本記事は MIXI DEVELOPERS Advent Calendar 2022 の4日目の記事です。
TL;DR
- Romi チームでは自然言語処理をメインでやりつつ、最近は音声系も手を出しつつあるよ
- 2022年末現在の音声認識最強モデル Whisper を高速化
- 重みの fp16 化
- TorchScript 化
- 認識の長さを30秒ごとから10秒ごとに
- 結果処理速度が約2倍に
- ソースコード: https://github.com/projectlucas/efficient_whisper
- 実験結果: https://github.com/projectlucas/efficient_whisper/blob/main/notebooks/efficient_whisper.ipynb
はじめに

こんにちは株式会社 MIXI Romi 事業部 Engineering Manager の halhorn こと信田です。
我々が開発している会話 AI ロボット Romi は、雑談会話をするロボットです。
Romi は、音声で人の声を聞き取り、その後 音声認識 -> 会話エンジン -> 音声合成 と処理を行うことで音声での会話を行います。
これまで Romi の開発は、会話の内容を text-to-text で考える会話エンジンを中心に行ってきました。
ですが音声認識の精度やコスト面での課題もあり、最近は将来に向けて音声認識・音声合成の内製化の検討も始めています。
音声合成の世界で今期待が大きいのが Whisper というモデルで、 Romi チームでも試してみたところなかなか高い精度が出ています。
そんな Whisper をチームメンバーが高速化した話を書きます。
Whisper とは
Whisper は OpenAI が2022年9月に発表した音声認識モデルです。
最近の音声認識は wav2vec 2.0 など大量の音声データのみから自己教師あり学習を行った後に、音声と書き起こし文からの音声認識モデルの学習を行うのが主流でした。
一方の Whisper は680,000時間という大量の多言語・マルチタスクの教師データを用いて学習された教師あり学習のモデルです。
モデルの構造自体は下図のように Encoder - Decoder からなる Transformer 基本としています。
(Transformer について知りたい方は大昔書いた 作って理解する Transformer / Attention なども見てみてください)
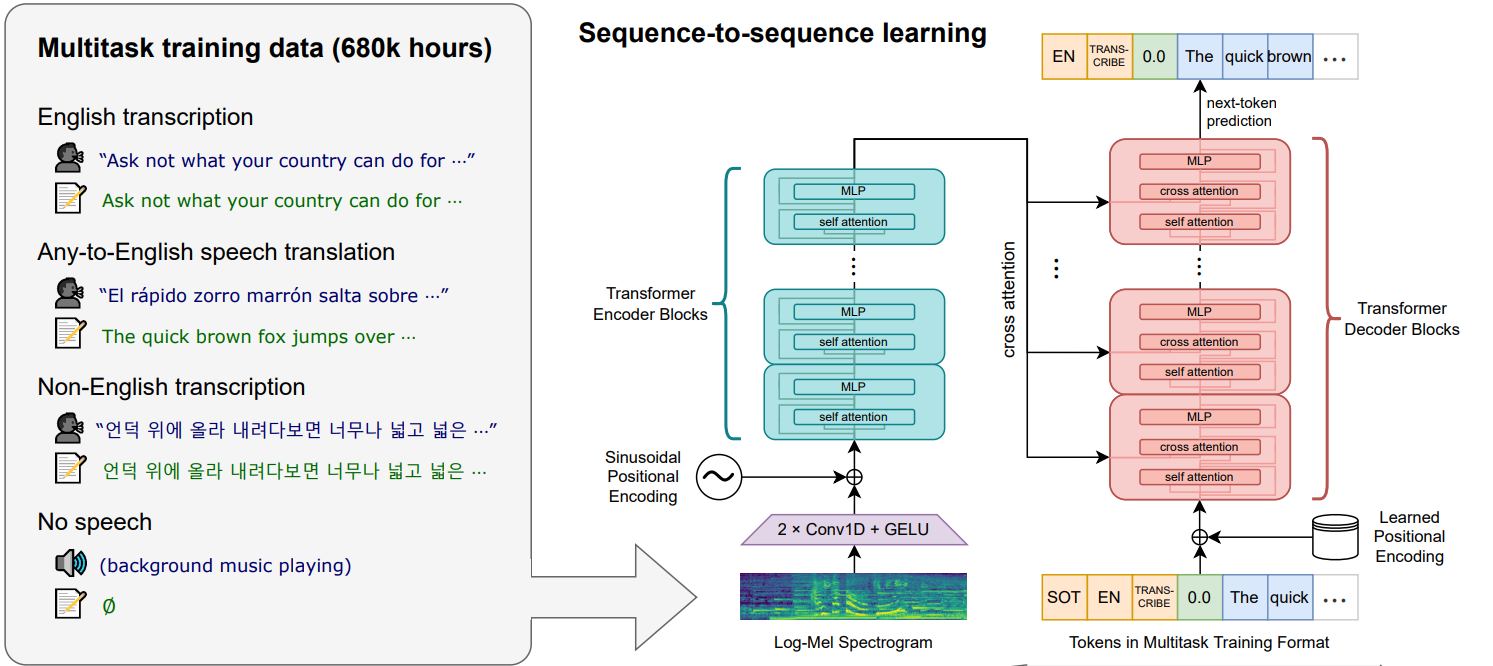
(画像は OpenAI Robust Speech Recognition via Large-Scale Weak Supervision より引用)
Encoder へは音声を入力し、 self attention によって音声の特徴量を作成します。
Decoder は、特殊トークン及びテキストのトークンと、 Encoder の特徴量を cross attention して、次のトークンを予測します。
学習を行うタスクは
- 英語音声の書き起こし
- 英語以外の言語の音声を聞き取り、英語で書き起こす
- 英語以外の言語の書き起こし
- 音声が存在するかの判定
など多岐にわたります。
英語以外の言語の書き起こしタスクも学習しているため、発表されたモデルで日本語の音声認識も可能です。
Whisper を高速化した話
「はじめに」でもふれたとおり、 Romi チームでは将来的に音声認識の内製化も検討しています。その中で Whisper は有力な候補の一つです。
そんな Whisper に対して、 Romi 事業部のスーパー機械学習エンジニア dguoy が推論の高速化に挑戦してくれました。
高速化のアイディアは次の3つです。
- 重みの fp16 化
- TorchScript を使うことによる高速化
- もともと音声を30秒ごとに処理するのを10秒ごとに処理することによる高速化
以下ではそれぞれ詳しく説明していきます。
重みの fp16 化
Whisper 自体は変更しませんが、呼び出し方を変え、重みも fp16 で演算することによって若干の高速化と省メモリ化を行います。
https://github.com/projectlucas/efficient_whisper/blob/main/notebooks/efficient_whisper.ipynb
Whisper の model.transcribe で fp16=True にすることにより、流れるデータは主に fp16 で計算されます。
model = whisper.load_model("large")
model.transcribe(
audio_data,
verbose=True,
language='japanese',
beam_size=5,
fp16=True,
without_timestamps=True
)
が、上記のコードでは重みは fp32 のままです。
重みも fp16 にするために以下のように model.half() を行います。
import whisper
model = whisper.load_model("large", device="cpu")
_ = model.half()
_ = model.cuda()
# exception without following code
# reason : model.py -> line 31 -> super().forward(x.float()).type(x.dtype)
for m in model.modules():
if isinstance(m, whisper.model.LayerNorm):
m.float()
いくつか解説ポイントがあります
-
device="cpu": GPU の無駄遣いを抑制(最終的にモデルは GPU に配置されます)- load_model を読むと、 device="cuda" の場合 GPU に重み情報を配置し、その後モデルにその重みをロードしてからモデル自体を GPU に配置しています。
- つまり、重みだけとモデルそのものと二重に重みが GPU に読み込まれてしまうようです。
- これを回避するため、
device="cpu"を指定して、重みを CPU に読み込みます。 - その代わり後で
model.cuda()することでモデルを GPU に配置します。
-
model.half()- ここでモデルの重みを fp16 に変換しています
-
for m in model.modules():- LayerNorm の中で入力された Tensor x を float つまり fp32 に変換してから forward に入力しています。
- 重みが fp16 になると型が合わず例外が発生します。
- これを防ぐため、 LayerNorm の重みだけは fp32 にしています。
上記によって、かなりメモリの節約になります。
結果
短い音声10個を音声認識するのにかかった時間を計測します。
もともと 13.6s かかっていたのが 12.5s まで高速化されました。
TorchScript 化
TorchScript とは
PyTorch は define-by-run つまり、モデルの実行時にモデルのグラフを構築します。
この方式はデバッグのしやすさなどのメリットがありますが、事前にモデルのグラフを構築しておく define-and-run より速度面で劣ります。
PyTorch で作ったモデルを TorchScript 化することにより define-and-run でモデルを動かすことが可能になり、モデルの推論を高速化することができます。
差分と工夫点
そんな便利な TorchScript ですが、どんなモデルでも使えるわけでは無く、静的に型付けされた python のサブセットである TorchScript Language で書かかれたモデルでしか使えません。
(詳しくは/厳密には TorchScript入門 n番煎じ や TORCHSCRIPT LANGUAGE REFERENCE を読んでください)
以下ではもともとのコードで TorchScript 化できない部分とその対応の一部を解説します。
- dict を渡すことはできない
- 差分
- self.kv_cache が dict なので分解して Tensor にする
- TorchScript は hook をサポートしていない
- 差分
- hook でキャッシュの更新をしている
- モデルが各キャッシュを return するように
- 独自で実装している LayerNorm, Liner, Conv1d などが TorchScript で動かない
- 差分
- 三項演算や/None (Optional) などが入ってくると TorchScript で動かないことがある
- PyTorch 公式のレイヤーに置換
- MultiHeadAttention などが動かない
- 差分
- self-attention か corss-attention かを xa の値が None かなどで分岐しているが、この分岐周りも動かない
- self-attention 用と cross-attention 用でクラスを分離
上記が全てではありませんが、 TorchScript 化可能なようにコードを修正し、 TorchScript 化することで高速化をおこないます。
結果
https://github.com/projectlucas/efficient_whisper/blob/main/notebooks/efficient_whisper.ipynb
更に 12.5s が 8.59s まで短縮されました!
認識の長さを30秒ごとから10秒ごとに
Whisper では音声を30秒ごとに区切って処理を行います。
もし音声が5秒しかない場合、残りの25秒分はパディングされます。コード
このような場合たった5秒の計算のために30秒分の大きな Tensor で計算をすることになり計算量が無駄です。
会話 AI ロボット Romi は雑談対話をするロボットであり、ユーザーの1発話はおよそ10秒以内であることが多いです。
したがって、30秒ごとの音声ではなく10秒ごとの音声にすることによって、短い音声に関して処理速度を上げることが可能です。
結果
更に 8.59s が 6.77s まで短縮されました。
これでもともとの時間の 49.8% の時間で推論が可能になりました。ほぼ倍速ですね!
ただ、認識の長さ変更は結果に微妙な影響を及ぼします。
[00:00.000 --> 00:30.000] 予想外の事態に電力会社がちょっぴり困惑切りだ
[00:00.000 --> 00:30.000] 町域にあった峰山藩は長岡藩に米100票を送ったことで有名。
[00:00.000 --> 00:30.000] 週末 友達と山に登ります
[00:00.000 --> 00:30.000] 後で図書館へ本を返しに行きます。
[00:00.000 --> 00:30.000] 55歳だって嬉しい時が嬉しいのだ
[00:00.000 --> 00:30.000] 私はパンもご飯も好きです。
[00:00.000 --> 00:30.000] デパートやスーパーで買い物をします
[00:00.000 --> 00:30.000] 用紙に書いてある番号を覚えます。
[00:00.000 --> 00:30.000] 明日 友達と 映画を 見に行きます。
[00:00.000 --> 00:30.000] あの男の人は背が高くて足が長いです。
[00:00.000 --> 00:10.000] 予想外の事態に電力会社がちょっぴり手を巻く気味が
[00:00.000 --> 00:10.000] 町域にあった峰山藩は、長岡藩に米100票を送ったことで有名。
[00:00.000 --> 00:10.000] 週末友達と山に登ります。
[00:00.000 --> 00:10.000] 後で図書館へ本を返しに行きます。
[00:00.000 --> 00:10.000] 55歳だって嬉しい時が嬉しいのだ
[00:00.000 --> 00:10.000] 私はパンもご飯も好きです。
[00:00.000 --> 00:10.000] デパートやスーパーで買い物をします。
[00:00.000 --> 00:10.000] 用紙に書いてある番号を覚えます。
[00:00.000 --> 00:10.000] 明日、友達と映画を見に行きます。
[00:00.000 --> 00:10.000] あの男の人は背が高くて足が長いです。
1文目の末尾が誤っていたり、3文目にスペースが含まれるかがことなったり、その他句読点周りが微妙に変わったりします。
今回はサンプル数が10と少ないので、この変更によりどの程度精度が変わるのかは検証できていませんが、精度に関して何らかの影響はあるかもしれません。
このあたりはどの程度の長さの音声が来るかなどサービスのドメインによって最適な値がかわりそうです。
速度計測の環境
速度の計測は GCP 上のサーバーで行っています。
- GPU: V100
- CUDA: 11.2
- PyTorch: 1.11.0+cu113
また、速度計測は最初の1回は諸々時間がかかるので、一度10文を音声認識後、もう一回10文を音声認識するときにかかる時間を計測しています。
おわりに
音声認識モデル Whisper に3つの工夫を行うことで、推論を1文あたり平均 1.36s から 0.667s へとほぼ倍速に高速化することができました。
今回は音声に関する記事でしたが、 「はじめに」でも触れたとおり、 Romi チームでは主に自然言語処理の分野で Deep Learning を使っています。
研究系人材の採用も行っていますので、会話ロボットを作りたい人はぜひお話しましょう。
https://www.wantedly.com/projects/92981