とらんすくらいぶってみました
音声ファイルをテキストにしてくれるアレです。
ちょっと触りたい衝動にかられたのでマネジメントコンソールで試してみました。
ジョブの作成(実行)
ダッシュボードより「Transciption jobs」


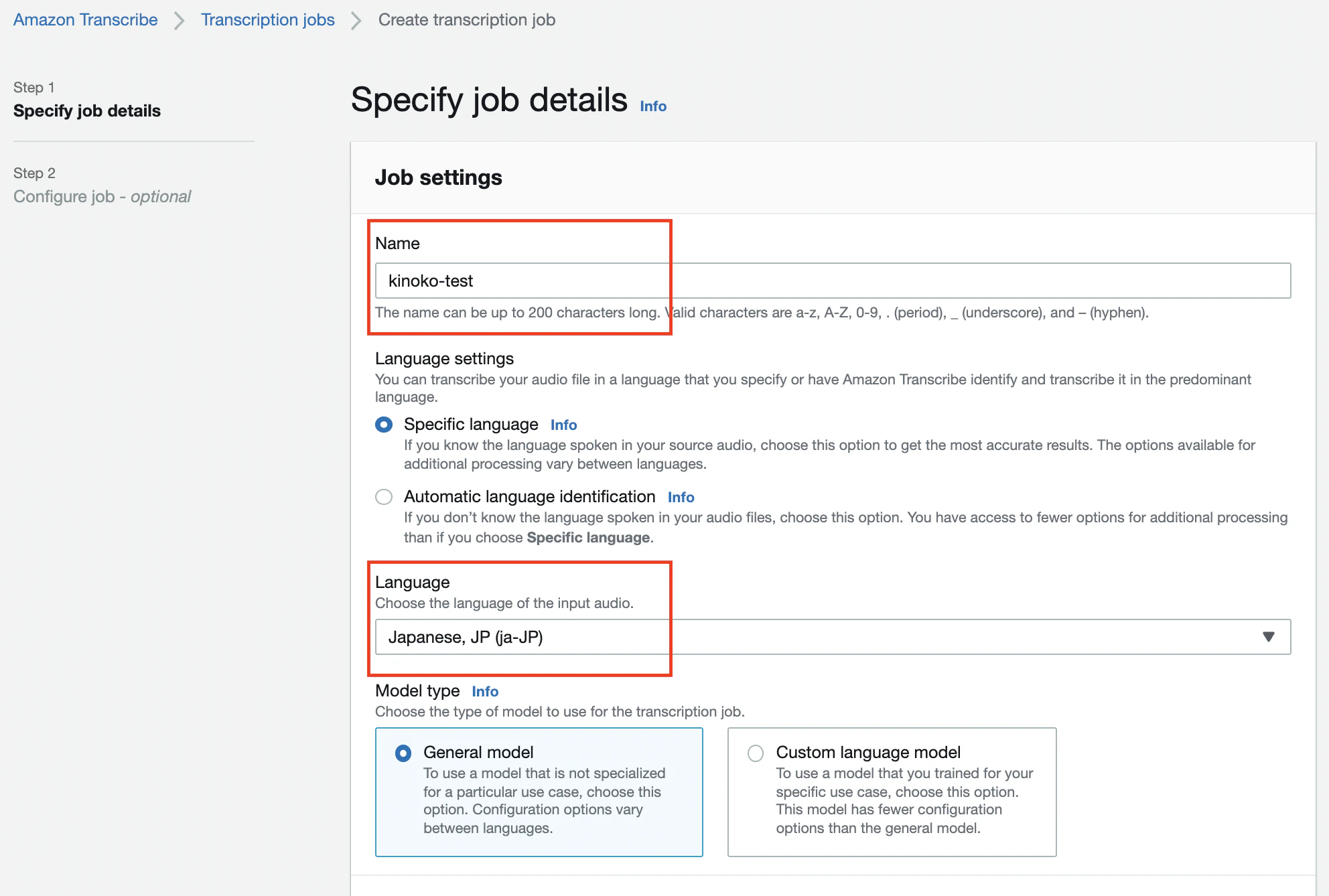
ジョブ名と音声ファイルの言語(入力言語)を指定
音声ファイルを置いたS3のオブジェクトを指定

他はデフォルトの状態でジョブ作成(実行)
解析中(In Progress)

完了(Completed)

解析結果

デフォルトでAWS管理のS3に解析結果が出力されるようで、90日間保存されます。自身でS3バケットを指定すればそこに出力されます。
解析結果は、Transcription preview (コンソール)で見ることができます。
そもそも何て言ったの?
えー、キノコです。初めまして。みなさんお元気でしょうか?ではでは です。
程よい感じにあってる!!
結果をダウンロード
こんな感じのjsonファイルがDLされます。
{
"jobName": "kinoko-test",
"accountId": "xxxxxxxx",
"results": {
"transcripts": [
{ "transcript": "えきのこです初めまして皆さんお元気でしょうかではあれば" }
],
"items": [
{
"start_time": "0.72",
"end_time": "1.17",
"alternatives": [{ "confidence": "0.7244", "content": "え" }],
"type": "pronunciation"
},
{
"start_time": "1.43",
"end_time": "1.81",
"alternatives": [{ "confidence": "0.2896", "content": "きのこ" }],
"type": "pronunciation"
},
{
"start_time": "1.81",
"end_time": "2.26",
"alternatives": [{ "confidence": "1.0", "content": "です" }],
"type": "pronunciation"
},
{
"start_time": "2.62",
"end_time": "2.97",
"alternatives": [{ "confidence": "0.8688", "content": "初め" }],
"type": "pronunciation"
},
{
"start_time": "2.97",
"end_time": "3.43",
"alternatives": [{ "confidence": "0.868", "content": "まして" }],
"type": "pronunciation"
},
{
"start_time": "4.11",
"end_time": "4.53",
"alternatives": [{ "confidence": "0.9554", "content": "皆さん" }],
"type": "pronunciation"
},
{
"start_time": "4.54",
"end_time": "4.6",
"alternatives": [{ "confidence": "0.9965", "content": "お" }],
"type": "pronunciation"
},
{
"start_time": "4.6",
"end_time": "4.94",
"alternatives": [{ "confidence": "1.0", "content": "元気" }],
"type": "pronunciation"
},
{
"start_time": "4.94",
"end_time": "5.25",
"alternatives": [{ "confidence": "1.0", "content": "でしょ" }],
"type": "pronunciation"
},
{
"start_time": "5.26",
"end_time": "5.29",
"alternatives": [{ "confidence": "0.9974", "content": "う" }],
"type": "pronunciation"
},
{
"start_time": "5.3",
"end_time": "5.67",
"alternatives": [{ "confidence": "1.0", "content": "か" }],
"type": "pronunciation"
},
{
"start_time": "6.24",
"end_time": "6.36",
"alternatives": [{ "confidence": "0.905", "content": "で" }],
"type": "pronunciation"
},
{
"start_time": "6.36",
"end_time": "6.45",
"alternatives": [{ "confidence": "0.903", "content": "は" }],
"type": "pronunciation"
},
{
"start_time": "6.45",
"end_time": "6.55",
"alternatives": [{ "confidence": "0.6174", "content": "あれ" }],
"type": "pronunciation"
},
{
"start_time": "6.55",
"end_time": "6.78",
"alternatives": [{ "confidence": "0.6241", "content": "ば" }],
"type": "pronunciation"
}
]
},
"status": "COMPLETED"
}
40分ほどの音源をインプット
40分ほどの音源を解析させてみたところ、正確に計測してなかったけど5分もかからなかった気がします。
ただ、句読点などが一切なかったので読むに耐えない・・・笑
12,418文字がずらずらと羅列された結果はなかなか壮大。ただ、精度は思った以上と、色々使えそうだなと思いました。
きっとオプション設定や他の処理をかけることで、文節区切りなどもできるのかと思うのでもう少し触ってみます。できます?
料金体系
| 階層 | ボリューム (分/月) | スタンダードバッチ文字起こし (USD/分)* |
|---|---|---|
| T1 | 最初の 250,000 分 | 0.02400USD |
| T2 | 次の 750,000 分 | 0.01500USD |
| T3 | 1,000,000 分超え | 0.01080USD |
40分の場合、T1階層なので0.024(USD)x40=0.96USD といったところでしょうか。
参考
上記を参考にLambdaから叩いてみたいと思います。