サーバーのログが全文検索可能かつ、処理単位で構造化されたログ表示の存在は便利で開発運用が捗ります。例えばサーバとクライアントで開発者が分離している場合、StackdriverのWebコンソールでHTTP Request Header, Request/Response Bodyの3点セットがログ全文検索可能になっているとクライアントE単独で調査できるようになるためクライアントEの開発も加速する場合があります。
Goで構造化ログを出力してWebサーバ開発を加速させる Go3 Advent Calendar 2019 10日目の記事です。9日目はuniさんのdive into iota: iotaはいつ誰が管理しているのか?記事でした。全文検索可能な構造化ログは便利になる反面ログ出力数がどうしても通常より多くなりすぎるため費用と便利さのトレードオフが発生します。本番環境で有効にするかは十分に吟味して検討するとよいでしょう。
GCP詳しい人向けの補足
GAE 1st gen時代に大変便利 だったカスタマイズされたStackdriverログ表示をCloudRunやその他GCPサービスでも同様に出力できるよう試行錯誤して再現した内容となっています。StackdriverからBigQuery export時にもGAE 1st gen同様親子関係を維持したまま同一BQテーブルに出力するよう調整しています。
サンプルアプリについて
ピンを刺したら裏でCloudRunで動作するGolang Serverに問い合わせGoogleMapから住所を応答して表示するサンプルアプリを用意しました。

開発が加速するログとは
1. リクエスト単位で構造化され全文検索可能なログ
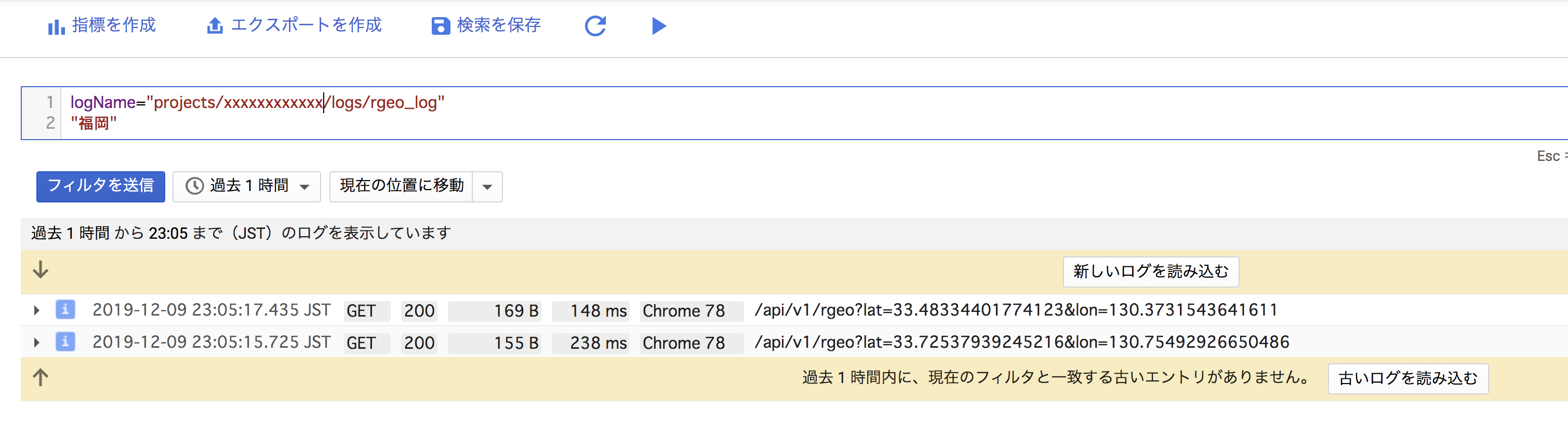
「福岡」を含むログを全文検索した例
高速に検索するにはindexが効くプロパティ指定が有効です。例: httpRequest.requestUrl:"/v1"
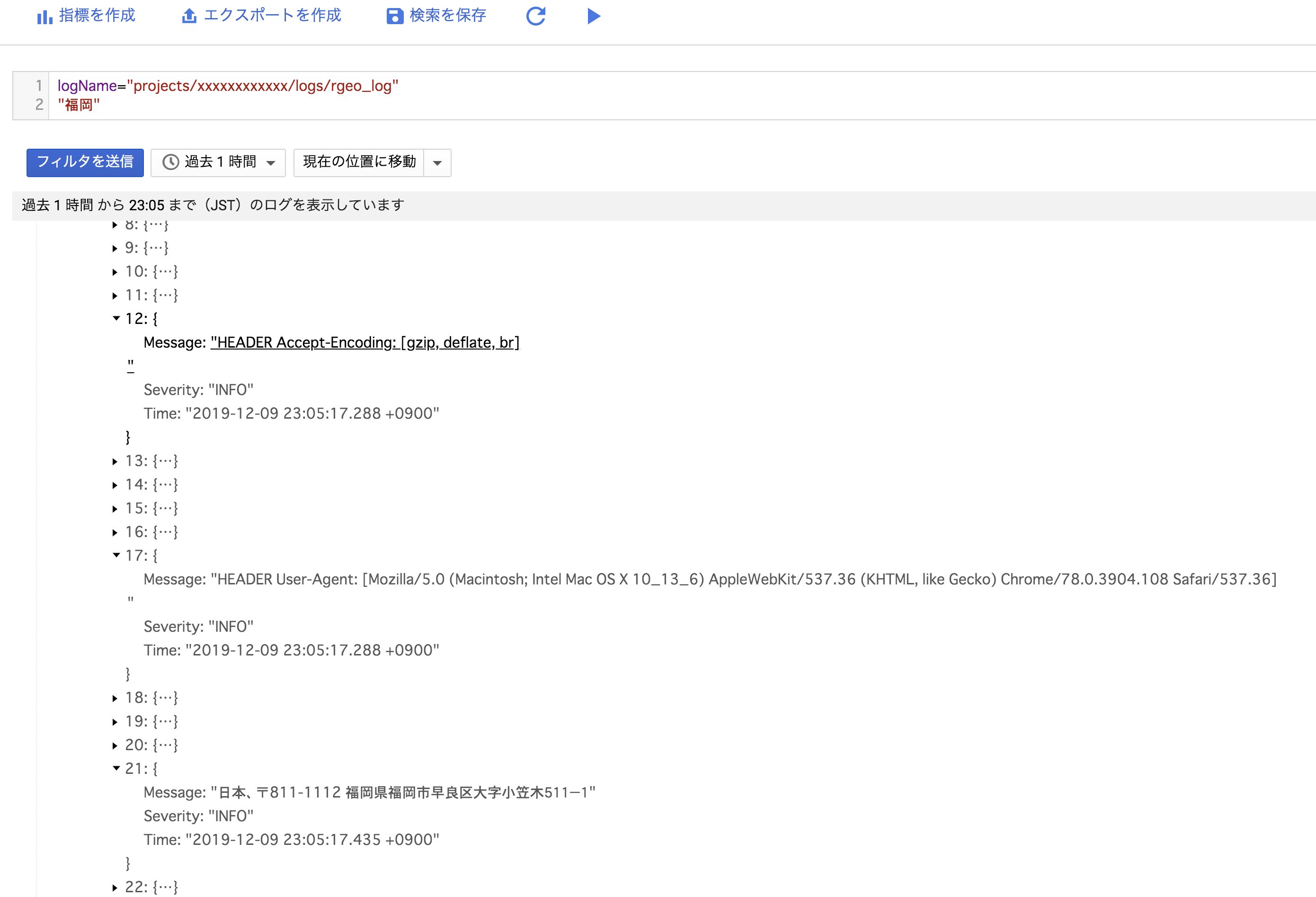
HTTPのリクエストごとに複数のログ出力が構造化されて記録されているため全文検索が可能になっています。またBigQuery Exportした際に、こちらの子ログが同じBQテーブルにまとめて出力されるためExport前提の場合は必須となります。
2. ネスト構造された親子関係でログ表示
1つのWeb通信ではTraceIDを共通でログ出力するとStackdriverが表示する際に自動でログを親子関係づけネスト表示します。TraceIDとはStackdriverでログ出力時に設定できるパラメータの1つとなります。
みづらい

みやすい(この表示を諦めるなら富豪的なログ出力実装は不要となります)
開発環境だけでも有効にすると、例えばログレベルがWarning以上のログが一目で視認できるようになるなど有効活用できます。
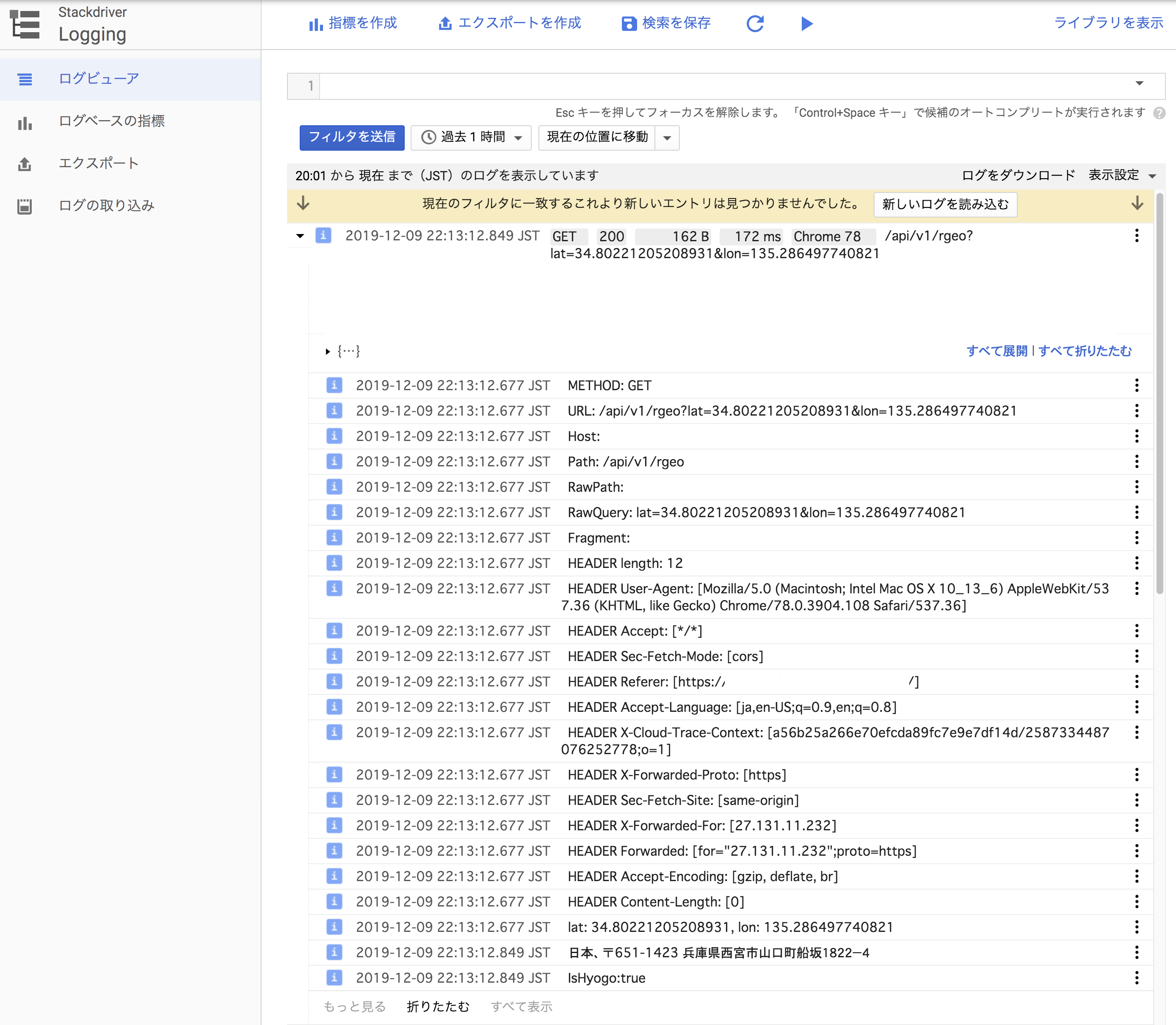
3. [option]HTTP Request HeaderとRequest/Response Bodyを全部ログ出力
WebAPI開発時に何かと調査が楽に便利になります。開発環境だけでも出力を検討しましょう。全てのWeb通信が通過するproxyサーバを用意するなどして、プロジェクトの通信を1箇所に集約して通信内容を全てログ出力し可視化するとエンジニアの開発手法もそれに依存するようになり少しだけよい変化が発生する場合があります。一方で本番環境で何でもかんでも出力していると 個人情報 がログに平文露出して記録されたり、容量から費用問題が発生するため工夫が必要です。
4. [option]ログをbig queryにexportして集計可能にしておく
Stackdriver Logの保持期間は30日です。消えてしまう前にStackdriver Export機能でBigQueryにアウトプットしておくと後追い調査で活躍する場合があります。
過去に活用した事例(障害や緊急対応ばかり!)
- あるAPIで特定の登録コードを障害発生期間に入力したユーザをすべて調べる
- 特定OSの特定バージョンでとあるボタンを押したユーザ数を通信ログからUserAgentで絞ってすべて調べる
- あるエラーが発生した回数を日別で集計して発生頻度が急増した日時を特定する
5. [option]Stackdriver Monitoring連携で異常時のSlack通知を準備する
本番運用が始まるとエラー時に即応しサービスを継続する必要があります。理想は発生させないこと、もしくはユーザ様が気付く前に検知して対処できるのが理想です。また開発規模が拡大すると開発環境やQA環境の停止すらも大きな損失が発生するようになります。Stackdriver Monitoring連携で簡単に各種サービスと通知連携できるため、そういったサービスが存在する点を覚えていると役に立つ日がくるかもしれません。通知オプション | Stackdriver Monitoring
Stackdriver Loggingの要点を2つだけ抑える
Stackdriver Logging仕様に特化したデータ構造を理解しないと、実装をみても理解しにくいため先に説明します。逆にデータ構造さえ理解すれば自由自在です。
1. ログの全文検索 と 構造化されたログを実現する
省略した擬似実装で説明します。 cloud.google.com/go/logging 前提の話です。logging.Entry.Payloadに encoding/json でJSON出力可能なarrayを設定すると実現します。1回のログ出力で構造化したJSONを出力するため、WEBコンソールで全文検索が実現します。詳細はEntry構造体の特にPayloadのコメントを読むとよいでしょう。
// 出力するログをencoding/json でJSON出力できるように設定
// lineはログごとの構造体
type line struct {
Severity logging.Severity
Payload string
Time time.Time
}
func (l *line) toLog() interface{} {
return struct {
Severity string
Message string
Time string
}{
Severity: string(l.Severity), // todo: logging.Severityはint型なのでstring型への置き換え実装を推奨(今回は省略)
Message: l.Payload,
Time: l.Time.Format("2006-01-02 15:04:05.000 -0700"),
}
}
func main() {
// ログ文字列をサンプルで設定(実際はInfoF関数などなどで設定)
lines := []line{
{logging.Debug, "Debug出力ログ", time.Now()},
{logging.Info, "Info出力ログ", time.Now()},
{logging.Warning, "Warning出力ログ", time.Now()},
{logging.Error, "Error出力ログ", time.Now()},
}
// jsonPayload.lines を生成
// Stackdriver Logging で検索した際にjsonPayload.linesに全てのログ文字列が存在するため検索文字列で該当の通信ログが見つかる。
var payload = struct {
Lines []interface{}
}{}
maxSeverity := logging.Info
for _, line := range lines {
if maxSeverity < line.Severity {
maxSeverity = line.Severity // 出力したlogから一番logレベルが高いものを親のlogレベルと設定
}
payload.Lines = append(payload.Lines, line.toLog())
}
// ログ出力
entry := logging.Entry{
HTTPRequest: logHTTPRequest, // r *http.Request を設定
Trace: TraceID(r),
Severity: maxSeverity,
Payload: payload,
}
parentLogger.Log(entry)
parentLogger.Flush() // バッファされているログをすべて送信
}
2.ネストされた親子関係のログ出力
子ログを大量に出力する実装を行います。Stackdriver LoggingのWebコンソールで親子関係としてログ出力するために、 TraceIDを親子共通にして 1行ずつ子ログを出力します。詳細はGoDoc Grouping Logs by Request ¶ や GAE のログに憧れての記事が詳しいです。
// ネストされた親子関係でログ表示するために子ログを出力するサンプル
func main() {
// log init
logClient, _ := logging.NewClient(context.Background(), googleCloudProject)
parentLogger := logClient.Logger( // 親ログ
"your_service_log",
logging.CommonResource(&monitoredres.MonitoredResource{
Type: logType,
Labels: map[string]string{
"project_id": googleCloudProject,
},
}),
)
childLogger := logClient.Logger("child_log") // 子ログ
// 子ログ出力(実際の出力は親ログの Flush() 時に出力される)
line := line{logging.Debug, "Debug出力ログ", time.Now()}
childLogger.Log(logging.Entry{
Severity: line.Severity,
Payload: map[string]interface{}{
"serviceContext": map[string]interface{}{},
"message": line.Payload,
},
Resource: &monitoredres.MonitoredResource{
Type: logType,
Labels: map[string]string{
"project_id": googleCloudProject,
},
},
Trace: TraceID(r),
})
}
所感
オンプレサーバに溜まったログをtailで監視していた時代から、クラウド時代になりログにも変化の波が訪れつつあります。ログを徹底的に可視化しプロジェクト内に布教成功すると開発者の開発スタイルにも少しだけ変化がおきます。それがよい変化ならきっと別プロジェクト移動時に真似してくれることでしょう。私にとってGAE 1st genのログ出力の完成度は衝撃的で、CloudRun導入時に思わず真似してしまいました。一方でStackdriverはlocal emulatorが存在しておらず、開発は試行錯誤が必要になります。この記事が少しでも助けになれば嬉しいです。最後まで読んで頂きましてありがとうございました。