データを蓄積し予測モデルを更新し続けるために、どういった機能を設計実装したか共有します。
2015年に遺伝的アルゴリズムで自動売買に挑戦したのが2年前。深層学習で再チャレンジして知見が溜まってきたので、運用における辛い話や設計を共有します。システムの話がメインです。

^ Flask x SQL alchemy で作りました。ワーカーはsupervisordです。最初Rubyからpycall使ってTensorFlow使ってたんですが PyCall.import_module を数回唱えたあたりで全部Pythonで書き換えました。デコレータ便利
伝えたかったこと
深層学習 株価予測 といったワードで調べるとそれなりの事例がすぐ見つかる世の中になりました。汎化能力を本当に有しているか疑問ですが例えばLSTMを使えば少しの情熱でバックテストでは利益が出る自動売買プログラムを開発できる時代です。ではそういった売買プログラムを長期運用するとどういった問題が起きるのか。データを蓄積し予測モデルを更新し評価するサイクルを回すためにどういった機能が必要になったか共有したいと思います。学習データを積み重ね予測モデルを更新し続けるニーズがある場合似た問題に遭遇すると思います。
学習済みモデル乱立問題
ニシローランドゴリラ(学名:Gorilla gorilla gorilla) は1000万年前にヒト族から続く系統と枝分かれして彼らはゴリラ属となりました。適切な学習を行った画像認識プログラムを用意すれば50年前の画像からでもヒトとゴリラの区別は付くでしょう。種の進化は相場の進化に比べ穏やかです。
自動売買プログラムの基となる学習済みモデルを作成するあたり、長期のマーケット変化に規則性はない、または進化し続けるため発見した規則性は必ず陳腐化するという考えから最高に精度がよく数年後も使い続けられる素晴らしい汎化能力を持ったモデルを作ることは諦めました。たとえ1ヶ月しか利益を出せなくとも今の相場にのみ汎化能力を持った、1年単位で見た場合は過剰適合で予測を外す学習済みモデルであっても適切にマネジメントすれば使い道はあると考えました。

学習済みモデルが大増殖した

学習済みモデルの大量運用ゆえの問題が発生
常に30前後の学習済みモデルを利用した自動売買プログラムが実行されます。うち何割かは手数料を差し引いても利益を出しています。残りはほぼヨコヨコで手数料でマイナスになるかすごい勢いで損失を出すパターン。定期的に前月の相場データを学習済みモデルが複数リリースしています。どう管理すれば利益が最大化するか考えました。
ライフサイクルを定義
今の相場にフィットせず損失を出し続けるモデルは速やかに退場させるため、みんな大好きステートマシンで学習済みモデルのライフサイクルを設計しました。ただ退場させた利益が出ないモデルが数年単位で見た場合は利益を出す場合もあるでしょう。1年分くらいデータが蓄積したらバックテストして楽しもうと思います。
肌感として利益を出すモデルは出し続け、いまの相場にフィットしていないモデルは高頻度取引ゆえに手数料でマイナスになっていくことが多いです。ゆえに成績が悪いモデルはわずか数日で引退するような急な傾斜で評価判定を回せるパラメータを設定しています。動的に売買ロット数を変化させることで負け続け資金を溶かすモデルからは速やかに資金を引き上げ、利益を出すモデルには資金を投下します。
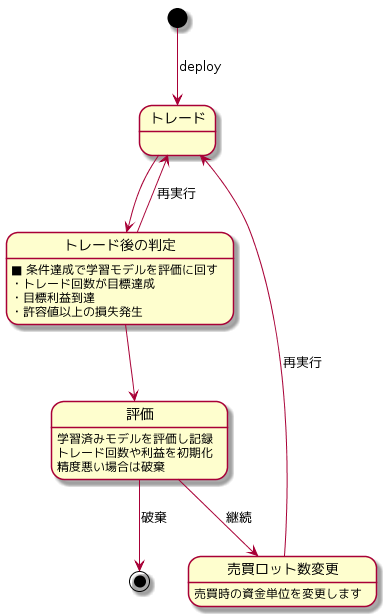
これは純粋にプログラミングの話になりますが、複雑な系を頭の中で考えて実装すると私の場合は100%手が止まったり、実装中に手戻りが発生します。少し手間が掛かっても事前に図にして可視化しておくようにしています。また図を眺めることで設計セルフレビューでバグを見つることも多いのでお勧めです。
売買ロットを動的に設定することで起きる問題
極端なパラメータ設定だと、5連勝で5 x 1000円利益でたが2周目に売買ロットを10倍にして1敗して10,000円負けました。といったことが発生します。モデルの評価は最小単位のロット数1での利益で評価しました。実際の利益がモデルの利益よりアンダーパフォーマンスにならないよう売買ロット変更ロジックは何度か試行錯誤して変更しました。ある程度運用を行ってデータが蓄積されてから最適化すると良い結果が出ました。
発注を最適化しないと手数料で死ぬ
学習済みモデルが10を超えたあたりから、モデル間での両建が目立ち始めます。20時にモデルAとBはEUR/USDを1ロット買い、10分後にモデルCがEUR/USDを1ロット売るなんて状態は日常茶飯事です。都度発注して手数料を払い続けるよりエントリータイミングを遅らせて丼発注で売買を相殺した方が利益が出るという判断から、発注管理ロジックを実装しました。
- 現在のポジションと、全てのモデルの発注を合計したポジションが1通貨単位(10kUSD)以上乖離したらスプレッドが拡大していない限り発注
- 深夜3時の相場が動かない時間帯に乖離ゼロにするよう発注
この発注最適化実装を入れると利益を損なう場合があるので、十分な吟味と導入後の有効性検証は頻繁に実施したほうがいいです。
発注最適化の副次的メリット
スリッページという単語をご存知でしょうか?発注価格と約定価格がズレる現象です。売買プログラムの発注と発注管理システムの発注を分離すると、スリッページにより想定より利益が出ない問題が解消しました。
自動売買システムの全体像
後付けで何個かは足したのでDBやクラス設計がガタガタになってて作り直したい感あるシステムです。各コンポーネントを疎結合にして非同期でワーカー化するとスケールしやすくて良い感じに運用できます。2度ほど発注管理ワーカーが死んで冷や汗が出たので監視worker作って緊急時はSlackで通知するようにしています。スマホへのPush通知はSlackApp利用すると便利ですね
付記
システムを運用し続けた感想として短期では規則性ある相場でも長期では規則性などなく、はるか未来まで見通す汎化能力を持った学習済みモデルを作成することは私にはできないという点です。古典になりますがフェラーのギャンブラーの破産問題 (Ruin problem)で論じられている通り勝率50%のときの破産確率と、2%不利な勝利48%での破産確率は大きな差があります。また破産確率を最小化させるにはBET価格の操作が有効であると知られています。
現実の取引は上記事例よりもはるかに複雑ですが、売買プログラムを資金管理システムと連携させることは容易です。平均発注数からレバレッジを計算し1日の最大損失を1万円以内にするといったことも精度高く実装できます。 ある程度勝率さえあれば破産せず打席に立ち続けることができる可能性が極めて高い点が自動売買を行う最大のメリットではないでしょうか。
さいごに
最終的に出来たものは1日数度取引してポジション調整するよく判らないシステムが完成しました。機械学習を利用した相場予測のコアロジックは部品に過ぎず、周辺の売買ロット管理や発注管理によって利益が大きく振れる点は興味深いです。最初のコンセプトだった、レンジ相場では逆張り、トレンド相場では順張りピラミッディング。節目では速やかに損切りして作戦変更。を何割かは実現出来たかなと思います。これからも運用を続けブラッシュアップしていこうと思います。最期までお付き合い頂きありがとうございました。