はじめに
群衆カウント (Crowd Counting) とは,特定エリアにいる群衆の総数を数える行為です.近年では,機械学習を用いた方法が開発されてきました.
本記事では,機械学習の方法に代わって対話型生成AIで群衆カウントが可能か示唆するために,簡易的に実験し評価します.
実験方法
いくつかのサンプル画像に対して,目視によるカウント(現実的に可能な範囲内に限る),機械学習による結果,生成AIに筆者が画像の文脈を添えたプロンプトを入力し得られた結果の3つを比較し,それぞれのズレをチャートにプロットすることで,目視や機械学習の結果からの生成AIの結果のズレを,凡そで把握します.
比較対象1: 目視
筆者が古典的手法でカウントします.画像に写る頭部の数を目安に数え上げます.大きなズレはないと考えられますが,特に人数が多い場合に限界があるのでカウントを割愛します.
比較対象2: 機械学習(DM-Count)
DM-Countという手法を用います.DM-Countは最適輸送(OT)を損失関数に用いて,予測密度マップを作成し人数を近似的に推定する手法です.
数え上げるためのプログラムは,下記を活用させていただきます.
学習モデルは,「UCF-QNRF - A Large Crowd Counting Data Set」という群衆カウント向け訓練データを活用します.
比較対象3: 対話型生成AI
3つの対話型生成AIを用いて,同一画像同一プロンプトから得られる結果を1回ずつ評価します.生成AIが範囲つきで回答した場合(e.g. 10人~20人)は,その平均値(e.g. 15人)を採用します.
活用する対話型生成AIとモデルは下記の3種類です.
- Gemini 3 Pro 思考モード
- Claude Sonnet4.5
- ChatGPT 5.1 Thinking じっくり
入力データ
Wikimedia Commonsから通行人や群衆が撮影された画像を,人数の少ないものから多いものまでピックアップし入力します.また,各画像に対して生成AIに入力するプロンプトが下記の通りです.
特に画像7, 8 に関しては生成AIが画角外の人数もカウントする傾向が見られ,DM-Countと対等な比較のできない恐れがあったため,「画像に収まる人数だけで何人ですか?」との文言を追加しています.
実験結果
実験結果は下記の通りです.
| No. | 入力画像 | DM-Count予測密度 | 目視 | DM-Count | Gemini 3 Pro 思考モード | Claude Sonnet4.5 | ChatGPT 5.1 Thinking(じっくり) |
|---|---|---|---|---|---|---|---|
| 1 |  |
 |
12 | 17 | 11 | 13 | 14 |
| 2 |  |
 |
40 | 38 | 20 | 27.5 | 17 |
| 3 |  |
 |
99 | 107 | 145 | 110 | 65 |
| 4 |  |
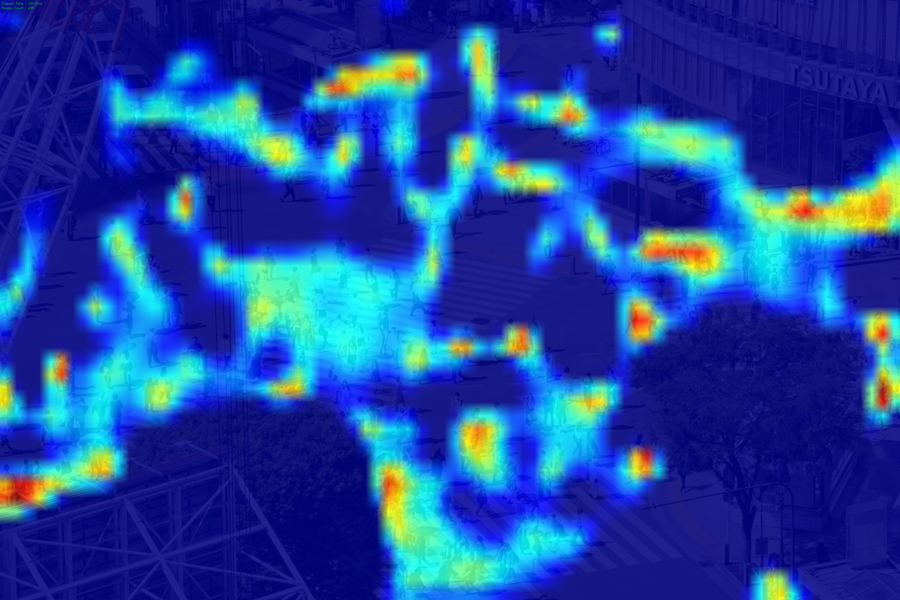 |
263 | 151 | 205 | 200 | 180 |
| 5 |  |
 |
134 | 157 | 34 | 150 | 170 |
| 6 |  |
 |
- | 272 | 300 | 250 | 190 |
| 7 |  |
 |
- | 320 | 700 | 3,000 | 400 |
| 8 |  |
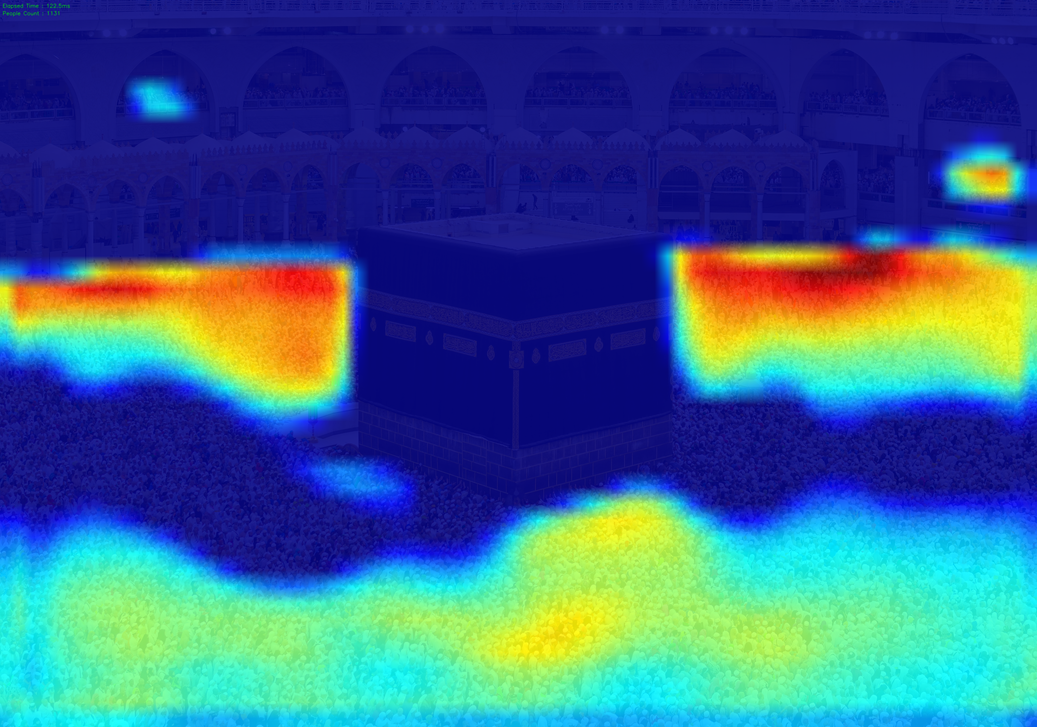 |
- | 1,131 | 12,500 | 45,000 | 25,000 |
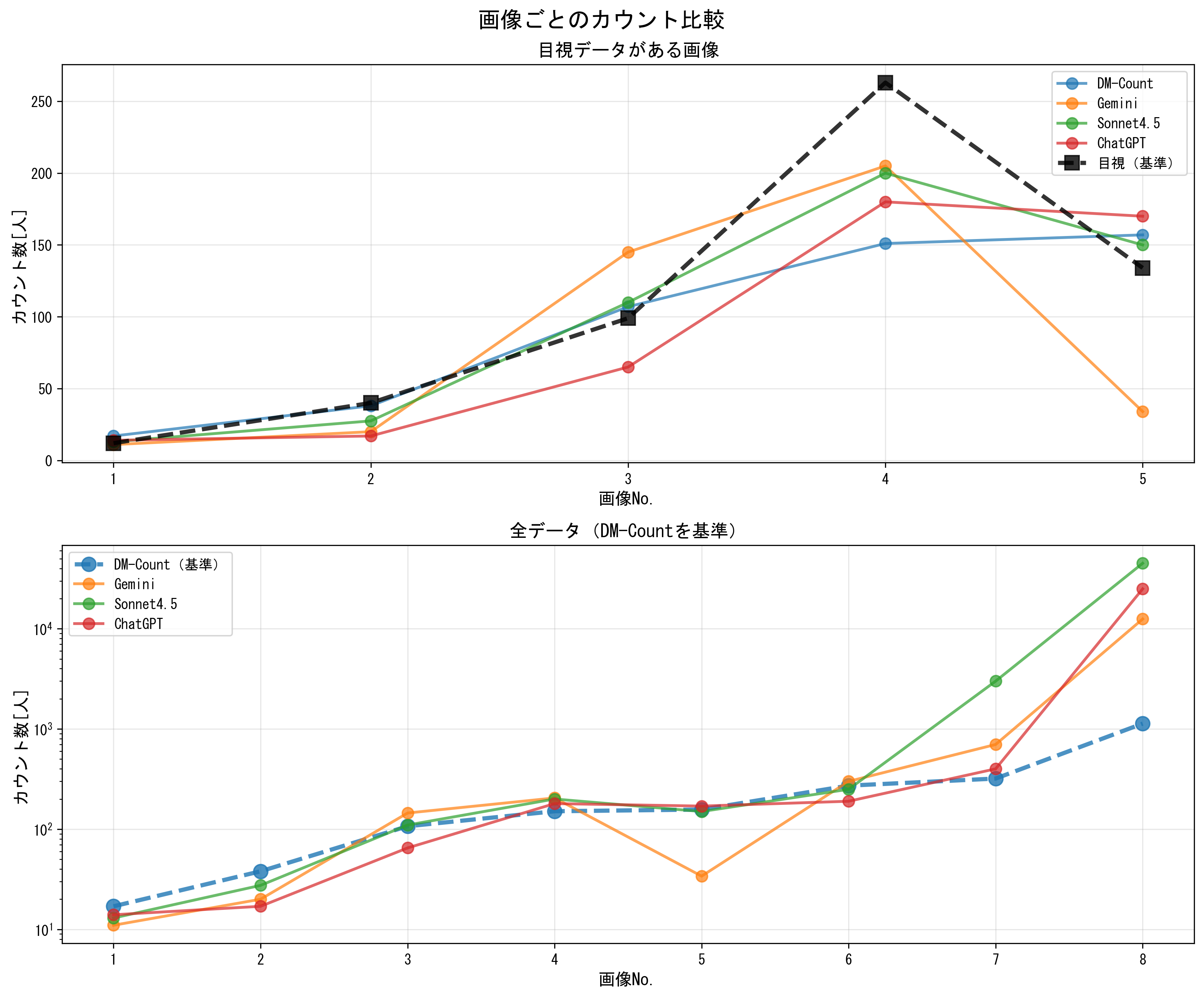
画像ごとに各手法との比較
群衆の人数が多くなるにつればらつきや誤差大きくなるものの,概算レベルの精度であれば従来手法(目視やDM-Count)と近しい結果を示しました.
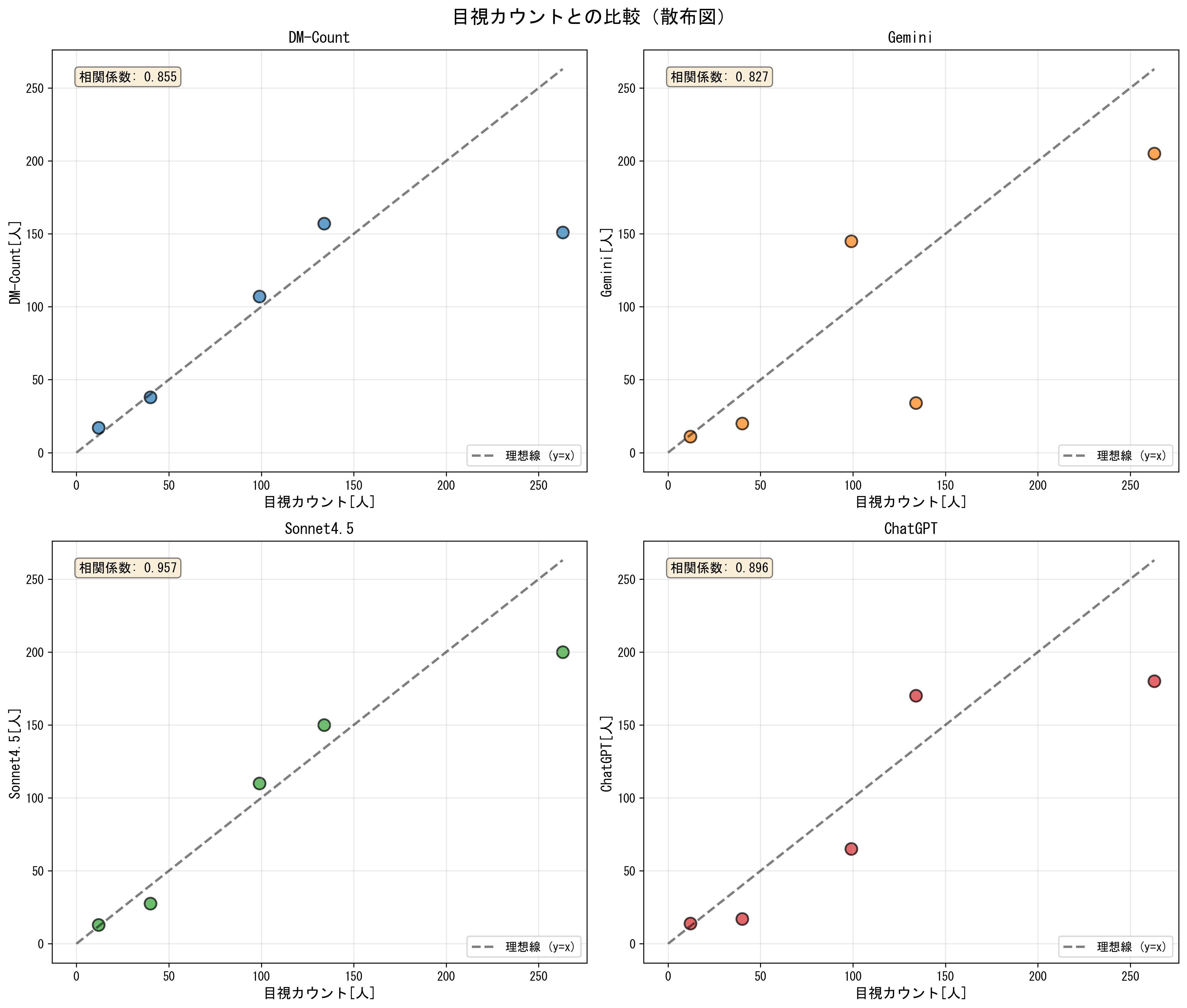
目視確認との誤差
群衆の人数別に目視確認と比較しても概ね相関が見られ,Sonnet4.5はDM-Countと遜色ないか,それ以上の正の相関を示す結果となりました.
まとめと考察
本記事では,群衆カウント (Crowd Counting) を対話型生成AIで行うことができるかを,目視や機械学習による数え上げと比較することで簡易的に実験し評価しました.実験の結果から,概算レベルでは既存手法と同傾向の結果を示すことが分かり,生成AIによる群衆カウントの有効性を示唆しました.
生成AIは,画像がどの場所なのか推察することができるため,その場所の規模感やコンテキストを推察することができます.実際に下記のような回答を得ており,場所やコンテキストから得られる情報を使って数え上げを補うことできている可能性が,従来手法との違いで興味深いと考えます.
この規模の交差点から判断すると、渋谷のスクランブル交差点のような大都市の主要交差点である可能性が高く、画像右上に「TSUTAYA」の看板も見えることから、実際に渋谷駅前のスクランブル交差点かもしれません。比較的混雑している時間帯の様子と思われます。
Claude Sonnet4.5やGemini 3 Pro 思考モードは数秒でレスポンスを返しましたが,ChatGPT 5.1 Thinkingは数分を要しました.費用面やネットワークの安定性,パフォーマンスの各方面で機械学習による手法からの優位性は乏しく,実用システムに組み込む可能性は低いと考えられますが,特段の知識なく数枚程度の画像を群衆カウントする用途では実用可能と考えます.
今後の課題
今回はN=8の少量のサンプルに対して,DM-Countという単一の手法との比較を行いました.正確な評価とするには,より多くのサンプルに対して様々な比較対象を用いて実験することは課題です.
謝辞
DM-Countのサンプルプログラムを公開してくださった高橋かずひとさん(@KzhtTkhs),ありがとうございました。
付録
グラフのプロットに用いたプログラムは下記のとおりです.これは結果をCSV化したうえで,生成AIを用いて下記のプロンプトから生成されたものを一部修正しました.
このCSVファイルの結果が比較できるようにグラフをプロットしたい.目視およびDM-Countが従来手法として,その他の生成AIによる出力がどれくらいズレているのか,ズレていないのかが関心ごとである.どのようなグラフをプロットすると良いか提案し,それをプロットするPtythonスクリプトを出力してください
プロットスクリプト
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
# 日本語フォントの設定
plt.rcParams['font.sans-serif'] = ['MS Gothic', 'Yu Gothic', 'Meiryo']
plt.rcParams['axes.unicode_minus'] = False
# CSVファイルの読み込み
df = pd.read_csv('result.csv', encoding='utf-8')
# カラム名の整形
df.columns = ['目視', 'DM-Count', 'Gemini', 'Sonnet4.5', 'ChatGPT']
# 欠損値を含む行を除外したデータフレーム
df_complete = df.dropna()
print("データの確認:")
print(df)
print(f"\n完全なデータ(欠損値なし): {len(df_complete)}行")
print(f"DM-Countのみ存在するデータ: {df['DM-Count'].notna().sum()}行")
# 図1: 散布図 - 目視 vs 各手法
fig, axes = plt.subplots(2, 2, figsize=(14, 12))
fig.suptitle('目視カウントとの比較(散布図)', fontsize=16, fontweight='bold')
methods = ['DM-Count', 'Gemini', 'Sonnet4.5', 'ChatGPT']
colors = ['#1f77b4', '#ff7f0e', '#2ca02c', '#d62728']
for idx, (method, color) in enumerate(zip(methods, colors)):
ax = axes[idx // 2, idx % 2]
# 目視とそれぞれの手法の両方のデータが存在する行のみを使用
valid_data = df[['目視', method]].dropna()
if len(valid_data) > 0:
ax.scatter(valid_data['目視'], valid_data[method],
alpha=0.7, s=100, color=color, edgecolors='black', linewidth=1.5)
# 理想線(y=x)を追加
max_val = max(valid_data['目視'].max(), valid_data[method].max())
ax.plot([0, max_val], [0, max_val], 'k--', alpha=0.5, linewidth=2, label='理想線 (y=x)')
# 相関係数を計算
if len(valid_data) > 1:
corr = valid_data['目視'].corr(valid_data[method])
ax.text(0.05, 0.95, f'相関係数: {corr:.3f}',
transform=ax.transAxes, fontsize=11, verticalalignment='top',
bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.5))
ax.set_xlabel('目視カウント[人]', fontsize=12)
ax.set_ylabel(f'{method}[人]', fontsize=12)
ax.set_title(f'{method}', fontsize=13, fontweight='bold')
ax.legend()
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('comparison_scatter.png', dpi=300, bbox_inches='tight')
print("\n図1を保存しました: comparison_scatter.png")
# 図2: 誤差分析 - DM-Countを基準とした比較
fig, axes = plt.subplots(2, 2, figsize=(14, 12))
fig.suptitle('DM-Countを基準とした各手法の誤差', fontsize=16, fontweight='bold')
ai_methods = ['Gemini', 'Sonnet4.5', 'ChatGPT']
colors_ai = ['#ff7f0e', '#2ca02c', '#d62728']
for idx, (method, color) in enumerate(zip(ai_methods, colors_ai)):
ax = axes[idx // 2, idx % 2]
# DM-Countと各手法の両方のデータが存在する行のみを使用
valid_data = df[['DM-Count', method]].dropna()
if len(valid_data) > 0:
ax.scatter(valid_data['DM-Count'], valid_data[method],
alpha=0.7, s=100, color=color, edgecolors='black', linewidth=1.5)
# 理想線(y=x)を追加
max_val = max(valid_data['DM-Count'].max(), valid_data[method].max())
ax.plot([0, max_val], [0, max_val], 'k--', alpha=0.5, linewidth=2, label='理想線 (y=x)')
# 相関係数を計算
if len(valid_data) > 1:
corr = valid_data['DM-Count'].corr(valid_data[method])
ax.text(0.05, 0.95, f'相関係数: {corr:.3f}',
transform=ax.transAxes, fontsize=11, verticalalignment='top',
bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.5))
ax.set_xlabel('DM-Count', fontsize=12)
ax.set_ylabel(f'{method}', fontsize=12)
ax.set_title(f'{method} vs DM-Count', fontsize=13, fontweight='bold')
ax.legend()
ax.grid(True, alpha=0.3)
# 4つ目のサブプロットには全体的な統計情報を表示
ax = axes[1, 1]
ax.axis('off')
stats_text = "統計サマリー\n" + "="*40 + "\n\n"
for method in ai_methods:
valid_data = df[['DM-Count', method]].dropna()
if len(valid_data) > 0:
mae = np.mean(np.abs(valid_data['DM-Count'] - valid_data[method]))
mape = np.mean(np.abs((valid_data['DM-Count'] - valid_data[method]) / valid_data['DM-Count'])) * 100
stats_text += f"{method}:\n"
stats_text += f" MAE: {mae:.2f}\n"
stats_text += f" MAPE: {mape:.2f}%\n"
stats_text += f" データ数: {len(valid_data)}\n\n"
ax.text(0.1, 0.9, stats_text, transform=ax.transAxes, fontsize=11,
verticalalignment='top', fontfamily='monospace',
bbox=dict(boxstyle='round', facecolor='lightblue', alpha=0.3))
plt.tight_layout()
plt.savefig('comparison_vs_dmcount.png', dpi=300, bbox_inches='tight')
print("図2を保存しました: comparison_vs_dmcount.png")
# 図3: 絶対誤差の比較(箱ひげ図)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 6))
fig.suptitle('誤差の分布比較', fontsize=16, fontweight='bold')
# 目視を基準とした絶対誤差
ax1.set_title('目視を基準とした絶対誤差', fontsize=13, fontweight='bold')
errors_visual = []
labels_visual = []
for method in methods:
valid_data = df[['目視', method]].dropna()
if len(valid_data) > 0:
error = np.abs(valid_data['目視'] - valid_data[method])
errors_visual.append(error)
labels_visual.append(method)
if errors_visual:
bp1 = ax1.boxplot(errors_visual, labels=labels_visual, patch_artist=True)
for patch, color in zip(bp1['boxes'], colors):
patch.set_facecolor(color)
patch.set_alpha(0.6)
ax1.set_ylabel('絶対誤差', fontsize=12)
ax1.set_xlabel('手法', fontsize=12)
ax1.grid(True, alpha=0.3, axis='y')
ax1.tick_params(axis='x', rotation=15)
# DM-Countを基準とした絶対誤差
ax2.set_title('DM-Countを基準とした絶対誤差', fontsize=13, fontweight='bold')
errors_dmcount = []
labels_dmcount = []
for method in ai_methods:
valid_data = df[['DM-Count', method]].dropna()
if len(valid_data) > 0:
error = np.abs(valid_data['DM-Count'] - valid_data[method])
errors_dmcount.append(error)
labels_dmcount.append(method)
if errors_dmcount:
bp2 = ax2.boxplot(errors_dmcount, labels=labels_dmcount, patch_artist=True)
for patch, color in zip(bp2['boxes'], colors_ai):
patch.set_facecolor(color)
patch.set_alpha(0.6)
ax2.set_ylabel('絶対誤差', fontsize=12)
ax2.set_xlabel('手法', fontsize=12)
ax2.grid(True, alpha=0.3, axis='y')
ax2.tick_params(axis='x', rotation=15)
plt.tight_layout()
plt.savefig('error_distribution.png', dpi=300, bbox_inches='tight')
print("図3を保存しました: error_distribution.png")
# 図4: 画像ごとの比較(折れ線グラフ)
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(12, 10))
fig.suptitle('画像ごとのカウント比較', fontsize=16, fontweight='bold')
# 目視データがある行
ax1.set_title('目視データがある画像', fontsize=13, fontweight='bold')
df_visual = df.dropna(subset=['目視'])
x_visual = range(1, len(df_visual) + 1)
for method, color in zip(methods, colors):
if method in df_visual.columns:
ax1.plot(x_visual, df_visual[method], marker='o', linewidth=2,
markersize=8, label=method, color=color, alpha=0.7)
ax1.plot(x_visual, df_visual['目視'], marker='s', linewidth=3,
markersize=10, label='目視(基準)', color='black', linestyle='--', alpha=0.8)
ax1.set_xlabel('画像No.', fontsize=12)
ax1.set_ylabel('カウント数[人]', fontsize=12)
ax1.legend(fontsize=10)
ax1.grid(True, alpha=0.3)
ax1.set_xticks(x_visual)
# DM-Countデータがある行(全データ)
ax2.set_title('全データ(DM-Countを基準)', fontsize=13, fontweight='bold')
df_dmcount = df.dropna(subset=['DM-Count'])
x_dmcount = range(1, len(df_dmcount) + 1)
ax2.plot(x_dmcount, df_dmcount['DM-Count'], marker='o', linewidth=3,
markersize=10, label='DM-Count(基準)', color='#1f77b4', linestyle='--', alpha=0.8)
for method, color in zip(ai_methods, colors_ai):
if method in df_dmcount.columns:
valid_mask = df_dmcount[method].notna()
x_valid = [i+1 for i, v in enumerate(valid_mask) if v]
y_valid = df_dmcount[method][valid_mask]
ax2.plot(x_valid, y_valid, marker='o', linewidth=2,
markersize=8, label=method, color=color, alpha=0.7)
ax2.set_xlabel('画像No.', fontsize=12)
ax2.set_ylabel('カウント数[人]', fontsize=12)
ax2.legend(fontsize=10)
ax2.grid(True, alpha=0.3)
ax2.set_xticks(x_dmcount)
ax2.set_yscale('log') # 対数スケールで表示(範囲が広いため)
plt.tight_layout()
plt.savefig('comparison_per_image.png', dpi=300, bbox_inches='tight')
print("図4を保存しました: comparison_per_image.png")
# 図5: 相対誤差のヒートマップ
fig, ax = plt.subplots(figsize=(10, 8))
fig.suptitle('相対誤差(MAPE)のヒートマップ', fontsize=16, fontweight='bold')
# DM-Countを基準とした相対誤差を計算
df_dmcount = df.dropna(subset=['DM-Count'])
error_matrix = []
image_labels = []
for idx, row in df_dmcount.iterrows():
errors_row = []
for method in ai_methods:
if pd.notna(row[method]) and row['DM-Count'] != 0:
mape = abs((row['DM-Count'] - row[method]) / row['DM-Count']) * 100
errors_row.append(mape)
else:
errors_row.append(np.nan)
if any(pd.notna(e) for e in errors_row):
error_matrix.append(errors_row)
image_labels.append(f"画像{idx+1}")
if error_matrix:
error_df = pd.DataFrame(error_matrix, columns=ai_methods, index=image_labels)
sns.heatmap(error_df, annot=True, fmt='.1f', cmap='RdYlGn_r',
ax=ax, cbar_kws={'label': '相対誤差 (%)'},
vmin=0, vmax=200, linewidths=0.5)
ax.set_xlabel('手法', fontsize=12)
ax.set_ylabel('画像', fontsize=12)
plt.tight_layout()
plt.savefig('error_heatmap.png', dpi=300, bbox_inches='tight')
print("図5を保存しました: error_heatmap.png")
print("\n全てのグラフの生成が完了しました!")
print("\n生成されたファイル:")
print(" 1. comparison_scatter.png - 目視との散布図比較")
print(" 2. comparison_vs_dmcount.png - DM-Countとの散布図比較")
print(" 3. error_distribution.png - 誤差の分布(箱ひげ図)")
print(" 4. comparison_per_image.png - 画像ごとの折れ線グラフ")
print(" 5. error_heatmap.png - 相対誤差のヒートマップ")