伝えたいこと
MSTICPyのtimeseries_anomalies_stl関数による異常検出およびdisplay_timeseries_anomoliesによる可視化が周期・季節変動を考慮した異常検出としてSplunkよりもサクッと利用しやすかったので紹介です。
異常検出 と一概に言っても 何に基づいた異常か 次第で、たとえ同じデータであっても結果が変わります。
いろんなメソッドを適材適所で選択したり、組み合わせたりしましょう。
※ 「MSTICPyとは?」については以前投稿しましたこちらをご参考ください。
https://qiita.com/hackeT/items/fabf6d7f76052f15cb26
異常検出
異常検出についての定義や典型的なメソッドについて説明している書籍や記事はたくさんありますので、ここでは割愛いしますが、知っておくべきことは 異常検出 と一概に言っても 何に基づいた異常か 次第で、たとえ同じデータであっても結果が変わるということです。今回はその一例を紹介したいと思います。
かつてより、異常検出には主に3つのアプローチが唱えられています。
- 外れ値検出
- 変化点検出
- 異常行動検出(異常部位検出)
自分が実行しているロジックがこのどれに当たるのかを理解することは重要だと思います。
特に「Outlier」と書いてあるものは外れ値検出であることが多く、今回紹介する
MSTICPyの関数およびSplunkコマンドらも「外れ値検出」に基づいています。
サンプルデータ
Splunk社が提供しているButtercupgameというWebサーバーへのアクセスログのチュートリアルデータから、いくつかの特徴量フィールドを選択したものをCSVとして保存しました、そのCSVファイルはこちらに配置しています。
サンプルコード
MSTICPyのライブラリ timeseries_anomalies_stl を利用した上記データに対するサンプルコードはこちらからダウンロードできます。
実行環境
Python 3.9.12
msticpy 2.4.0
statsmodels 0.13.5
このNotebookファイルではbuttercupgame_iplocation.csvから ["req_time","bytes","Country","status","action"] のフィールドを抽出しreq_timeを"%Y-%m-%d %H"の日時フォーマットに変更した上で、action="addtocart"に対して1時間ごとのアクセス数をカウントしたものについて異常検出をかけています。
Notebookファイルで今回ポイントとなるのは以下二つのセルです。
1. timeseries_anomalies_stl
from msticpy.analysis.timeseries import timeseries_anomalies_stl
df_count = df_action[['date_clock','count']]
df_count = df_count.set_index('date_clock')
output = timeseries_anomalies_stl(df_count)
msticpy.analysis.timeseriesのライブラリ内のtimeseries_anomalies_stl関数は
statsmodels.tsa.seasonal.STLをインポートしている異常検出用の機能です。
STLはSeasonal and Trend decomposition using Loessの略であり、データが「トレンド・サイクル」に起因しているのか「季節変動」に起因しているのかを区別するのを手助けします。具体的には、時系列データを「トレンド・サイクル」、「季節変動」、「残余」の3つの成分に分解するためにLoess (Locally estimated scatterplot smoothing)を使用して、3つのコンポーネントの平滑推定値を抽出します。
この例ではoutput = timeseries_anomalies_stl(df_count)のようにオプション引数が明示的に付与されておりませんが、実際には、デフォルト値として、以下の値が付与されています。
- seasonal = 7
- period = 24 (Hourly)
- score_threshold = 3
Other Parameters
----------------
seasonal: int, optional
Seasonality period of the input data required for STL.
Must be an odd integer, and should normally be >= 7 (default).
period: int, optional
Periodicity of the the input data. by default 24 (Hourly).
score_threshold: float, optional
standard deviation threshold value calculated using Z-score used to flag anomalies,
by default 3
なお明示的にオプション推定をしなかった理由は、今回利用したButtercupgameのデータが一週間ちょっとのデータであり、seasonalを設定するには短すぎた点とWebサーバーへのアクセスログにおけるperiodは各国からの時差もあるが1日(日次)が妥当だと考えたからです。
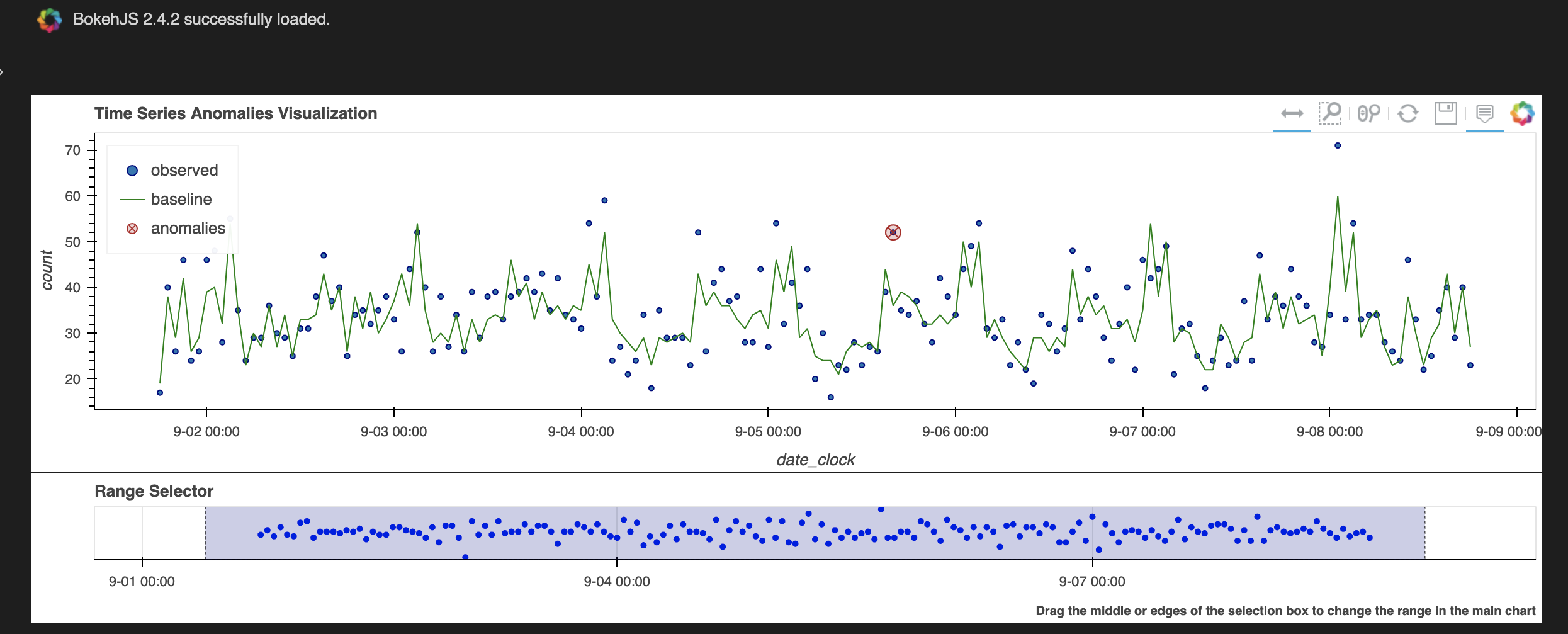
これにより、1時間単位のaddtocartアクションのカウント数としては"2022-09-05 16時"のcount 52が異常だと判断されました。

参考までに追加されたフィールドの説明です。
| フィールド名 | 説明 |
|---|---|
| residual | 残余 |
| trend | トレンド・サイクル |
| seasonal | 季節変動 |
| weight | 外れ値の影響を軽減するために利用される重みづけ |
| baseline | トレンドサイクルと季節変動を加算した値 |
| score | 残余のZスコア |
| anomaries | score_thresholdオプションに対してscoreが上回ったら1(異常判定)になるフラグ |
2. display_timeseries_anomolies
from msticpy.nbtools.timeseries import display_timeseries_anomolies
# display_timeseries_anomolies関数の使用上、事前に結果のタイムフィールドにdatetime型を適用し、かつ時系列順に並び替える
output['date_clock'] = pd.to_datetime(output['date_clock'])
output = output.sort_values(by='date_clock')
timeseries_anomalies_plot = display_timeseries_anomolies(
data=output,
y='count',
time_column='date_clock'
)
このセルでは、obzerved, baseline, anomaliesの3つのデータをプロットするタイムチャートを生成し表示します。ポイントとしてtime_columnに与えるフィールドはdatetime型にしておく必要があります。
またy='count'のyは単なる縦軸のラベル名ではなく、Pandasデータフレーム内のobservedで表示する列名を指定します。
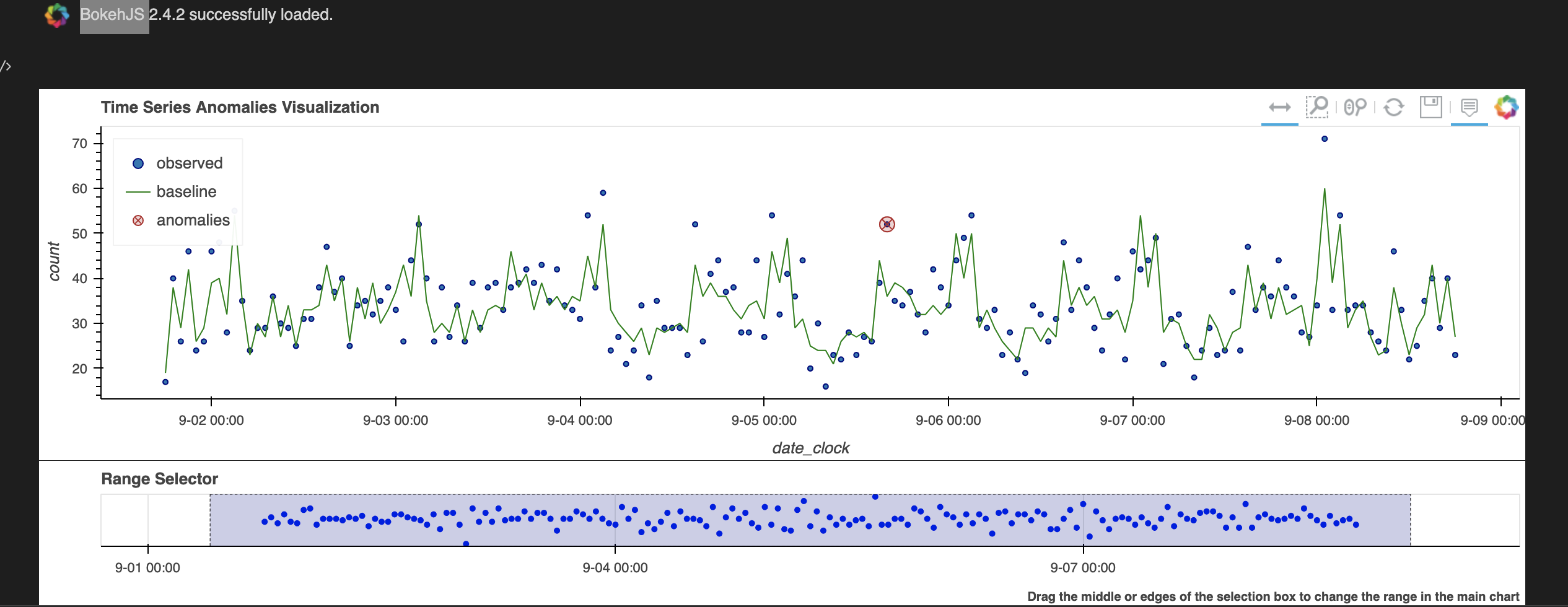
Splunkのanomalydetectionコマンドの例
さて、Buttercupgameのデータが長期的なデータではないので季節変動はあまり影響しませんでしたが、異常値が出ました。次にSplunkで同じように異常検出をやってみます。
SplunkのデフォルトコマンドにはSTLを使った異常検出コマンドがないため、
今回はいくつかの異常検出コマンドのラッパーコマンドである anomalydetection コマンドを利用しました。
https://docs.splunk.com/Documentation/Splunk/9.0.4/SearchReference/Anomalydetection
source="buttercupgame_iplocation.csv" index="msticpy" sourcetype="csv"
| table req_time bytes Country status action
| eval date_clock = strftime(strptime(req_time,"%d/%b/%Y:%H:%M:%S"),"%Y-%m-%d %H")
| eval count = 1
| stats count by date_clock,action
| where action=="addtocart"
| fields date_clock count
| anomalydetection count action=annotate method=histogram
| anomalydetection count action=annotate method=zscore
| anomalydetection count method=iqr action=transform
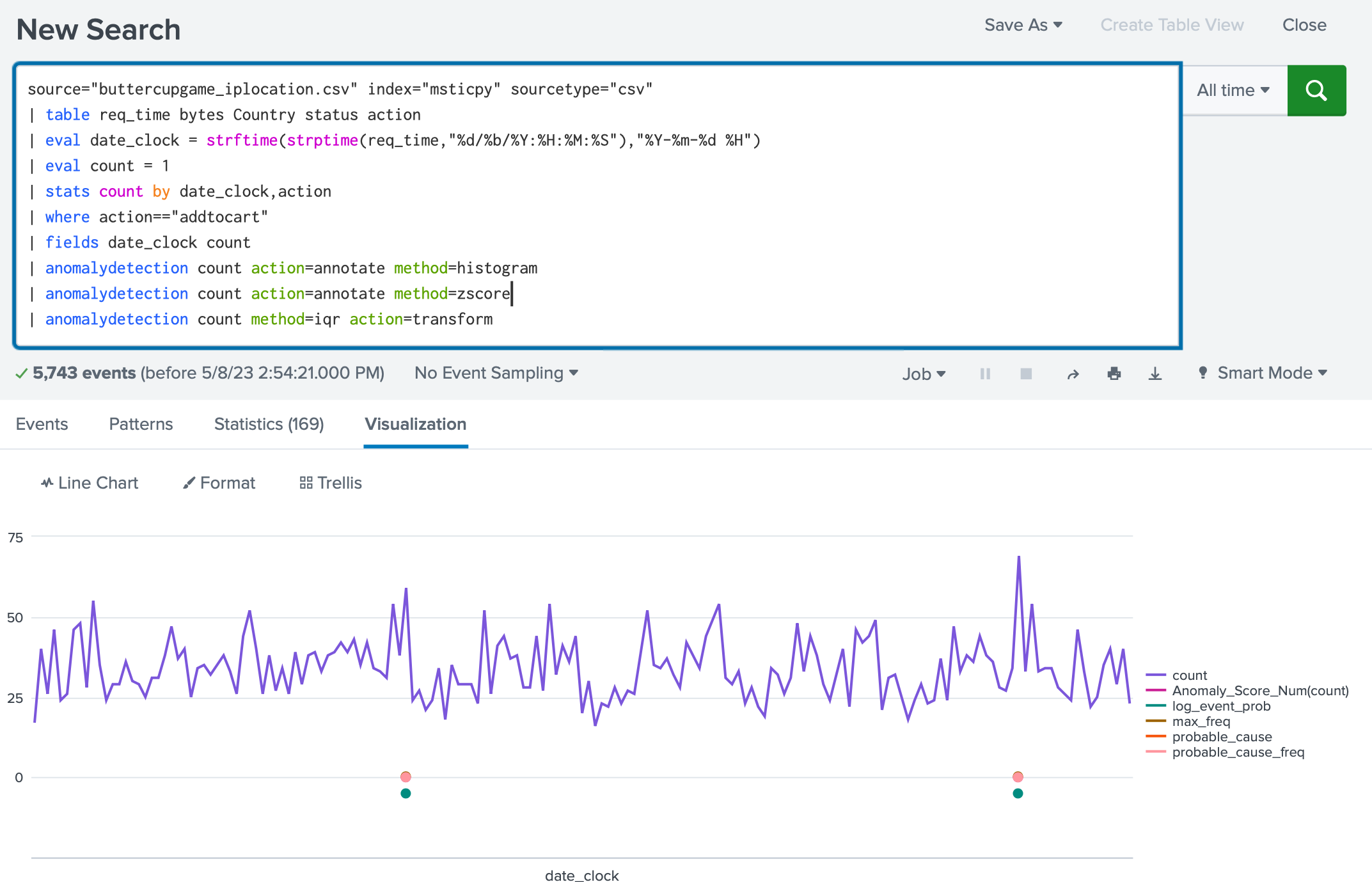
anomalydetectionコマンドのmethod=histgramとmethod=zscoreにて同一の二つの点らがプロットされています。

method=histgramは頻度、つまり標準偏差による外れ値判定を行いmethod=zscoreも全体から見た発生頻度や平均値からの乖離を用いて異常スコアを計算し、外れ値判定をするものであるため類似しています。そしてこの二つはカウントの最も多い二つを検出しておりピーク検出に近い結果となりました。
最後のmethod=iqrは outlierコマンドのラッパーであり、指定したフィールドについて、四分位範囲(IQR)を用いて外れ値を検出するものでしたが、検出はありませんでした。
このようにサイクル変動を気にしない異常検出のアルゴリズムとMSTICPyでSTLを用いたサイクル変動を考慮するものでは、たとえ短いデータでも検出されるものが異なることがわかりました。あとは閾値のパラメータのチューニングや特徴量となるフィールドの選定と加工のトライアンドエラーにより、正しい道を切り開く時間になると思います。この辺をChatGPTをはじめとする生成系AIやDeepLearningなどの特徴量選定およびパラメーターの最適化を自動で行うAIを用いて効率化いきたいものです。
余談ですが、Splunkにてサイクル変動を考慮するコマンドとして predictコマンドというものがありperiodで周期を指定できますのでご興味あれば試してみてください。
今回はMSTICPyの timeseries_anomalies_stl関数の紹介でしたので、検出結果への考察はこの辺にします。
SplunkではMLTKを利用することでPythonの statsmodelsライブラリを利用できるでしょう。
Python for Scientific ComputingのAppに numpy, scipy, pandas, scikit-learn と statsmodelsのライブラリが含まれているためです。
(付録) Splunk MLTKの例
ざっと外れ値検出するMLTKの機能に「Smart Outlier」というものがあります。Density(密度)、つまりカーネル密度推定に基づいて判定します。
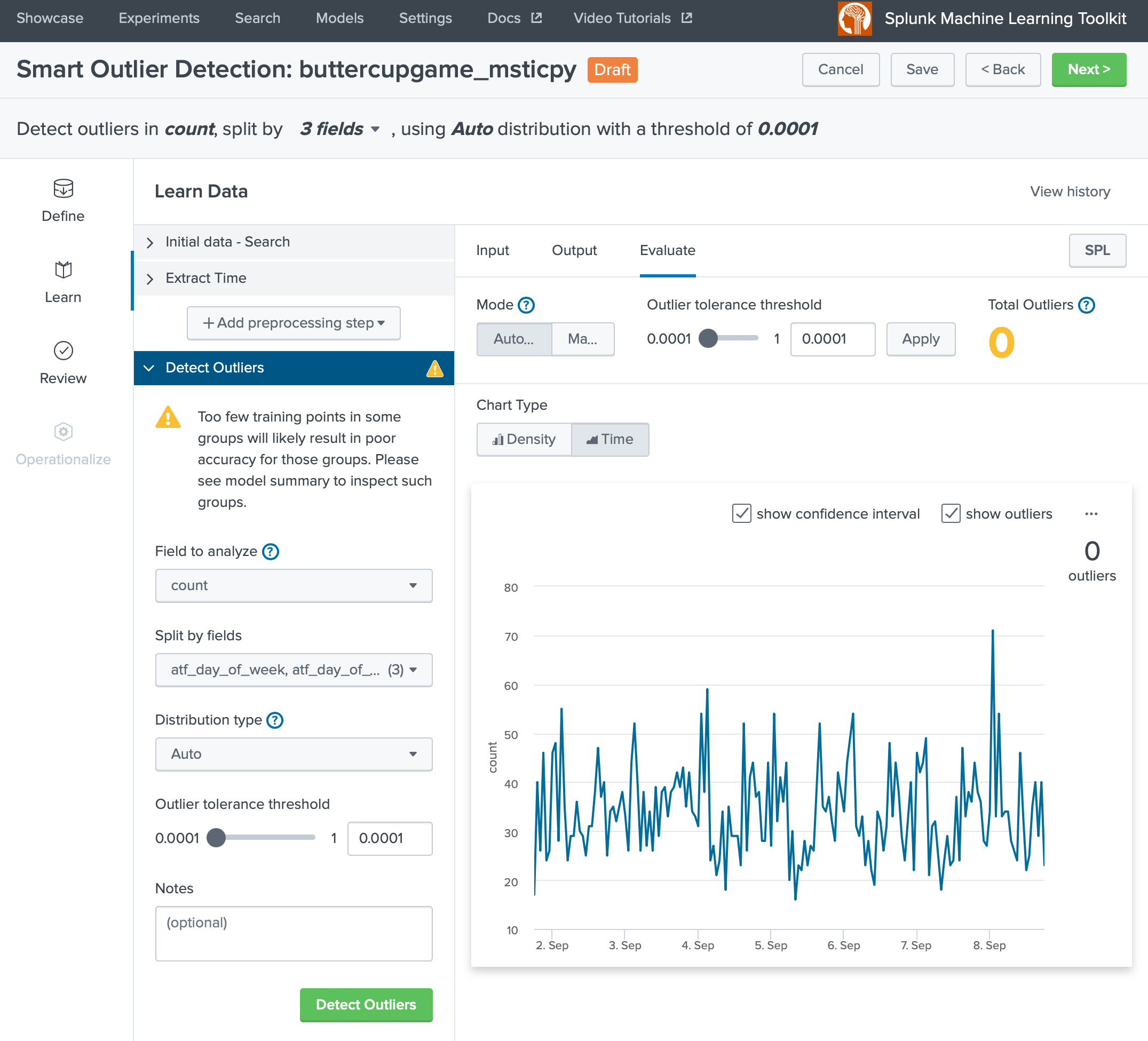
残念ながら、閾値を一番下げても Total Outliers が 0 であり、異常検出されたデータはありませんでした。
Warning▲を見るとデータが少なすぎて精度を担保できないとありました。anomalydetectionコマンドが利用するような統計処理ではなく、機械学習アルゴリズムを利用する場合は、ある程度のデータ量と特徴が必要のようです。
(付録) Splunk DSDLの紹介
Splunk App for Data Science and Deep Learning (DSDL)には、STLを実装している機械学習モデルがありました。こちらはApp内のサンプルデータに対する実行です。
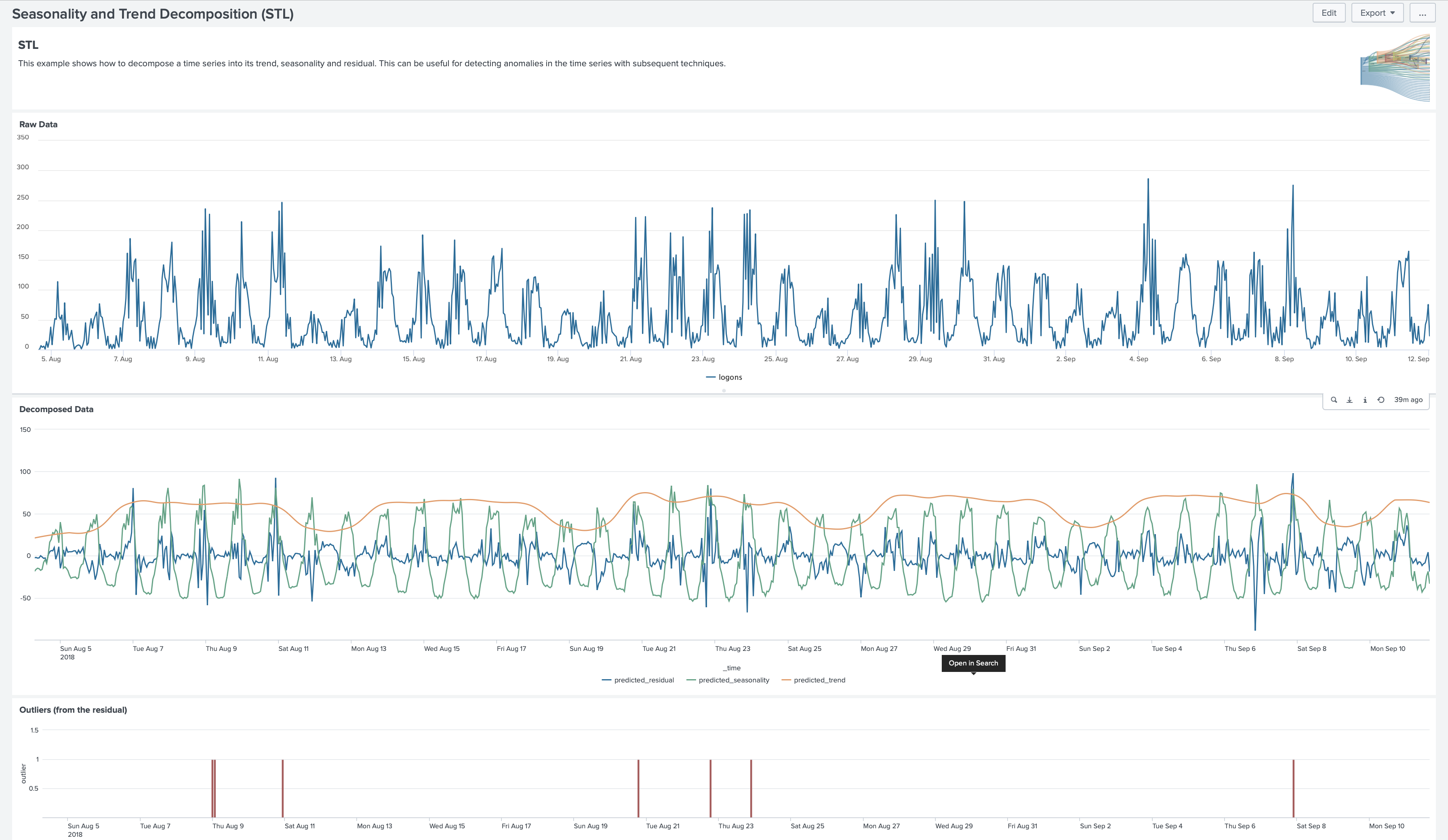
Outlier(外れ値)の検出には、MTLK同様にカーネル密度推定を用いています
outlier=1.0のところのみ抜粋します
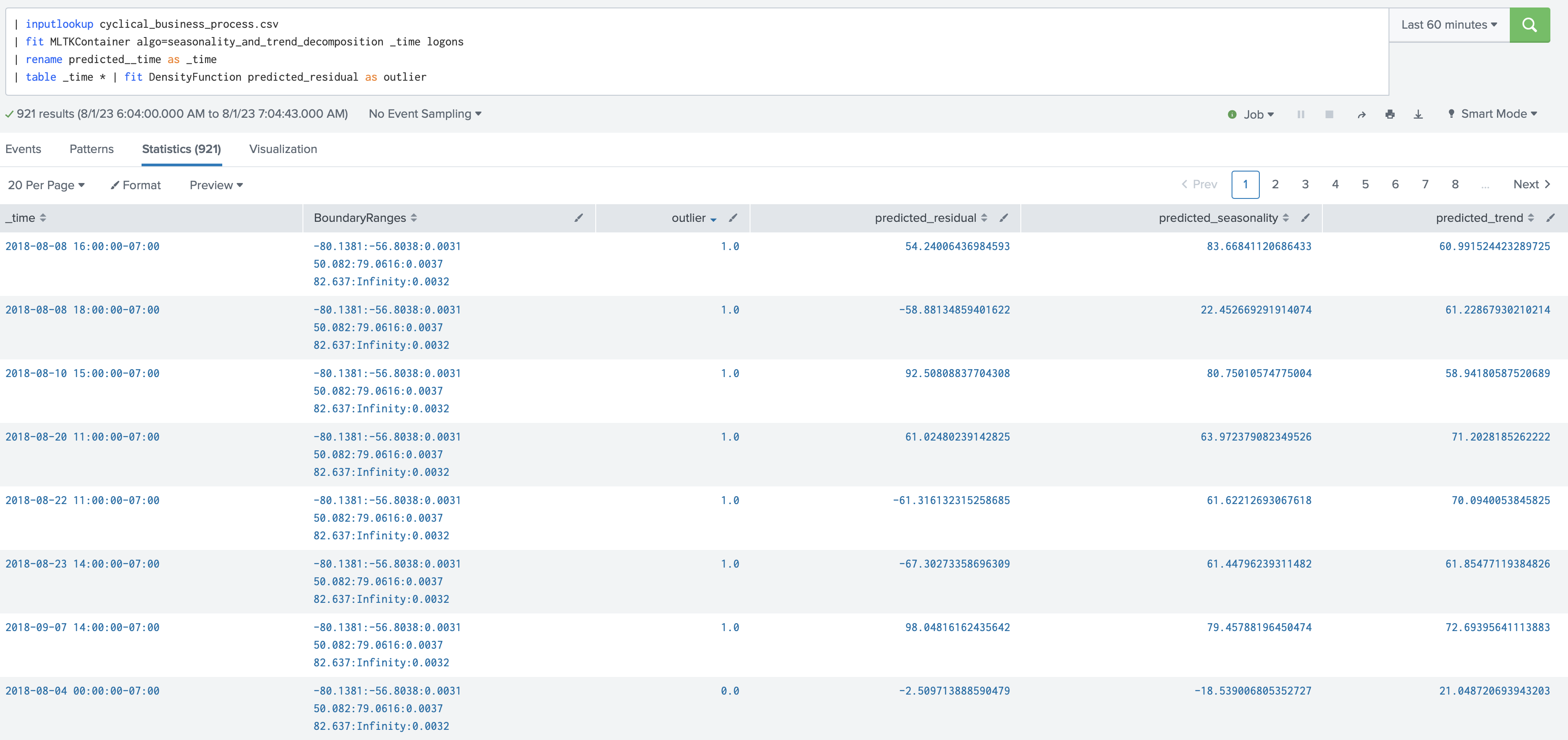
seasonally_and_trend_decompositionのアルゴリズムに沿って、residual,seasonality,trendが出力されていますね。
本日はこの辺で、ご一読ありがとうございました。
Happy msticpying!
引用・参考
Splunk anomalydetection command