Qiitaにいいね!機能が追加されたのにソートできない(知らないだけかもしれない)みたいなので、スクレイピングの勉強も兼ねてプログラムを組もうと思います。
対象ページ
今回は、例としてスクレイピングをキーワード検索して出たページを取得して、いいね!の数が多い順にソートしようと思います。
対象のページは下の図のような感じです。
https://qiita.com/search?q=%E3%82%B9%E3%82%AF%E3%83%AC%E3%82%A4%E3%83%94%E3%83%B3%E3%82%B0
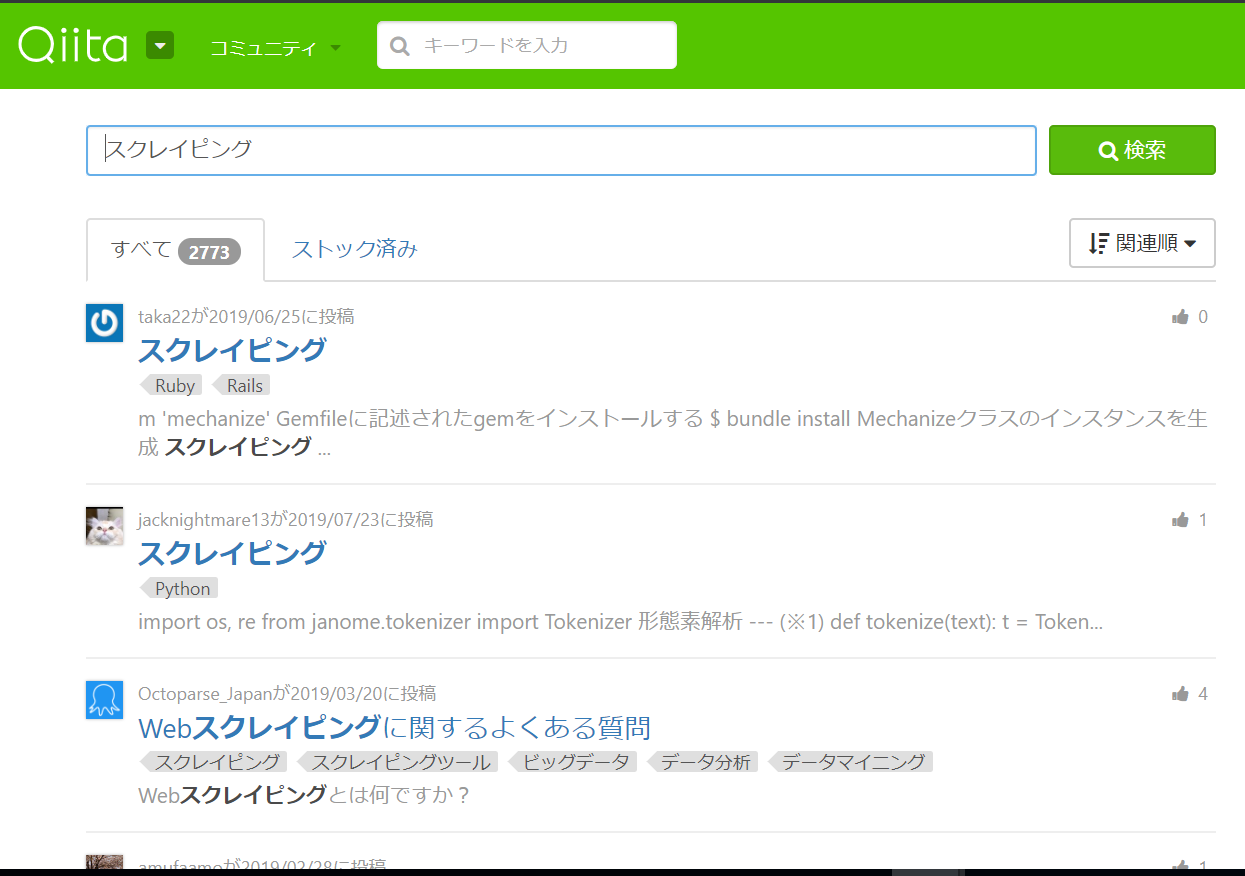
対象データ
先述のページから、簡潔に
・タイトル
・いいね数
の情報と取得します。
ライブラリ
今回使用するライブラリは、以下の2つです。
・requests_html
・requests.exceptions
・time
requests_htmlはWebスクレイピングを行うPython用のライブラリです。ページ情報を取得する際に HTML要素のセレクターを指定することもできます。
requests.exceptionsはネットワークの回線が悪いときやリダイレクトの回数が多いときを考慮して処理を追加しています。try-exceptはしっかりしておきましょう。
timeはアクセスに一定の間隔を空けるために使用します。同じドメインに複数回アクセスするときは、sleep()しておきましょう。
実際のインポートはこんな感じです。
from requests_html import HTMLSession
from requests.exceptions import ConnectionError, TooManyRedirects, HTTPError
import time
データ取得
今回取得するページはページングで表示内容を切り替えるようになっています。そのため、ページを切り替えるとURLが変わってしまいます。
具体的には、
https://qiita.com/search?page=1&q=%E3%82%B9%E3%82%AF%E3%83%AC%E3%82%A4%E3%83%94%E3%83%B3%E3%82%B0
pageのクエリストリングが変わります。
このことを踏まえて、プログラムを組むと
base_url = 'https://qiita.com/search?page='
qs = '&q=スクレイピング'
for page_num in range(1,11):
session = HTMLSession()
resp = session.get(f'{base_url}{page_num}{qs}')
elems = resp.html.find('.searchResult_itemTitle')
score = resp.html.find('.searchResult_sub > ul > li:nth-child(1)')
time.sleep(2)
for文でクエリストリングをインクリメントしています。今回は実行時間も考慮して10ページ分だけアクセスしています。
また、もしfindで要素の取得が上手くいかないとき、以下の記事を参考にしてください。自分もこれで解決しました。
Python Webスクレイピング テクニック集「取得できない値は無い」JavaScript対応@追記あり6/12
そして、sleep()は忘れずにしましょう。
try-except
今回は以下のことを考慮して実装します。
・ネットワークの回線が悪い
・リダイレクトの回数が多い
・レスポンスが不正
このことを踏まえて、プログラムを組むと
try:
for page_num in range(1,11):
session = HTMLSession()
resp = session.get(f'{base_url}{page_num}{qs}')
elems = resp.html.find('.searchResult_itemTitle')
score = resp.html.find('.searchResult_sub > ul > li:nth-child(1)')
time.sleep(2)
except requests.exceptions.ConnectionError:
print('NetworkError')
except requests.exceptions.TooManyRedirects:
print('TooManyRedirects')
except reqeusts.exceptions.HTTPError:
print('BadResponse')
実装
結果的にプログラムは
from requests.exceptions import ConnectionError, TooManyRedirects, HTTPError
from requests_html import HTMLSession
import time
base_url = 'https://qiita.com/search?page='
qs = '&q=スクレイピング'
title = {}
try:
for page_num in range(1,11):
session = HTMLSession()
resp = session.get(f'{base_url}{page_num}{qs}')
elems = resp.html.find('.searchResult_itemTitle')
score = resp.html.find('.searchResult_sub > ul > li:nth-child(1)')
time.sleep(2)
#辞書型でデータをインポート
for (i, j) in zip(score, elems):
title[int(i.text)] = j.text
except requests.exceptions.ConnectionError:
print('NetworkError')
except requests.exceptions.TooManyRedirects:
print('TooManyRedirects')
except reqeusts.exceptions.HTTPError:
print('BadResponse')
これで実行すると、

ちゃんとデータ取得出来ていることが分かります。
ソート
今回ソートはlambdaを使って行います。
プログラムはこんな感じ。
title_sort = sorted(title.items(), key=lambda x: -x[0])
実行すると、
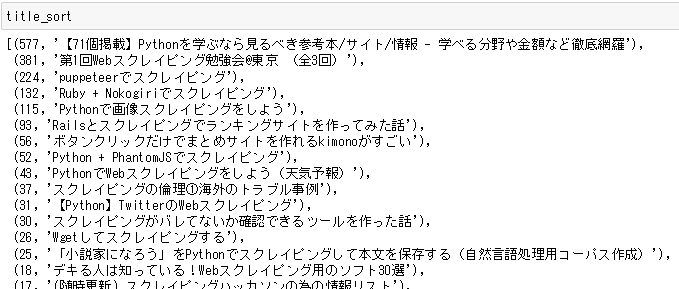
いいね!の多い順にソートできました。
総括
普通スクレイピングはBeautiful Soupを使うことが多いのですが(多分)、今回はrequests_htmlでのスクレイピングを行いました。要素の取得以外は、思ったより簡単にスクレイピング出来たと思います。
また、スクレイピングを行う際は、相手のこと(サーバ等)を考えて行いましょう。