1 はじめに
Pythonを使って、JPEGファイルから文字を抽出してみます。
2 環境
VMware Workstation 15 Playerで作成した仮想マシン(1台)を使用しました。
CentOSの版数は下記のとおりです。
[root@server ~]# cat /etc/redhat-release
CentOS Linux release 8.3.2011
カーネル版数は以下のとおりです。
[root@server ~]# uname -r
4.18.0-240.el8.x86_64
3 パッケージのインストール
まず、仮想マシンにAnacondaをインストールしました。
インストール方法は、Anacondaのインストール方法を参照してください。
次に、各種パッケージのアップデートを行いました。
(base) [root@server ~]# conda update conda
(base) [root@server ~]# conda install anaconda
(base) [root@server ~]# conda update --all
次に、tesseract(テッセラクト)をインストールしました。
tesseractは、OCRエンジン(光学式文字認識エンジン)です。
インストール方法は、https://anaconda.org/conda-forge/tesseractを参照ください。
(base) [root@server ~]# conda install -c conda-forge tesseract
最後に、pyocrをインストールしました。
pyocrは、PythonからOCRエンジンを利用可能にするためのモジュールです。
インストール方法は、https://anaconda.org/conda-forge/pyocrを参照ください。
(base) [root@server ~]# conda install -c conda-forge pyocr
4 PCのディスプレイで採取した画像ファイルから文字列の抽出
4.1 画像ファイルの作成
テスト用の画像ファイルを作成します。
ここでは、/var/log/messagesファイルの先頭30行をJPEGファイルとして保存します。
[root@server ~]# head -n 30 /var/log/messages
/var/log/messagesファイルの先頭30行のログを表示します。
そして、Ctrl+PrtScを押下して、画面のハードコピーを作成しました。
ペイントを使って、画面のハードコピーをJPEG形式で保存します。
ファイル名はsyslog.jpgとしました。
4.2 ソースコード
from PIL import Image
import pyocr
# OCRエンジンを取得
engines = pyocr.get_available_tools()
if len(engines) == 0:
print("OCR engine not found")
sys.exit(1)
engine = engines[0]
# 画像の文字を読み込む
txt = engine.image_to_string(Image.open('syslog.jpg'), lang="eng")
print(txt)
4.3 実行結果
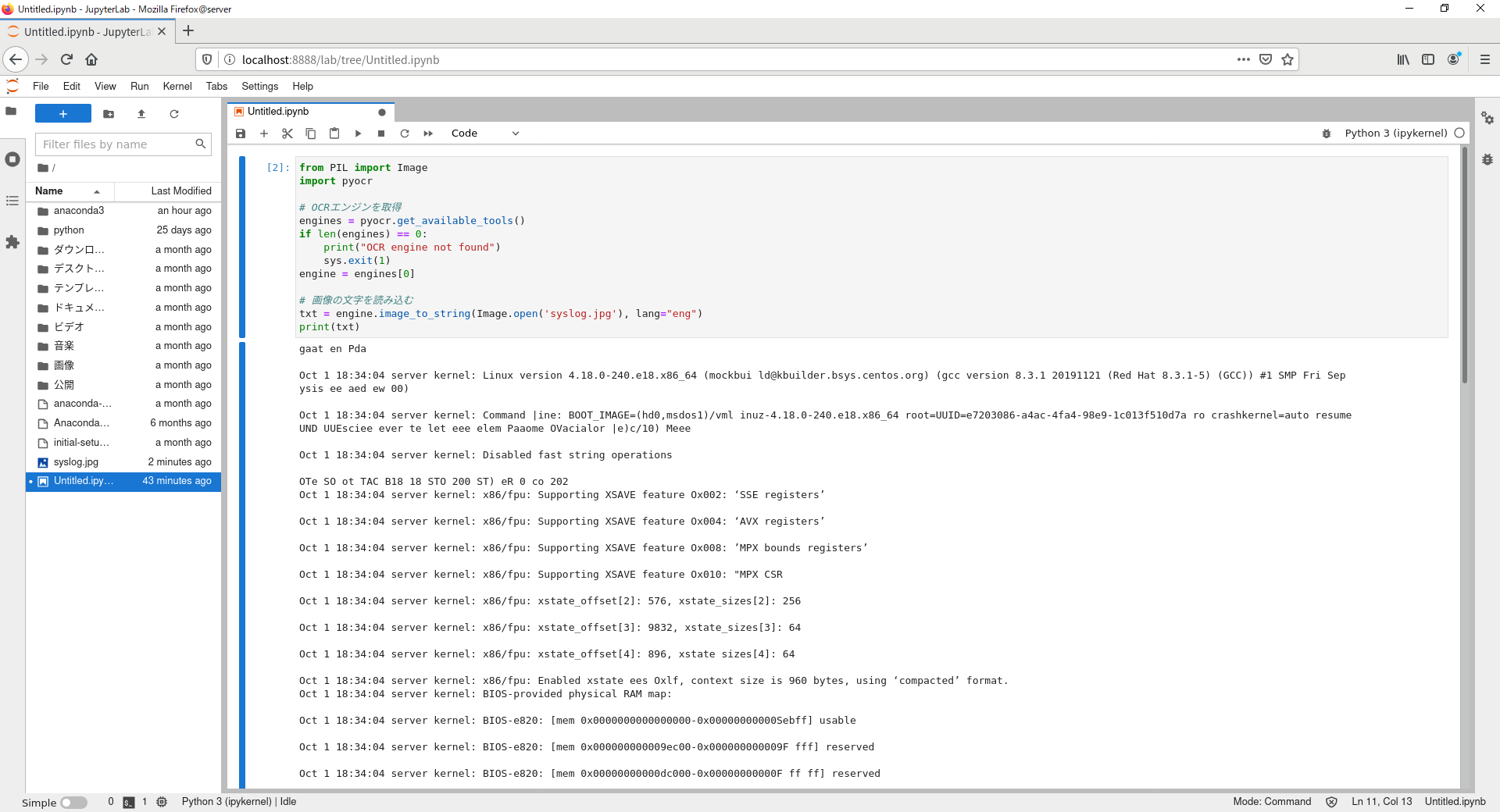
JupyterLabを使って、抽出結果を確認してみます。
詳細は確認していませんが、JPEGファイルからログを抽出できていることがわかります。
5 スマフォのカメラで撮影したJPEGファイルから文字列の抽出
5.1 JPEGファイルの作成
テスト用のJPEGファイルを作成します。
WikipediaのTransportationの部分をスマフォで撮影しました。
日本語がはいっていると変換できないので、英語だけの部分を撮影しました。
都合によりJPEGからPNGに変換したものを以下に示します。

5.2 ソースコード
from PIL import Image
from PIL import ImageEnhance
import pyocr
engines = pyocr.get_available_tools()
if len(engines) == 0:
print("OCR engine not found")
sys.exit(1)
engine = engines[0]
# JPEGファイルをオープンする
im = Image.open('IMG_20211110_213000.jpg')
# 画像を明瞭にする
im_enhanced = ImageEnhance.Brightness(im).enhance(2.0)
# 文字をグレースケール化する
im_gray=im_enhanced.convert(mode='L')
# 画像を180度回転する。
im_rotate = im_gray.rotate(180)
# JPEG形式で保存する。
im_rotate.save('test.jpg','jpeg', quality=80, optimize=True)
# JPEGファイルから文字を抽出する。
txt = engine.image_to_string(Image.open('test.jpg'), lang="eng")
print(txt)
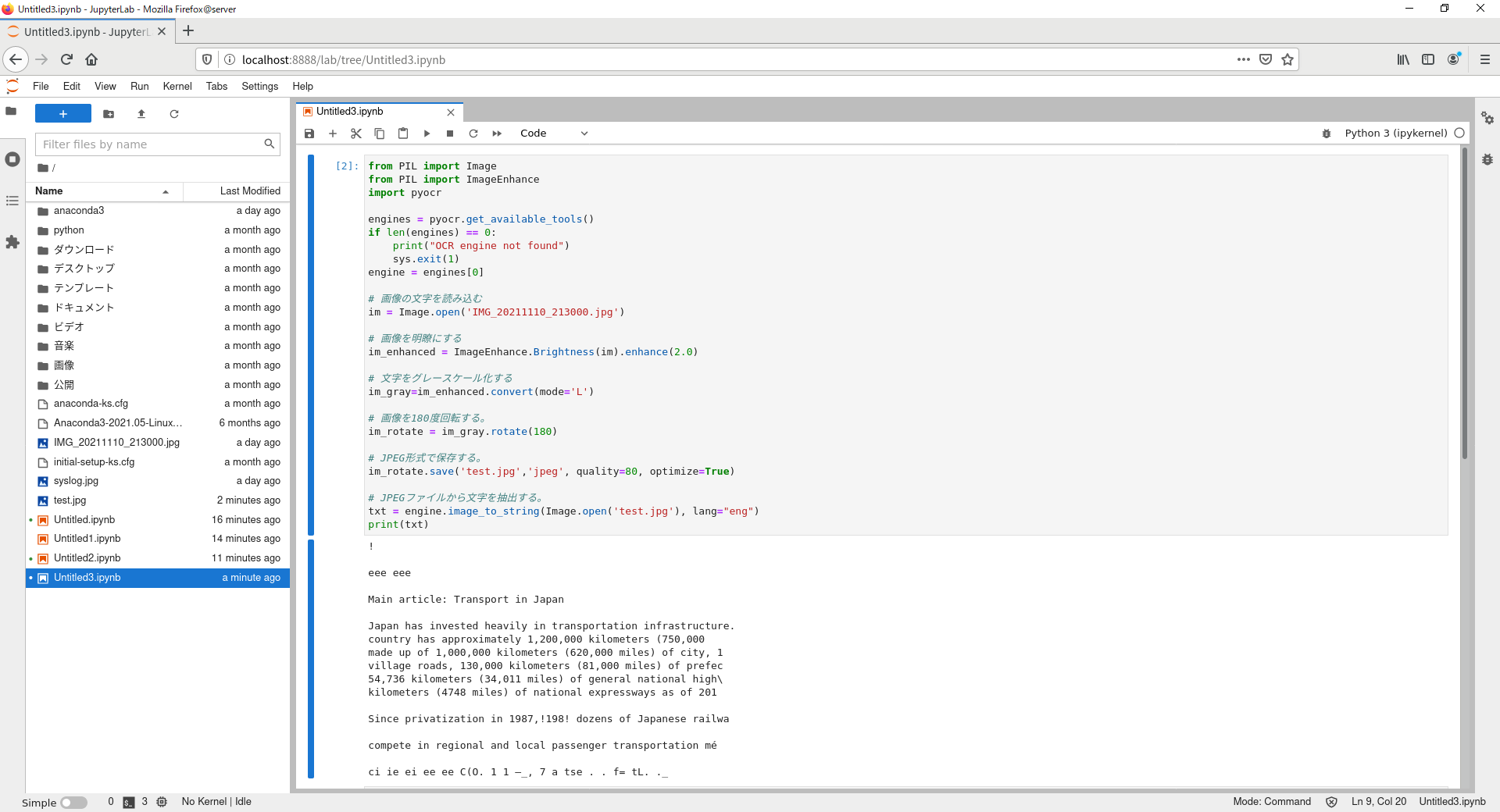
5.3 実行結果
こちらも詳細は確認していませんが、JPEGファイルから文字列が抽出できていることがわかります。
Z 参考情報
いちばんやさしいPython機械学習の教本 人気講師が教える業務で役立つ実践ノウハウ
■新規にパッケージを入れたい、あるいは更新したい場合にエラーになる場合
Pythonで書くTesseract 4の基本的な使い方。APIとCLIからOCRを実行する方法