はじめに
新規自社サービスを開発すると、サービス利用状況の統計出力がしたくなってくる。
また、統計情報はセールスチームや開発チームなどステークホルダに広く展開するべきだろう。
毎月DBやログからデータ取ってきてexcelで図表化は大変なので、自動化&スマートなUIでさくっと仕組みを作ってしまおう。
やりたいこと
- S3に保存されている業務ログからアクセス履歴を統計出力する
- Aurora MySQLからトランザクションデータやマスタデータを統計出力する
- 統計データは可視化されWEBブラウザで関係者に展開できる(もちろんユーザ認証は行う)
- データの更新作業は自動化する
- 本来の開発業務の時間を削ることなく、可能な限りAWSマネージドサービスを利用してサクッと作る
やれること
QuickSightの公式を見るとイメージが湧くだろう。
https://aws.amazon.com/jp/quicksight/
環境
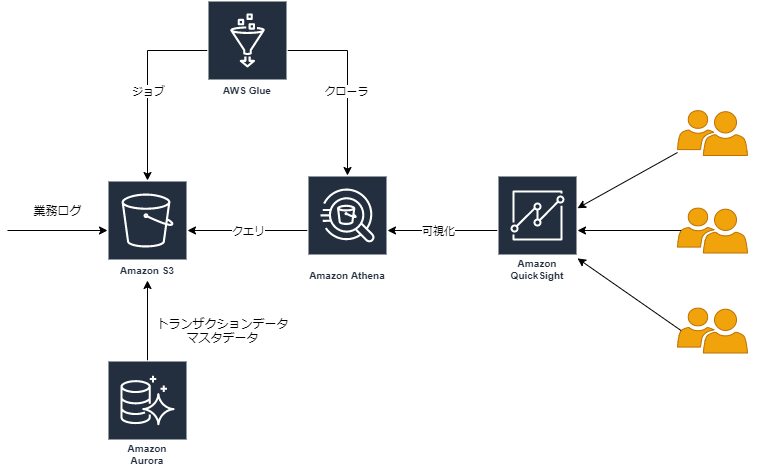
構築ガイド
やりたいことにあるとおり、綺麗さなどは微塵も気にせずにサクッと作る。
S3バケットの準備
Athena用のS3バケットを用意する。
業務ログ用とDB用の2種類用意しておくと使い勝手が良い。
また、後述するAWS Glueジョブ用に使用するjsonファイルを格納するS3バケットも作成しておく。
| バケット名の例 | 備考 |
|---|---|
| logs-athena | 業務ログ用 |
| db-athena | DBデータ用 |
| glue-job | AWS Glueジョブ用に使用するjsonファイル格納用 |
業務ログの抽出
筆者の環境においては、業務ログとALBのアクセスログなど全て同じS3ディレクトリ内に圧縮して出力されていたため、以下の通り統計に必要な業務ログデータのみを抽出した。
- 全量のログファイルを保存しているS3バケットに対してAWS Athenaでテーブル作成
- 全量のログファイルから業務ログのみを抽出
- 業務ログのテーブル化
上記の作業はAWS GlueとAWS Athenaを利用して実現する。
全量ログのテーブル化
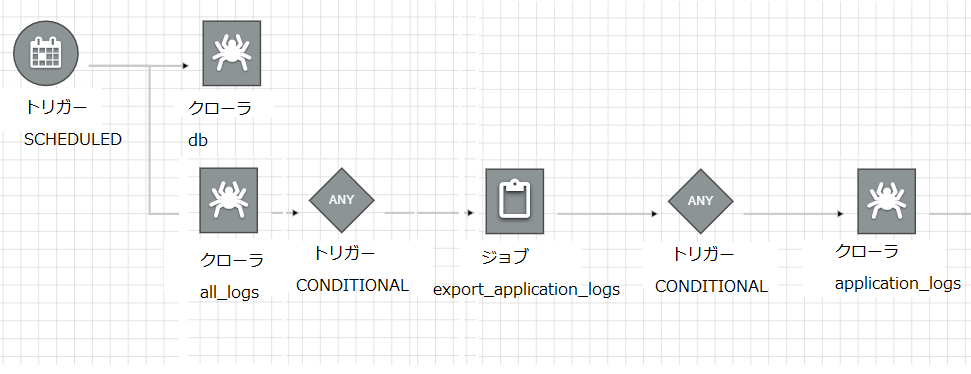
AWS Glueの管理画面において、クローラを作成し、実行する。
実行後、AWS Athenaの管理画面において、all_logsテーブルが作成されており、標準SQLでクエリ検索ができることを確認できるだろう。
| 項目 | 内容 |
|---|---|
| クローラの名前の例 | all_logs |
| crawler source type | Data stores |
| データストア | {全量ログが保存されているS3バケットパス} |
| IAM ロール | (新規作成) |
| スケジュール | オンデマンドで実行 |
| データベース名の例 | logs |
業務データのみを抽出
以下の2つの準備を行う。
- 業務データ抽出用のSQL文を記述したjsonファイルを作成。
- AWS Glueで上記SQLを実行し、結果を上述の
S3バケットの準備で作成した業務ログ用のバケットに保存するジョブを作成。
以下の先達の記事を参照して構築した。
https://dev.classmethod.jp/articles/20180528-aws-glue-etl-job-with-spark-sql/
業務データ抽出用jsonファイルの作成
作成したall_logsテーブルに対して、業務ログのみを抽出可能なSQLを実行することで抽出を行う。
SQL文を記述したjsonファイルをS3上にアップロードしておくことでAWS Glueから実行する。
以下のようなjsonファイルを作成し、上述のS3バケットの準備で作成したAWS Glueジョブ用に使用するjsonファイル格納用S3バケットにアップロードする。
ここで、業務ログメッセージはmessageに格納されており、かつmessageの先頭にapplication-logsが付与されている前提とする。
{
"source_database":"logs",
"source_table":"all_logs",
"target_s3_url":"s3://logs-athena/application_logs/",
"target_format":"parquet",
"sql":"SELECT * FROM stagingtable WHERE message LIKE 'application-logs%'"
}
業務ログ抽出用ジョブの作成
AWS Glueの管理画面において、上記のjsonファイルを読み込み、SQL実行して結果を保存するジョブを作成する。
また、スクリプト編集画面にて、先達の記事を参考にスクリプトを作成する。
ここで、全量ログファイルはjson形式で、かつyear、month、day、hourでHive形式で保存されている前提とする。
| 項目 | 内容 |
|---|---|
| ジョブ名の例 | export_application_logs |
| IAMロール | (新規作成) |
| Type | Spark |
| Glue version | Spark 2.4, Python 3 |
| このジョブの実行 | ユーザーが作成する新しいスクリプト |
| ジョブのブックマーク | 有効化 |
| ジョブパラメータ1(キー) | --extra_job_parameters_bucket |
| ジョブパラメータ1(値) | glue-job |
| ジョブパラメータ2(キー) | --extra_job_parameters_key |
| ジョブパラメータ2(値) | export_application_logs.json |
スクリプトの詳細は先達の記事を参照してほしい。
https://dev.classmethod.jp/articles/20180528-aws-glue-etl-job-with-spark-sql/
業務ログテーブルの作成
AWS Glueの管理画面において、クローラを作成し、実行する。
AWS Athenaにapplication_logsテーブルが作成される。
| 項目 | 内容 |
|---|---|
| クローラの名前の例 | application_logs |
| crawler source type | Data stores |
| データストア | s3://logs-athena/application_logs/ |
| IAM ロール | (先ほど作成したもの |
| スケジュール | オンデマンドで実行 |
| データベース名の例 | logs |
DBデータの抽出
業務ログのみでもほとんどのケースで統計情報は作成可能であるが、業務要件上、バッチ処理等でいくつかのデータはDBに既に統計処理されて保存されているケースが多いだろう。
また、業務ログデータとマスタデータを紐付けておくことで、可視化において何かと便利になる。(IDではなく和名で出力するなど)
業務で利用しているDBを統計に使用する場合、リソース負荷も気になることから、日次等でAthenaにデータ投入しておくことをお勧めする。
DBデータのエクスポート
トランザクションデータやマスタデータなどをcsv出力して、上述のS3バケットの準備で作成したDBデータ用のS3バケットに保存する
例えば、簡易にメンテナンス用の踏み台EC2サーバからcronでcsvエクスポートしてS3にアップロードする場合は、以下のようなシェルをcronに登録しておく。
# !/bin/sh
dir_name=`date "+%Y%m%d_%H%M%S"`
dir=~/s3_sync/
dir_path=${dir}${dir_name}
mkdir ${dir_path}
mkdir ${dir_path}/transactions
mkdir ${dir_path}/master
mysql -hdb.local db -uroot -e "SELECT * FROM transactions" > ${dir_path}/transactions/transactions.csv
mysql -hdb.local db -uroot -e "SELECT * FROM masters" > ${dir_path}/masters/masters.csv
aws s3 sync ${dir_path} s3://db-athena/ --acl bucket-owner-full-control
DBデータテーブルの作成
AWS Glueの管理画面において、クローラを作成し、実行する。
AWS Athenaにtransactionsテーブルとmastersテーブルが作成される。
| 項目 | 内容 |
|---|---|
| クローラの名前の例 | db |
| crawler source type | Data stores |
| データストア1 | s3://logs-athena/transactions/ |
| データストア2 | s3://logs-athena/masters/ |
| IAM ロール | (先ほど作成したもの) |
| スケジュール | オンデマンドで実行 |
| データベース名の例 | logs |
ワークフローの作成
AWS Glueでは、ワークフローを作成し、スケジュール実行することができる。
上記で作成したジョブとクローラをワークフロー化し、日次実行させておく。
DBデータのエクスポートはワークフローに組み込むことはできないので、ワークフロー開始までの時間に十分なバッファを設けておこう。
QuickSightによる可視化
ここまでで、統計出力させるための下準備が完了している。
AWS QuickSightを利用して可視化してみよう。
以下では、業務ログデータにマスタデータを結合し、折れ線グラフでアクセス数の遷移を表示させるケースを例に記載する。
データセットの作成
- QuickSightにログインし、
データの管理から新しいデータセットをクリックする。 -
Athenaをクリックし、以下を入力/選択し、データの編集/プレビューをクリックする。
| 項目 | 内容 |
|---|---|
| データソース名の例 | data_set |
| Athena workgroup | [primary] |
| データベース | logs |
| テーブル | application_logs |
可能であればSPICE利用にし、Athenaへのクエリ課金を抑えることをお勧めする。
SPICEを利用する場合は、定期的にデータ更新する必要があるので、忘れずに更新スケジュール設定も行っておこう。
- データの編集画面に遷移したら、画面上部のデータ追加をクリックし、マスタデータを追加する。
| 項目 | 内容 |
|---|---|
| スキーマ | logs |
| Athena workgroup | [primary] |
| テーブル | masters |
-
結合判定部分をクリックし、結合タイプに
Leftを選択する。結合区はID等のログデータとマスタデータを紐付ける項目を選択する。 -
画面上部の保存をクリックする。
分析の作成
-
新しい分析をクリックし、ユーザのデータセットから先ほど作成したデータセットを選択する。 - ビジュアルタイプに
折れ線グラフを選択する。
| 項目 | 内容 |
|---|---|
| X軸 | Timestamp等の日時データ |
| 値 | ログID等を集計:カウント |
| 色 | アクセス元種別等の和名 |
ここで、業務ログ上はアクセス元種別等のグループ情報はID等の2Byte文字を含まないデータとなっていることがほとんどであるため、DBのマスタデータで対応する和名等を保持していれば、和名をセットすることが望ましい場合が多い。
セールスチームなどで、ビジネス統計をマーケティング活用するために利用する場合において、直感的に判別可能な情報で出力することで利便性が向上する。
ダッシュボードの公開
- 分析画面の右上にある
共有>ダッシュボードを公開をクリックする。 - QuickSightのトップページに戻り、右上の
QuickSightの管理>ユーザを管理>ユーザーを招待から公開したいメンバのメールアドレスを入力する。
終わりに
統計に必要なデータが全てAWS上に保存されている場合、上記の簡単な手順でビジネス情報を統計化し、ダッシュボードを公開することができる。
更に詳細なビジネス分析を行う場合は、物足りない部分が多いと思われるが、顧客要望等でなるべく手間を掛けずに統計出力したい、自動化したい場合は、ぜひ利用することをお勧めする。