Mr.Childrenの言わずと知れた名曲をComprehendに投入してみました。
ミスチル好きなものでして。
Amazon Comprehendとは
テキストを分析し、感情の判定やキーフレーズ検出などを行うことができる、機械学習を利用した自然言語処理(NLP)サービスです。コンソールから1分もかからずに分析できてしまいます。
解析されるインサイトは以下の6つ。
- エンティティ
- キーフレーズ
- PII
- 言語
- 感情
- 構文
リアルタイム解析を実行


Input text に解析したい文章を入力しAnalyze!
これだけです。たったこれだけで解析されちゃいます。Everything (It's you)の歌詞を入力し解析実行!
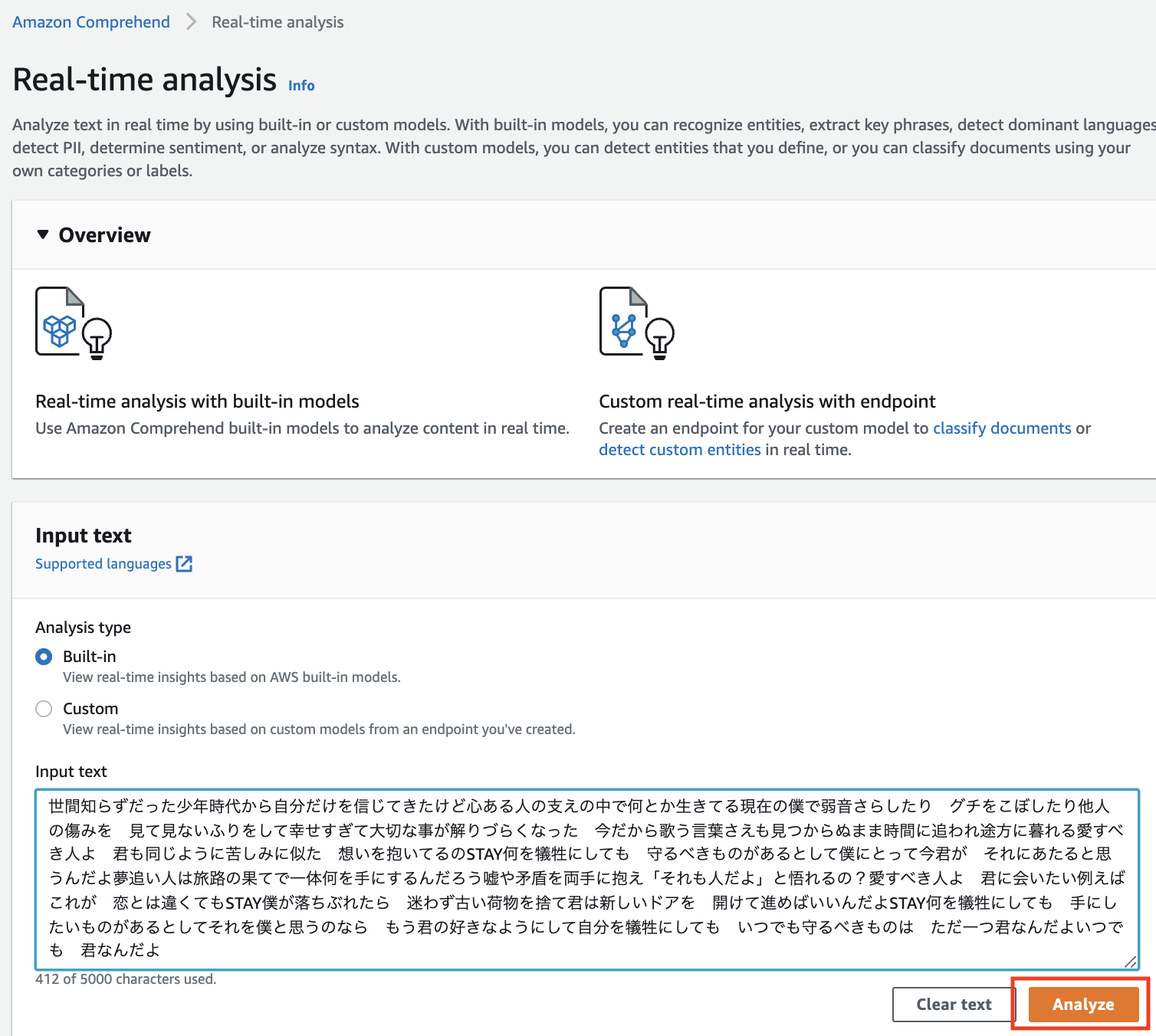
解析結果
6つのインサイト

Entities
人、場所、位置などの情報に自動的に分類される情報。
STAY は人名と認識されたようです。
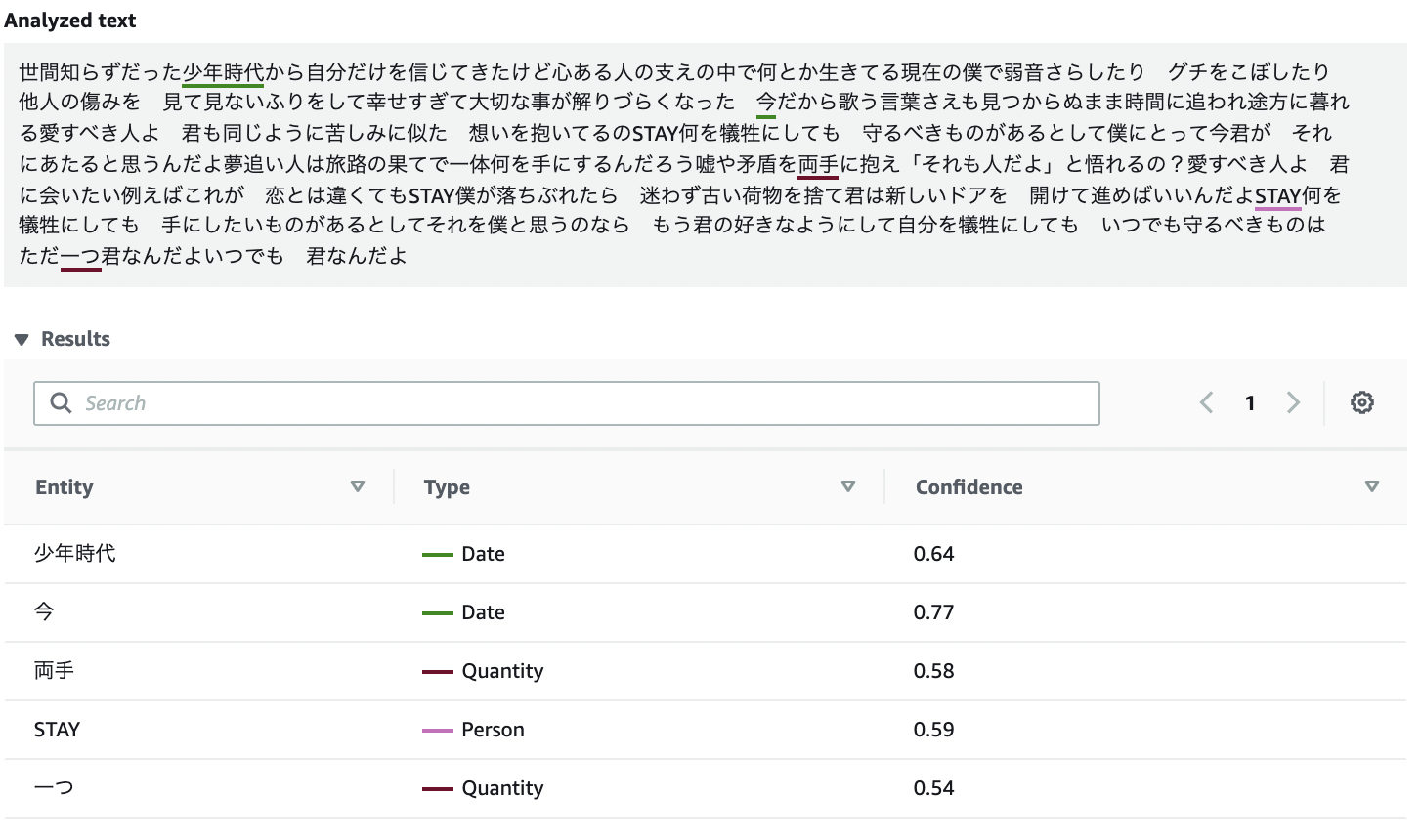
API Response.json
{
"Entities": [
{
"Score": 0.6422388553619385,
"Type": "DATE",
"Text": "少年時代",
"BeginOffset": 8,
"EndOffset": 12
},
{
"Score": 0.7727364897727966,
"Type": "DATE",
"Text": "今",
"BeginOffset": 100,
"EndOffset": 101
},
{
"Score": 0.5865667462348938,
"Type": "QUANTITY",
"Text": "両手",
"BeginOffset": 233,
"EndOffset": 235
},
{
"Score": 0.5952135920524597,
"Type": "PERSON",
"Text": "STAY",
"BeginOffset": 322,
"EndOffset": 326
},
{
"Score": 0.5447555780410767,
"Type": "QUANTITY",
"Text": "一つ",
"BeginOffset": 395,
"EndOffset": 397
}
]
}
Key phrases
「キーフレーズ」と分析されたフレーズとその信頼スコア
「世間」「少年時代」「自分」などが上位のようです。
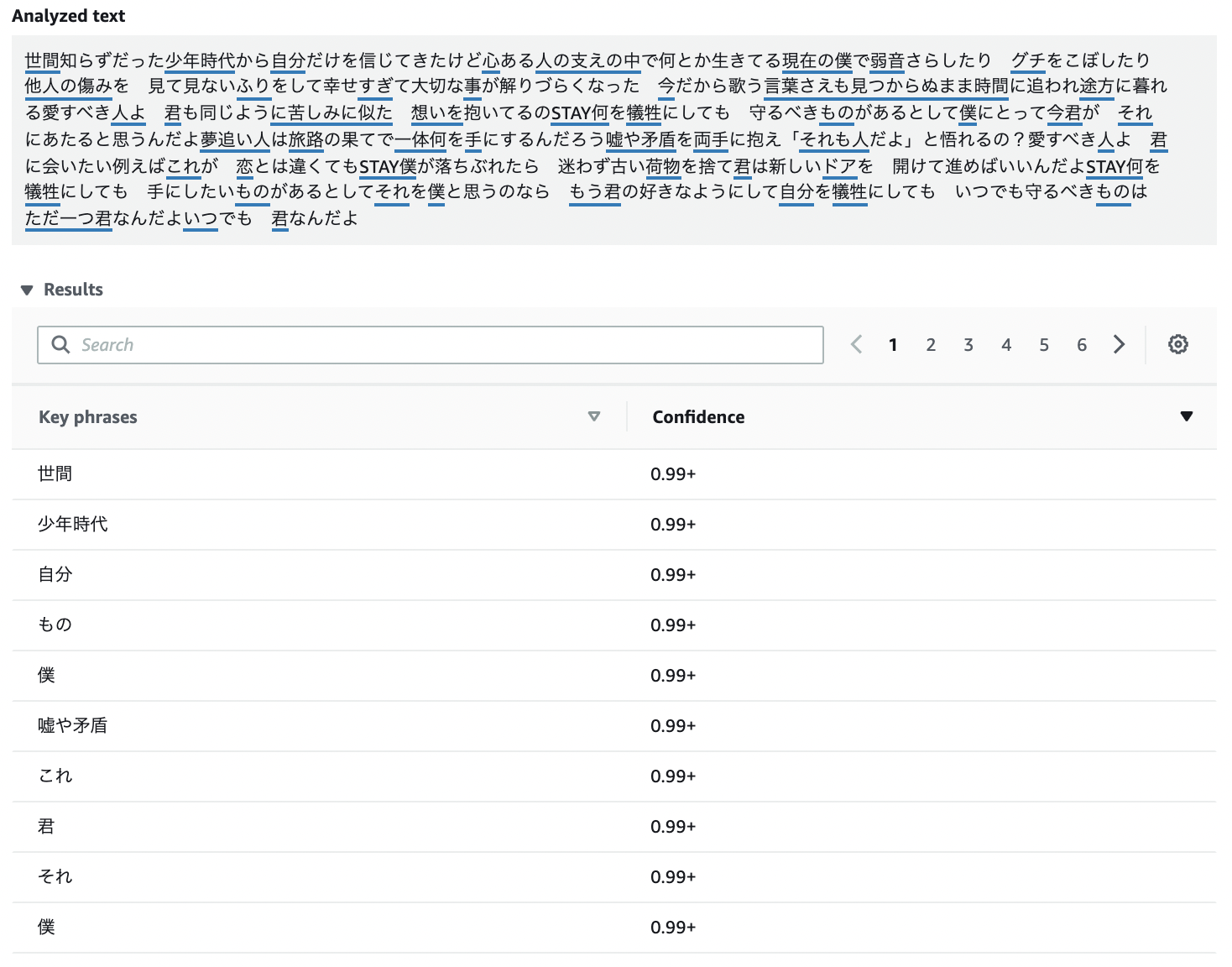
API Response.json
{
"KeyPhrases": [
{
"Score": 0.9991187453269958,
"Text": "世間",
"BeginOffset": 0,
"EndOffset": 2
},
{
"Score": 0.994473397731781,
"Text": "少年時代",
"BeginOffset": 8,
"EndOffset": 12
},
{
"Score": 0.9939662218093872,
"Text": "自分",
"BeginOffset": 14,
"EndOffset": 16
},
{
"Score": 0.9875624179840088,
"Text": "心",
"BeginOffset": 26,
"EndOffset": 27
},
{
"Score": 0.9364995956420898,
"Text": "人の支えの中",
"BeginOffset": 29,
"EndOffset": 35
},
{
"Score": 0.98807293176651,
"Text": "現在の僕",
"BeginOffset": 43,
"EndOffset": 47
},
{
"Score": 0.985284149646759,
"Text": "弱音",
"BeginOffset": 48,
"EndOffset": 50
},
{
"Score": 0.9150426983833313,
"Text": "グチ",
"BeginOffset": 56,
"EndOffset": 58
},
{
"Score": 0.9841071963310242,
"Text": "他人の傷み",
"BeginOffset": 64,
"EndOffset": 69
},
{
"Score": 0.9866365790367126,
"Text": "ふり",
"BeginOffset": 76,
"EndOffset": 78
},
{
"Score": 0.6099014282226562,
"Text": "すぎ",
"BeginOffset": 83,
"EndOffset": 85
},
{
"Score": 0.7314071655273438,
"Text": "事",
"BeginOffset": 89,
"EndOffset": 90
},
{
"Score": 0.9500252604484558,
"Text": "今",
"BeginOffset": 100,
"EndOffset": 101
},
{
"Score": 0.8240435719490051,
"Text": "言葉さえも見つからぬまま",
"BeginOffset": 106,
"EndOffset": 118
},
{
"Score": 0.6586101055145264,
"Text": "時間",
"BeginOffset": 118,
"EndOffset": 120
},
{
"Score": 0.716262936592102,
"Text": "途方",
"BeginOffset": 124,
"EndOffset": 126
},
{
"Score": 0.6114963889122009,
"Text": "人よ",
"BeginOffset": 134,
"EndOffset": 136
},
{
"Score": 0.5545666217803955,
"Text": "君",
"BeginOffset": 137,
"EndOffset": 138
},
{
"Score": 0.721443772315979,
"Text": "に",
"BeginOffset": 143,
"EndOffset": 144
},
{
"Score": 0.6975231766700745,
"Text": "苦しみに似た",
"BeginOffset": 144,
"EndOffset": 150
},
{
"Score": 0.6116013526916504,
"Text": "想いを",
"BeginOffset": 151,
"EndOffset": 154
},
{
"Score": 0.8357267379760742,
"Text": "STAY",
"BeginOffset": 159,
"EndOffset": 163
},
{
"Score": 0.7455344200134277,
"Text": "何",
"BeginOffset": 163,
"EndOffset": 164
},
{
"Score": 0.9078458547592163,
"Text": "犠牲",
"BeginOffset": 165,
"EndOffset": 167
},
{
"Score": 0.9965271353721619,
"Text": "もの",
"BeginOffset": 176,
"EndOffset": 178
},
{
"Score": 0.9996755123138428,
"Text": "僕",
"BeginOffset": 184,
"EndOffset": 185
},
{
"Score": 0.9795992374420166,
"Text": "今",
"BeginOffset": 189,
"EndOffset": 190
},
{
"Score": 0.5885325074195862,
"Text": "君",
"BeginOffset": 190,
"EndOffset": 191
},
{
"Score": 0.9860681295394897,
"Text": "それ",
"BeginOffset": 193,
"EndOffset": 195
},
{
"Score": 0.9740948677062988,
"Text": "夢追い人",
"BeginOffset": 205,
"EndOffset": 209
},
{
"Score": 0.9694126844406128,
"Text": "旅路",
"BeginOffset": 210,
"EndOffset": 212
},
{
"Score": 0.5604091286659241,
"Text": "一体",
"BeginOffset": 216,
"EndOffset": 218
},
{
"Score": 0.6506443619728088,
"Text": "何",
"BeginOffset": 218,
"EndOffset": 219
},
{
"Score": 0.516764760017395,
"Text": "手",
"BeginOffset": 220,
"EndOffset": 221
},
{
"Score": 0.9917513728141785,
"Text": "嘘や矛盾",
"BeginOffset": 228,
"EndOffset": 232
},
{
"Score": 0.8492306470870972,
"Text": "両手",
"BeginOffset": 233,
"EndOffset": 235
},
{
"Score": 0.9291658401489258,
"Text": "それも人",
"BeginOffset": 239,
"EndOffset": 243
},
{
"Score": 0.9886345863342285,
"Text": "人",
"BeginOffset": 256,
"EndOffset": 257
},
{
"Score": 0.9289801716804504,
"Text": "君",
"BeginOffset": 259,
"EndOffset": 260
},
{
"Score": 0.995627760887146,
"Text": "これ",
"BeginOffset": 268,
"EndOffset": 270
},
{
"Score": 0.8548830151557922,
"Text": "恋",
"BeginOffset": 272,
"EndOffset": 273
},
{
"Score": 0.8810998797416687,
"Text": "STAY僕",
"BeginOffset": 279,
"EndOffset": 284
},
{
"Score": 0.8819072246551514,
"Text": "荷物",
"BeginOffset": 297,
"EndOffset": 299
},
{
"Score": 0.9923756718635559,
"Text": "君",
"BeginOffset": 302,
"EndOffset": 303
},
{
"Score": 0.9759371280670166,
"Text": "ドア",
"BeginOffset": 307,
"EndOffset": 309
},
{
"Score": 0.7493122816085815,
"Text": "STAY",
"BeginOffset": 322,
"EndOffset": 326
},
{
"Score": 0.8759680390357971,
"Text": "何",
"BeginOffset": 326,
"EndOffset": 327
},
{
"Score": 0.9159817099571228,
"Text": "犠牲",
"BeginOffset": 328,
"EndOffset": 330
},
{
"Score": 0.9839121699333191,
"Text": "もの",
"BeginOffset": 340,
"EndOffset": 342
},
{
"Score": 0.9930424690246582,
"Text": "それ",
"BeginOffset": 348,
"EndOffset": 350
},
{
"Score": 0.9922454953193665,
"Text": "僕",
"BeginOffset": 351,
"EndOffset": 352
},
{
"Score": 0.5670811533927917,
"Text": "もう",
"BeginOffset": 359,
"EndOffset": 361
},
{
"Score": 0.5696842670440674,
"Text": "君",
"BeginOffset": 361,
"EndOffset": 362
},
{
"Score": 0.9778668284416199,
"Text": "自分",
"BeginOffset": 371,
"EndOffset": 373
},
{
"Score": 0.6204937100410461,
"Text": "犠牲",
"BeginOffset": 374,
"EndOffset": 376
},
{
"Score": 0.9709562063217163,
"Text": "もの",
"BeginOffset": 389,
"EndOffset": 391
},
{
"Score": 0.8189772963523865,
"Text": "ただ一つ君",
"BeginOffset": 393,
"EndOffset": 398
},
{
"Score": 0.9007982611656189,
"Text": "いつ",
"BeginOffset": 402,
"EndOffset": 404
},
{
"Score": 0.8109763264656067,
"Text": "君",
"BeginOffset": 407,
"EndOffset": 408
}
]
}
Language
言語判定です。もちろん日本語として解析されています。

API Response.json
{
"Languages": {
"LanguageCode": "ja",
"Score": 0.9694656729698181
}
}
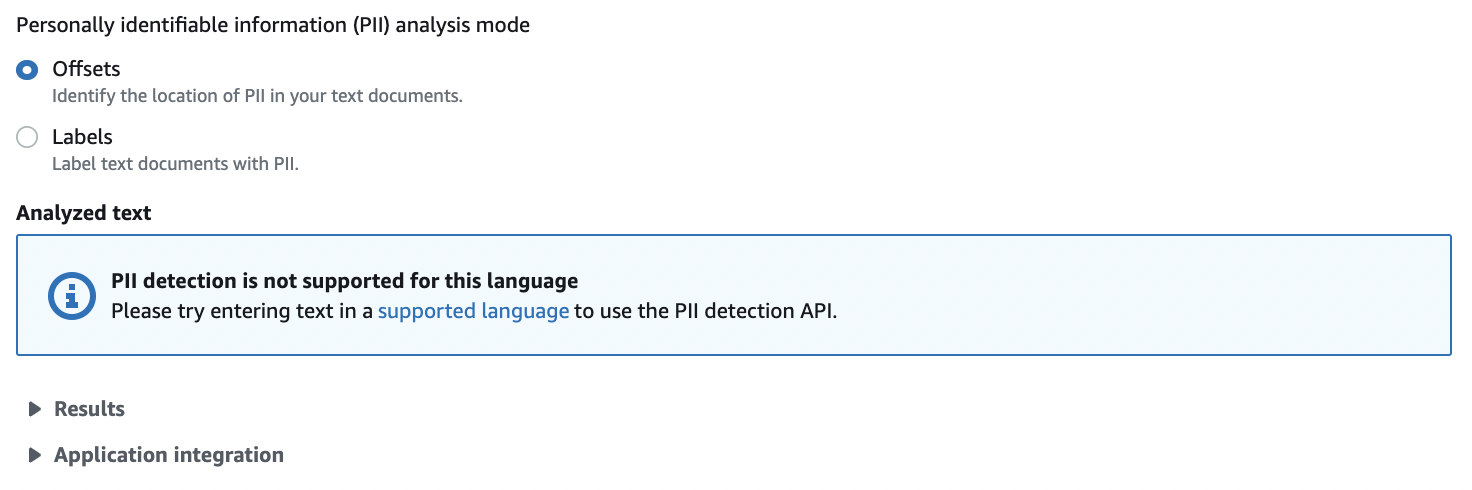
PII
個人識別情報を検出できるようですが、日本語はまだ未対応のようです。
Sentiment
感情が以下の4つに分類されます。77%でポジティブとなりました。
Neutral(ニュートラル)
Positive(ポジティブ)
Negative(ネガティブ)
Mixed(混在)

API Response.json
{
"Sentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Positive": 0.7775697112083435,
"Negative": 0.015565356239676476,
"Neutral": 0.19310088455677032,
"Mixed": 0.013764000497758389
}
}
}
Syntax
名詞、形容詞、動詞などの構文解析(シンタックス)も日本語には対応していないようです。
まとめ
とりあえず分析してみると思わぬ見え方ができて面白いかも。
いろんな歌詞を試してみたい!