Advent Calendar用の投稿です。
概要
ある日、awsの料金が馬鹿みたいにあがりました。普段の10倍くらい上がっていたと思います。
その発覚から原因究明、対策までを記載していきます。
環境
- AWS
- IoTデバイス
システム概要
IoTデバイスからMQTTでデータを送信→IoTCoreで受信→SQS(FIFOキュー)を通してLambdaを起動→RDS(Aurora)に保存
というようなよくあるIoTのシステムです。
ステージング環境と本番環境を持っています。
経緯
発覚
メンバーからのアラートにより発覚しました。金額を見た時は心臓がキュッとなるくらい焦りました。
調査
起こってしまったものは仕方がないと割り切り、一刻も早く解決するために原因を探ります。
状況把握
まずは状況を把握する必要があります。ざっくりまとめとしては以下の状況でした。
- 発生していた環境
- ステージング環境
- 金額が上昇していたサービス
- Lambda(どの関数かは不明)
- CloudWatchLogs
- データの流れ
- IoTCoreで受信したjsonデータを複数のSQSに送る
- FIFOキューをトリガーとしてLambdaを動かす
- LambdaからDBにデータ登録する
- 特記事項
- RDSはコスト削減のため夜間は停止
- 新規追加予定のデバイス試験中
ログの調査
Lambdaの実行情報はCloudWatchLogsに出していましたので、CloudWatchInsightsを使用してエラーログを洗い出しました。
使ったクエリはこんな感じのものです。
fields @timestamp, @message
| filter level = "ERROR"
| sort @timestamp desc
| limit 100
すると、エラーログが山ほど出ていたので詳細を追うことにしました。
まずはエラーを吐いている関数の特定。これはロガーが出力したデータ内にfunction_nameの項目があるので、簡単に特定可能でした。
あとはせっせと対象関数のDEBUGログとコードを見ながら仮説・検証を繰り返して解析していったのですが、ここは割愛します。
原因
一番の原因は送られたデータが想定量の10倍のデータが送りつけられていたことでした。
大きいデータが送られた結果、以下のような事象が発生しました。
- Lambdaで処理がさばききれずにタイムアウト
- 通常1秒以下で終わるLambdaが30秒間動き続ける(!)
- エラーになったので対象データの情報をCloudWatchLogsに出力
- 想定の10倍のログ出力(!!)
- この大容量データ処理に加え、随所でDEBUGログも出力
- FIFOキューを使用していたため、エラーになった大量データがリトライされる
- 以下、無限ループ(!!!)
従量課金ってこういう時恐ろしいですね。
問題点
今回の問題として、以下が挙げられます。
- デバイス側が大きいデータを送ってきてしまう
- クラウド側で問題発生時に気づけなかった
デバイス側の問題は我々ではどうにもできなかったので、クラウド側で問題発生時に気づく必要がありました。
対策
今回の問題、水際で防ぐ方法はいくつかあると思いますが、以下の観点からCloudWatchAlarmを使用することにしました。
- 対策コードを入れられるタイミングではなかった
- Budgetsのアラートは権限が与えられていない
- タイムアウトを短くすると正常な処理でもタイムアウトする可能性が出てくる
設定方法
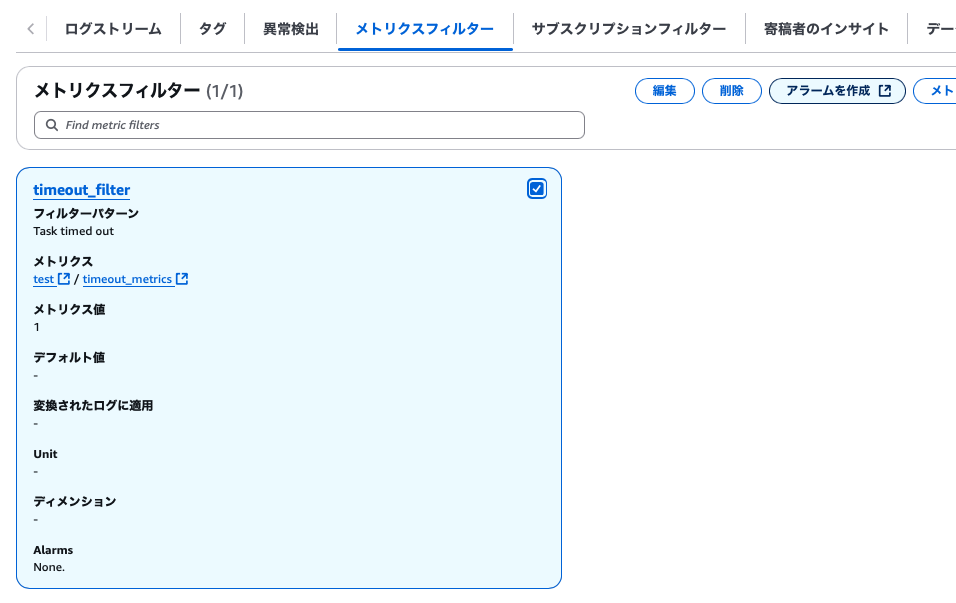
- 対象のCloudWatchLogsのグループを開いて
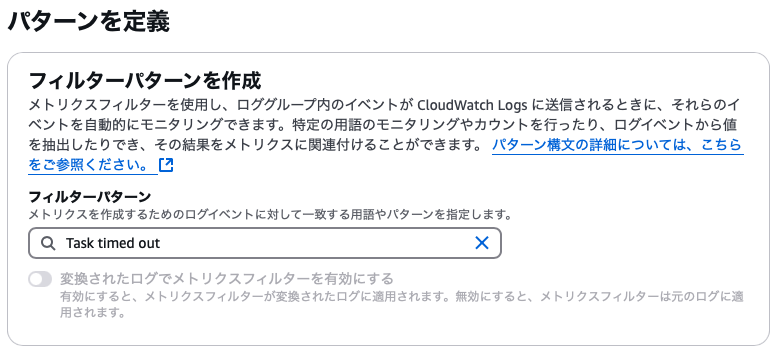
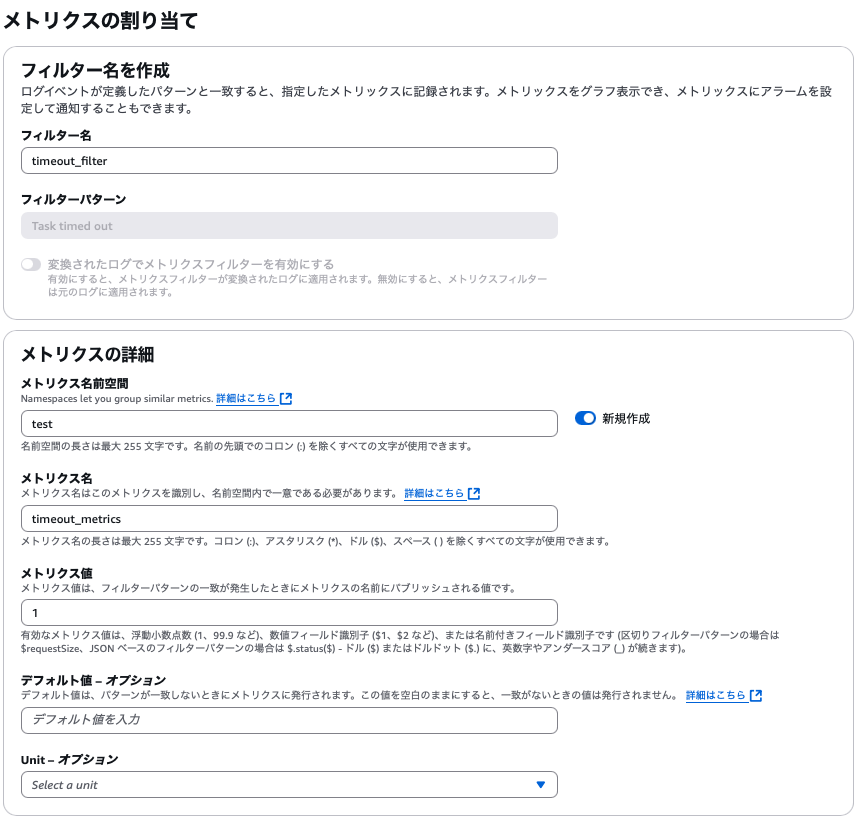
アクション→メトリクスフィルターを作成を選択 - フィルターパターンに
Task timed outを入力して次へ - メトリクス値に1を入力。それ以外は適宜設定を入力して次へ
- 内容確認して
メトリクスフィルターを作成を押下- 当該ロググループのメトリクスフィルターのタブに自動的に遷移します
- 作成したメトリクスフィルターにチェックを入れて
アラームを作成を押下 - メトリクスと条件の指定で適宜設定を行い次へ
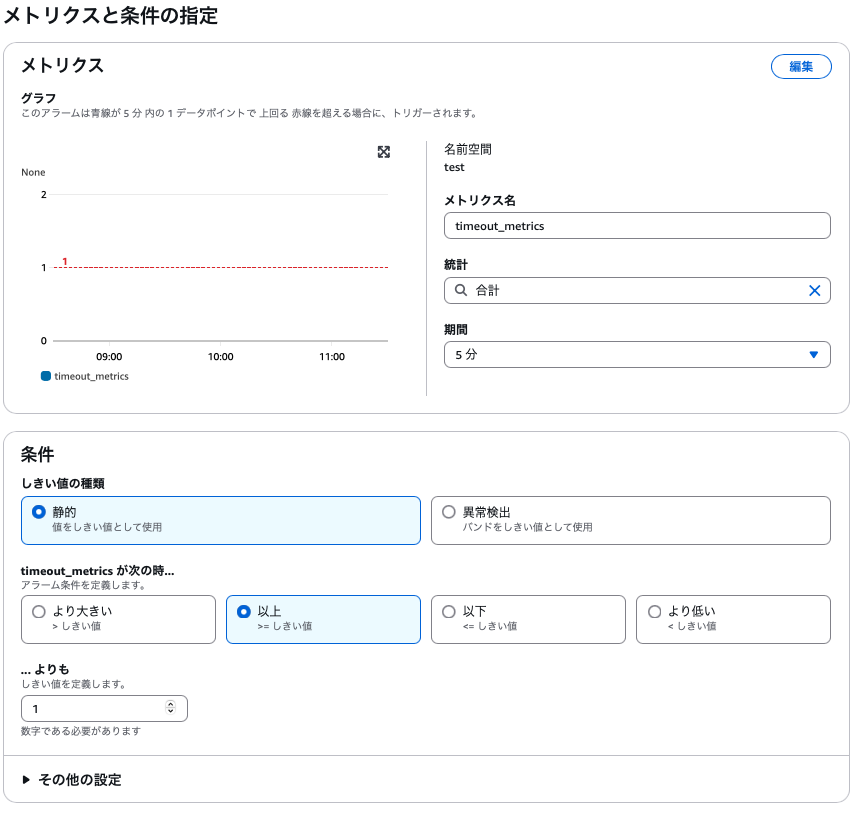
- 画像は5分間のログの中で
Task timed outが含まれるログが1つでもあればアラームを出すという設定になっています
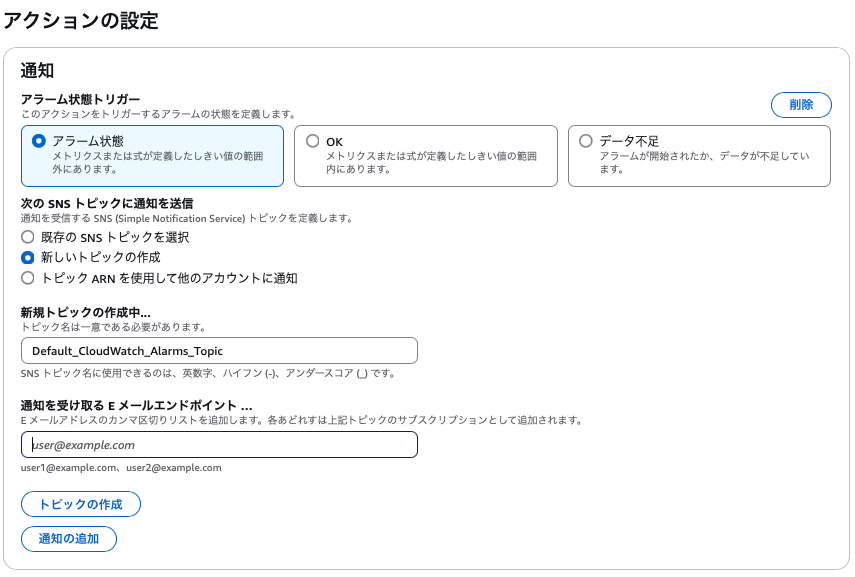
- アクションの設定で
アラーム状態トリガーにアラーム状態`を選択し、SNSトピックが既にある場合はSNSトピックを選択- SNSトピックがない場合はアラームを受け取りたいメールアドレスを入力してトピックを作成します
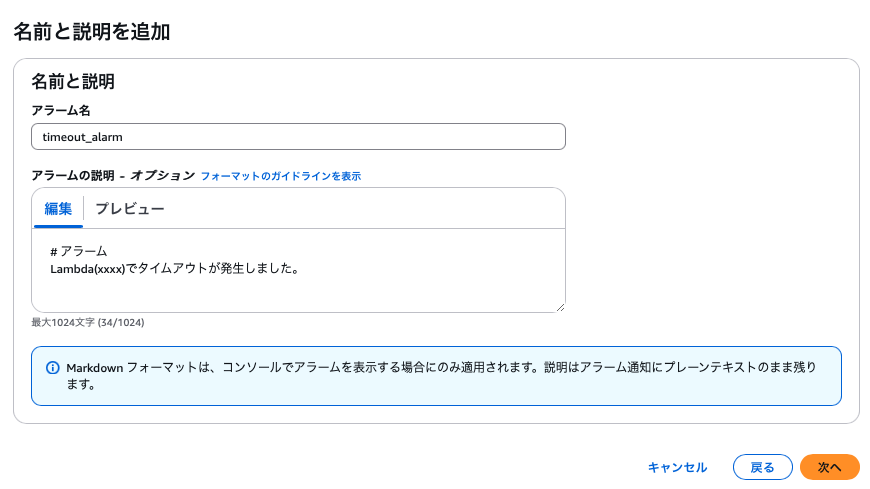
- アラーム名と説明を設定して次へ
- 設定内容を確認して
アラームの作成を押下

これで対象のLambdaがタイムアウトした時にすぐにメールが届くようになりました。
結果
結果的にその後同じ理由で料金が上がることはなかったのですが、
Lambdaのタイムアウトを監視していたおかげでRDSが止まっているタイミングでデータが送信された場合にタイムアウトが繰り返されるという問題が発生してもすぐに気づくことができ、無駄な課金を避けることができました。
気づき・学び
よかったこと
タイムアウト発生時に即気づくようになった。
本番環境にもアラームを設定したことで、異常発生時から発見、解決までの時間が短くなった。
このあと、本番環境で割とやばい問題が発生しましたが、アラームを設定していたおかげで次の日には解決するということが実際にありました。
課題
ERRORが発生した際のアラームも同時に設定したのですが、アラームが発生しても、問題なしと判断されるものがあるとアラーム確認を怠るようになってくるため、適正と判断された場合は適宜メトリクスの条件を変える必要があると最近は感じています。
学び
従量課金は便利である一方、普通に使っているつもりでも思わぬところで課金される可能性があるので気をつけねばならないなと感じました。
とはいえ、こういったことは自分たちの想定していないところで発生するので、事前にアラームを設定しておくなど、二重三重の対策を打っておくのが大事だなと身を持って感じました。
使えるならばBudgetsのアラートも設定しておきたいところです(今回は権限上できませんでした)。
皆様も従量課金にはお気をつけください。