伝えたいこと
MSTICpyを用いてSplunkからデータを取得するいくつかの方法の紹介します。
現在の最新リリースバージョン v2.4.0 にて、SplunkGeneral.get_events_parameterized関数から呼ばれるJob.results()のSplunk SDK Pythonを処理する際に先頭100件しか取得できないバグを発見したため、コードを修正し提案しました。そのPull Requestが本家レポジトリにマージされたので、そのパッチ適用についての共有です。
なお本バグの修正コードは次バージョン v2.5.0にて自動で適用される予定です。
追加: 2023.05.27 v2.5.0がリリースされました。よってv2.5 以上の最新バージョンを利用することでバグを回避できます。https://github.com/microsoft/msticpy/releases
※ 「MSTICPyとは?」については以前投稿しましたこちらをご参考ください。
https://qiita.com/hackeT/items/fabf6d7f76052f15cb26
MSTICpyでSplunkのデータを取得するには
MSTICpyでSplunkのデータを取得するにはQueryProviderというデータコネクターおよび組み込みサーチ関数の機能を利用します。
QueryProviderはSplunk以外にも、Microsoft SentinelやDefenderといった他のベンダーリソースへの接続もサポートしており、Splunkからのデータ取得用のコネクターは Splunk Providerと呼ばれます。
https://msticpy.readthedocs.io/en/latest/data_acquisition/SplunkProvider.html
上記リンク先に英語ではありますが、Splunk Providerの設定方法とデータ取得サンプルがあります。また以下のレポジトリのNotebook In [17]: より Splunkからのデータ取得方法についてのデモがありますので素直に実行した際のエラーなどの参考になると思います。
https://github.com/Tatsuya-hasegawa/MSTICPy_utils/blob/main/msticpy_light_tutorial.ipynb
msticpyはインストール済みという想定で、かいつまんで紹介します。
追加ライブラリのインストール
pip install msticpy[splunk]
A. Splunkのクレデンシャルをハードコードした接続
import msticpy as mp
mp.init_notebook()
splunk_uri = "localhost"
splunk_user = "api_msticpy" # ダミー例
splunk_password = "dummypassword" # ダミー例
qry_prov = mp.QueryProvider("Splunk")
qry_prov.connect(host=splunk_uri, username=splunk_user, password=splunk_password)
これによりlocalhost:8089 のSplunk REST APIにアクセスし、認証を試みます。Splunkとの接続に成功するとconnectedとレスポンスが返ってきます。うまく接続できない場合は、上記REST API接続するユーザー(splunk_user)のroleに、adminもしくはsplunk-system-roleが付与されていることをご確認ください。
検証したところ、単なるuserやpowerのロールのみでは失敗しました。
B. msticpyconfig.yamlにクレデンシャルを登録した接続
msticpyconfig.yamlに対象のSplunkとユーザー情報を登録し、Pythonコード内にハードコードでの指定をしない方法もあります。
msticpyconfig.yaml内に以下のようにSplunkセクションをDataProvidersのセクションを追加します。(localhost:8089がSplunk REST API接続先の例、v2.6.0以上を利用している場合はポート番号をクオテーションで囲って文字列にしないとエラーが出ます。)
DataProviders:
Splunk:
Args:
host: localhost
port: "8089"
username: "api_msticpy" # ダミー例
password: "dummypassword" # ダミー例
msticpyconfig.yamlを利用した場合、init_notebook()の実行中に上記設定がロードされます。
import msticpy as mp
mp.init_notebook()
splunk_prov = mp.QueryProvider("Splunk")
splunk_prov.connect()
Splunkからのデータ取得方法
A. 任意のSplunkクエリをexec_query関数にて実行する (Adhoc)
SPLを指定してクエリを実行します。msticpyではQueryProviderで取得したデータの戻り値はpandas DataFrameになります。
splunk_query = '''
search index="_internal"
| head 5
| table *
'''
df = splunk_prov.exec_query(splunk_query)
B. 組み込み関数を利用する
Query ProviderにはSPLが自動で関数内に埋め込まれている組み込み関数がいくつかあります。
組み込み関数の一覧を表示するには list_queries()をコールします。
In:
splunk_prov.list_queries()
Out:
['Alerts.list_alerts',
'Alerts.list_alerts_for_dest_ip',
'Alerts.list_alerts_for_src_ip',
'Alerts.list_alerts_for_user',
'Alerts.list_all_alerts',
'Authentication.list_logon_failures',
'Authentication.list_logons_for_account',
'Authentication.list_logons_for_host',
'Authentication.list_logons_for_source_ip',
'SplunkGeneral.get_events_parameterized',
'SplunkGeneral.list_all_datatypes',
'SplunkGeneral.list_all_savedsearches',
'audittrail.list_all_audittrail']
それぞれ目的に沿って必要最低限のSPLが事前に組み込まれています。例えばSplunkGeneral.get_events_parameterized関数がその中でも最も汎用的ですが
print引数を与えると、クエリを発行する前に事前にどういうクエリがSplunkで実行されるかを確認できるので便利です。以下は、Splunk BOTS v2のデータに対する試行です。
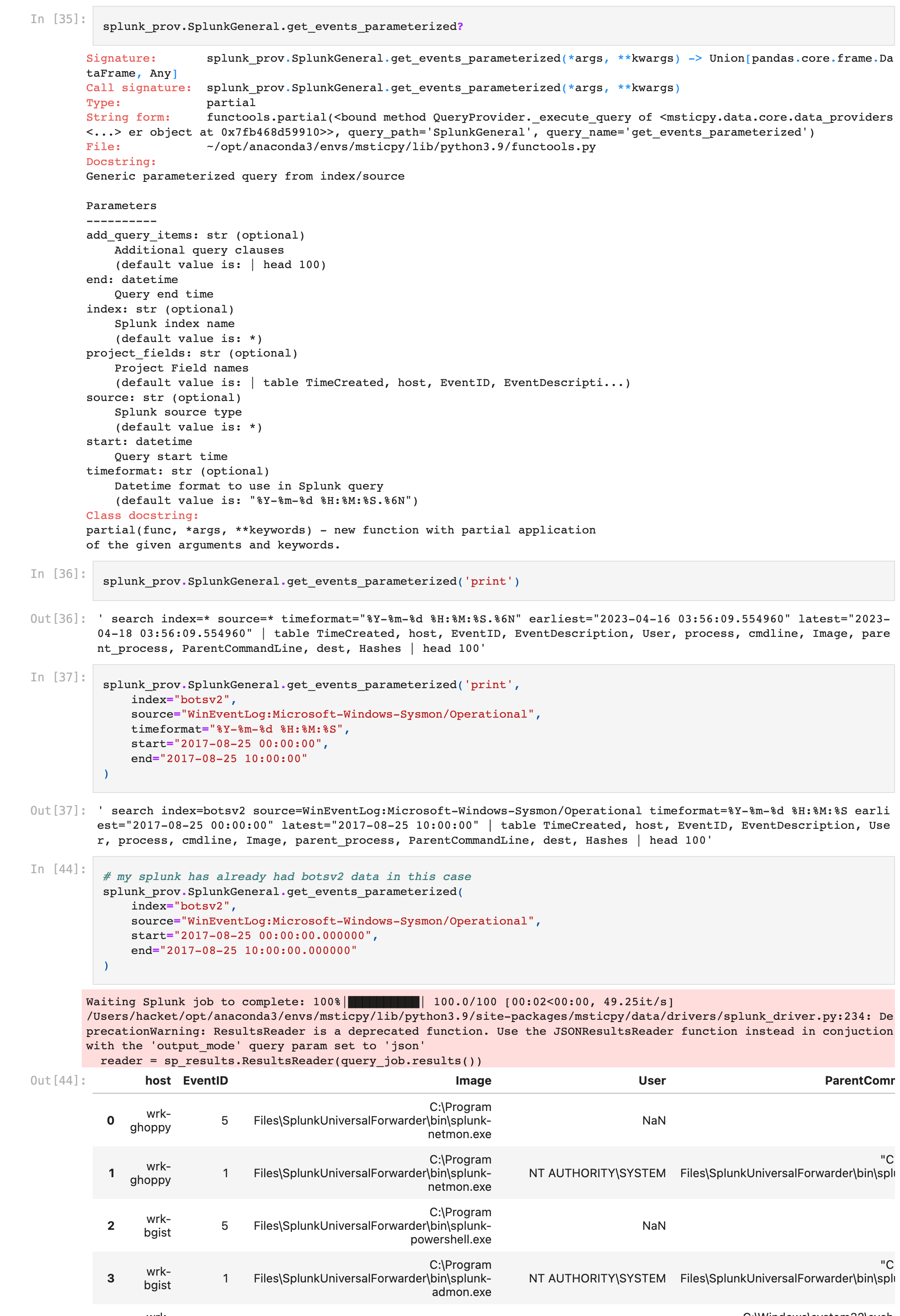
先頭100件しか取得できないバグとその原因
SplunkGeneral.get_events_parameterized関数に先頭100件しか取得できないバグを発見しました。
Splunk Enterprise 8.2.3と9.0.4で確認した際のPoCがこれらです。
https://github.com/Tatsuya-hasegawa/MSTICPy_utils/blob/main/qp_splunk_poc_bugfix/msticpy_splunk_reader_bug.ipynb
https://github.com/Tatsuya-hasegawa/MSTICPy_utils/blob/main/qp_splunk_poc_bugfix/msticpy_splunk_9_0_4_reader_bug.ipynb
本来、100件しか取得できないのはSplunkGeneral.get_events_parameterized関数のデフォルトの挙動として正しいです。なぜならデフォルトでは組み込みSPLの末尾に | head 100が自動付与されるためです。
一方でadd_query_itemsオプションやcount=0オプションを付与すると、このhead 100の制限を外すことができる仕様でした。参考: https://msticpy.readthedocs.io/en/latest/data_acquisition/SplunkProvider.html#running-pre-defined-queries
しかしながら最新版のv2.4.0では、このadd_query_itemsオプションやcount=0オプションを付与しても結果が100件しか返ってきませんでした。
バグはいつから?
2022年6月が最終コミットのこのチュートリアルNotebookでは、Out[9]をみる限り100件以上の取得に成功していました。
よって、このバグはその後のmsticpyもしくはSplunk SDKのバージョンアップに起因するものと考えています。
バグの原因
Splunk Python SDKのnormal searchを指定した検索ジョブを生成し、ジョブが完了した後、ページネーション処理が施されていないことが原因でした。
つまりSplunkの内部では検索ジョブ自体は正常に走り100件以上の件数の結果を保持していましたが、REST API経由での取得が最初の100件以外は取得していなかったようです。
v2.4.0のバグを含むコード↓
# Set mode and initialize async job
kwargs_normalsearch = {"exec_mode": "normal"}
query_job = self.service.jobs.create(query, **kwargs_normalsearch)
・・・
reader = sp_results.ResultsReader(query_job.results())
normal searchのquery_jobs.results()はジョブの検索結果に対するストリーミングハンドルを返すため、先頭の100件しか取得できません。
ちなみに、SplunkのSDKにはNormal,Blocking,One-Shot,Exportの4つのサーチモードが用意されています。
参考 https://dev.splunk.com/enterprise/docs/devtools/python/sdk-python/howtousesplunkpython/howtorunsearchespython/
Searches run in the following modes, which determine when and how you can retrieve results:
Normal: A normal search runs asynchronously. It returns a search job immediately. Poll the job to determine its status. You can retrieve the results when the search has finished. You can also preview the results if "preview" is enabled. Normal mode works with real-time searches.
Blocking: A blocking search runs synchronously. It does not return a search job until the search has finished, so there is no need to poll for status. Blocking mode doesn't work with real-time searches.
One-shot: A one-shot search is a blocking search that is scheduled to run immediately. Instead of returning a search job, this mode returns the results of the search once completed. Because this is a blocking search, the results are not available until the search has finished.
Export: An export search is another type of search operation that runs immediately, does not return a search job, and starts streaming results immediately.For searches that produce search jobs (normal and blocking), the search results are saved for a period of time on the server and can be retrieved on request. For searches that stream the results (one-shot and export), the search results are not retained on the server. If the stream is interrupted for any reason, the results are not recoverable without running the search again.
この中でmsticpyのSplunk Providerで提供されているのは
- Normal 検索 (非同期、ジョブステータスの確認が必要、 結果の取得にJobs.results()を利用)
- One-shot 検索 (同期、ジョブステータスの確認が不要、 結果の取得にJobs.oneshot()を利用)
の二つのみです。
ワークアラウンド(即座にできる軽減策)
One-shotモードのサーチを利用すると、検索が完了した際にその結果レコードを返すBlocking検索が実行されるため、今回のバグの影響を受けません。非同期のストリーミングによる取得ではなく、一括取得になるため、100件を超えて取得できました。
One-shotモードを呼び出すにはSplunkGeneral.get_events_parameterizedに oneshot=True というオプションを付与すると利用できます。
ただし、service.confs["limits"]["restapi"]["maxresultrows"]を制限にしており
limits.confのrestapiに関するmaxresultrowsを変更しなければデフォルトでは50000件しか取れない制約になっています。
バグの修正
今回のバグはSplunkDevの公式ドキュメントのTo-paginate-through-a-large-set-of-resultsを参考に、現在どこまで取得できているかのoffsetと一度に幾つのデータを取得するかのウインドウサイズを意味するpage_sizeのパラメータと共にページネーション処理を追加しました。
さらにサーチ時間の上限となるタイムアウトを設けることで対応しました。
これらはSplunkGeneral.get_events_parameterized関数のオプション引数として渡せます。
-
page_sizeデフォルト100イベント page_size=のオプションで変更可能 (Splunk SDK内ではcountという属性名で処理されるので煩わしい) -
timeoutデフォルト60秒 timeout=のオプションで変更可能
修正後のPoC Notebookファイルはこちらです。50000件以上の全件数を取得できているのが確認できます。
※このNotebookファイル内のpaginate_widthの引数名は古く、マージされる際にpage_sizeに変更になりました。
また同時にSplunk SDKのResultReaderが現在では非推奨だったので、Splunk SDKのJSONResultsReaderに変更しました。
こちらが本家msticpyレポジトリへのこのバグ修正のPRです。
https://github.com/microsoft/msticpy/pull/657
コードのリファクタリングを少しコアエンジニアのianhelleに手伝ってもらい、マージされました。
晴れてmsticpyの貢献者としてContributorsリストにも載せてもらえました。
修正パッチの当て方
修正するPythonファイルが一つのみですので、簡単です。
msticpyv2.4.0の既存のdata/drivers/splunk_driver.pyを以下の最新コードに置き換えるのみです。
https://github.com/microsoft/msticpy/blob/main/msticpy/data/drivers/splunk_driver.py
なおこのバグ修正は次のバージョン v2.5.0で正式にリリース版に反映される予定であり、マイルストーンに載っています。https://github.com/microsoft/msticpy/milestone/6?closed=1
あとがき
Splunkのデータをmsticpy側で処理するメリットとしては、少量のデータであれば手軽に他のデータソースのログと相関分析ができたり、Splunkが持っていないデータエンリッチメント機能や機械学習アルゴリズム、グラフ可視化を適用できる点だと考えています。
例えばSplunkのMLTKでは、STLによる季節変動を考慮した異常検出ライブラリはありませんが、
msticpyであればそれをtimeseries_anomalies_stl関数により容易にできます。(過去の投稿より)
SIEMといえど得意不得意はあるので結局最後は適材適所で使い分けてもいいのではないかと最近は感じてきています。
今回のバグの発見とmsticpy本家へのPull Requestを経て、大きなプロジェクトでもどこかにバグは健在しており、
探せば見つかるものだなと実感しました。バグを見つけてツールを切り替えて諦めるのではなく、またバグにカスタムパッチを当てて動くようにしただけで満足せず、OSSとしてのmsticpyに貢献できたのは大きな経験になりました。
また報告した際に、この「Splunk Provider」のアップデートに取り組んでいるチームがいるが、彼らもこのバグに気がついていなかった、すばらしい。とコメントもらえてほっとしました。時間をかけて真相調べてコード修正して報告しても、これは仕様で裏オプションの〇〇を追加するとできるようになるよ、と言われたらショックが大きいですもんね。
ちなみに上で書いたoneshotモードは裏オプションの一つのようでドキュメントには記載されていないが、コードには存在するオプションでした。
OSSプロジェクトごとに多少のコーディングの癖があり、そのプロジェクトのコーディング規約や癖に直していただくことも多いですが、コードを介した開発者同士のふれあいと思って、今後も楽しくPR貢献していこうと考えています。
ご一読ありがとうございました。
Happy msticpying!