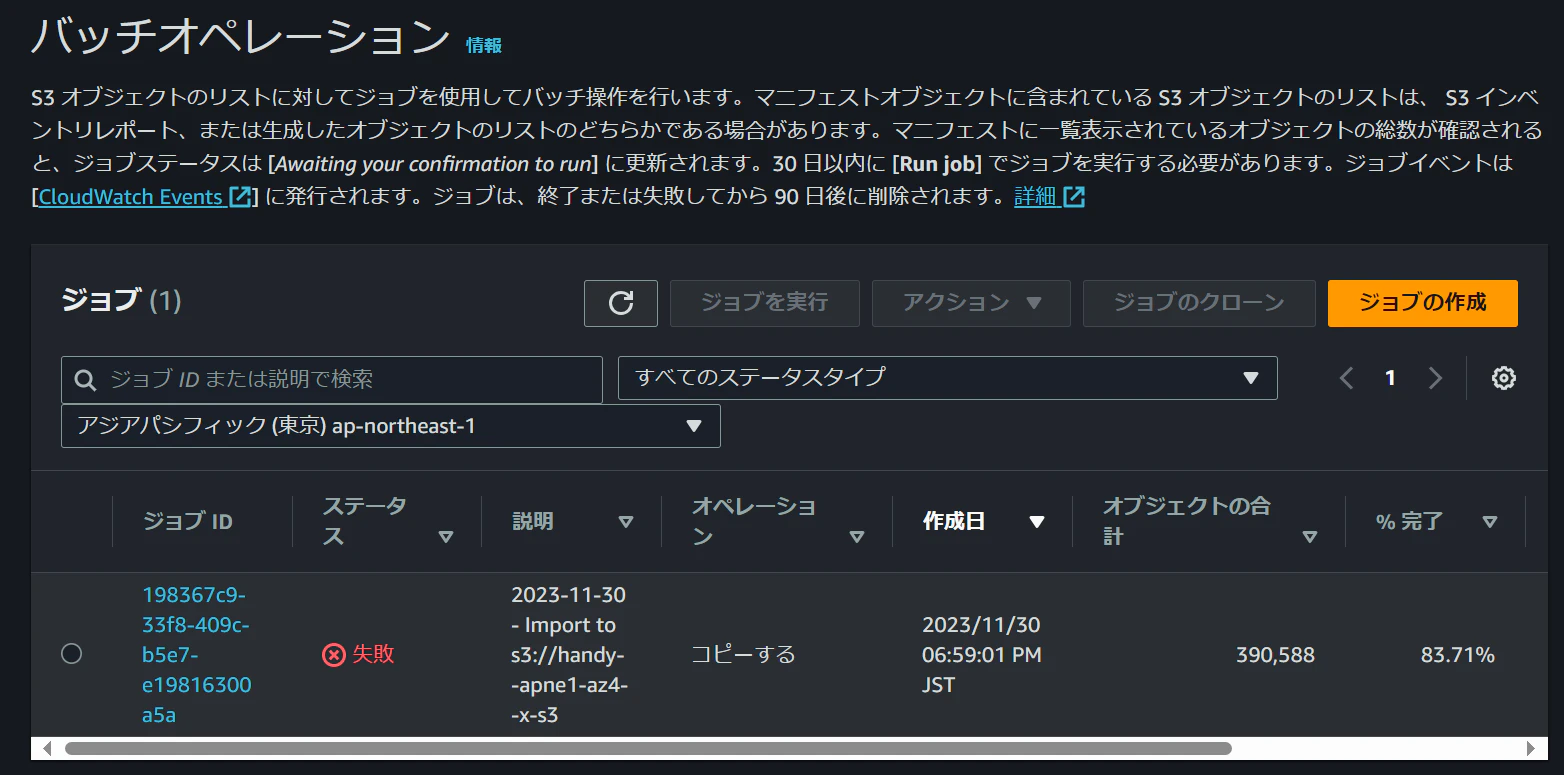
半日待ちましたが全然終わらないので放置したのですが、翌日確認したところ失敗していました。
AWSアカウントに紐づけてるメールアドレス宛に、Amazon S3のプロダクトマネージャーの方から以下のようなメールが届いていました。
「無効なKMSキーを使用して暗号化されたオブジェクトがあり、Importジョブが無効なKMSキーを使用してコピーしようとして失敗していた」と連絡がありました。ジョブは手動で失敗していただいたようです。
※AWSのプロダクトマネージャーから直接メールが届くのは初だったので驚きました
私たちは、あなたがS3管理コンソール(ジョブID:198367c9-33f8-409c-b5e7-e19816300a5a)からS3ディレクトリバケットにデータをコピーするためにインポートジョブを開始したことに気づきました。S3PutObjectCopy操作のソースバケット内のオブジェクトを暗号化するために使用された無効なKMSキーがあり、その結果、Importジョブがこの無効なKMSキーを使用してオブジェクトのコピーに失敗していることがわかりました。ジョブを失敗させる措置をとりました。これらのオブジェクトのKMSキーを有効にした後、これらのオブジェクトを正常にコピーするためにImportジョブを再起動することができます。

ただ、いくつかのオブジェクトはインポートできていたので、今回はこのまま進めたいと思います。
オブジェクトアクセス
Glue/Athenaの場合
Glue Crawlerを使用してクロールしようとしましたが、コンソールからではS3バケット一覧に表示されず、手動入力してもエラーでクローラーの作成自体が失敗しました。
一応バージニア北部でも確認しましたが、そちらでも同じく一覧に表示されませんでした。

Mountpoint for Amazon S3の場合
仕方ないので、今年GAされたMountpoint for Amazon S3を使用して、S3をEC2にマウントして確認してみます。
https://aws.amazon.com/jp/blogs/news/mountpoint-for-amazon-s3-generally-available-and-ready-for-production-workloads/
手順は以下の記事を参考にしました。
テストデータはCloudTailログを利用します。
昨年分のログに対してEC2上でコマンドを実行して結果が変わるか確認します。

EC2上にStandardクラスのS3バケットとExpress One ZoneクラスのS3バケットをマウントしました。
[root@ip-10-20-0-7 mnt]# ll
total 0
drwxr-xr-x. 2 root root 0 Dec 1 05:41 mount_express
drwxr-xr-x. 2 root root 0 Dec 1 05:42 mount_standard
どちらも同じオブジェクト構成になっていることを確認します。

以下のコマンドで対象フォルダ配下のファイルを検索する時間を計測してみます。
$ time find /mnt/mount_standard/AWSLogs/123456789123/CloudTrail-Digest/ap-northeast-1/2022/ -type f | wc -l
$ time find /mnt/mount_express/AWSLogs/123456789123/CloudTrail-Digest/ap-northeast-1/2022/ -type f | wc -l
-
Standardクラスの場合
2293ファイルの検索で約11秒かかりました。

-
Express One Zoneの場合
2293ファイルの検索で約6秒かかりました。

使用したEC2の構成は以下の通りです。
・インスタンスタイプ:t3.small
・AMI:ami-0d48337b7d3c86f62(Amazon Linux 2023 AMI 2023.2.20231016.0 x86_64 HVM kernel-6.1)
厳密に条件を準備したわけではないですが、ざっくり半分ぐらいの時間で処理を完了することができました。
※あくまで自環境での結果であり、必ずしも同じ結果になるとは言えないため、参考程度にとどめてください。
おまけ
ちなみに同じ環境でS3上の対象オブジェクトをEBSにダウンロードしてきてコマンドを試してみました。

0.006秒でした。

おわりに
これまでのストレージクラスと比べるとかなり処理が早くなっていることが実感できました。
やり方が悪かったのかAthenaからのクエリ結果は確認できませんでしたが、同じタイミングで発表されたMountpoint for Amazon S3のExpress One Zoneサポートも一緒に検証出来て良かったです。
https://aws.amazon.com/jp/about-aws/whats-new/2023/11/mountpoint-amazon-s3-express-one-zone-storage-class/
AWS公式ブログが公開されてますので、興味のある方は是非こちらをご覧ください。
https://aws.amazon.com/jp/blogs/aws/new-amazon-s3-express-one-zone-high-performance-storage-class/
企業の利用事例は以下に記事があります。
https://aws.amazon.com/jp/blogs/storage/tag/amazon-s3-express-one-zone/