
深窓学習始めました。あ、深層
最近、ちまたではやりの、つい数年前にブレイクスルーしちゃった技術、
DeepLearning
やりたい事が出来たので、ちょっと遊んでみようかなと遊んでみました。
ネット界をひたすら回って'今'をザックリ調べる
と思っていたら、自分的に最初から最強チート気味な、良い感じのあんちょこ的スライドが見つかったのであっさり現状を理解!
えっ?夢かも?画像を沢山放り込めば勝手に特徴を見つけて見分けてくれるの?
- 思い起こすと高校生。
- 画像処理とニューラルネットワークに興味津々に手を出すも、少しだけかじって所詮今はこの程度か…
- から十数年。まさか認識したいモノに合わせた設計無しにピクセル流し込めば、
ニューラルネットが画像認識する時代が来てる(途中だけどね)のはカンドウです
もう、止まらないわくわくが!
Caffeを淹れる準備
今一番アツイらしいcaffeを淹れてみる。
- うぇぶさーふぃんして探した参考サイト
- http://kivantium.hateblo.jp/entry/2015/01/03/223607
- http://lapriem.hotcom-web.com/wordpress/2015/02/09/39/
- http://christina.hatenablog.com/entry/2015/01/23/212541
- http://lapriem.hotcom-web.com/wordpress/2015/02/09/39/
- これはお手軽、トレーニング済みデータ github
- これがあれば少ないデータでもそこそこの精度で早く学習が済むというありがたいデータ。
- 深層の浅い層を学習済みのモノで流用できるというディープラーニングの素晴らしい能力による、手軽こそは正義な使い方。
- ライセンスに制約アリます
ひとまずCaffeを淹れる
御手抜き用 vargrantのファイル
- 貴方の御手を煩わせないよう作りました。
- VargantfileのGist
- 色々手順があるcaffeだけれど、さくっとお試しする為の環境はこれ一発で出来ます(ギガバイトクラスのデータが落ちてくるので注意)
- もし既に環境ある人は中を見れば手順は大体理解できるかも?
- …ただ、見知らぬ環境ではテストできてないので動かなかったらコメントにて情報クダサイ!
ちなみにvargrantって?
自分はこちらを参考に憶えました。
ちなみに憶えたてほやほやです。
- http://qiita.com/hidekuro/items/fc12344d36d996198e96
- http://www.slideshare.net/shin1x1/vagrant-php
- http://qiita.com/yuki-takei/items/1a5fc4ab66f58e9536f0
詳しくない人(たとえばちょっと前の自分)向けに軽く最低限の手順だけ書くと、
参考サイトを参考にvagrantを入れて、
https://gist.github.com/haiatto/2ba86acce285e7c52b63
このVargantfileを好きなディレクトリを作って入れて
vagrant up
とコマンドラインから実行するとubuntuの仮想環境からcaffe入れるところまで
ダウンロードやらmakeやらでお時間多少かかりますが環境が整っちゃうやつです。
淹れたCaffeを愉しむ
Caffeで猫と戯れる。
深層学習を調べると必ず出てくる猫画像。
猫がブレイクスルーの一因を担っているので良く出てきます。
というわけで、まずは猫を認識して何かしてみよう。
猫を見つけてつぶやくとかお題としてはシンプルで面白そうかも。
というわけで。
まずはCNNとか深煎りしてみる
CNNってなにするものさ。よやいやさ。どっこさ。
- CNNとは Convolution Neural Network(CNN) (画像検索LINK) っていうやつです。
- これが数年前に登場するや否や並み居る強豪アルゴリズムをブッチギッテいきなり高い認識率をたたき出してブレイクスルーしちゃいました
- caffeは、このネットワークのモデルを protobuff という汎用のテキストフォーマットで書いて、学習させて、認識させる っていう事をやる奴です。
- ちなみに、このネットワークの構成次第で認識できるモノや精度が劇的に変わるらしいです。
- ある意味で回路設計に近いらしいとのこと
- より精度の高くなる構成や研究結果をレイヤーとして実装したものが公開されたりと最先端の研究で日進月歩(比喩ではなく本気(マジ)で)進化してるらしいです。
CNNに具体的になにさせればよいのさ
画像を流し込んで種類とそのスコアをもらう。
これだけです。
- でも、注意。たとえば猫だけを覚えさせたネットワークなら、猫らしさをもとに数値がいい感じで出てきて、閾値とかでぶった切れば猫判定が出来ると思ってました。
- もしかしたらそれでも出来るのかもしれませんが、判断難しそうでした
- でも試してわかったこととして、猫らしくなさ、もちゃんと覚えさせないと精度上がらなさそうでした。
- もう一つ技術上の制約あります。CNNの特徴の一つ、位置不変性で、画像の中から目的の小領域を見つけ出すまでCNNがやってくれると思っていたけれど、今はそこまでは無理らしいです。
- かなりアバウトでも結構行けちゃうみたいですが、画像の中に一部猫が小さく映ってるとかは無理っぽい
- でも、結構ザックリした切り出しでもソレなりに良い認識率。そこがCNNの凄そうなところ
それを踏まえて、CNNに具体的になにさせるかというと…
- まずはザックリ猫が居るかもしれない領域を切り出す。
- これは、大抵は既存の方法でやるらしいです。たとえば顔認識とか領域認識とか移動物体認識とか。
- ちなみに、認識結果から領域を切り出すことは出来ないみたいです。
- バックプロジェクションの仕組みとか理解すればいけるのかな?
- そして、その領域を切り出して中身が何なのかを判断する、それが主流なの画像の識別用のディープラーニングの使い方らしいです
深煎りしたcaffeを愉しむ
- ここで公式のサンプルでもあるイメージネット(2012年版)は初めから猫を識別できます。さらにそれ以外も識別できます。全部で1000カテゴリくらいに。
- ならば、猫らしさと猫らしくなさ(=他のものだと識別)してくれるので今回の目的には好都合かも
- 時間のかかる学習しなくていいし、これ使おう。さっそく試してみよう!
猫を視るcaffeを淹れる
未来を見据えてwebサービスっぽくしちゃえ
- webサービスっぽくなってたらきっと便利だよね
- 画像をWebsocketで送りつけて、結果を非同期で受け取る感じくらいで実装してみよう
サーバーつくろう!
- nodejsが使えると個人的には楽。でも、numpyとかpythonが無いと不便そう。という事でひとまずpythonで書いてみよう
- tornadoを使いました
- tornadoはpepper君のqimessagingでも使われてたWebサーバーフレームワーク(その経緯で存在をしっていたので使ってみた)
- 参考サイト
- http://qiita.com/intermezzo-fr/items/71caf7646cb16ef74ea0
- http://ami-gs.hatenablog.com/entry/2014/02/14/121145
- さあインストールだ!
よし出来た!
※三分間クッキングの要領で途中経過は飛ばしました
- githubへのりんく(pepper_caffe/pepper_deep_cat)
- Vagrantを入れた人はこれも既に入っているので、以下でお試し可です。
caffeWork/pepper_caffe/pepper_deep_cat_test.sh
-
サーバーは [server_test01.py] (https://github.com/haiatto/pepper_caffe/blob/master/pepper_deep_cat/server_test01.py) で、機能は
-
WebSocket経由で画像のURLを受け取って結果をjsonで返す
-
WebSocket経由で画像のサイズとRGB値を受け取って結果をjsonで返す
-
クライアントは index.html と main.js
-
knockout.jsでバインドしているのでindex.htmlはほとんどテンプレです。本体はmain.js
-
main.jsは単に認識ボタンが押されたら画像のURLを送ってるだけ
-
みたいな感じです!
Pepper君と連動させれば完成!
よしできた!
※またもや三分間クッキングの要領で途中経過は飛ばしました
-
先ほど立ち上げたVirtualBOX内のサーバーのURLが必要です。ws:// から始まるURLを指定します。(ws://IPアドレス:8080)
-
なお、みんなPepper君持ってないだろうし、Webカメラでも試せるようにしてます!
-
そこ!ペッパー君の意味って… とか言わない!
-
ご家庭にスタンドアローンで存在するっていうだけで、立派に面白いおもちゃです。Pepper君。
-
(ホントはcaffeサーバー側もインストールしたいけど、ATOMだし…メモリ1GBだし動かないと思う)
-
(Pepper君で本格的に活用するなら、Jetsonあたりを背中に、よし追加オプションだ!JETパック装着だー!とかやるといいかもと割と本気で思ってます。EC2とか青天井クラウドだと怖いし)
-
というわけで、できた!
感想文(現在)
- 超適当に作った割には、一応ぎりぎり猫を認識してつぶやいてくれました。
- 移動体検出とか、正直どうかと思う方法で適当にやったので、そこを何とかすると、精度は飛躍的に上がりそうです。
- 今は、精度としてはホントにぎりぎりです。誤検知もあるけど、検知してくれないこと多い感じに。
- でも、ネットワークを専用に作ったり、移動体検出をもっとマトモにしたりすると実用(?)的になりそうな雰囲気!
- Pepper君に新たなる眼を持たせたのでひとまず満足!
感想文(未来)
さて、もし、ペッパー君が周囲のあらゆる移動体や、特徴のある形状やら模様を片っ端から識別して、理解していく御目目を持ったなら…
- ペッパー! そこの鉢植えの記録、毎日とっておいて! 半年くらいよろしく!
- ペッパー! 洗濯機の前まで来て!
- ペッパー!ここのまどから見える猫を見かけたら写真撮っておいて!
- Hey! Pep! ティーデリバリー!ナウナウ!(腰にお茶運び道具を装着してPepper専用珈琲メーカーを見つけて(きっとネスレ製)Caffeを入れるペッパー)
なんて未来もくるかも。日進月歩のディープラーニング技術を取り入れた眼を得たら多分ちょっと未来に近づく予感でいっぱい。
次回
- Pepperブロックそろそろ頑張る。
以下はこの投稿を書くにあたって
探索中に集めた情報
- R-CNN
- Regions with Convolutional Neural Networks
- http://nbviewer.ipython.org/github/BVLC/caffe/blob/dev/examples/detection.ipynb
- なんかいい感じに複数の物体認識してる気になる奴
+α関係ない事
普通の画像処理について知りたい人に個人的な偏見ありでおすすめする本…
-
個人的なバイブルは C言語による画像認識入門
-
ハフ変換から遺伝的アルゴリズムによる顔画像マッチングなどまで載っている入門とは名ばかりの楽しい本
-
この本の影響で時々休みの日に趣味で画像処理をたしなむ程度の人生に
-
旧2級の時には凄くいい教科書
-
今も多分変わらず良いものだと思われます
-
下手な入門本なんかよりはるかに読んでて楽しい珍しいタイプの教科書
以下はこの投稿を書くにあたって色々試して…結局、投稿しなかったけど、記録したものです。自分で学習したりしたいときに参考になるかも?
とらぶるの記録!
ハマってしまった罠などを一部記録しました
とらぶる
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import sys
import caffe
MODEL_FILE = 'caffe/examples/mnist/lenet_train_test.prototxt'
PRETRAINED = 'caffe/examples/mnist/lenet_iter_5000.caffemodel'
IMAGE_FILE = 'images/cat.jpg'
caffe.set_mode_cpu()
net = caffe.Classifier(MODEL_FILE,PRETRAINED)
I0419 15:38:27.980262 5052 layer_factory.hpp:74] Creating layer mnist
I0419 15:38:27.980397 5052 net.cpp:84] Creating Layer mnist
I0419 15:38:27.980484 5052 net.cpp:338] mnist -> data
I0419 15:38:27.980581 5052 net.cpp:338] mnist -> label
I0419 15:38:27.980671 5052 net.cpp:113] Setting up mnist
F0419 15:38:27.980842 5052 db.hpp:109] Check failed: mdb_status == 0 (2 vs. 0) No such file or directory
*** Check failure stack trace: ***
- エラーが出るのでサンプルで試しても同様のエラーが!
- lmdbというやつ周りでトラブル!
- lmdbというのはライトなデータベースらしい
- ソースを見てみるとオープンあたりで失敗してそう…
- まあエラー見ても明らかにファイル見つからないといってるし
答え
- カレントディレクトリの問題でした
- LMDB使ったモデル使う場合はカレントディレクトリに気をつける!
とらぶる2
net = caffe.Classifier(
MODEL_FILE,
PRETRAINED)
IndexError Traceback (most recent call last)
<ipython-input-15-2ca149acab05> in <module>()
6 net = caffe.Classifier(
7 MODEL_FILE,
----> 8 PRETRAINED)
9 list(net.inputs)
/home/haiatto/caffe/caffe-master/python/caffe/classifier.pyc in __init__(self, model_file, pretrained_file, image_dims, mean, input_scale, raw_scale, channel_swap)
27
28 # configure pre-processing
---> 29 in_ = self.inputs[0]
30 self.transformer = caffe.io.Transformer(
31 {in_: self.blobs[in_].data.shape})
IndexError: list index out of range
答え2
- pythonの caffe.Classifier は、サンプル的なモノらしい
- なので対応しているのは inputs が存在するモデルのみ!
- 具体的には、layer に含まれていない input があるデータのみ対応。リアルタイムに処理するデータ向けという事です。
- 最初からLMDBとかが入っているだけのデータは想定してないらしい
- LMDBしか入力のないような場合は継承元のcaffe.Netクラスを使う!
とらぶる3
- 猫の御方のLMDBデータを使うと、なぜか softmax_lossレイヤー とか accuracyレイヤー でアサートする!
答え3
- ソースを追ったら、ラベルがゼロから始まらないと明らかにチェックに引っかる様になっているのに、ラベルが1から振られているから…
- さらにBLAME見てみると、チェックコード追加が去年の11月頃から…
- つまり、猫の御方の投稿の時点(去年の8月)でのcaffeでは動いていたという事実!
- バージョン間の互換性のせい!
- 色々追って分かったけど結構互換性無くなるような変更がバリバリ入ってます
- 関数名変えたりとか…一部しか見てないけど見た範囲でも結構あったり…
とらぶる4
- モデル用のprototxt、ネットのサンプルを引っ張ってきたけど何か違うんだけど…
- layers とか layer とか…
- 公式ページのチューリアルはlayersなんだけどなぁ…サンプルのソースはlayerなんだよなぁ…同じ内容指して解説してるのに
答え4
- https://github.com/BVLC/caffe/pull/2036
- 変更されてました! 2015年2月頃に!
- ソースもその時点で全部layersからlayerに書き換えられてる!じゃん
- まじー うけるー
- …という事で下位互換性は微妙なので気負つけましょうという教訓を得ました
- (一応本体はlayersでも動くようになってます。でもモデルの可視化ツールがlayerのみ対応に書き換えられてて新バージョンに変換しないと積み増した)
- (一応変換ツールは upgrade_net_proto_text あるようです。)
編集中カットされた項目たち
リポジトリをクローンし以下のコマンド実行!(※学習は結構長いです)
cd ~/caffe/myProj/cat-fancier/classifier/catnet
./create_catnet.sh
./train_quick.sh
caffeの抽出には時間がかかるのでジックリ待つ
- VirtualBox上でCPUでやってるのも理由かもだけど、事前学習済みから始めてるとはいえ結構時間かかるみたい。
- なんていうか水出しみたいな…(…あくまで珈琲に拘ってみたり。そろそろしつこいって?)
- ちなみに待ってる間にこの記事書いてます…でもまだ終わらず。
より深煎り
/catnet/create_catnet.sh
TRAINDB=catnet_train_lmdb
TESTDB=catnet_val_lmdb
- こちらはLMDBという画像とラベル用番号入りのデータベースを準備する為のスクリプトみたいです。
- 学習用(train)と認識テスト用(val)
- データベースには認識結果のカテゴリ用番号が振られた猫画像のリストがリサイズされて入るようです
- 画像を見てみるとかなり自然な猫画像…。世界が驚く訳だ…こんな画像でいいなんて。
/catnet/train_quick.sh
PRETRAINED=./data/bvlc_reference_caffenet.caffemodel
SOLVER=catnet_quick_solver2.prototxt
- 学習済みデータと設定ファイルを使って学習させる処理が書かれてるみたい
- これを実行すると学習が始まりました 時間書かかる!
/catnet/catnet_quick_solver2.prototxt
net: "catnet_train_val.prototxt"
…
solver_mode: CPU
- 学習の設定ファイル
- 学習の回数とか繰り返し周りの事が書かれています
/catnet/catnet_train_val.prototxt
name: "CaffeNet"
layers {
name: "data"
type: DATA
top: "data"
top: "label"
data_param {
source: "./catnet_train_lmdb"
backend: LMDB
batch_size: 50
}
transform_param {
mean_file: "./data/catnet_mean.binaryproto"
crop_size: 227
mirror: true
}
include: { phase: TRAIN }
}
layers {
name: "data"
type: DATA
top: "data"
top: "label"
data_param {
source: "./catnet_val_lmdb"
backend: LMDB
batch_size: 50
}
transform_param {
mean_file: "./data/catnet_mean.binaryproto"
crop_size: 227
mirror: false
}
include: { phase: TEST }
}
layers {
name: "conv1"
type: CONVOLUTION
bottom: "data"
top: "conv1"
blobs_lr: 1
blobs_lr: 2
weight_decay: 1
weight_decay: 0
convolution_param {
num_output: 96
kernel_size: 11
stride: 4
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
...
- 学習させるニューラルネットワークの各層の入力数などの設定と繋がり
- protbuffというグーグル謹製の汎用型付データフォーマット
- layersというのが深層学習の繋がり部分の1層らしいです
- top とか bottom は blobと呼ばれるデータの塊への接続
- 重要そうなところは…
include: { phase: TRAIN }
include: { phase: TEST }
type: DATA
type: CONVOLUTION
type: POOLING
type: RELU
type: LRN
type: INNER_PRODUCT
type: DROPOUT
type: ACCURACY
type: SOFTMAX_LOSS
- ↑のあたり?
- phaseは学習時とテスト時に切り替える設定だろうとして…
- 残りは、スライドで得た知識などと併せてみると…
- DATA を
- CONVOLUTION からの
- POOLING して
- RELU とかを繰り返しつつ DROPOUT とか間に挟んで
- INNTER_PRODUCT で SOFTMAX_LOSS な識別してる
- みたいな?
- つまりConvolution Neural Network(CNN) (画像検索LINK) というネットワークのモデルを記述している事が大体わかります。
- さらに情報を集めたところ、
- このネットワークの構成次第で認識できるモノや精度が劇的に変わるらしいです。
- ある意味で回路設計に近いらしいです
- より精度の高くなる構成や研究結果をレイヤーとして実装したものが公開されたりと最先端の研究で日進月歩(比喩ではなく)進化してるらしいです。
ひとまずそれくらいわかれば十分。細かいことは後でじっくりとやろう!
1.まずはcaffeのサンプル読むべきでした(反省)
- こういうのを飛ばしてイキナリ応用編に飛び込むのはダメですね…
- まず猫の御方は何をやっているのかというと、ファインチューニングを使った画像を分類するネットワークの作成です。結構複合的なことをやっておられます。
- 分類するネットワークのところは MNIST という手書き数字認識サンプルがほぼ同じことをしています
- http://caffe.berkeleyvision.org/gathered/examples/mnist.html
- 英文を超訳(超適当な訳の略!)で読んだ限りではですが
- このサンプルの特徴としては、ラベルを振ったデータベースを使って学習させる一連の流れがわかる、という事のようです。
- ラベルを使って、SOFTMAX_LOSS というところらへんでバックプロジェクション(間違ってたら逆にフィードバック)させるネットワークを作って
- あとは俗にいうらしいフルコネクト層で10個の分類(出力)になるよう繋いで正解不正解をもとに学習させてるそうです。
- 豆知識
- フルコネクト層は、caffeでは INNERPRODUCT LAYERって言うそうです。
- for some legacy reason, Caffe calls it an innerproduct layer と書いてあります
- なお、ここら辺はサンプルについてる説明だけでなくチュートリアルでも解説されてます
- http://caffe.berkeleyvision.org/tutorial/net_layer_blob.html
- ↑より引用
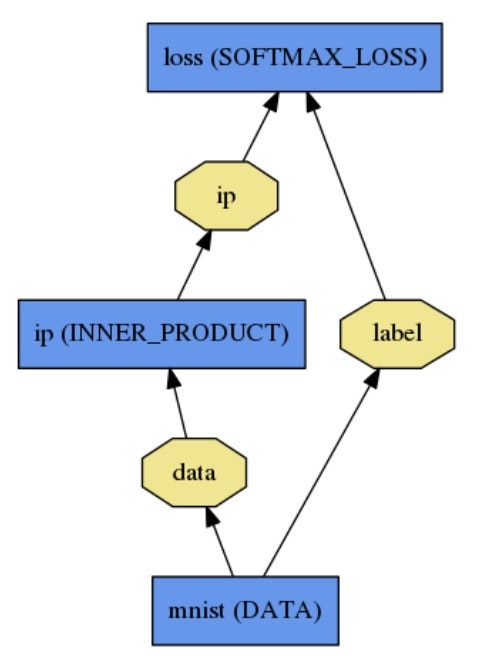
2.さてこのネットワークを使ってリアルタイムに認識させるにはどうすればよいの?
- caffe.Classsifier というpythonのクラスを使えば簡単に出来そうに見えます。
- でも、さっき作ったラベル付でデータベースから学習とテストをさせるモデルの prototxt を渡してもエラーを吐くばかりで動きません
- …なんで?
- 結論として、データベースから読む prototxt はcaffe.Classsifierは扱えないようです
- データベースから読むモデルは学習&テストの時用!
- 学習結果を使って認識するプログラム書く場合は外部からの入力が書かれたモデルのprototxtを用意する必要あるそうです
- そんな視点で、MNISTサンプルの中を見ると lenet.prototxt というファイルがあって、まさにそんな感じの構成でした。
テスト
-
さて学習も終わったのでテスト!
-
ipython notebookをつかってテストします
-
ipythonの参考例は、本家のサンプルにありました
-
pythonのプログラムはこちらの方の投稿を参考に書いてみましたCaffeでDeep Learning つまずきやすいところを中心に
-
https://github.com/haiatto/pepper_caffe/blob/master/cat_test01.ipynb
-
うーん…なんか識別結果が微妙な感じ…どうやって猫とそれ以外を判断すればいいんだろう……うーんーうーん……ん ハッ!?