mizti さんの AWS Step FunctionsとLambdaでディープラーニングの訓練を全自動化する を自分の求めるものに従って微修正したものです。
背景
- AWS の高性能 GPU マシン、 p2 インスタンスで DeepLearning (TensorFlow) の学習を回したい
- でも p2 は高い!!
- スポットインスタンスを使うと安い!
- しかしスポットインスタンスは実行中に入札額によって強制シャットダウンされる
- 学習中データを定期的に S3 にアップロードしたい
- スポットインスタンスを立ち上げて学習開始するのを自動化したい
- しかしスポットインスタンスは実行中に入札額によって強制シャットダウンされる
- 学習完了時に勝手にインスタンスをシャットダウンしたい
- スポットインスタンスを使うと安い!
仕様
- 学習開始の Slack 通知
- データ格納先の S3 のチェック
- bucket は存在するか?
- 既に学習結果格納ディレクトリが無いか?(上書きしないようチェック)
- スポットインスタンスへの入札と、結果の Slack 通知
- インスタンス上でのデータダウンロードと学習(もしくは任意のタスク)実行
- 学習完了後の Slack 通知とインスタンス削除
を勝手にやってくれます。
AWS StepFuncion と AWS Lambda を使います。

データの取得方法や、学習を実行するコマンドは Step Function に引数として json 文字列で与えるため、 DeepLearning の学習に限らず、時間がかかり成果物をファイルとして出力するようなタスクに対し汎用的に使えます。
{
"exec_name": "test1", // 実行名。結果格納ディレクトリ名。
"bucket_name": "your-output-bucket-name", // 結果を格納するバケット名
"repository_url": "https://github.com/hoge/fuga.git", // 学習用のプログラムが入ったリポジトリ
"repository_name": "fuga", // リポジトリ名
"data_dir": "fuga/data/", // ローカルでの学習データの格納場所
"output_dir": "fuga/output", // ローカルでの学習結果の格納場所
"data_get_command": "aws s3 cp s3://your-data-bucket-name/hoge/fuga.data fuga/data/",
// S3 等からのデータの取得コマンド
"exec_command": "python fuga/train.py", // 学習実行のコマンド
"ami_id" : "ami-111111", // 起動するインスタンスの AMI ID
"instance_type" : "p2.xlarge", // 起動するインスタンスのタイプ
"spot_price" : "7.2" // スポットリクエストの最高金額
}
mizti さんのものとの差分
上記のものは mizti さんの AWS Step FunctionsとLambdaでディープラーニングの訓練を全自動化する で実現されていますが、真似て作ってみたあとで自分で以下のカスタマイズをしました。
- 通知をプッシュではなく Slack に
- 全般的なエラー発生時にも Slack に通知する
- スポットインスタンスの入札が完了するまでループして待機する
- 一つの S3 バケット内に複数の学習結果を格納していく
- 学習完了後、即座にインスタンスを破棄する
自動化
全体的な説明
AWS Lambda を使って、 S3 のチェック、 EC2 のスポットリクエストの送信〜学習の開始、 Slack への通知等個別のタスクを実装します。
それらを AWS Step Function を使ってつなぎ合わせ、自動化を実現します。
下準備
学習用のインスタンスの AMI を作成する
p2 インスタンスへの TensorFlow 導入 のとおり TensorFlow を実行するための AMI を作成します。
Lambda 用ロールの作成
lambda から S3 の状態をチェックしたり、 EC2 のスポットフリートリクエストを送信したりするため、それらを行うロールを作ります。
lambda-training という名前で作るとします。
以下のようなポリシーをアタッチします。
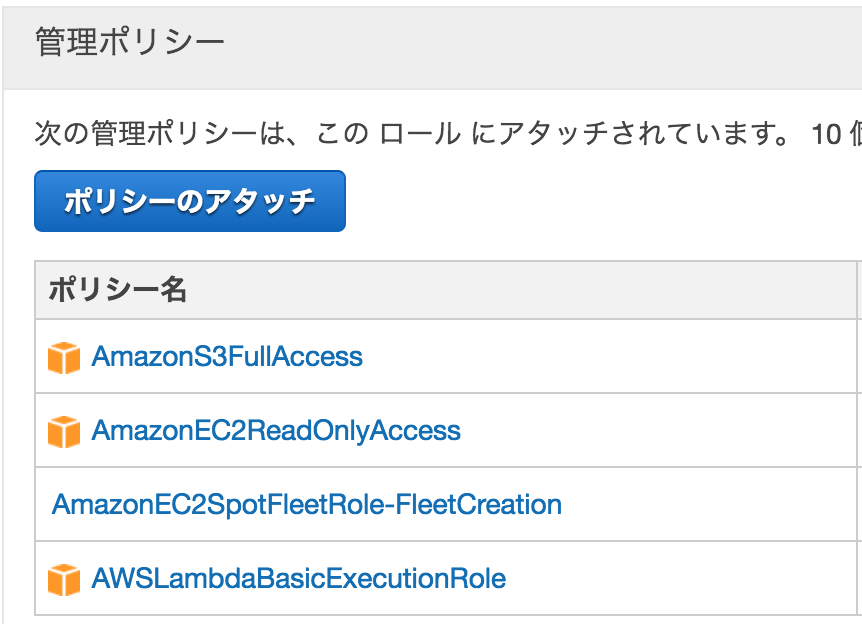
ここで AmazonEC2SpotFleetRole-FleetCreation はスポットフリートを作成するためのポリシーで以下の様なものを自分で作りました。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"ec2:DescribeImages",
"ec2:DescribeSubnets",
"ec2:RequestSpotInstances",
"ec2:RequestSpotFleet",
"ec2:TerminateInstances",
"ec2:DescribeInstanceStatus",
"iam:PassRole"
],
"Resource": [
"*"
]
}
]
}
このあたりは各サービスごとのセキュリティのポリシーに合わせてより権限を絞ったほうが良いと思います。
信頼関係は lambda を指定しておきます。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
タスク実行用の EC2 用のロールの作成
学習を行う EC2 はデータを S3 等からダウンロード/アップロードする必要があるため、それらの権限を与えるロールを作成します。
ec2-deep-learning という名前で作るとします。
管理ポリシーに AmazonS3FullAccess 等を追加しておきます。
信頼関係は EC2 を設定しておきます。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "ec2.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
スポットフリートロールの作成
これは一度でも AWS Console からスポットリクエストを送ったことがあればその際に作られている気がします。
AmazonEC2SpotFleetRole ポリシーをアタッチされ、spotfleet.amazonaws.com に信頼関係を持ったロールです。
aws-ec2-spot-fleet-role という名前になっているとします。
暗号化キーを作成
Slack の WebHook URL などもろもろの情報を暗号化するため、 AWS の暗号化キーを作ります。
- IAM の左メニューの暗号化キーを選択
- リージョンを EC2 と同じものを選択(重要)
- キーの作成をクリック
 画像は既に作成済みのものです。
画像は既に作成済みのものです。
以下のようにして作っていきます。
- alias: lambda-training 等
- キー管理者: 管理権限をもたせたいユーザーを適当に(この作業をしている自分等)
- キーユーザー: 先程作った lambda-training ロールにチェックを入れます
これによって、 lambda-training ロールで実行されている AWS Lambda が暗号化・復号化をできるようになります。
lambda-training ロールが lambda-training 鍵を使えるようにする
名前が同じでややこしいですが、ロールの方にも設定を追加して鍵を使えるようにします。
ロールの方の lambda-training のインラインポリシーで以下を追加してください。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "lambdakms",
"Effect": "Allow",
"Action": [
"kms:Decrypt"
],
"Resource": [
"arn:aws:kms:us-west-2:111111111:key/1111-1111-1111"
]
}
]
}
Resource の部分は lambda-training 鍵の arn を指定してください。
AWS Lambda の実装
AWS Console 上で Lambda function を実装していきます。
halhorn が使っている lambda や step function は https://github.com/halhorn/AWSAutoLearning においてありますのでそちらを基本的に参照してください。最後の .py は不要です。
(殆どのコードはオリジナルの mizti さんのものを使わさせていただいております。)

AWS Lambda 内での AWS の操作には boto3 を使います。
困った時や拡張したいときには Boto3 - EC2 や Boto3 - S3 を読むと良いでしょう。
Lambda は lambda_handler をエントリーポイントとして実行され、 json で与えた引数が event 変数の中に入った状態で実行されます。
また、 event を最後 return することで、その内容を step function で定義された次の lambda に伝えることができます。
作成した lambda は適当な json を引数にしてテストを行い、動作確認を行うのが大事です。

ここでは特に注意を要する模についてのみ説明をします。
request_spot_fleet
スポットフリートのリクエストを行い、インスタンスが立ち上がったら学習用のコードを実行するための Lambda です。
FLEET_ROLE や EC2_ROLE など定数部分を適切に設定してください。
KEY_NAME はインスタンス作成時に使っているキーペア名を指定してください。
EC2 起動時の処理
create_user_data 内を編集することで、 EC2 が立ち上がった後の学習実行用のコマンドをよしなに変えることができます。
このコマンドは root ユーザーで行われます。その為逐一 sudo -u ubuntu ** としています。
また sudo -u ubuntu -i COMMAND とすることで .zshenv なども読み込まれた状態でコマンドを実行できます。が、これはカレントディレクトリが ubuntu のホームになった状態で実行されるので注意してください。また、私の環境では .zshrc は読み込まれませんでした。
やっていることは以下のようなことです。
- 定期的に学習結果諸々を S3 に UP する cron の作成
- データの取得
- 学習の実行
-
complete.logという学習完了フラグとなるファイルの作成- これが S3 に UP されることによって、 Lambda は学習の完了を知る仕組みです。
テスト
以下のような引数でテストすることになると思います。
{
"exec_name": "test1",
"bucket_name": "your-output-bucket-name",
"repository_url": "https://github.com/hoge/fuga.git",
"repository_name": "fuga",
"data_dir": "fuga/data/",
"output_dir": "fuga/output",
"data_get_command": "aws s3 cp s3://your-data-bucket-name/hoge/fuga.data fuga/data/",
"exec_command": "python fuga/train.py",
"ami_id" : "ami-111111",
"instance_type" : "p2.xlarge",
"spot_price" : "7.2"
}
ディレクトリはホームディレクトリにいて、そこで git clone した前提で書いてください。
フルパスで書く場合 /home/ubuntu/fuga/... 等となります。
send_notification / send_error_notification
作業の進捗その他を Slack に通知します。
まず、事前に InCommingWebHook を Slack から取得してください。こんな感じで。
次に Webhook をそのままべた書きするのはセキュリティ上よろしくないので、暗号化した上で環境変数に埋め込みます。
コードの下部に環境変数を埋め込む場所があるのでここで slackChannel と kmsEncryptedHookUrl を設定してください。**ただし、urlの方はhttps://を抜いて下さい**。また、この際に「暗号化ヘルパーを有効にする」にチェックを入れてください。
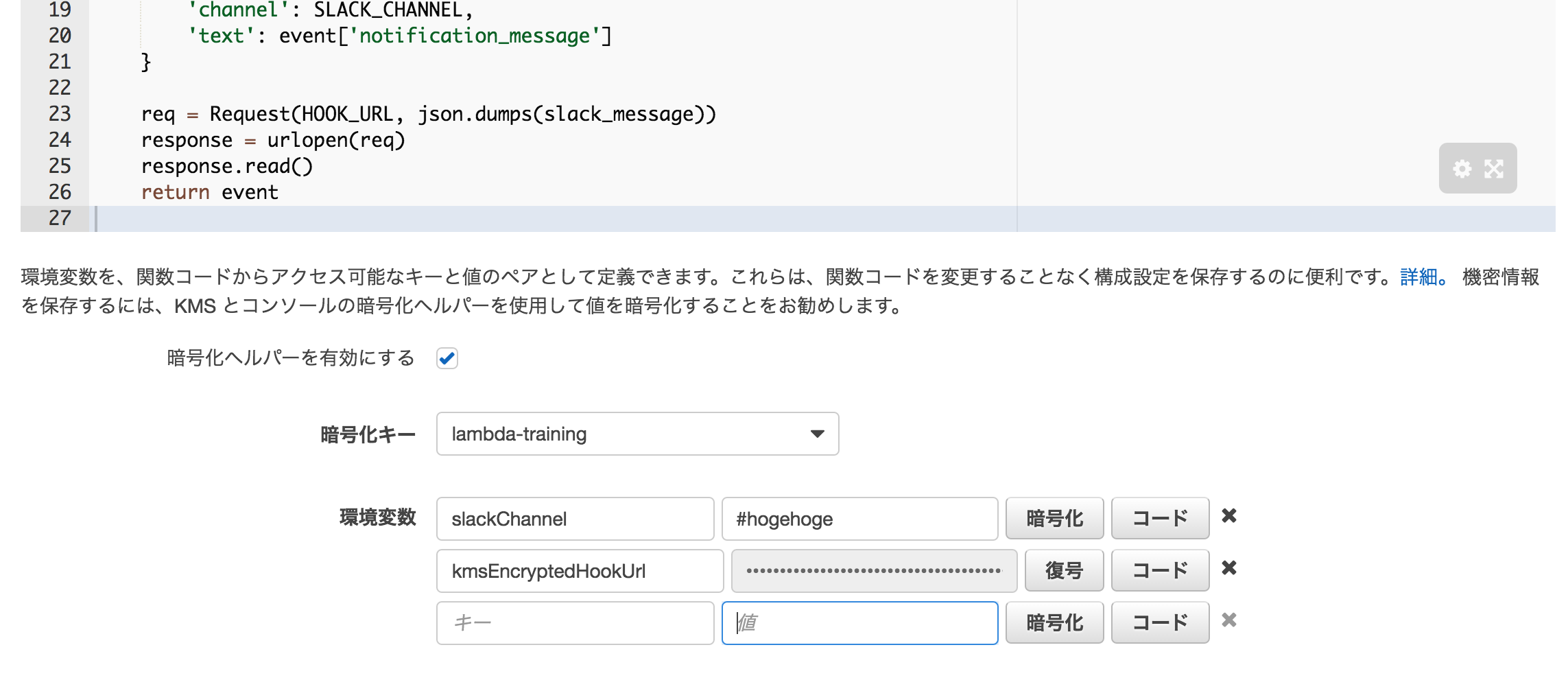
暗号化キーは、以前作った「lambda-training」を指定してください。もしここで lambda-training が現れない場合、キーを作るリージョンを間違えているか、ロールの設定が間違っていると思います。
あとは暗号化、をクリックして、 kmsEncryptedHookUrl のみ暗号化します。
AWS Step Function の実装
個別の Lambda ができたら、それらをつなぎ合わせる Step Function を実装します。
これは json で記述され、タスクの種類、実行内容、次に何をするか、等から構成されます。

Create a State Machine から作成します。
一度作ると編集ができない残念仕様な気がします。。
動かす
個別の Lambda をテストでちゃんと確認していれば、 StepFunction は普通に動いてくれるはずです。
以下のような雰囲気のデータで実行してみましょう。
{
"exec_name": "test1",
"bucket_name": "your-output-bucket-name",
"repository_url": "https://github.com/hoge/fuga.git",
"repository_name": "fuga",
"data_dir": "fuga/data/",
"output_dir": "fuga/output",
"data_get_command": "aws s3 cp s3://your-data-bucket-name/hoge/fuga.data fuga/data/",
"exec_command": "python fuga/train.py",
"ami_id" : "ami-111111",
"instance_type" : "p2.xlarge",
"spot_price" : "7.2"
}
なお、プライベートな Github のリポジトリを使う場合は、鍵情報を暗号化キー等でなんとかするか、アクセスキーを持ってきて repository_url に差し込むかするとかになります。
 ステップが勝手に進んでいく!楽しい!
ステップが勝手に進んでいく!楽しい!
お疲れ様でした。