はじめに
昨年度の第3回金融データ活用チャレンジに引き続き,今回も第4回金融データ活用チャレンジに参加させていただきました.時間的な余裕がなかったため,コンペ期間の後半しか取り組めず,またほとんど時間をとることができませんでした.ただ,やりっぱなしではもったいないと思いますので,備忘録も含めて,記事を書かせていただきます.
なお昨年度の私の記事については,以下をご覧ください.
第4回金融データ活用チャレンジとは
金融業界におけるAI・データ活用人材の育成,発掘を目的として,一般社団法人金融データ活用推進協議会 (FUDA) が,業界横断でのデータコンペティションを開催しています.今回の第4回は,「生成AIで実現する経営支援~提案書作成チャレンジ~」をテーマに実施されました.
昨年度の第3回に参加していたこともあり,大きな理由があったわけではなく,今回はなんとなく参加をさせていただきました.
Dataikuとは
今回のコンペでも,Dataikuを使わせていただきました.Detaikuはデータの加工,機械学習モデルの構築,AIの開発・運用などを一元化するプラットフォームで,コードを使うことなくフローを書くことで,実施することができます.
直感的に操作をすることができ,大変使いやすいと思っています.一方でコードを書かないため,どこまでフローを実行した結果なのか,途中で分からなくなってしまい,戸惑ってしまった部分もありました.
まずは手引書を実施
まず最初は手引書に基づいて,1社分の提案書を作成しました.手引書はDataikuの方々が準備されたもので,詳しい説明がなされています.手順通り進めて行くことで,すばやくスタートラインに立つことができました.
コンペでは10社分の提案書を作成することが課題でしたが,この手引書においては,有価証券報告書は1社分のみを使用し,この1社分の提案書を作成するものでした.
10社分を読み込みRAGを作成
取り組まれた方の多くが,次のステップとして,10社分の提案書の作成を取り組まれたのだと思います.
私もsecurities_reportフォルダの中に10社分の有価証券報告書を入れ,10社分をまとめてRAGを作成することにしました.1社の場合と同様に実施し,提案書を作成するフローに修正しました.コードを1社に絞る部分を削除し,手引書に示されている通り,AzureOpenAI内のembedding modelsのRequests per Minuteの値を200に減らす対応を行いました.
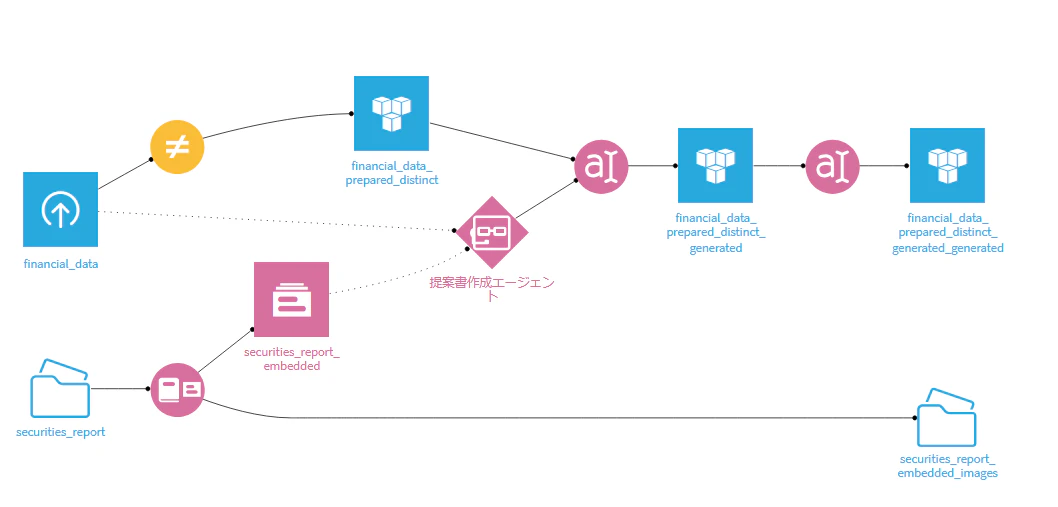
ただ,なぜか上手く有価証券報告書が読み取れていないと回答が返ってしまう現象が続きました.私のやり方が悪いだけだった可能性があります.(実際,再度実施してみると,上手く提案書が作成されることが分かりました.)
10社まとめてRAGを作成する方法は,最初失敗したこともあり,難しいのかもしれないと考えて,別の方法を試す方針に切り替えました.時間的な余裕がなかったため,きちんと考えることができませんでした.いまいちの回答が返ってきたとき,もう少し原因を考えればよかったと後悔しています.
1社ごとを10回ループさせる
次に考えたのが,1社ごとにRAGを作成して,これを用いて1社ごとに提案書を作成していく方法です.繰り返すことが可能であれば,そこまで難しいことではないような気がしており,実際に実施してみることにしました.手作業で実施するのもおもしろくないと感じ,Giminiと相談して,Dataikuの「シナリオ」の機能を使うことにしました.プロジェクト変数を設定して,プロジェクト変数を変えながら,10回実施する形を想定しています.ただこの方法は,RAGを作成してすぐに変更する形をとっており,めちゃくちゃ無駄なことをしているのかもしれません.
作成したフローは以下です.
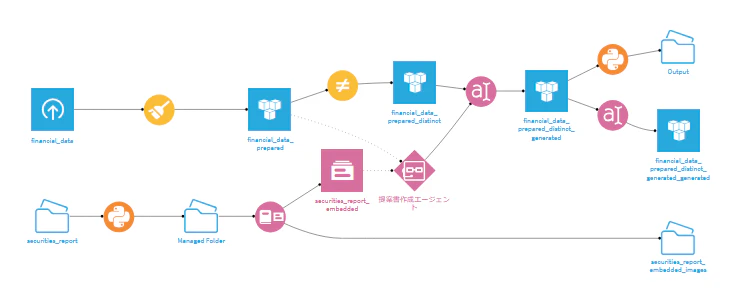
まずプロジェクト変数をVariablesから以下のように設定しました.このように設定することで,target_companyという変数がフローの中で使えることになります.
{
"target_company": "12044"
}
シナリオによって,target_companyの値を変えながら変更していくようにしています.10回実行することで10社の提案書が作成されるイメージです.securities_reportフォルダの中に10社分の有価証券報告書を入れ,その中からManaged Folderにtarget_companyで指定した会社の有価証券報告書にコピーします.抽出するPythonスクリプトはGiminiに尋ねて以下のようにしました.target_companyを変更するたびに.Managed Folderの中身を変更するため,途中でManaged Folderの中身を空にする操作が入っています.
import dataiku
import os
import io
# 1. 入出力フォルダのセットアップ
input_folder = dataiku.Folder("securities_report")
output_folder = dataiku.Folder("Managed Folder")
# 2. プロジェクト変数の取得(シナリオで書き換わる変数)
client = dataiku.api_client()
project = client.get_project(dataiku.default_project_key())
vars = project.get_variables()["standard"]
target = vars.get("target_company")
# --- 追加:出力フォルダの中身を空にする ---
print("Cleaning output folder...")
for path in output_folder.list_paths_in_partition():
output_folder.delete_path(path)
print("Folder cleaned.")
# ---------------------------------------
# 3. ファイルのフィルタリングと保存
files = input_folder.list_paths_in_partition()
for file_path in files:
# ファイル名に変数が含まれているかチェック(例: "7203_report.pdf")
if target in file_path:
# ファイルの内容を読み込む
with input_folder.get_download_stream(file_path) as f:
data = f.read()
# 出力フォルダに同じ名前(または新しい名前)で保存
output_folder.upload_data(file_path, data)
print(f"Saved: {file_path}")
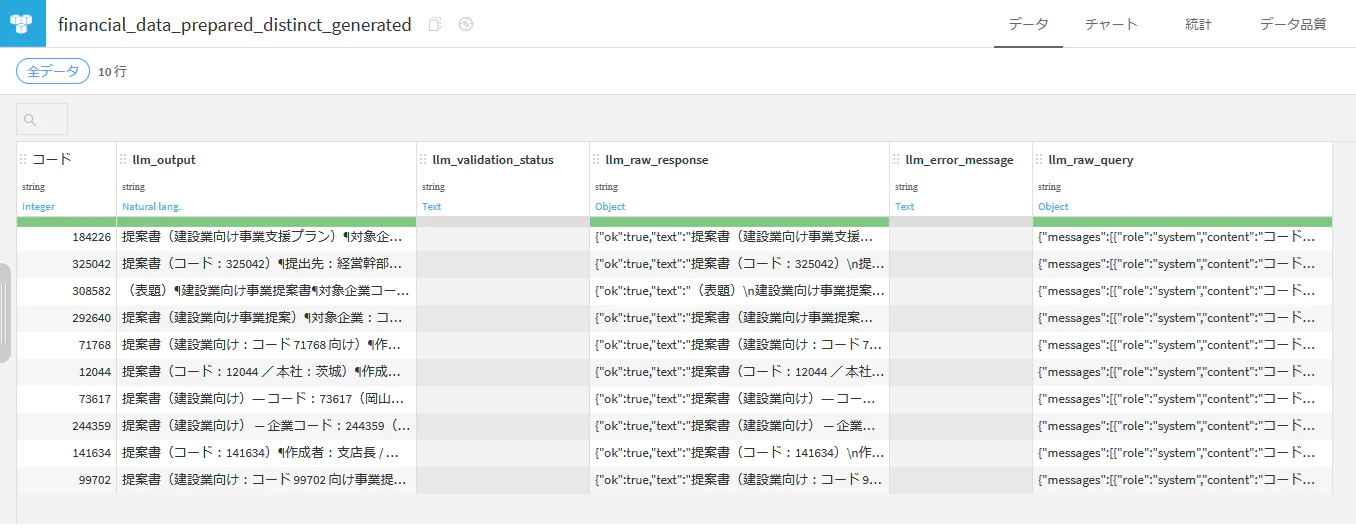
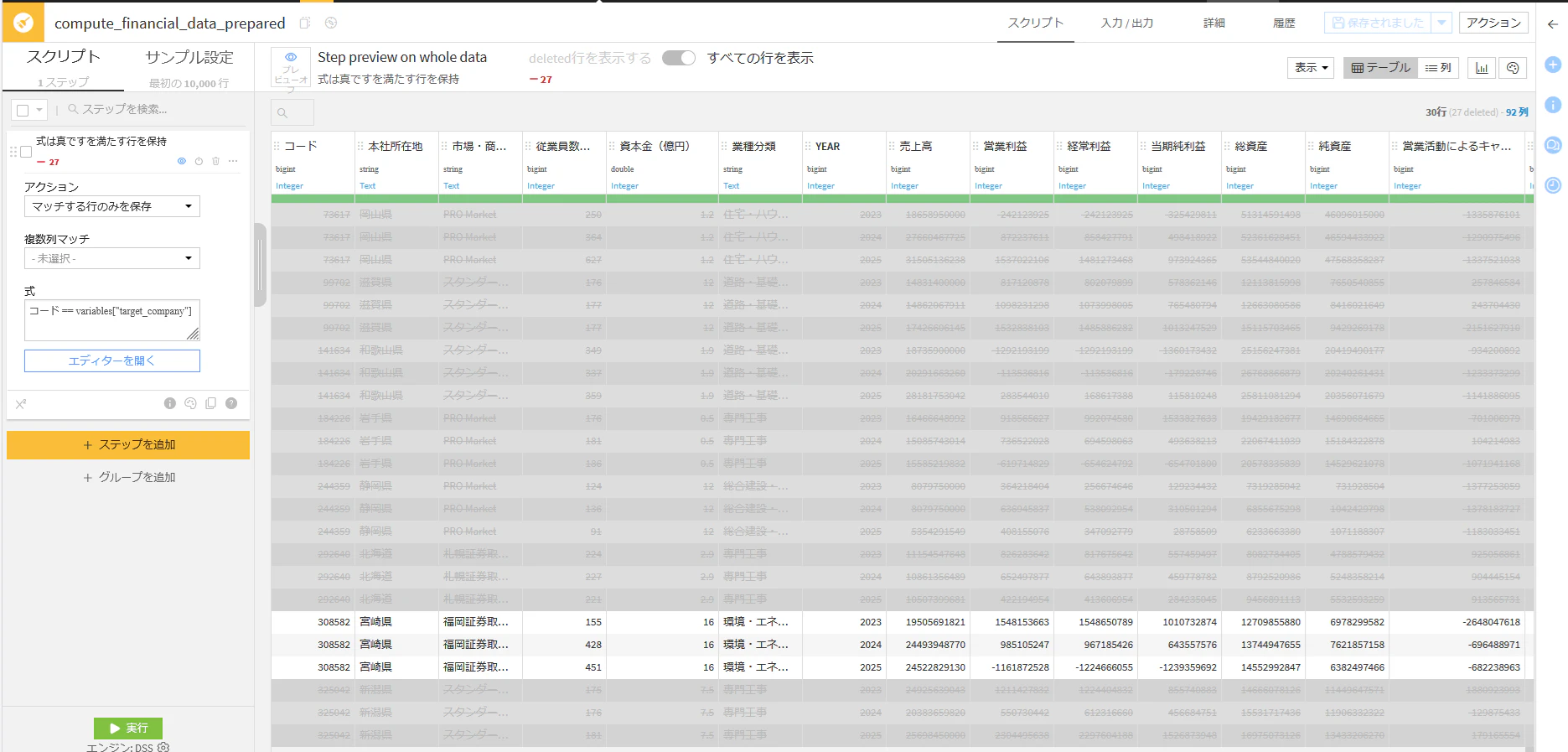
一方,financial_data_preparedを作る操作は,プロジェクト変数target_companyを使うように変更しました.アクションを「マッチする行のみを保存」を選択し,式のところには「コード==variable["target_company"]」の記載し実行するようにしました.
また,Outputフォルダに提案書のWordファイルを保存することにしています.この部分は,Slack内で共有されていたPythonスクリプトをそのまま使用させていただきました.共有いただいた方に感謝しています.本当にありがとうございます.
import dataiku
import pandas as pd
import io
from docx import Document
# 設定画面で追加したフォルダの「名前」を正確に指定
output_folder = dataiku.Folder("Output")
# 入力データセット
df = dataiku.Dataset("financial_data_prepared_distinct_generated").get_dataframe()
def generate_and_save(row):
doc = Document()
doc.add_paragraph(str(row["llm_output"]))
filename = f"{row['コード']}.docx"
# メモリ上に保存してフォルダにアップロード
doc_io = io.BytesIO()
doc.save(doc_io)
doc_io.seek(0)
output_folder.upload_stream(filename, doc_io)
return filename
# 実行
df.apply(generate_and_save, axis=1)
シナリオで使用するPythonスクリプトは以下のようにしました.こちらのスクリプトもGiminiと対話しながら生成しました.company_codesは与えられた10社のコードを記載したものです.
import dataiku
from dataiku.scenario import Scenario
import time
client = dataiku.api_client()
project_key = dataiku.default_project_key()
project = client.get_project(project_key)
scenario = Scenario()
TARGET_DATASET_NAME = "financial_data_prepared_distinct_generated"
company_codes = ["12044", "71768", "73617", "99702", "141634", "184226", "244359", "308582", "325042"]
for code in company_codes:
print(f"--- Starting: {code} ---")
# 変数をセット
scenario.set_project_variables(target_company=code)
definition = {
"type": "RECURSIVE_BUILD",
# "type": "NON_RECURSIVE_FORCED_BUILD",
"buildMode": "FORCE_REBUILD", # これにより「変更なし」と判定されても強制実行
"outputs": [{"id": TARGET_DATASET_NAME, "projectKey": project_key}]
}
try:
print(f"Triggering build for {TARGET_DATASET_NAME} with code {code}...")
job = project.start_job(definition)
# 終了待機
while True:
status = job.get_status().get("baseStatus", {}).get("state", "")
if status in ['DONE', 'FAILED', 'ABORTED']:
print(f"Job finished: {status}")
break
time.sleep(2)
except Exception as e:
print(f"Error: {e}")
print("Done.")
シナリオを実施しましたが,Outputに提案書が保存されることはなく,実行が終了します.いろいろ試行錯誤をしましたが,うまく行きませんでした.途中のレシピを実行しても,フローの前の部分を更新することが難しいことが分かりました.
シナリオを動かす以前の問題として,target_companyを固定した場合で考えてみます.financial_data_prepared_distinct_generatedを実行するだけでは,それ以前のフローが更新されるとは限らないと考察されます.例えば,RAGを作成するcompute_securities_report_embeddedを再度実行して,Knowledge Bankを更新する.さらにはfinancial_data_prepared_distinctを再実行してから,financial_data_prepared_distinct_generatedを更新すると,上手く行くのかもしれません.
結局,このあたりでコンペ期間が終了してしまいました.全く時間が足りなかったというのが正直なところです.今回は,生成AIに関する部分をほとんど扱うことができずに終わってしまったと後悔しています.
最後に
昨年度のコンペに引き続きDataikuを使用しました.なかなか消化不良の部分もありましたが,試行錯誤をすることはできたように感じています.Dataikuが守備範囲の広いすばらしいツールであると再認識しました.今後はDataikuをきちんと勉強して,使えるようになりたいと思っています.DataikuにはDataiku Academyと呼ばれる学習コンテンツが準備されています.こちらを勉強しながら,来年度のコンペに向けて,今から備えたいと思っています.
いろいろと学ぶ機会をいただき,ありがとうございました.コンペを主催された方々にこの場をお借りして感謝をさせていただきます.