はじめに
私が機械学習の研究を始めたのは 2002 年でした。各家庭にブロードバンドが普及し始めたインターネットの黎明期です。そのブルーオーシャンを一気に手中に収めようと、ソフトバンクが街中で ADSL モデムをバラまいていました。
当然、計算機科学の花形は、インターネットやその基盤を支えるデータベースに関する研究です。当時は、機械学習など誰にも振り向いてもらえない不毛の研究分野でした。すごい勢いでモデムをバラまくソフトバンク社長の頭より不毛だったのは、よくできた皮肉だと思います。

なぜそこまで不毛だったのか?
詳細は後で説明しますが、軽く先走ると、数学の素養が高いレベルで求められるにもかかわらず、社会的なインパクトなど皆無の基礎研究でしかなかったからです。
ザ・キング・オブ・地味。信長の野望で言えば飛騨の姉小路のような泡沫ポジションだったのです。各社が札束を抱えて「AI人材」を追い求める現代にあって、若い人には信じられないかもしれませんが、本当です。
そして、ぺんぺん草すら生えない不毛の研究分野においてさえ見捨てられた研究トピックがありました。そう、**現代の我らが大正義「にゅーらる☆ねっとわーく」**です。

当時は「あんなブラックボックスに何ができるんだ」などと白い目が向けられていたのです。
それが**「機械学習こそ最強の学問である」「ディープラーニングにあらずんば AI にあらず」**などの極論を、産業界にして言わしめるほどの下克上を成し遂げたわけですから、私にしてみれば西から日が昇るほどの大事件です。
このように、短期間で価値観が180度転回する業界をクロスレンジで観察しても、目が回るばかりでその動向を把握することは難しいでしょう。そこで、**「人工知能と計算機科学の歴史を学んでロングレンジからその全体像を眺めようぜ!」**という野心的な魂胆が、ふと思い浮かぶわけです。
歴史を知れば未来が見える。嗚呼、温故知新。いまこそ皆で歴史を振り返り、人工知能と計算機科学の進歩に思いを馳せようではありませんか!(拳を握りしめながら)
人工知能研究のはじまりとニューラルネットワークの誕生
1936年にチューリングが「計算の原理」を数学的に明らかにした後、1944年にノイマンがその原理を電子回路で実現する近代的な計算機アーキテクチャを確立しました。
1950年代にトランジスタを用いたコンピュータが実現されると、世界の科学者はその計算能力に驚嘆したそうです。当時の科学者界隈でネットスラングが流通していれば、**「コンピュータ速すぎワロタwwww」**などとテンション爆上げだったに違いありません。

チューリングが予言したとおり、今後コンピュータの性能が順調に上がれば、本当に人間の知能を実現できるかもしれない——計算機科学者のマッカーシーとミンスキーはそう考え、1955年から「思考する機械」の研究を始めました。コンピュータ誕生のインパクトを考えれば、ごく自然な野心だったと言えるでしょう。
そして、翌年の1956年に、彼らは当時の主要な計算機科学者をダートマス大学に集めて会議を開きました。**「人工知能(Artificial Intelligence)」**という用語は、会議参加を促すためにマッカーシーらが書いた会議開催の提案書で初めて用いられた……本当かどうかは分かりませんが、このあたりのドラマはうまく脳内補完してください。
この会議で「人工知能」と呼ばれる新しい分野がめでたくキックオフされ**「探索」を軸にしたアプローチで第一次人工知能ブームが盛り上がっていきます**。例えば、1956年に開催された国際数学者会議では、計算機科学者のダイクストラが最短経路を探索するアルゴリズムを「人工知能」として発表しました。
このアルゴリズムによれば、出発地から目的地まで到達可能な経路選択の組み合わせが多数あり、距離がそれぞれ異なるという制約のもとで、コンピュータが人間より高速に最短経路を計算できました。
これは、人間の思考過程をシミュレーションしている!いや、高速エミュレーションとまで言っていいのではないか!?なんたって、機械が最短経路を「考える」んだから!すごい!すごいよ!人工知能バンザイ!!

ダイクストラのアルゴリズムは、現代ではカーナビや乗り換え案内を実現する基本としてよく知られています。当時の研究者たちは、この基本アルゴリズムを「人工知能」と呼んで大はしゃぎしたわけですが、これをピュアすぎると言って笑うのは後知恵です。
現在最先端のディープラーニングも、すでに大はしゃぎがひと段落して「単なるシステム」になってますよね。各時代において「先端の情報処理」が人工知能と呼ばれ、それが社会に浸透するほど「単なるシステム」としてそう呼ばれなくなるというのが、人工知能でお決まりのパターンです。
計算機科学者がさまざまなアルゴリズムを競って考案する一方で、心理学者のローゼンブラッドは、1958年に**「パーセプトロン」を発表しました。これは脳の神経細胞をモデル化した「形式ニューロン」を多数組み合わせ、それらの重み付き多数決で結果を出力する数理モデルです。
簡単なパターンを認識できただけでなく、正解データから重みの一部を学習することでその認識精度を改善できました。これが世界初のニューラルネットワーク**です。
パーセプトロンは世界中から多くの注目を集め、その後は様々な種類のニューラルネットワークが考案されるようになります。ディープラーニング大正義の現代では、多層パーセプトロンがニューラルネットワーク界のセンターアイドルですが、実は地下アイドルがたくさんいます。
さて、第一次人工知能ブームと日本の高度成長とは、だいたい時期が同じです。日本が国民総生産で西ドイツを抜いてアメリカに次ぐ世界第二の経済大国となり、1回目の東京オリンピックが開催された時期です。もはや戦後ではない。団塊の世代の目頭が熱くなる三丁目の夕日です。

画像出典:NIKKEI STYLE「東京五輪は「大転換」の象徴 半世紀前の再現なるか」
この時期のブームは、計算機に対する期待が大きかっただけに、それが外れたと知れ渡ったときの揺り戻しも大きかったようです。「結局大したことできねーじゃん」と、皆で一斉にガッカリしたのです。
なぜショボかったのか?
理由は簡単、ハードウェアがショボかったからです。
(下の写真は、1954年に開発された「IBM NORC」)

画像出典:ディリィ・ニュウス・エイジェンシイ
当時のコンピュータは、現代の子ども向け携帯ゲーム機にもまったく及ばない性能しか持っていませんでした。そのため、本当に解きたい現実の複雑なタスクには全然対応できなかったのです。アムロがいくら優秀なパイロットでも、モビルスーツの性能がショボければどうしようもありません。
その失望から、1960年代の後半から研究資金が削減され始め、ほどなく人工知能の研究全体が下火になります。いわゆる**「冬の時代」**の到来です。

けれども、分野全体が滅びたわけではありませんでした。コンピュータと人工知能の可能性に魅せられた科学者たちは、資金が少なくとも地道に研究を続けました。
人間に知性が宿る限り、いかなる逆境にあろうとも、技巧の限りを尽くして坂の上の雲を!いや、はるか彼方のアンドロメダを目指そうではないか!!
すごい執念ですね。一流の科学者たちが持つこのマインドには頭が下がります。そして、これが次のブームを生み出す原動力となるのです。
知識工学の進歩と第五世代コンピュータプロジェクト
1958年に集積回路が発明され、1960年代の前半にその量産化が始まると、コンピュータの計算能力はすさまじい勢いで向上し始めました。
インテル創業者のムーアは、1965年に発表した論文で「同じ面積を持つCPUに組み込まれるトランジスタの数は18ヶ月ごとに2倍になる」と予言しました。これが有名な**「ムーアの法則」**です。
トップが大胆にブチ上げた以上、インテル開発陣は頑張るしかありません。会社の威信にかけて、予言を妄言で終わらせるわけにはいかないのです。過酷なノルマを課された営業社員のような状況に当惑したエンジニアは多数いたと思います。しらんけど。
そして……開発陣はよくがんばった!感動した!!
トップのムチャ振りを本当に実現したのです。予言どおり、CPU内のトランジスタ数は爆発的に増加し、その計算能力は驚異的なスピードで伸び続けました。
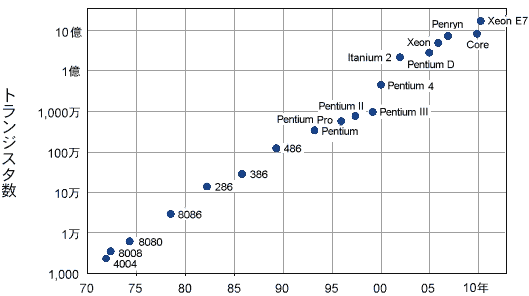
画像出典:情報処理概論
さて、ムーアの法則にしたがってコンピュータが進歩すれば、今度こそ知能を持たせられるに違いないと、また多くの科学者が期待し始めました。だって、前回はハードウェアがショボすぎたことがうまくいかなかった原因だったわけですから。
例えば、パーセプトロンのように学習を覚えた高性能コンピュータが、人間と同じように知能を進歩させるかもしれない——そう素朴に信じる人もいました……あれ?なんだか最近も似たような言説をチラホラ見た気がしますが……きっと気のせいでしょう。
その気運に乗って、1970年代の後半から80年代に入る時期に、再び人工知能にスポットライトが当てられます。第二次人工知能ブームの幕開けです。

この時代のブームのキーワードは**「知識表現と推論」**でした。人間が問題解決の能力を持つのは、経験から学び取った「知識」に基づいて、結果を予測したり原因を推測したりするなど、何らかの「推論」を行えるからだと科学者たちは考えました。だから、コンピュータに現実の複雑なタスクを処理させるためには、同じように知識と推論を実装すればいいだろう。
そのために、人間が経験的に蓄えた知識を、まずコンピュータに体系化しておこう。そして、人間がデータを入力すると、人工知能はそのデータと知識を照合し、マッチすればその知識をロジカルな規則に当てはめて結果を推論すればいい。実にシンプルですね。
1970年代の前半に計算機科学者のファイゲンバウムによって考案されたこの枠組みを、**「エキスパート・システム」と呼びます。また、条件・結果などを知識として体系化したデータベースを「知識ベース」と呼び、その知識を当てはめて最適な結果を推論する仕組みを「推論エンジン」**と呼びました。
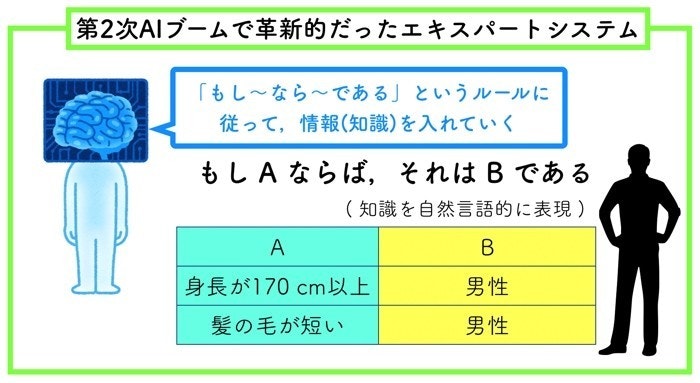
画像出典:そうだ!研究しよう「第2次AIブームで盛り上がりを見せた「知識表現」に関して:エキスパートシステムとは!?」
知識ベースに依存しない推論エンジンが商用化され、知識(ナレッジ)を差し替えるだけで新しい分野で簡単にシステムを作れるようになると、エキスパート・システムは多様な分野に応用されました。
例えば、新薬の開発、地層の解析、機関車の故障修理、航空機の離着陸管制などなど。人間の意思決定をコンピュータに補助させようという発想はこの時期に生まれ、その実用化はある程度実現されたと言えるでしょう。「コンピュータが人間の仕事を奪う」と囁かれたのは、最近の話ではないのです。
知識表現と推論がメインテーマとなったこの時代では**「知識工学」が発達しました。優れたナレッジを体系化するための手法とそれを蓄えるデータベースを追求する学問です。そして、これからは「ナレッジ・エンジニア」**が大量に必要になると声高に叫ばれました。
しかし、祇園精舎の鐘が鳴ると、知識工学は尻に敷かれたポテトチップのように粉々になり、ナレッジ・エンジニアも雲散霧消しました。昨今はデータサイエンティストが大量に必要だと言われていますが、いまゼロからデータサイエンスを学んで年収アップを狙うくらいなら、**「バーニラバニラ高収入」**を選ぶ方が賢明かもしれません。
さて、第二次人工知能ブームが盛り上がった時期も、日本経済は絶好調でした。オイルショックとプラザ合意による円高を乗り越えて貿易黒字を積み上げ、「ジャパン・アズ・ナンバーワン」の黄金期を迎えます。

日本は、繊維、重工業、自動車、電機、半導体と、次々に国内産業を育てることに成功してきました。一方で、当時のコンピュータ産業は、IBMをはじめとする米国企業が圧倒的な主導権を握っていました。
そこで、従来型のコンピュータとは設計思想が異なる次世代のコンピュータを実現し、アメリカから主導権を奪って次の基幹産業に育てるために、野心的な国家プロジェクトを進めようとしたのです。
このプロジェクトは**「第五世代コンピュータプロジェクト」**と名付けられました。つまり、コンピュータに実装される論理回路として、
- 真空管を使う → 第一世代
- トランジスタを使う → 第二世代
- 集積回路を使う → 第三世代
- 超集積回路を使う → 第四世代
と位置づけ、その先を行く高度なアーキテクチャを持ったコンピュータによる情報処理——すなわち、人工知能の実現を目指すプロジェクトだったのです(ちなみに、そのアーキテクチャは「非ノイマン型コンピュータ」という触れ込みだったのですが、ここでは割愛)。
理論的な裏付けが何もない状態から**「独自に新型モビルスーツを作ろうぜ!」**などとコンセプトだけが先行するこのノリに、すでに地雷臭しか感じないのは後知恵でしょうか。

通産省(現在の経済産業省)主導のもので産学連携の体制が整えられ、プロジェクトが滑り出します。日本のプロジェクト開始を皮切りにして先進各国も大型の国家予算を付け、似たような研究開発に乗り出しました。世界中で多額の資金が人工知能の研究に投下されたため、第二次人工知能ブームは一気に過熱します。
この壮大な国家プロジェクトの構想を簡単に要約すると、現代の「スマートスピーカ」の実現と言えるかもしれません。音声などの自然な方法(「マン・マシン・インターフェース」と呼びます)でコンピュータに所望の結果を伝えれば、コンピュータがその結果を知識から推論し、ユーザに理解しやすい形式で応答する大規模な並列計算システムを作り上げるという一大構想でした。
役所が一枚噛んでる時点ですでに失敗は確定してるわけで、プロジェクトは当然のごとく失敗に終わってしまいます。人間が暗黙に持つ知識を網羅的に形式化し、それらを推論規則に完璧に当てはめることなど、ほとんど不可能だったからです。
要するに、実世界に対する人間の働きかけはもっと柔軟であり、コンピュータによるトップダウンの機械的な計算アプローチのみでは対応しきれないことが多すぎるんですね。結局、プロジェクトはバブル経済の崩壊とともに座礁してしまいます。

1990年代に入ると、ハードウェアの進歩に伴うダウンサイジングの流れが強まり、コンピュータの構成は大規模なメインフレームを中心とする集中型から、各ユーザが用いる小型端末とそれらを相互接続するネットワークとで構成される分散型へ移行していきます。
エキスパート・システムは、「コンピュータで人間の作業が省力化される」というポジティブな認識を社会に残しました。ただし、このシステムも分散型への移行に伴って、「知識表現と推論」という大がかりな仕組みでなくとも同等以上の結果が得られるようになり、人工知能とは呼ばれなくなりました。ああ、諸行無常の響きあり。人工知能って本当に闇が深いですね。
一方で、大きく飛躍した研究テーマがあります。そうです、**我らが大正義「にゅーらる☆ねっとわーく」です。
ローゼンブラッドが提案した初期のパーセプトロンは、数学的な制約によりその「一部」しか学習できず、ミンスキーらによって数理モデルとしての限界が指摘されていました。そのため、このパーセプトロンは「単純パーセプトロン」**と呼ばれます。
これに対して、日本が誇るスーパー科学者・甘利俊一先生(現在は理化学研究所脳科学総合研究センター特別顧問)が1967年に巧妙な工夫で制約を取り払い、パーセプトロンの「全体」を学習できるように拡張しました。
**「確率降下学習法」と呼ばれるこのアルゴリズムは、1979年にヒントンらによって再発見され、「バックプロパゲーション(誤差逆伝播法)」とカッコいい名前が付けられました。そして、拡張された単純パーセプトロンは「多層パーセプトロン」として広く認知されます。これが後年のディープラーニングの基礎となります。
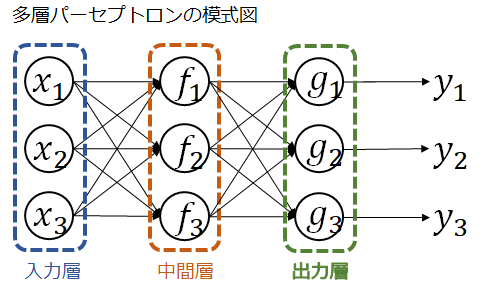
ちなみに、甘利先生はそのご著書のなかで、「温泉に入ってたら思いついちゃった☆」**とブレイクスルーなアルゴリズム誕生の瞬間を述懐されており、我ら凡百の徒には計り知れない何かが宿っているとしか思えません。
第五世代コンピュータが失敗に終わる頃、第二次人工知能ブームは収束を迎えます。人工知能は、また**「冬の時代」**に入ってしまいました。

空前のコンピュータ環境の出現と機械学習の発展
エキスパート・システムと第5世代コンピュータの挫折から、システムの動作をトップダウンで記述するアプローチが袋小路であることが分かると、科学者たちはデータからボトムアップでシステムを改善するアプローチに注目しました。
つまり、人間が知識を網羅的に書き出すのではなく、コンピュータにデータから「傾向」を発見させようとしたのです。「人手で知識を詰め込む」のではなく、**「自律的に知識を得る方法を詰め込む」**というメタなアプローチで攻めることにしたんですね。押してダメなら引いてみろの発想です。
この場合、パーセプトロンと同じ要領で何らかの数理モデルをデータから学習させます。学習が環境において妥当であれば、未知の状況においても機械は正しく動作するでしょう。
これが**「機械学習」と総称される各種アプローチの基本的な考え方です。「過去問を解いて試験本番に臨もうぜ!」**と言えば、その基本スタンスと難しさが理解できるのではないでしょうか。

もちろん、数理科学を基礎とする工学的なアプローチは、人工知能ブームとは関係なく昔から研究されてきました。例えば、自然現象を数理モデルで説明しようとする物理学などは、その大家ですよね。
この数理科学が「機械学習」として計算機科学に食い込み始めたのは、コンピュータの性能が上がり、ボトムアップで「試験本番」を乗り切ることが現実味を帯びてきたからです。
しかし、第二次人工知能ブームでトップダウンのアプローチが挫折した後も、次の2つの理由により、機械学習は計算機科学の分野で主流にはなれませんでした。
第一に、モデルをうまく学習させられるほど、コンピュータの性能が十分高くなかったことです。
タスクが複雑になれば、それに合わせてモデルも複雑にする必要があります。ところが、機械学習のアルゴリズムの多くはその複雑度に対して計算量が爆発的に増加するため、コンピュータの性能が伸び続けても、なお計算が難しかったのです。

そのため、扱えるタスクは限定的で実用に堪えず、基礎研究の域を出ませんでした。先にザ・キング・オブ・地味と書いたのは、これが理由です。
コンピュータで実世界の課題を解決しようとする計算機科学の分野において、「で、そのアルゴリズムは何の役に立つの?」と聞かれるとぐうの音も出ないのです。
第二に、モデルを学習させるためのデータを集める方法が限られていました。
1990年代の後半にはコンピュータの能力がさらに向上し、近似計算すれば学習できる場合もあったのですが、大量のデータを効率よく収集できる環境が不十分であったため、やっぱり地味な基礎研究にしかならずに注目を集めませんでした。
いまや華々しい花形ポジションを確立した機械学習も、売れない俳優志望がコンビニのバイトで食いつなぐような厳しい下積み時代があったのです。

ところが、時代は大きく変わります。1990年代の後半から携帯電話・家庭用コンピュータが普及し始め、2000年代の前半からブロードバンドの整備が進みました。どこかの不毛がモデムをバラまいてくれたお陰です。
そして、2000年代の中盤に世界初のスマートフォンが発売されると、「ネットワーク接続されたコンピュータを一人が一台ずつ持ち歩く」という空前のコンピュータ環境が実現しました。
これにより、世界中で膨大な量のデータが流通するようになりました。まさに**「データ多すぎワロタwwww」**の時代が来たのです。
つまり、遅くとも2000年代の中盤には、機械学習の発展を阻むボトルネックがほとんど解消されました。ここから、凄まじい勢いで研究が進みます。
特に「大量のデータを高性能コンピュータに入力し、重いシミュレーションをクラウド上で大規模にブン回す」のように、コンピュータの計算能力で押し切る力技の研究が増えました。個人的に**「脳筋研究」**と呼んでいます。
そして、この力技を極限まで追求して大きな成果を上げたのが……そうです、**我らが大正義「にゅーらる☆ねっとわーく」のセンターアイドル「ディープラーニング(深層モデルを用いた学習=深層学習)」**です。
深層学習の登場
深層モデルは、多層パーセプトロンをディープに(深層化=複雑化)した数理モデルです。
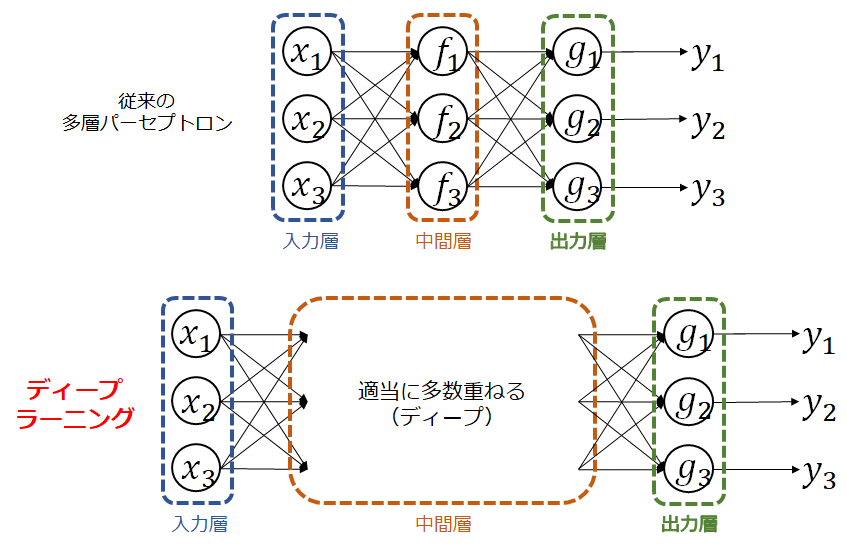
従来から、ディープにしても従来のバックプロパゲーションで学習できることは理論的には明らかでした。しかし、実際にコンピュータに計算させると、数値計算上の問題からうまくいかないことが知られていました。
ヒントンは巧妙なトリックでこの問題を克服し、多層パーセプトロンをディープにした状態で学習させることに成功したのです。
ニューラルネットワークでは論文が通らないとさえ囁かれるほど過酷に冷遇された極寒の時代に、その研究の火を消すことなく踏ん張った彼の執念には恐れ入るばかりです。「姉小路縛り」で天下統一を目指す根性こそが、天才の真骨頂なのかもしれません。

ディープラーニングが2010年代の前半に画像認識への応用で大成功を収め、これまで泡沫だった研究分野が産業界を巻き込んで一躍花形となりました。
第一次人工知能ブームでは探索アルゴリズムが、第二次人工知能ブームではエキスパート・システムが、それぞれ「人工知能」としてもてはやされましたが、第三次人工知能ブームではディープラーニングが大本命となりました。
2000年代前半に、自分の研究のために多層パーセプトロンを細々と自作していた私に言わせれば、微生物が進化を重ねて錦織圭になったくらいのインパクトです。ミラクルすぎるだろ。

ディープラーニングは、多層パーセプトロンが考案された時代から基本的な部分で変わっていません。両者の違いは、モデルの複雑度と、その学習に前述したトリックが組み込まれていることにあります。
前者が増すことによって爆発的に増加する計算量は、力技と近似計算の組み合わせで押し切ることができます。
例えば、囲碁の世界チャンピオンを破ったAlphaGoは、その内部でディープラーニングを使った近似計算を実行するために、1000台以上のプロセッサを束ねたクラウドサーバを稼働させたそうな。広大な砂浜に落とした一粒のダイアを探すために、大型ショベルカーを1000台動員するイメージです。

ディープラーニングは、コンピュータの計算能力とビッグデータという組み合わせが、とても効果的に作用するアプローチでした。**「りんごとハチミツ恋をした」**と言っていいでしょう(古い)。
後者は「データの特徴を自動で捉える」などと一般に謳われる、なんとなく胡散くさいトリックです(専門的には、特徴抽出を含むモジュールを「微分可能な世界に組み込んだ」と言えるかもしれません)。
ちなみに、深層モデルが**「脳を模したモデル」**と説明されることがあるのは、先に説明したとおり、ローゼンブラッドが形式ニューロンを繋げて単純パーセプトロンを作ったことに由来するためと思われます。
しかし、これは飛行機を指して「鳥を模した乗り物」と説明することと同じです。深層モデルは、あくまでも入出力の対応関係を近似する数理モデルに過ぎず、決して脳のモデルではありません。
また、近年米国に迫る経済大国となった中国が、今回のビッグウェーブに乗って計算機科学の主導権を握ろうとしているように見えます。これは、かつて日本が第五世代コンピュータで米国に挑んだ構図に似ていると感じるのは、私だけでしょうか?
いまや最先端の情報処理技術で先んじることは、世界の覇権を握ることと同じなのです。第一次、第二次で勢いのあった日本は現在非常にデリケートな経済状況にあり、どこにも出る幕がありません。
嗚呼、坂の上の雲はどこに行ったのでしょうか。もう日本はアンドロメダを目指せないのでしょうか?
各時代で共通・類似する事実
さて、人工知能と計算機科学の研究史を俯瞰すると、各時代で共通・類似する事実が見えてきます。4つほどあげてみましょう。
第一に、「人工知能」という用語は、いつの時代もそれを使う側にとって都合よく解釈され続けたという事実です。結局は単なる情報処理でしかないのですが、いろんな大人の事情で「とにかくすごいもの」と扇情的に解釈され、一般に用いられてきました。

第二に、歴史は繰り返すという事実です。何らかのきっかけでブームが起こるたびに、社会は人工知能という未来に夢を抱き、踊らされ、期待外れに落胆してきました。その効果が誇大に解釈されかねない不正確な情報が、都合のよい用語で喧伝されるからです。
民間のポジショントークはともかく、大学の研究者などの権威ある肩書きを持つ人まで「エキスパート・システム」「ディープラーニング」「シンギュラリティ」など、マーケティング色の強いパワーワードを使ってブームを過熱させるのはお決まりのパターンですね。
第三に、人工知能は、あらゆる問題を解決できる魔法の杖ではないという事実です。あまりにも当然なのですが、これが忘れ去られてしまうことが、過熱したブームがもたらす弊害の1つと言えるでしょう。

自分たちが直面する問題の本質的な原因を追求することなく、「人工知能でなんとかしたい」という話はいつの時代にも山ほどあります。しかし、人工知能はただの情報処理であり、それはツールに過ぎません。
最近ようやく無意味な「人工知能ブーム」が沈静化し、世の中の人は気づき始めましたが、魔法の杖などこの世のどこにも存在しないのです。当たり前すぎる。
第四に、人間と同じようにコンピュータに問題を解かせようという試みは、指数関数的に伸び続けるコンピュータの計算能力を生かした力技の前に、ことごとく敗れ去ってきたという事実です。

脳とコンピュータはまったく異なります。空を飛ぶために鳥を作る必要がないのと同じように、人間にとって便利なコンピュータを実現するために脳を作る必要はありません。
将来的に「人工知能」と呼ばれるであろう新しい情報処理は、ハードウェアをどう有効に使うかという観点から切り離されることはないだろうと私は予測しています。
シンギュラリティの到来による「超知能」の実現可能性
技術的特異点(シンギュラリティ)は、コンピュータが人間の知能を超越し、技術による問題解決の能力が指数関数的に向上することにより、「超知能」が文明を支配し始める時点のことらしいです。この時点ですでに宗教的な胡散臭さが漂います。

数学者でSF作家のヴィンジが、1980年代に発表した小説でこの用語を初めて使いました。その後、2005年にカーツワイルがムーアの法則を根拠にしてその概念を拡張させて使い始め、第三次人工知能ブームで広まったようです。
著名人・有名科学者がディストピアな未来を懸念する声明に同意したこともあり、「2045年」という数字と大胆な予測が世界的に注目を集めました。要するに、日本で一時期流行した「ノストラダムスの大予言」の世界バージョンです。

実は、この手の未来予測はカーツワイルが初めてではありません。例えば、1962年には「最初の超知的機械に関する思索」という会議が開催され、統計学者のグッドが「知的爆発」の可能性を指摘しています。
また、1965年に計算機科学者のサイモンは「20年以内に人間ができることは何でも機械でできるようになるだろう」と述べていますし、1970年にミンスキー(「人工知能」の用語を初めて使った科学者)は「3年から8年の間に、平均的な人間の一般的知能を備えた機械が登場するだろう」と予想しています。
このように、歴史を振り返れば、多くの人がいろいろな角度から風呂敷を広げ、世間をセンセーショナルに驚かせ、毎回その期待を裏切ってきました。裏切ったところで責任の詰め腹を切らされるわけではありませんので、言ったもん勝ちになるからです。

そうした歴史を踏まえれば、シンギュラリティなど「またか」という乾いた感想の対象でしかありません。言ったもん勝ちはいいとして、二番煎じもいいところです。
もちろん、私は人工知能の実現を信じています。実現できない理由が現時点で見当たらないからです。「空を飛ぶ」ために、最終的に鳥ができあがるのか、飛行機ができあがるのか、もっと別の何かができあがるのか、それは分かりませんし、いつ実現できるかも予測できません。
しかし、いつか何らかの方法で空を飛べるようになると、いまのところ考えています。ただし、「超知能が実現する」とか「コンピュータが人類を支配する」とか、そういった SF のような未来予測を信じてはいません。
人間は新しい技術を社会に役立て、より良い未来を作るために、社会に技術を融合させて文化をアップデートする努力を続けてきました。だからこそ、世界は常に改善され、豊かになってきたのです。
それは今も昔も、当然これからも変わりません。人間はそんなに馬鹿ではないし、長期間かけて創り上げてきた文化は脆くもありません。そういう意味で、コンピュータが人間の知能を超越したり、人間を支配したりすることはないと思います。
このあたりの話は、日本が世界に誇るスーパー科学者の杉山将先生が明快にファイナルアンサーを叩き出しているので、これを心に刻みましょう。
「いつの間にか変わっていた」の衝撃
一方で、冒頭で書いたとおり、計算機科学は猛烈な勢いで発展を続けています。今後も情報処理の可能性は広がり、コンピュータはより深く社会に浸透していくはずです。
これも先に説明したように、経路探索のアルゴリズムは70年ほど前に人工知能とみなされていました。また、インターネットで買い物するときは**「あなたにはこれがオススメです」と表示され、現時点ではこの仕組みが人工知能と呼ばれることがあります。

どの経路で行くか、何を買うかは、もちろん最終的に人間が判断するので、人工知能による「支配」とまでは言えません。しかし、「誘導」されているとは言えそう**です。
計算機科学の研究が進むと「人間にできてコンピュータにできないこと」が、少しずつ「コンピュータでもできる」ようになっていきます。そうすると「かつて人工知能と呼ばれていたもの」を自分が使っていることすら分からなくなり、それは人工知能ではなくなります。
だから、仮に真の人工知能が実現できるとしても、「2045年」のような分かりやすいターニングポイントが意識されるとは思えません。じわりじわりと社会が変わり、いつの間にか便利に(ある人にとっては不都合に)なっているでしょう。

そして、発展を続ける計算機科学が、20年後に何を「いつの間にか当たり前」にするかは誰にも分かりません。
ただし、近年の計算機科学が、「人間が暗黙に持つ知識・技能を人工知能で置き換える」ことのできる範囲を、押し広げる方向へ進歩しており、当面の間はその進歩の方向性が変わらないことは間違いなさそうです。
データから巧妙に暗黙知(言語化できない知識)を取り出す機械学習が凄まじい勢いで発展しているため、多くの人が従来から携わってきた仕事のいくつかは大きく変化するに違いありません。
それに伴って、各人に期待される役割や社会の仕組みも、少しずつ変わることになるんでしょうね、きっと。
最後に
Google トレンドによる検索回数によると、最近ようやく「人工知能」のブームが沈静化してきたことが分かります。グラフの青線は「人工知能」の検索回数の推移、赤線は「機械学習」のそれです。
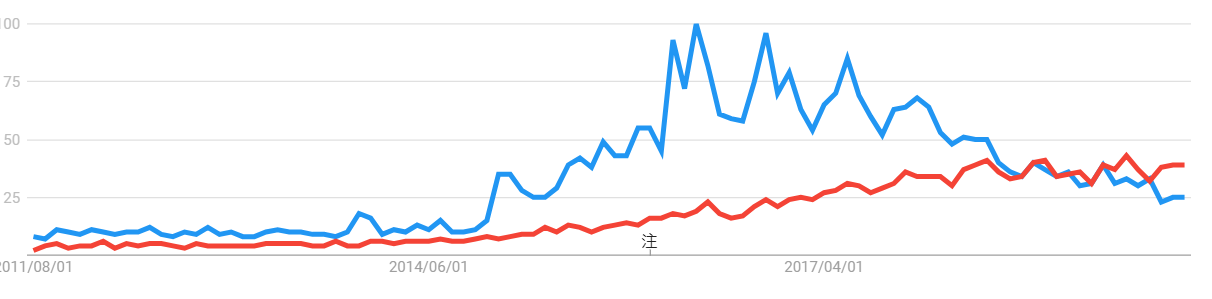
後者が前者を上回ってきたことから、人々がまともなデータ分析に目を向け始めたとポジティブにとらえてよいのか分かりませんが、とりあえず、人工知能の夢から覚めてきたことが客観的に分かりますね。
さて、皆で歴史を振り返り、人工知能と計算機科学の進歩に思いを馳せてきましたが、最後はなんとなくしめやかな結末になってしまいました。盛者必衰は世の理です。
ちなみに、最近プレステ4の人気タイトル「デトロイト:ビカム・ヒューマン」にハマってプレイしまくっていました。人間と変わらない見た目と超知能を持ったアンドロイドが、自由を求めるというストーリーで、手の込んだヒューマンドラマに感心した次第です。

さて、コンピュータがここまで発達するのはいつになるのでしょうか?
そもそも、人間と同じ知能など実現できるのでしょうか?
次の人工知能ブームがいつ来るかは分かりませんが、楽しみにしながら皆で正座して待ちましょう。
再編集後記
この記事は、note で公開していた記事(前編 / 後編)を再編集したものです。
これを書いてから1年ほど経ちましたが、本当にメディアで「AI」を見かける機会が減りました。私は医療系 IT 企業でエンジニア採用を担当していますが、「AI 開発やりたいです!」という人も、あまり見かけなくなった気がします。
本文にも書きましたが、技術は一定のレベルに達して陳腐化すると、オブジェクト指向のように「隠蔽」され、中身を詳しく知らなくても使えるようになります。AI も1つの技術群に過ぎませんので、宿命的に陳腐化し、次々と隠蔽されていきます。
例えば、ディープラーニングのカラクリは、高校で習う微積分と線形代数だけで説明できます。さて、ライブラリを使ってディープラーニングを動かせるエンジニアの中で、そのカラクリを説明できる人はどれほどいるでしょうか……おそらくそれほど多くはないと思うのですが、これこそまさに隠蔽された証拠であり、技術の進歩と言えるでしょう。
計算機科学は日々ものすごい勢いで進歩しています。ソフトウェアが人間の仕事を効率化・代替していく速度は、これからもどんどん上がっていくはずです。
だからこそ**「自分はどうしてもこれをやりたいんだ」「これだけは絶対誰にも負けないんだ」という熱意や執念が、AI には決して模倣できない創造性の源泉になる**と思うのです。
……さて、長々と書いてしまいましたが、当社では、
「三度の飯よりパソコンが好き」
「キーボードに触れていないと死ぬ」
「気がついたらエディタを叩いて何かを作ってしまう」
などなど、エンジニアリングに熱意と執念を抱いている尖ったパソコン野郎を大募集しております。
我こそはと腕に覚えのあるエンジニアは、ぜひ私に経歴書なりポートフォリオなりを送りつけてください。少数精鋭のエンジニアチームで歓迎します。
求人票は paiza でどうぞ。