Define-by-run である Eager Execution がデフォルトとなり、 API も大きく変わりそうな tensorflow 2.0。
紹介の動画が詳しくそれらを説明してくれているので 英語のリスニング練習のために 大まかな内容を日本語に書き起こしました。

スクリーンショットはすべて上記動画のもので文章は基本的にはそれらの要点を引用し訳したものとなります。
訳は意訳で、細かい部分は書いていません。
動画の意図と異なる部分などありましたらご連絡ください。
最初に
(このセクションは動画の翻訳ではありません)
この動画では eager execution (eager-mode) の話が沢山出てきます。
eager execution を理解するには Define-and-run と Define-by-run の違いを理解しておく必要があります。
- Define-and-run: 計算グラフを定義(Define)してからデータを流し込み(run)結果を得る
-
Define-by-run: python の通常コードのように、
x + yとグラフ定義をすると同時にグラフが実行されて結果が得られる
従来の tensorflow は Define-and-run で、 PyTorch は Define-by-run です。
eager execution は tensorflow で Define-by-run を可能にする仕組みです。
概要
すばやく理解できるよう、先に動画後半のまとめスライドです。

- 「簡単に使える」を重要視
- クリーンな API
- オブジェクト指向的な書き方
- python 的な書き方
- eager execution がデフォルトに
- パフォーマンスのため graph-mode も混在して使える
preview が今年の末、その後正式版が2,3週間後(few weeks later)にリリースされる
なぜ 2.0 を作るのか
PyTorch の追い上げがすごい。
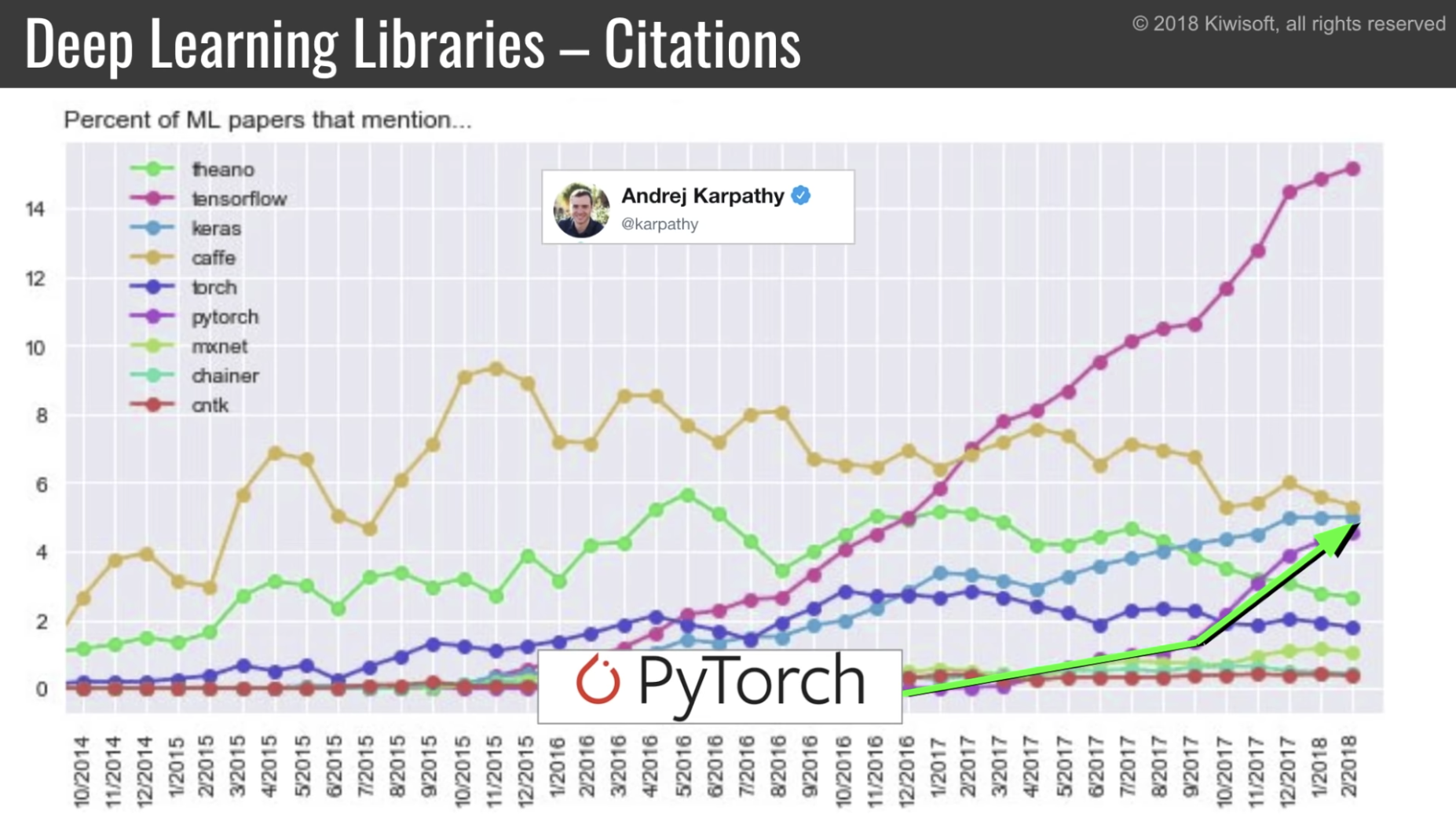
PyTorch と比較すると、以下の点で従来の tensorflow は辛い。これらを2.0では解決したい。
- 問題1: PyTorch の方がシンプルでわかりやすい
- eager execution をデフォルトにする
- 問題2: PyTorch のほうが python 的
- よりオブジェクト指向的にしてグローバルな状態をへらす
- 問題3: PyTorch のほうがクリーン(tensorflow は同じような関数がたくさんあったり)
- いろいろ消すぜ
問題1: PyTorch の方がシンプルでわかりやすい
(Define-by-run な) eager-mode がデフォルトに
(Define-by-run な) PyTorch のコードはとてもシンプル
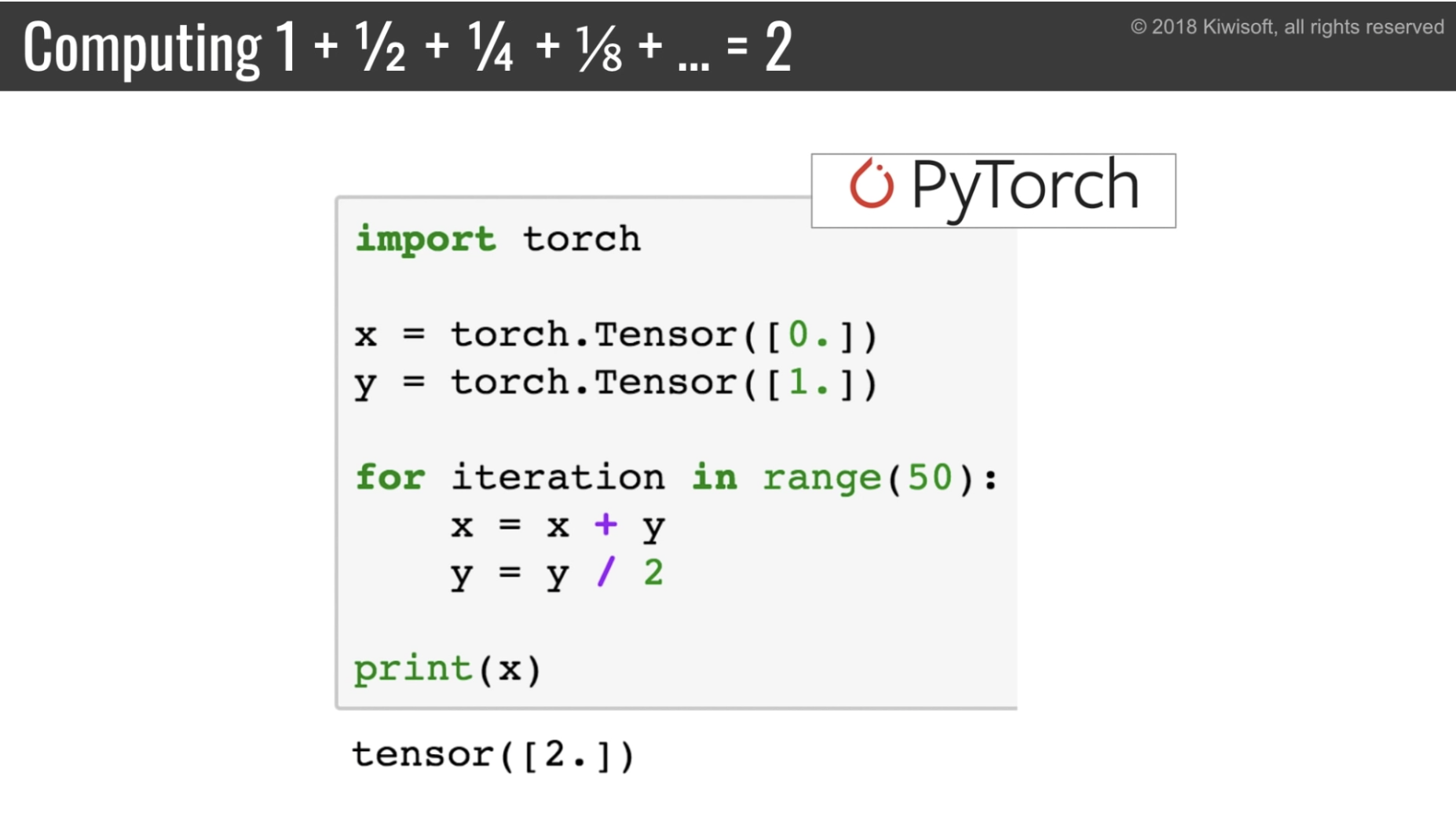
(Define-and-run な) Tensorflow だとこんなに大変

従来の tensorflow はその他以下のような問題点も。
(コードは動画参照)
- ノードの実行順は保証されないので、不定な結果を出すグラフを作れてしまう
- nan などの値が作られるときにどこでそれがおこっているかわからない
- 問題がグラフを作るところに有ったとしてもそれが発覚するのはグラフを実行するときだから
- デバグのためのノード(tf.Printとか)はあるが使い方がトリッキーだ
- 同様の理由で、速度のプロファイリングを取るのも難しい
そこで tensorflow 2.0 ではこうなる。
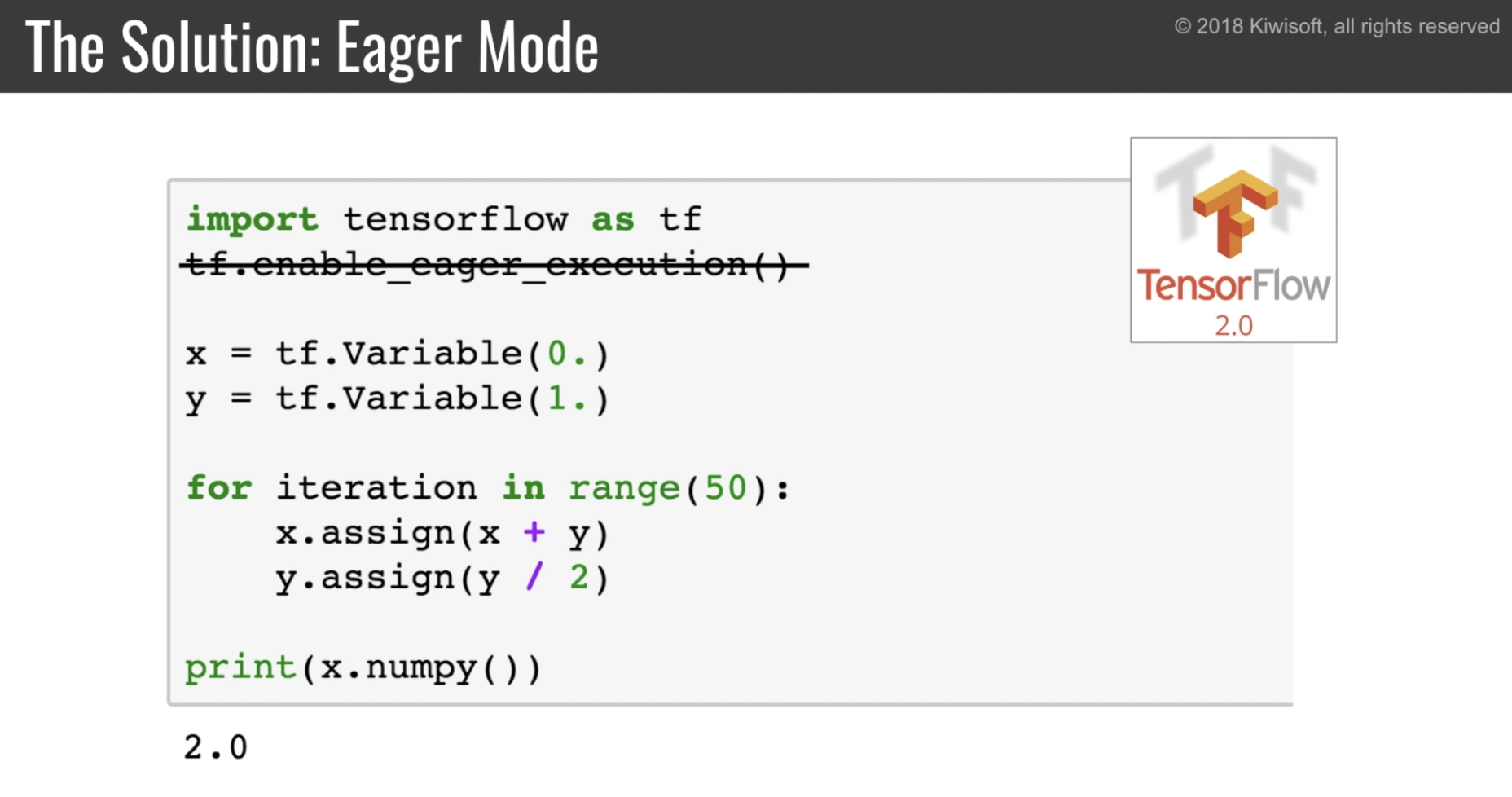
すでに実装されている eager execution がデフォルトになる。
eager-mode と graph-mode を混合して使用できる
- (Define-and-run の) graph-mode にも利点がある
- パフォーマンスが良い
- 特に Deep なモデルで小さなバッチサイズの場合
- XLA を使うことでより速度・メモリ使用量のパフォーマンスを高められる
- 複数のオペレーションをマージして一つの演算にしたり
- 様々なデバイスや環境に移植しやすい
- パフォーマンスが良い
tensorflow 2.0 では eager-mode と graph-mode を混ぜて使える。

@tf.contrib.eager.defun を使うことである関数のみグラフモードで実行することが可能

更に autograph を使うことで通常の python 関数を tensorflow の Graph にできる。
eager に実行すれば eager-mode で実行される。
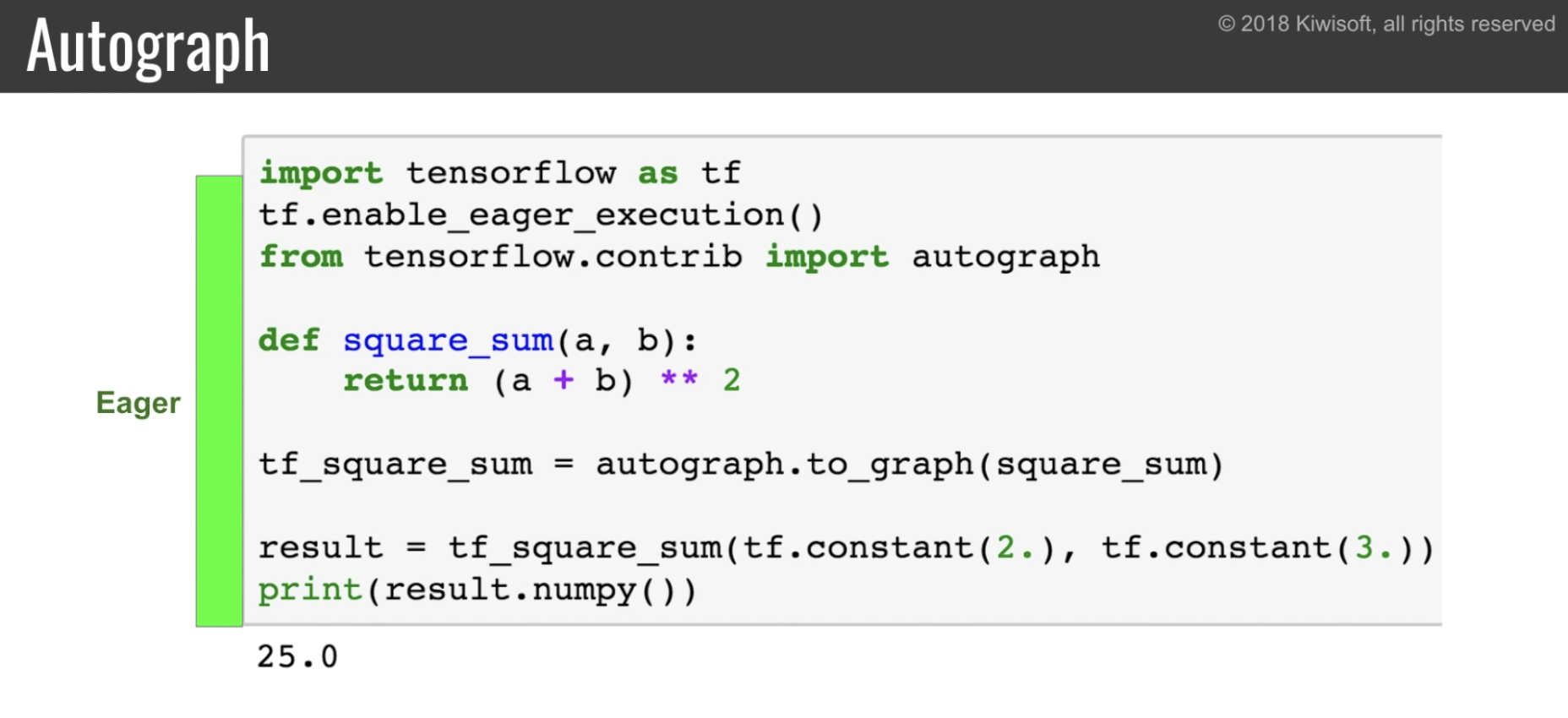
一方 graph の中で実行すれば graph-mode で実行される。
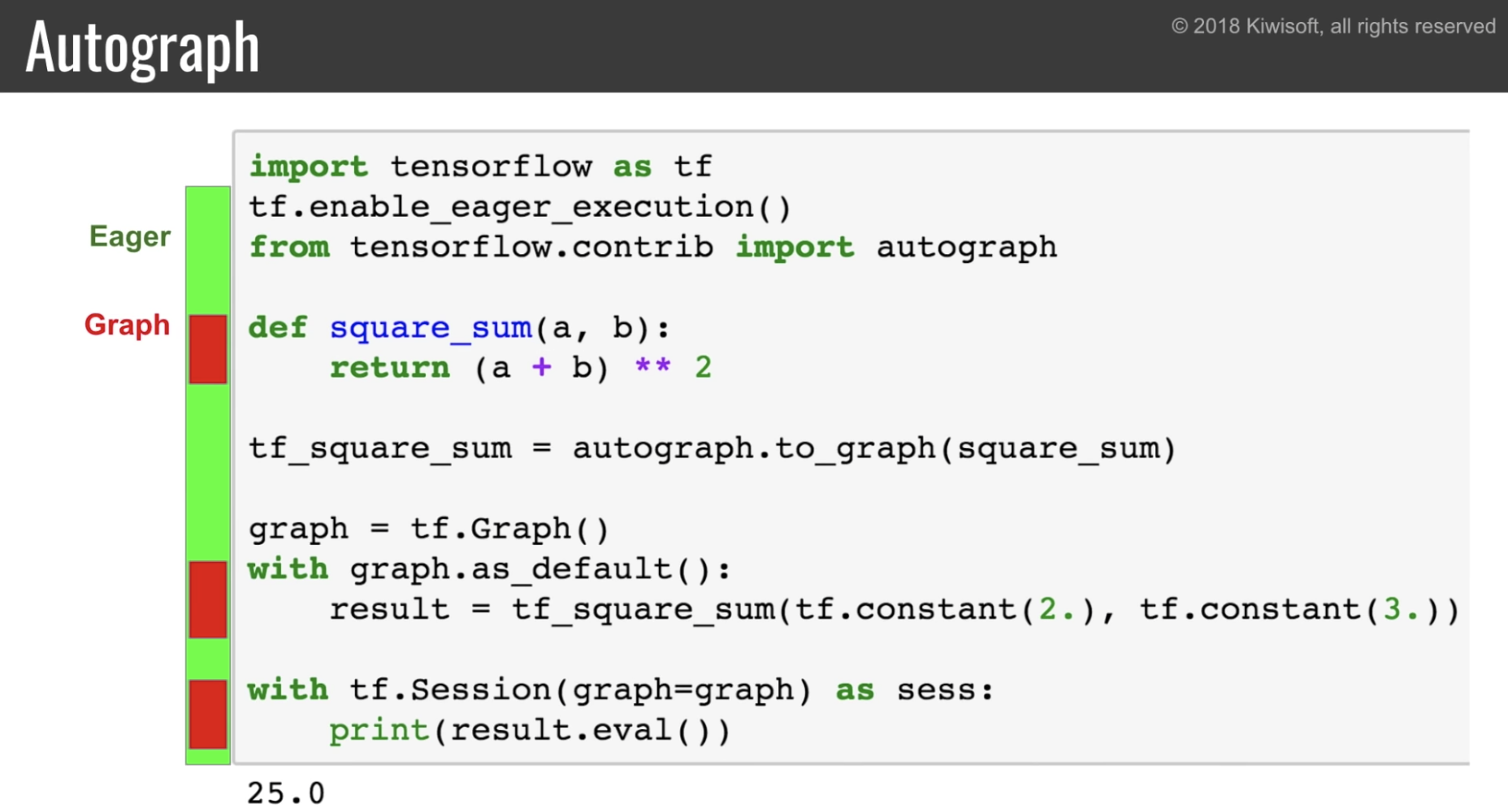
ループを使った複雑な関数等でも Autograph は使える。
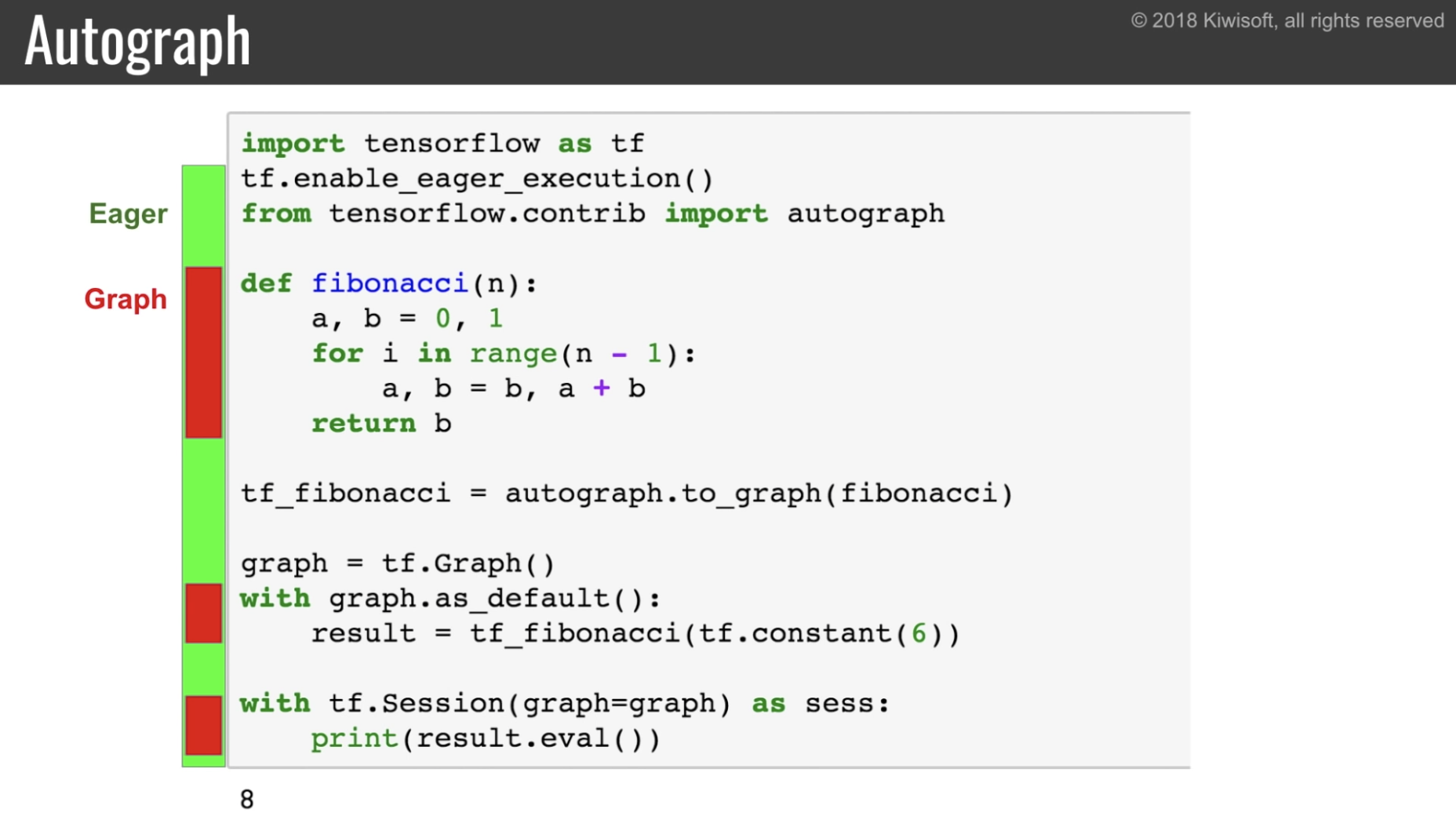
問題2: PyTorch のほうが python 的
PyTorch のほうがオブジェクト志向的で python 的だ。
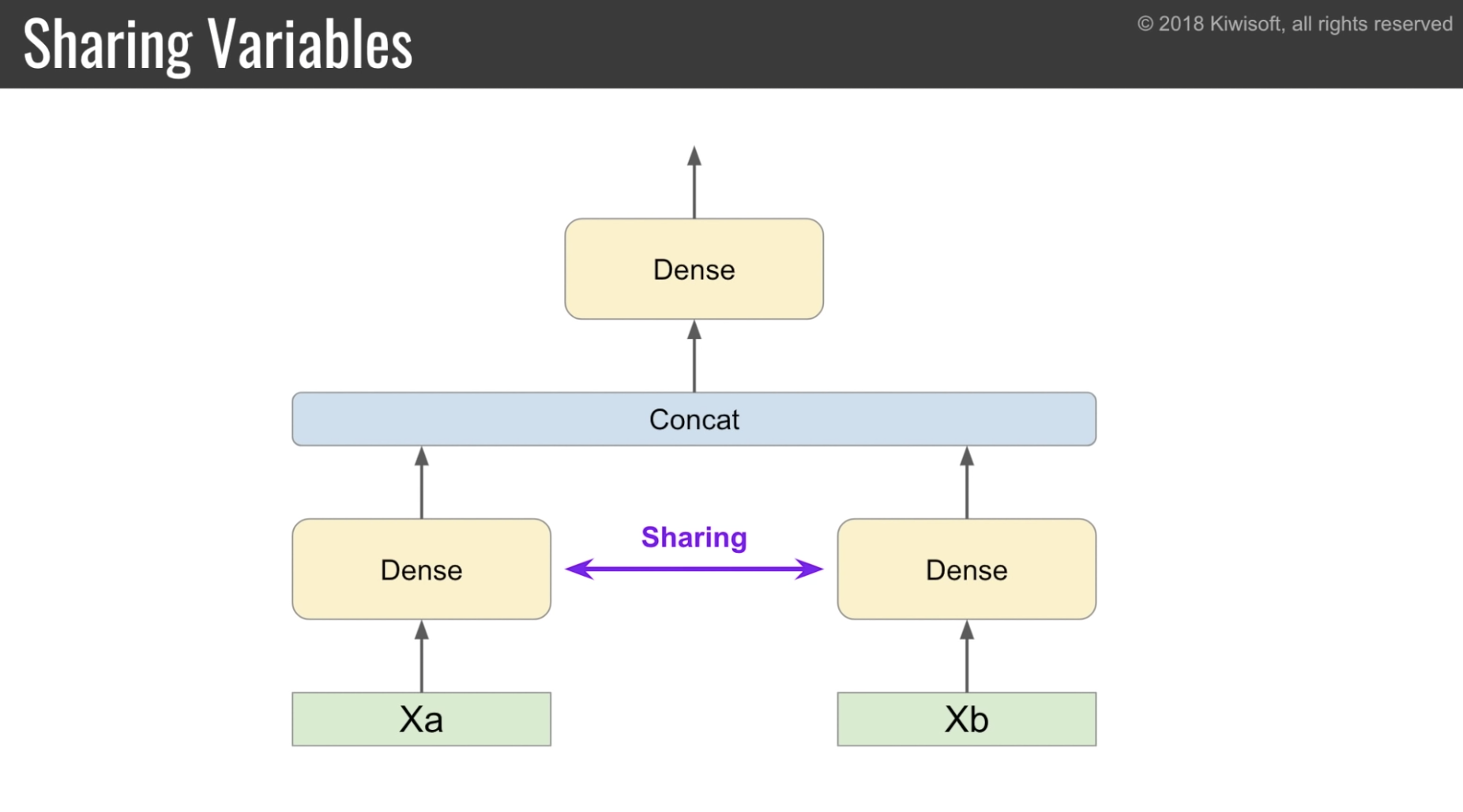
重み共有
Siamese Network の例。
従来の tensorflow では tf.variable_scope と tf.get_variable を使って「変数名」で重みを共有する。
tensorflow 2.0 では keras API を使うようになる。

Dense という処理のオブジェクトを作り、それを複数の入力に適用することで重みの共有を表現している。
こちらのほうが、グローバルな状態を持たず、よりオブジェクト指向的。
Collection が deprecated に
optimizer などで使う、学習用変数の Collection などが deprecated に。
従来の tensorflow
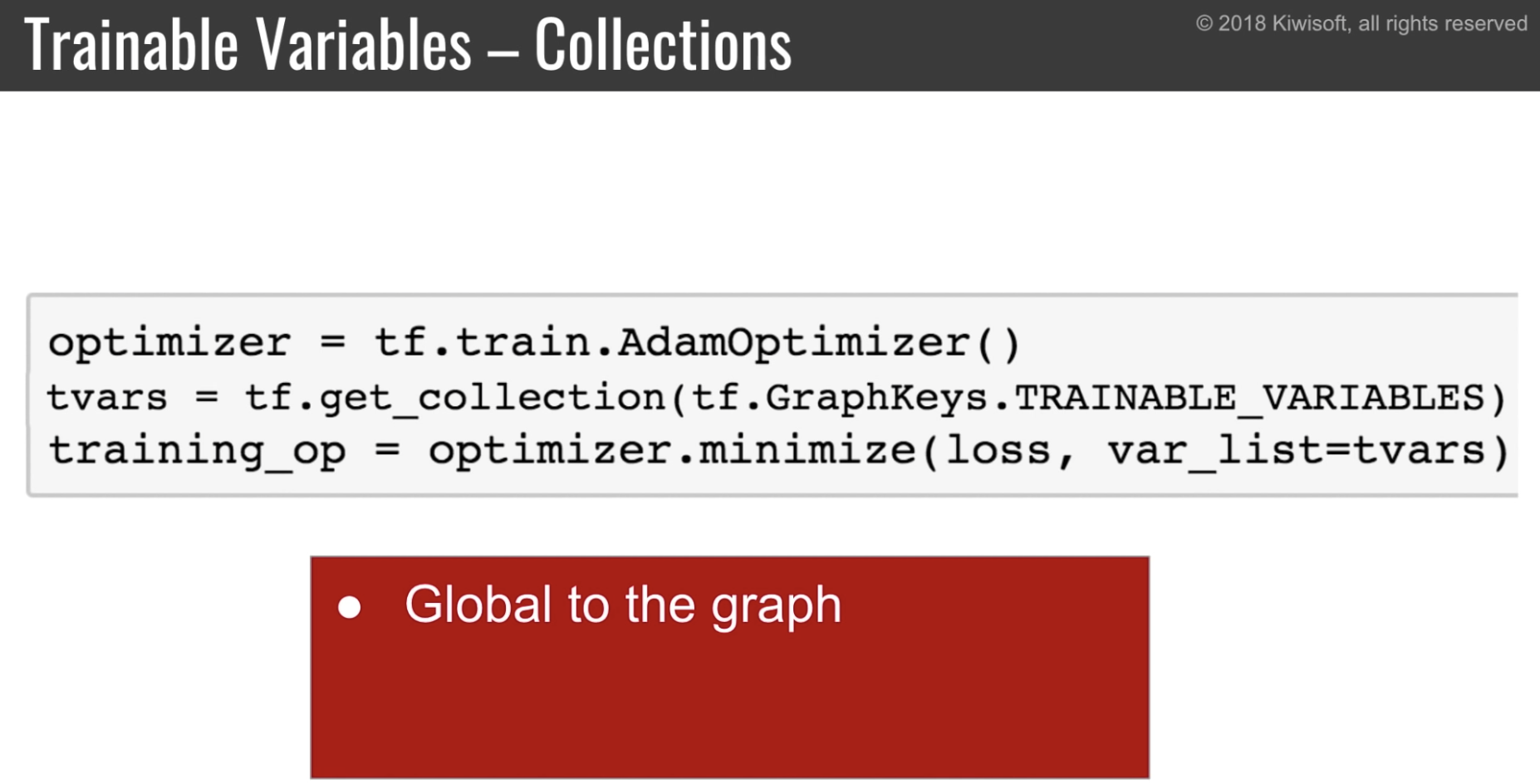
tensorflow 2.0
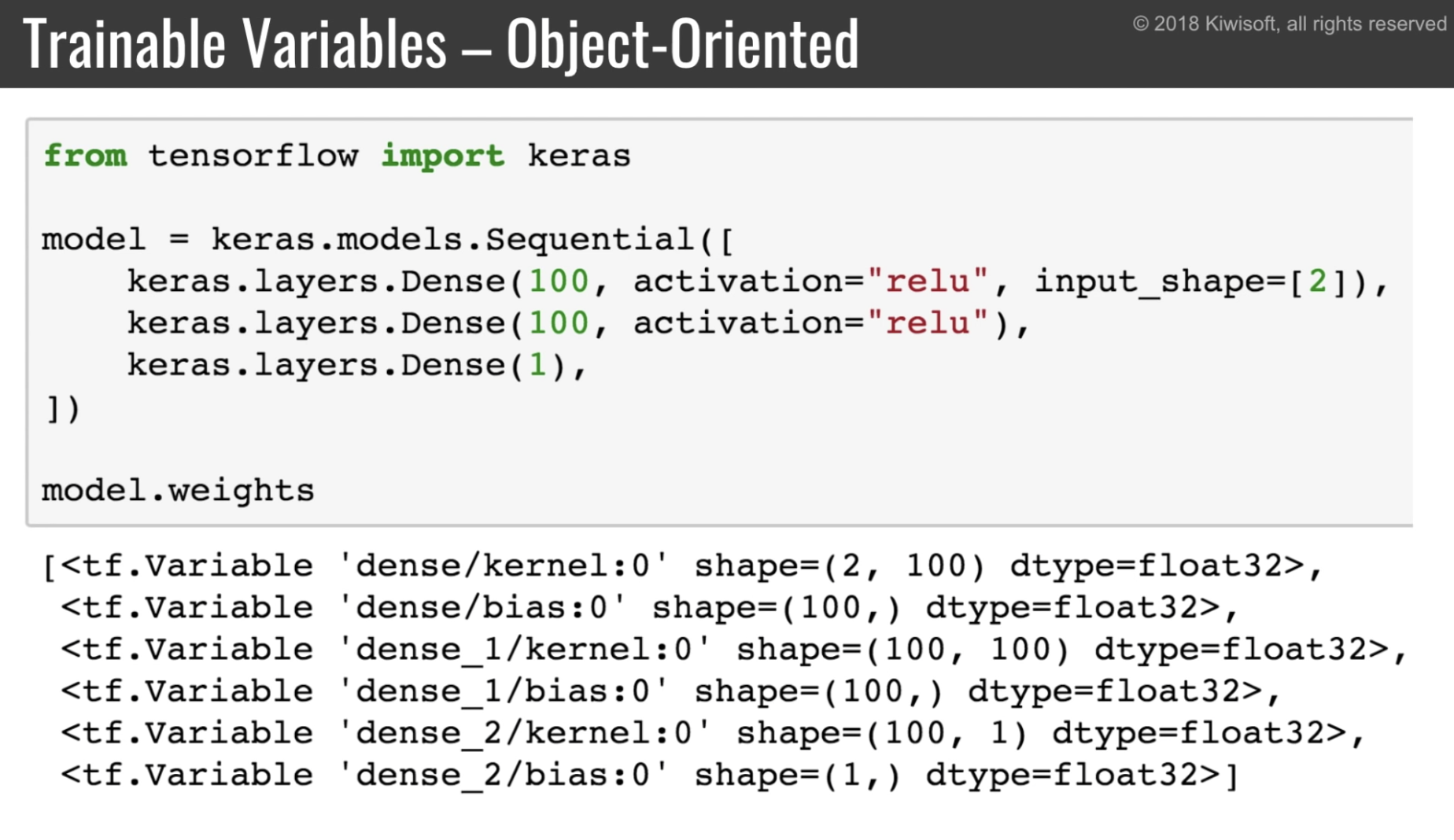
weights 一覧は layer オブジェクトのプロパティとして取得できる。
tensorflow 2.0 での変更
- tf.variable_scope -> 廃止
- レイヤーを使って重みを共有
- tf.get_variable -> 廃止
- layer.weights で重みを取得
- optimizer.minimize は loss の他に var_list を必ず取るようになる。
- var_list=model.weights
- tf.assign(a, b) -> 廃止
- a.assign(b) を使う
- a[1].assign(5) みたいな書き方は tensorflow 1.11 で使えるように
問題3: PyTorch のほうがクリーン
keras の api と tf の api が混在しているのを整理する

contrib を消す
一部は core api に統合。一部は別のプロジェクトとして分離。
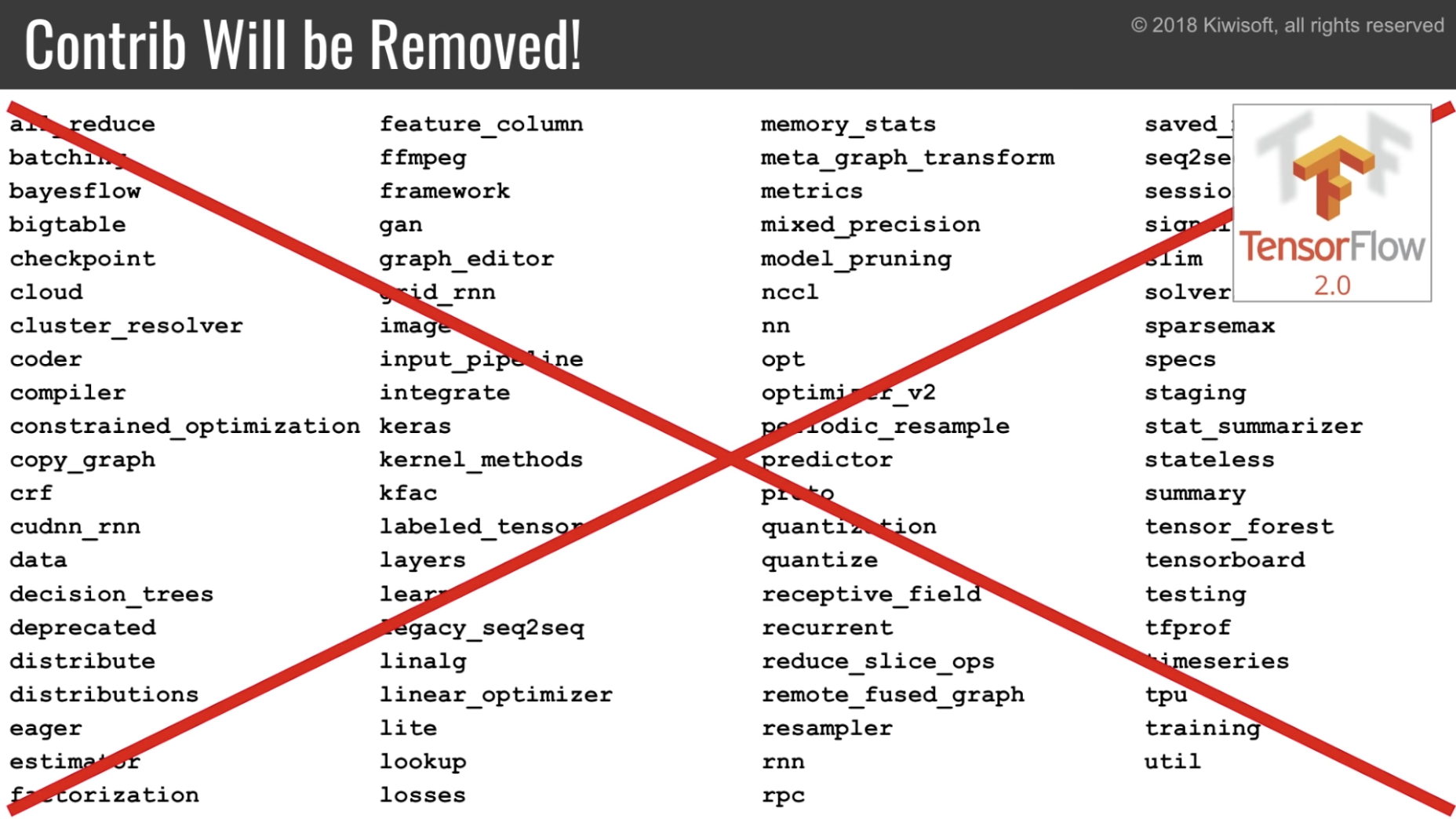
メソッドの整理
デバッグ系を tf.debugging にまとめたり
互換性のために以下の手段が提供される
- ミグレーションツール
- v1 から v2 への変換
- tf.compat.v1
Public Design Review Process
- 誰でも tensorflow の改良を提案できる
- TF-RFC でプルリクを送る
その他
(このセクションは動画の翻訳ではありません)
本家の Roadmap も参考になると思います。
https://www.tensorflow.org/community/roadmap