はじめに
この記事はDeepLearning推論用デバイスまとめ記事の第三弾です。第三弾ではGoogleが提供しているEdge TPUについて紹介します。他のデバイスに関しては下記にまとめています。
- Deep Learning推論用デバイスその1 Intel NCS2
- Deep Learning推論用デバイスその2 Nvidia Jetson Nano
- Deep Learning推論用デバイスその3 Google Edge TPU
Google Edge TPU
TPUとは
Tensor Processing Unit(TPU)はGoogleが開発したプロセッサです。TPUは機械学習の計算を高速化するために設計されたASICで、Google翻訳やGoogle検索などのクラウドサービスでもCloud TPUとして利用されておりました。他社のアクセラレータ(NVIDIAなど)とTPUのパフォーマンス検証についてはGoogleの技術ブログにて公開されています。
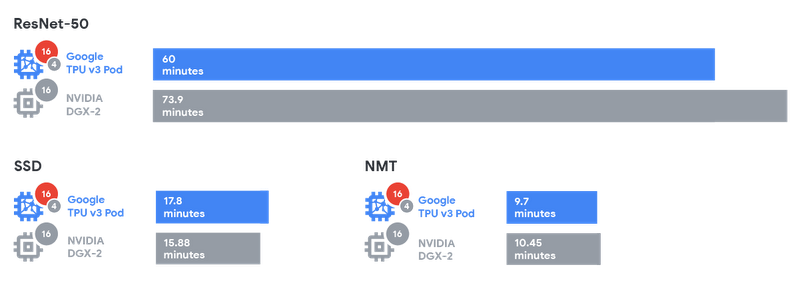
(引用:https://storage.googleapis.com/gweb-cloudblog-publish/images/Graphic2_2x.max-800x800.png)
上記の表を見るとSSD以外の2つのモデルに対しては学習時間が短くなっています。
Edge TPU
Cloud TPUはGoogleのクラウドサービスやGCPでのモデル学習などに利用されています。それに対してTPUを推論に利用するために開発されたのがEdge TPUです。Edge TPUは開発ボードとUSB型アクセラレータの2つが提供されています。
Dev Board

| CPU | NXP i.MX 8M SoC (quad Cortex-A53, Cortex-M4F) |
|---|---|
| GPU | Integrated GC7000 Lite Graphics |
| ML accelerator | Google Edge TPU coprocessor |
| RAM | 1 GB LPDDR4 |
| Flash memory | 8 GB eMMC |
| Wireless | Wi-Fi 2x2 MIMO (802.11b/g/n/ac 2.4/5GHz) and Bluetooth 4.2 |
| Dimensions | 48mm x 40mm x 5mm |
| (引用:https://coral.withgoogle.com/products/dev-board) |
USB Accelerator
USB AcceleratorはDev BoardからAcceleratorを分離してUSBとして提供したものです。これにより、Accelerator以外のマシンをカスタマイズできるようになっています。ホストマシンはLinux OSである必要があります。
推論速度
Googleの技術ブログより公開されている推論速度の比較です。TPU Edgeを利用したときと利用していない時で比較を行っています。モデルはImagenetを学習させたモデルです。
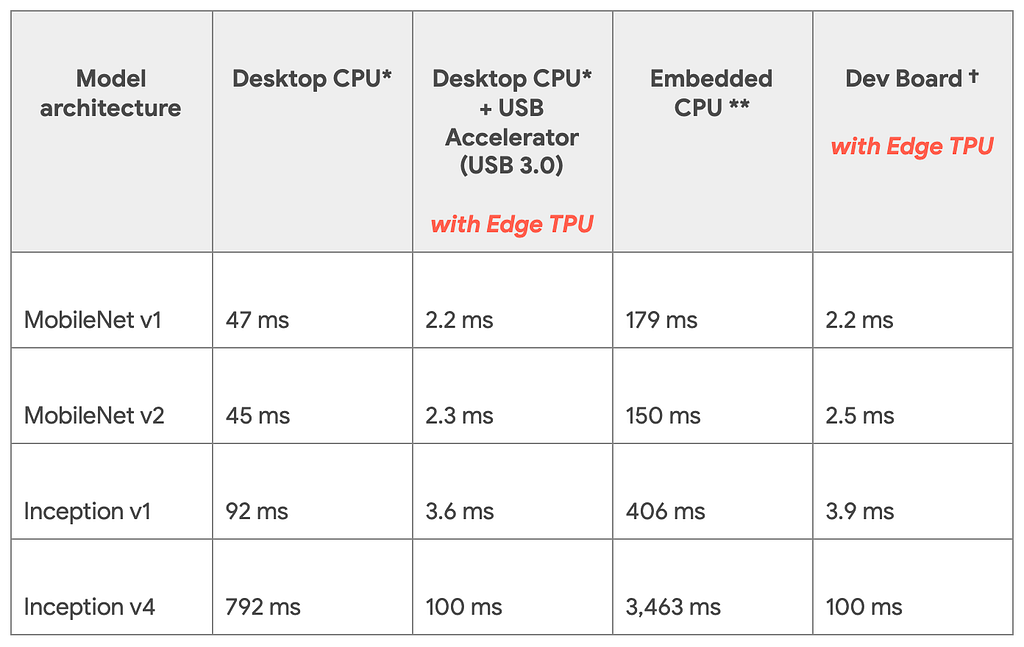
(引用:https://cdn-images-1.medium.com/max/1024/1*pCYQHA_PmF2_awq2coMJvg.png)
Dev BoardとUSB Acceleratorで推論速度が変わっていないことからCPU自体のスペックにはほとんど影響しないということがこの表からわかります。
また同じハードでモデル同士を比較するとDesktop CPUにおけるInception v4からMobile Net V1は16倍速くなっているといえますが、Dev Boardの場合だと45倍速くなっていると計算できます。ここを見るとモデルアーキテクチャの違いも速度に影響すると考えられます。
対応環境
前回のNVIDIA Jetson Nanoの記事でも紹介した通り、Edge TPUを利用して実行するためにはいくつか条件がありますので紹介します。
量子化
モデルの重みは32bitで利用されますが、Edge TPUでは8bit integerに量子化をする必要があります。こちらは学習後の重みを量子化するのではなく学習の段階からQuantization Aware Trainingという手法を利用して学習する必要があります。
テンソルのサイズが定数
Edge TPUで推論する時にはモデル内で利用するテンソルのサイズは定数である必要があります。なので入力サイズの変わるRNN系統のモデルは利用できないです。
こちらにサポートされている演算が載っています。
モデルパラメータがコンパイル時に定数
重み・バイアスは定数である必要があります。なので学習などは想定しておりません。また、VAEで利用されるReparametrization Trickのような乱数を利用した演算はこちらの条件にあってないので推論させることはできなさそうですが、今後検証する必要があります。