はじめに
自動車業界の1企業にて、SREチームのマネージャ兼アーキテクトとして活動しています。
SREというと運用のイメージを持つ方が少なくないと思いますが、我々は効率的な運用を実現するためにサービスの企画、計画、要件定義、設計、テストなどにも参画します。本ドキュメントではITサービス(以降、プロダクトと言い換えます)の信頼性に焦点を当て、要件定義からテストまでの活動例をご紹介します。特にFMEAのアプローチに焦点を当て、前後のステップに関する記述は簡略化します。図の記載内容も実プロジェクトのものから変更しているのでイメージとして見てください。なお、プロダクトを開発、運用するに際してクラウドベンダーサービスを活用しています。開発スタイルとしてはスクラム開発を採用しています。
FMEAとは何か
FMEAは Failure Mode and Effect Analysisの略称です。FMEAを実施する目的は、潜在的な事故・故障を設計段階で予測・摘出することです。FMEAは「設計FMEA」「工程FMEA」などのように適用されるプロセスにより分類されます。FMEAは自動車業界でも広く活用されています。本ドキュメントにおいては「設計FMEA」に焦点を当てます。
FMEAでは「故障モード」と呼ばれる故障状態の分類を用います。製品や部品の故障モードを挙げていき、ユーザーや製品に及ぼす影響や危険度を予測します。さらに、想定される故障の発生確率や影響度合いを評価、ランク付けを行い、重大な事故・故障を予防します。
クラウドベンダーサービスの利用者が考慮すべき、そして対処できる故障モード
AWSやGCP、AzureのようなITベンダーが提供するクラウドベンダーサービスを使用する場合、サービスの内部構成は利用者に対して隠ぺいされます。つまり、内部構造に関して利用者がFMEAを実施することはできません。その代わりに、クラウドベンダーと利用者との間でSLAを結びます。この場合において、我々利用者はクラウドベンダーから提供される一つ一つのサービスを最下層の部品として、故障状態の分類を行うこととなります。
信頼性要件定義からテスト、運用までの活動例
開発、運用対象となるプロダクトで提供する顧客価値を確認あるいは定義するところから活動を開始し、その後は各StepのIN/OUTを数珠繋ぎにして活動を進めます。
Step1. 利用者に対してどのような価値を提供するかを決める
- プロダクトの提供価値について、POなどに確認します。機会が得られれば自らも提案します。
- 提供価値をもとに、対象アクターと、アクターによるプロダクトのユースケースを定義します。
Step2. 利用者に価値を体感いただくために必要なSLO、SLAを決める
-
開発するプロダクトの価値を利用者に体感いただくために必要となるSLO、SLAを定義します。(SLOとSLAの定義例については図1を参照)
-
SLO、SLAを信頼性観点で定義する際には、以下4つの信頼性副特性を参考にします。この特性の定義についてはJIS X 25010を参考にしています。
- 成熟性:通常の運用操作の下で,システム,製品又は構成要素が信頼性に対するニーズに合致している度合い
- 可用性:使用することを要求されたとき,システム,製品又は構成要素が運用操作可能及びアクセス可能な度合い。
- 障害許容性:ハードウェア又はソフトウェア障害にもかかわらず,システム,製品又は構成要素が意図したように運用操作できる度合い。
- 回復性:中断時又は故障時に,製品又はシステムが直接的に影響を受けたデータを回復し,システムを希望する状態に復元することができる度合い。
-
SLOやSLAはプロダクトのユースケースまたはユースケースグループごとに定義します。
-
費用や工数、期間といった制約についてもこのタイミングで確認します。開発局面だけでなく運用局面における制約も確認します。
図1. SLA、SLOの例

Step3. プロダクトを構成するクラウドベンダーサービスの基本構造を明らかにする
- プロダクトのユースケースを実現するアーキテクチャの論理モデルを描きます。論理モデルでは、システム構成要素を明記します。
- 次に、論理モデルを実現する物理モデルを描きます。物理モデルでは、論理モデルに記載されたシステム構成要素を実装するクラウドベンダーサービスを明記します。このタイミングでは実装するクラウドベンダーサービスは複数案あってもかまいません。
Step4. プロダクトを構成するクラウドベンダーサービス単位で発生する可能性のある故障状態を整理し(FMEA)、その故障状態への対策を選定する
- 信頼性要件はクラウドベンダーサービスとクラウドベンダーサービスを利用する側の2つの観点で定義します。
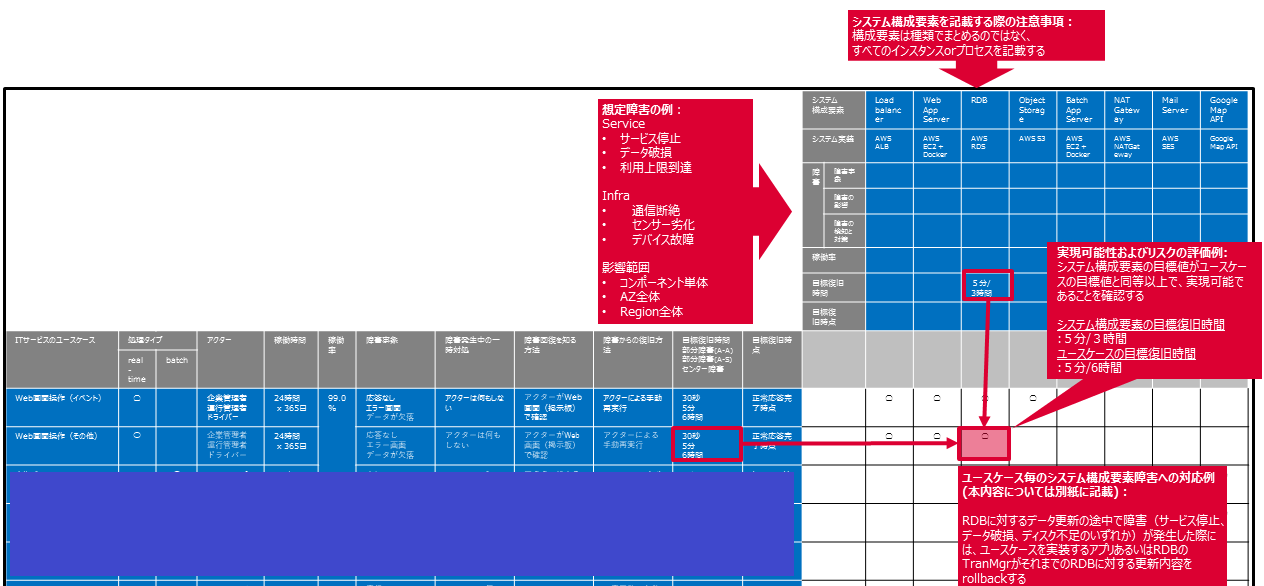
- クラウドベンダーサービスを利用する側の信頼性要件の定義に際しては、Step2で定義しユースケースやSLO、SLAなどをベースにし、必要に応じて加筆します。特に、図3の表に記載した観点で具体化することによってクラウドベンダーサービスを利用する側からの要件を明確にすることに努めます。ここではFTAのアプローチが役立ちます。
- その次にクラウドベンダーサービスに求める信頼性要件を定義することになりますが、その要件(の実現方法)を具体的に定義するために必要となる前提作業が故障状態の整理です。FMEAはここで活用します。
- 繰り返しとなりますが、AWSやAzureのようなITベンダーが提供するクラウドベンダーサービスを使用する場合、サービスとして提供されるシステムの内部構成については、利用者に対して隠ぺいされます。その結果として、我々が考慮すべき、あるいは対処できる故障状態は(a)クラウドベンダーサービスが停止する、(b)データが破損する、(c)クラウドベンダーサービスの利用量制限に達するといったクラウドベンダーサービスの外から見た異常動作に限定されます。
- 故障が発生する確率については、過去の障害事例から推測します。
- クラウドベンダーサービス上に利用者が導入したソフトウェアやアプリケーションの故障モードに対する対応は利用者の責任で行います。
- 温度・湿度センサーの劣化や車両とクラウド間の通信障害といった故障モードへの対応について検討する場合は、このステップで実施します。(本ドキュメントでは記載対象外)
- 性能効率性品質やセキュリティ品質については、他に適当なアプローチがあるため、ここでは信頼性品質に絞ります。
Step5. 対処すべき故障状態に対する対策の案を出す
- 対策についても、クラウドベンダーサービス側での対策とクラウドベンダーサービスを利用する側の対策の2つの観点で案を出します。
- 対策の検討に際しては、デザインパターン( 参考文献2を参照)や他のプロダクトでの事例など等も参考にします。
- プロダクトのSLAを実現するためにクラウドベンダーサービスのSLAを前提とする場合には、クラウドベンダーサービス側での対策がそのクラウドベンダーサービスのSLAに記載されている前提条件を満たすようにします。
Step6. 投資対効果などの検討結果をもとにして、対策を決定する
- 対策によって、SLOやSLAを実現可能であることを机上で確認します。(実機での確認はStep8で実施します)
- 対策が自働化できない場合には、手運用に要する時間やその他のコストも見積もります。
- コストが想定以上に高くなってしまった場合は、先にSLOやSLAでうたっているレベルが本当に必要か再検討するチャンスと捉えます。
図2. プロダクトを構成するクラウドベンダーサービス、故障モード、故障時の影響、対策の例 (FMEA)
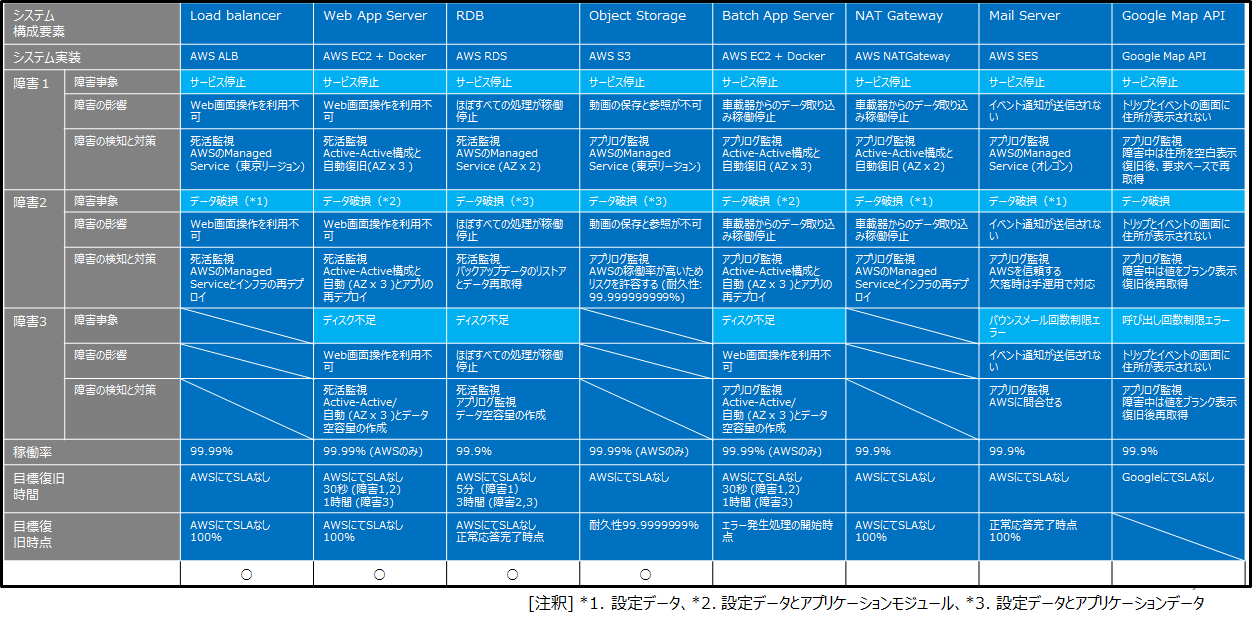
図3. クラウドベンダーサービスを利用する視点を加えた故障モードと、要件および対策に対する妥当性評価観点の例(右上のプロダクトを構成するクラウドベンダーサービスに関する項目は記述を省いているので図2を参照してください)
Step7. 信頼性要件を実現するシステムアーキテクチャを作成する
- Step3で描いた論理、物理レベルのアーキテクチャに対して、Step6で決定した対策を反映させます。これをもってアーキテクチャ図を完成させます。
Step8. 対策を基にテスト計画を立てる
- テストは、障害事象の発生→障害検知→対処→評価の一連の流れを実施します。一度の評価で要件を満たせないリスクを考慮して、対策検討→対策実施→再評価の活動も計画に入れます。
- 障害事象の発生方法は、AWSなど環境制約を考慮して決定します。
- 障害対処に関しては、システムで自動処理する処理と人が手作業で行う処理を含めます。
- 要件を満たすか否かは、SLOやSLAで定義した内容に基づいて判断します。
- テスト環境に関しては、ツールやサーバーだけでなく、インシデント管理ツールや担当者間のコミュニケーションツール、テスト目的に適切なデータも用意します。
Step9. テストを実施し、実現可能性を再評価する
- テスト結果に基き、コストなどの制約下でSLA、SLOを実現できることを確認します。
- 実現できることを確認できなかった場合には、対策を検討、実施し、再テストを行います。
Step10. プロダクトリリース後に想定外の故障モードが発生することに備えた運用を行う
- リリース後に想定外の故障モードが発生するリスクは決してゼロにはなりません。
- 想定外の故障モードが発生した場合に、早期発見、早期対応、潜在リスクへの事前対処を実施できるように、監視およびインシデント管理、問題管理の体制を整え、運用します。
参考文献
1.FTA/FMEA再入門の基礎知識
本ドキュメントで取り上げているFMEAやFTAについて関心を持たれた方は、まず本文献を参照してください。
2.『クラウドデザインパターン』カテゴリ:CDP:可用性を向上するパターン
デザインパターンは本文献に記載されているものだけでなく、サイドカーパターンなど様々なものがあります。