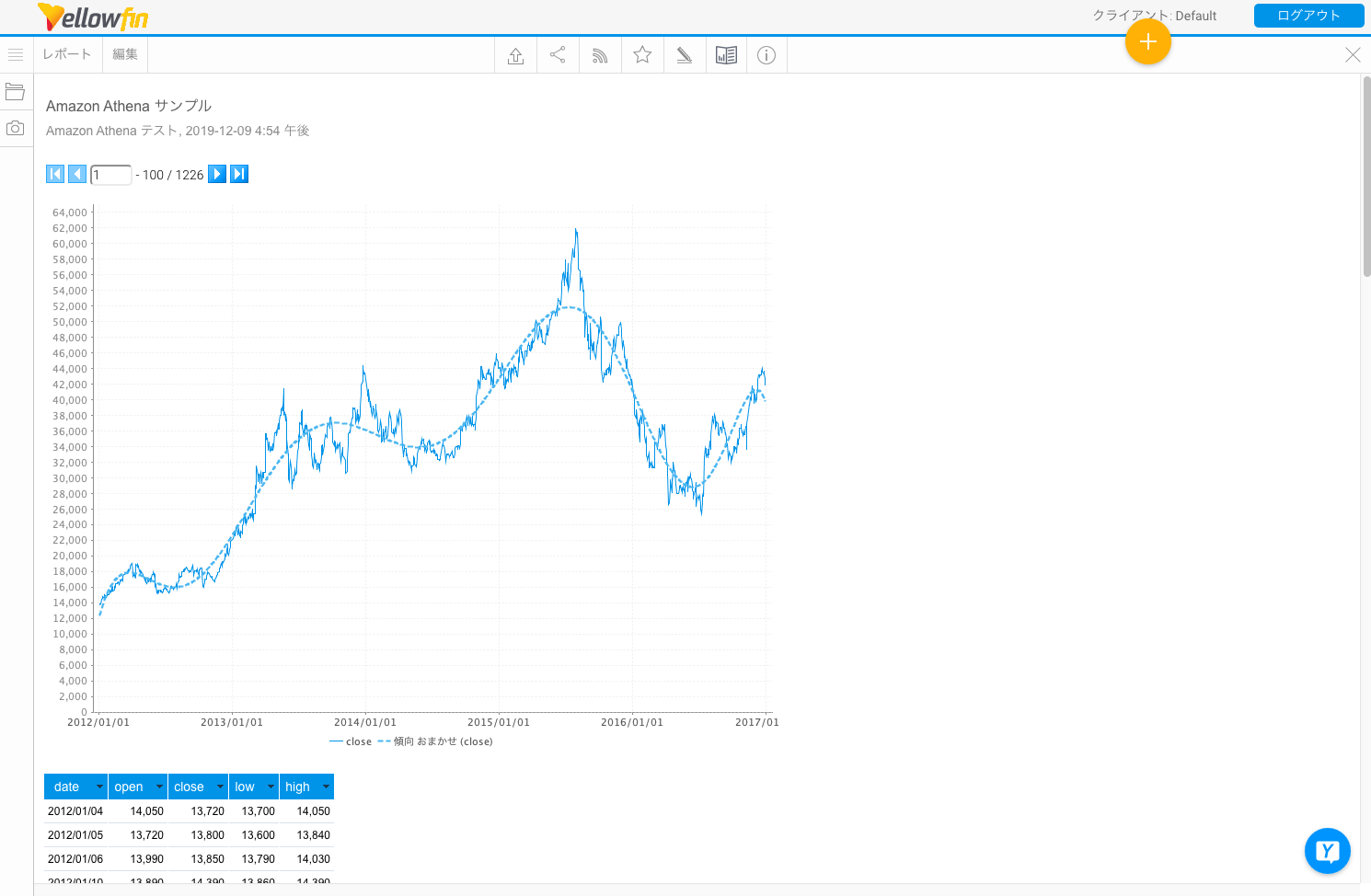
Yellowfin 8.0.2ではAmazon Athenaが正式にサポートされました。この機能を使えば、Amazon S3に保管されたデータを容易に分析することができます。
この記事では、簡単なCSVのファイルを例として、Yellowfin+Athena+S3を連携する手順をご紹介します。
Amazon Athenaとは
Amazon Athenaは標準SQLを使用してAmazon S3内のデータを直接、簡単に分析できるようにするインタラクティブなクエリサービスです。
CSV、JSON、ORC、Avro、Parquetといったさまざまなデータ形式がサポートされており、AthenaのJDBCドライバーを使用して、さまざまなBIツールからAthenaに接続することもできます。
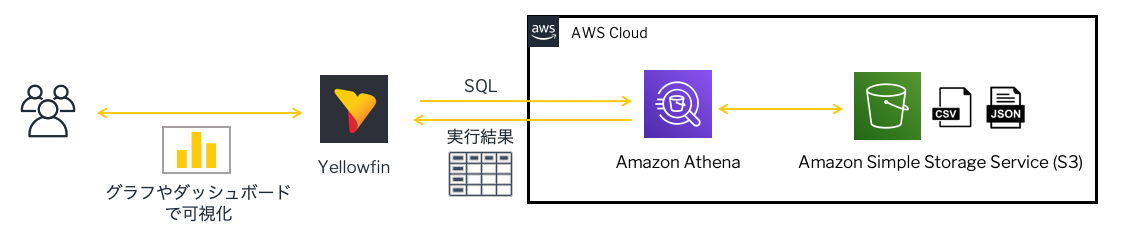
つまり、上図のようにAthenaを中継することによって、S3のファイルをわざわざDBに取り込まなくてもYellowfinの分析対象としてしまえるのです。
Amazon Athenaを使ってみる
それではAthenaを実際に使ってみましょう。やることはざっくり以下の4つです。
- IAMで権限のあるアクセスキーを作成する
- S3にファイルを置く
- Athenaにテーブルを作る
- Yellowfin(BIツール)のデータソースを設定する
IAMで権限のあるアクセスキーを作成する
まず、S3とAthenaへのアクセス権を割り当てます。とりあえず細かいことは考えずに動かしてみたいので、どちらもフルアクセスを直接アタッチしました。
そして、アクセスキーを作成します。アクセスキーIDとシークレットアクセスキーは後で必要になるので、手元にコピーしておきます。
S3にファイルを置く
Amazon S3にファイルを配置します。
今回はKaggleで公開されているユニクロ(ファーストリテイリング)の2010年から2016年の株価データをサンプルとして使用します。
S3にバケット、フォルダを作成し、CSVファイルを配置します。
ただ、ダウンロードしたCSVファイルはそのまま使わず、ヘッダー行の除去を行っています。Athenaを使う場合、こうした前処理はAWS GlueなどのETLで事前に済ませておく必要があります。なお、今回は手作業で除去しました。
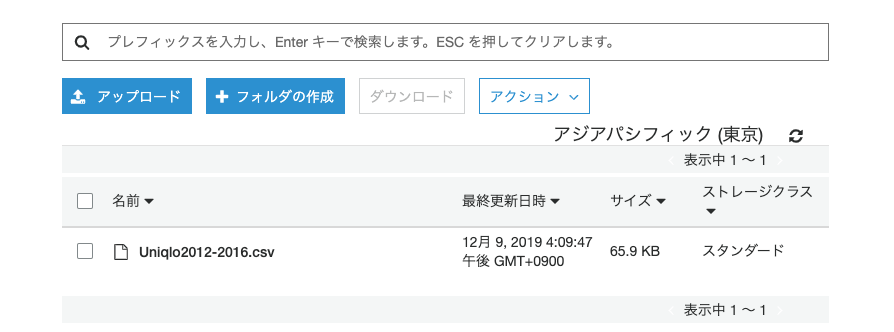
配置したフォルダのパス(s3://バケット名/フォルダ名/〜)が後で必要になりますので、手元にコピーしておいてください。
Athenaにテーブルを作る
Athenaのサービス画面のトップにある「Get Started」をクリックします。
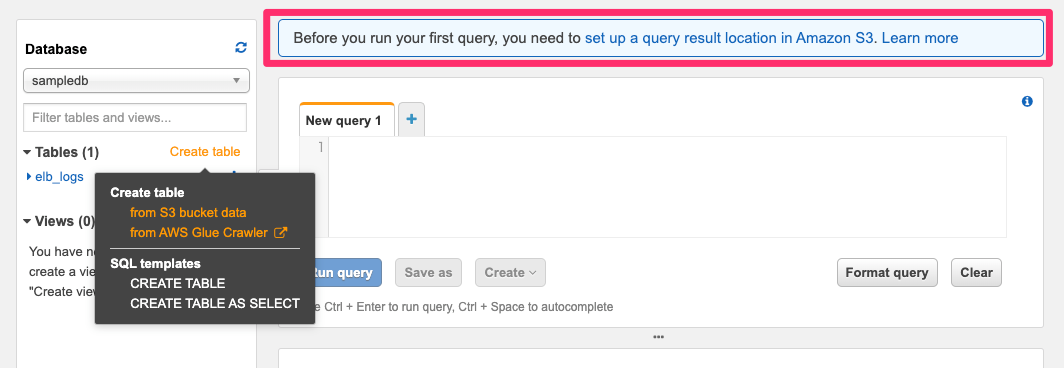
このメッセージが出ているときは、クエリの実行結果の出力先を事前に設定する必要があります。リンクをクリックして、出力先にするS3のフォルダを指定してください。とりあえず動かすだけなら適当なフォルダで大丈夫です。
この出力先も後で必要になるので、手元にコピーしておいてください。
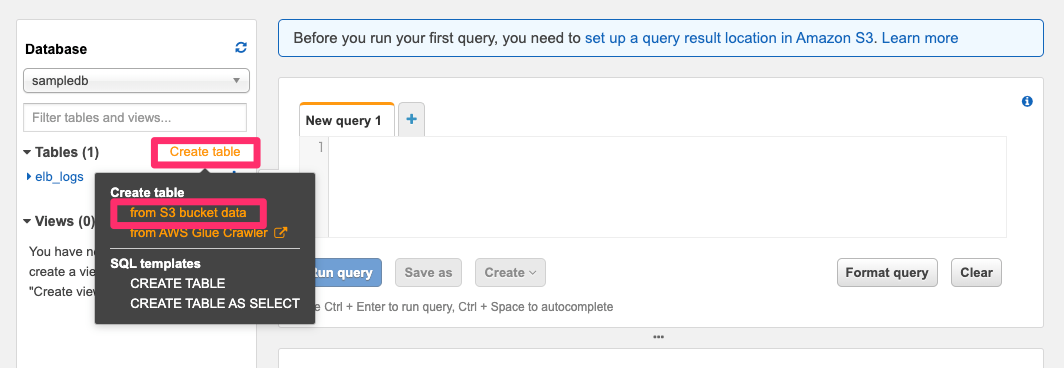
「Create Table」→「from S3 bucket data」と進みます。
データベース名、テーブル名と、CSVを配置したフォルダのパスを入力します。パスはフォルダまでで、ファイル名は不要です。
データフォーマットは「CSV」を選択します。
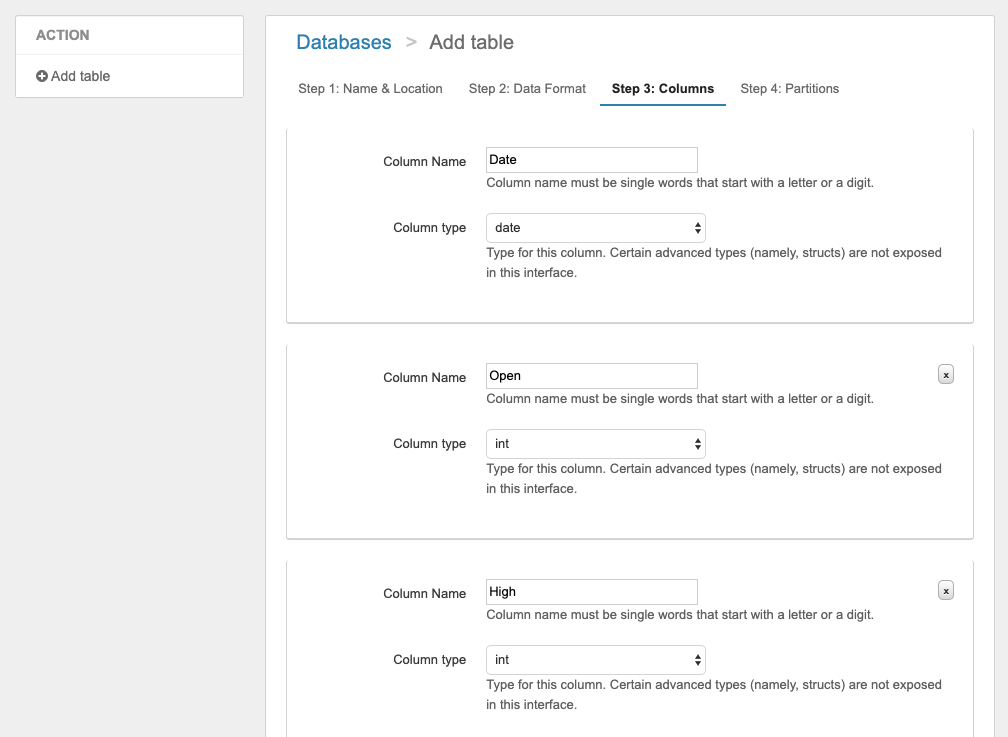
カラムを定義します。今回の例では以下の7つのカラムを定義しました。
- date (date型)
- open(int型)
- high(int型)
- low(int型)
- close(int型)
- volume(bigint型)
- stock_trading(bigint型)
パーティションは特に追加せずにテーブルを作成します。
テーブル作成が成功したらResultsに「Query successful.」と表示されます。
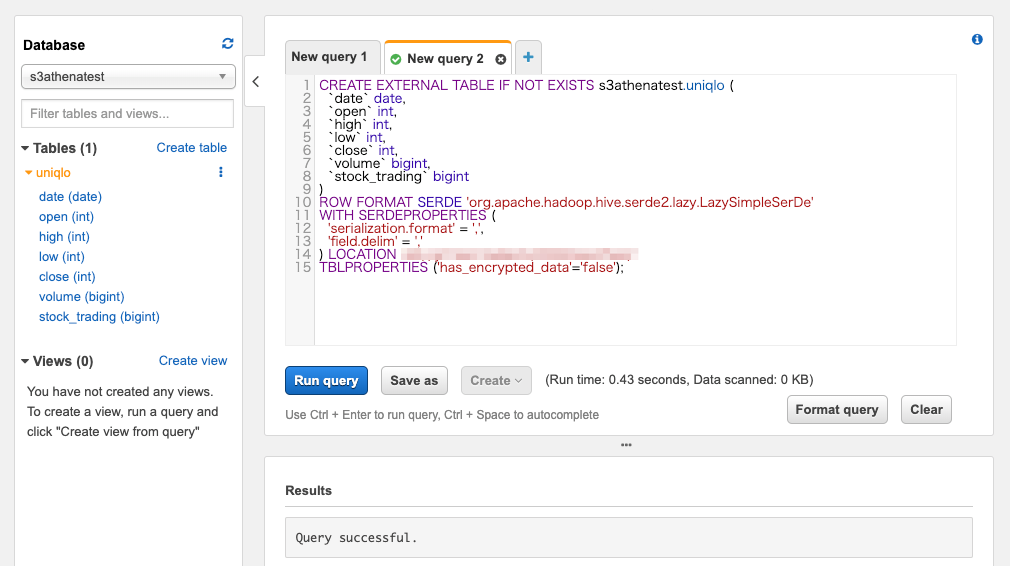
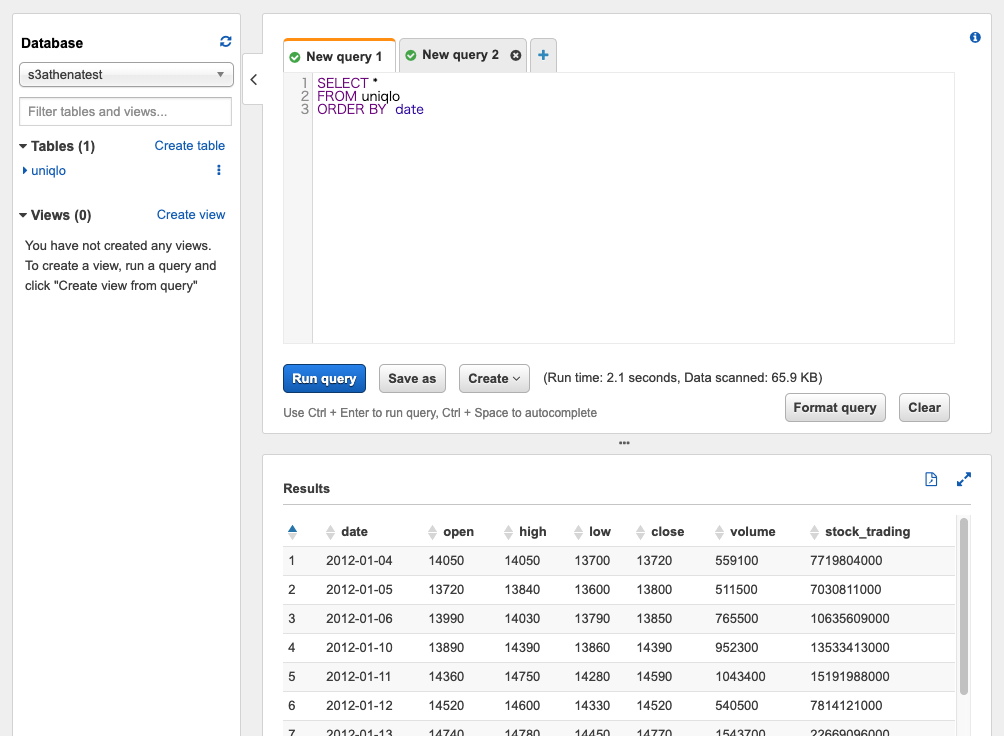
Athenaの画面上でクエリを実行してみると、CSVファイルを探索した結果が返ってきました。
Yellowfinのデータソースを設定する
JDBCドライバの入手
AWSから提供されているAthenaのJDBCドライバを入手します。ご自身の環境に合わせた適切なものをダウンロードしてください。
プラグインの追加
Yellowfinのメニューの「管理」→「プラグイン管理」から、入手したJDBCドライバをプラグインとして追加します。
データソースの追加
プラグインを追加すると、データソース作成時にデータベースタイプ「Amazon Athena」が選択可能になります。
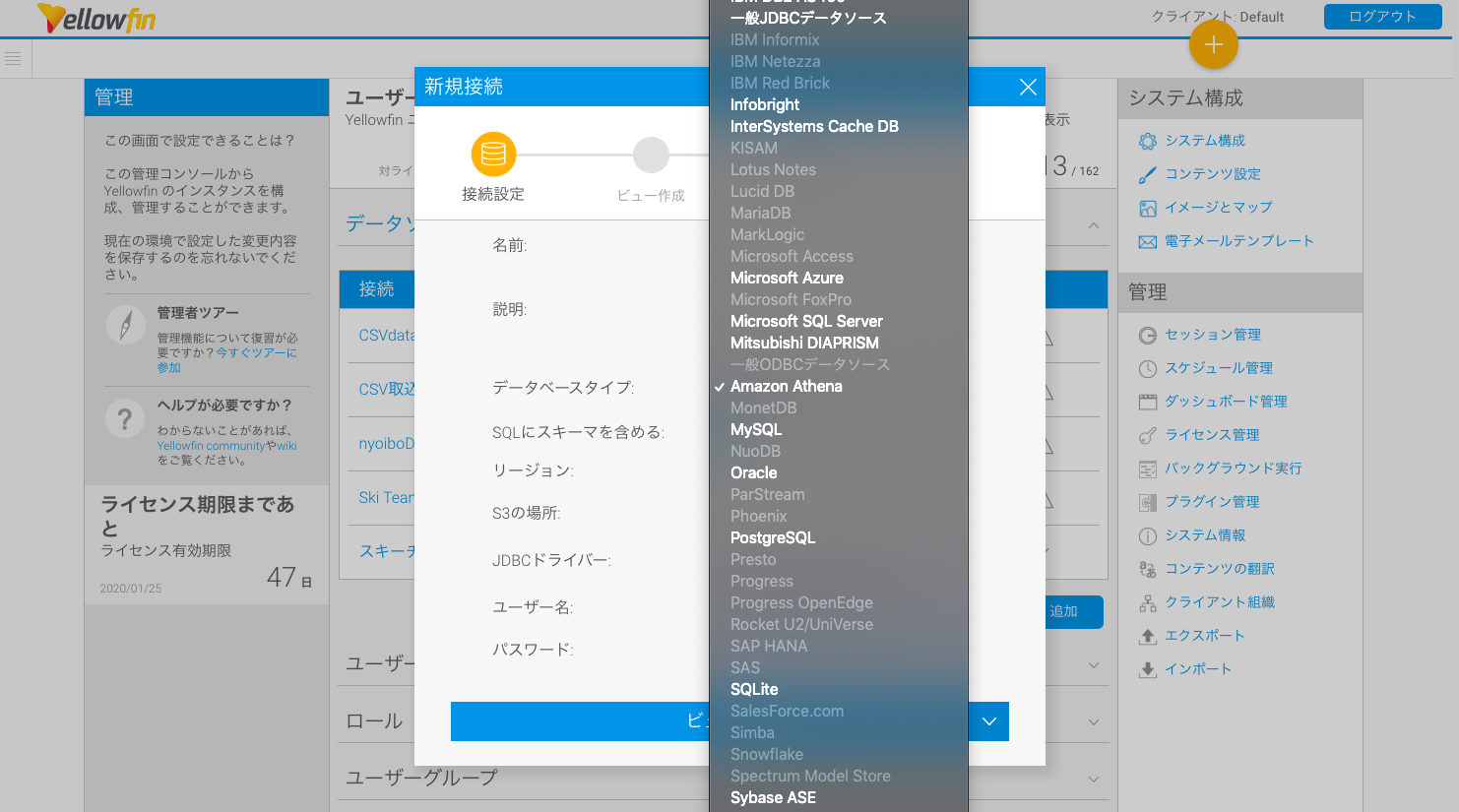
以下の4箇所を入力します。
- リージョン:AWSのリージョン名
- S3の場所:上記手順で設定したクエリ実行結果の出力先のパス
- ユーザー名:上記手順で設定したアクセスキーID
- パスワード:上記手順で設定したシークレットアクセスキー
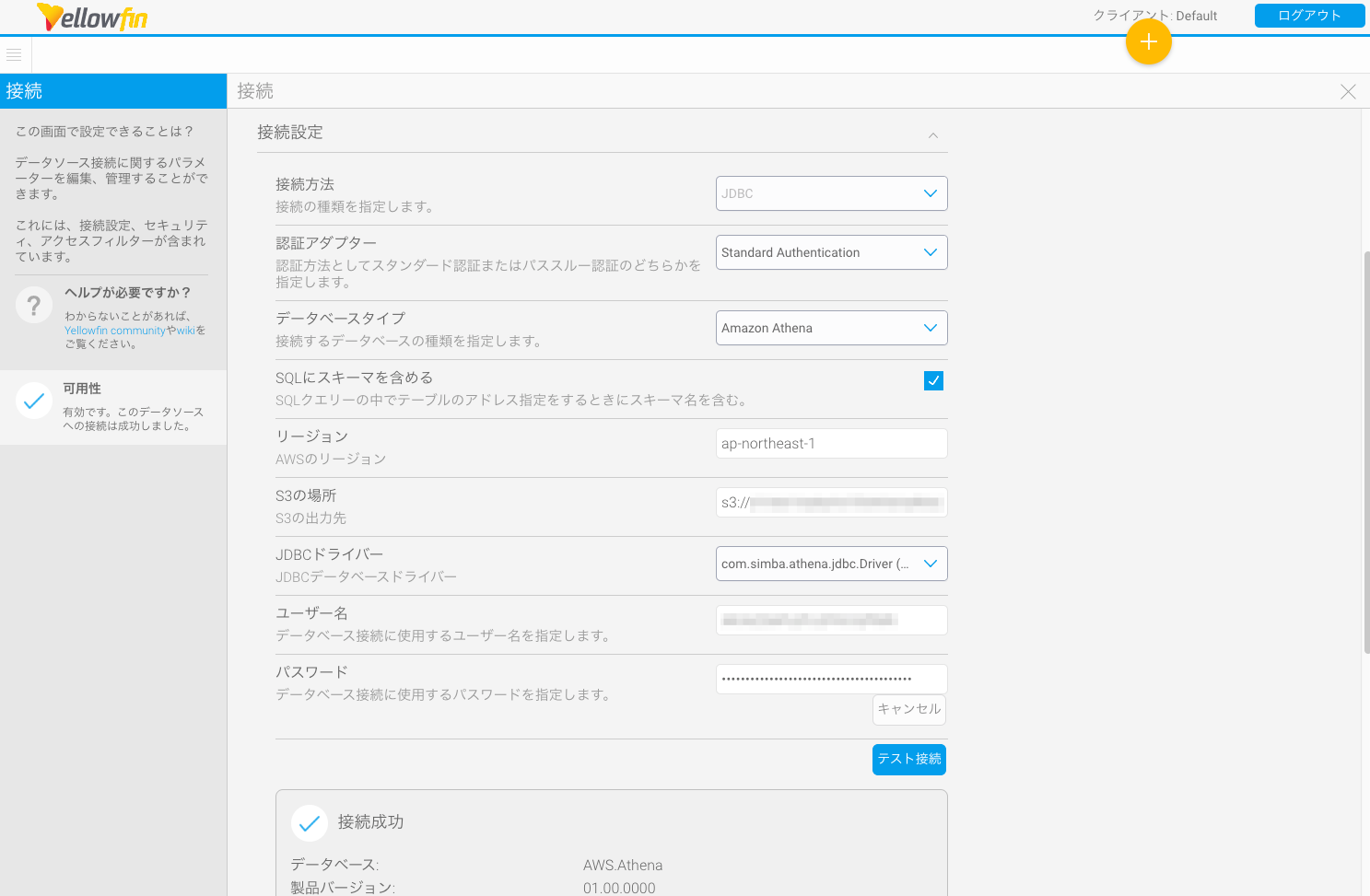
接続に成功すれば、あとはごく普通にビューやレポートを作成することが可能です。