はじめに
前回は、Databricksで需要予測を行うための環境構築を行いました。
今回は、実際に需要予測モデルの最初のステップとして
「指数平滑法(Holt-Winters法)」を使った予測を見ていきます。
このパートでは、
- 需要予測の基本的な流れ
- 時系列データの扱い方
- シンプルな予測モデルの考え方
を理解することを目的とします。
01 事前確認
アクセラレータでは、データの再作成有無を設定できます。
| 設定 | 意味 |
|---|---|
| true | データを作り直す |
| false | 既存データを使用 |
今回は既存データを利用します。
print(dbname)
print(catalog)
02 Databricksのデータ構造
Databricksではデータは以下の階層で管理されます。
Catalog
↓
Schema(Database)
↓
Table
今回の例:
hirota_fcst_catalog
↓
demand_planning
↓
part_level_demand
03 環境セットアップ
このNotebookでは、需要予測に必要なライブラリを読み込みます。
主な分類は以下の通りです。
① データ処理
import numpy as np
import pandas as pd
- numpy:数値計算
- pandas:データ操作
② 可視化
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import matplotlib.dates as md
需要推移や予測結果をグラフで確認するためのツール
③ 時系列モデル
from statsmodels.tsa.api import ExponentialSmoothing, SimpleExpSmoothing, Holt
from statsmodels.tsa.statespace.sarimax import SARIMAX
| モデル | 用途 |
|---|---|
| SimpleExpSmoothing | 単純指数平滑 |
| Holt | トレンド対応 |
| ExponentialSmoothing | 季節性対応 |
| SARIMAX | ARIMA系 |
④ MLflow
import mlflow
モデルや評価結果を管理するツールになります
⑤ Hyperopt
from hyperopt import hp, fmin
モデルのパラメータを自動調整するツールになります
⑥ Spark
import pyspark.sql.functions as f
大量データの処理のためのツール
補足:なぜSparkを使うのか
時系列モデルの基本として
1つの時系列 → 1つのモデル
を作成していきます。
つまり、
5商品 → 5モデル
となります。
実務では1000商品、10000商品以上の数を取り扱うことになり、この商品数のモデルを作成する必要があります。
ここで、Databricksの強みであるSparkを使うと、商品ごとに並列でモデル作成が可能となります。
04 データ整形
時系列モデルでは、データを「時間順」に整える必要があります。
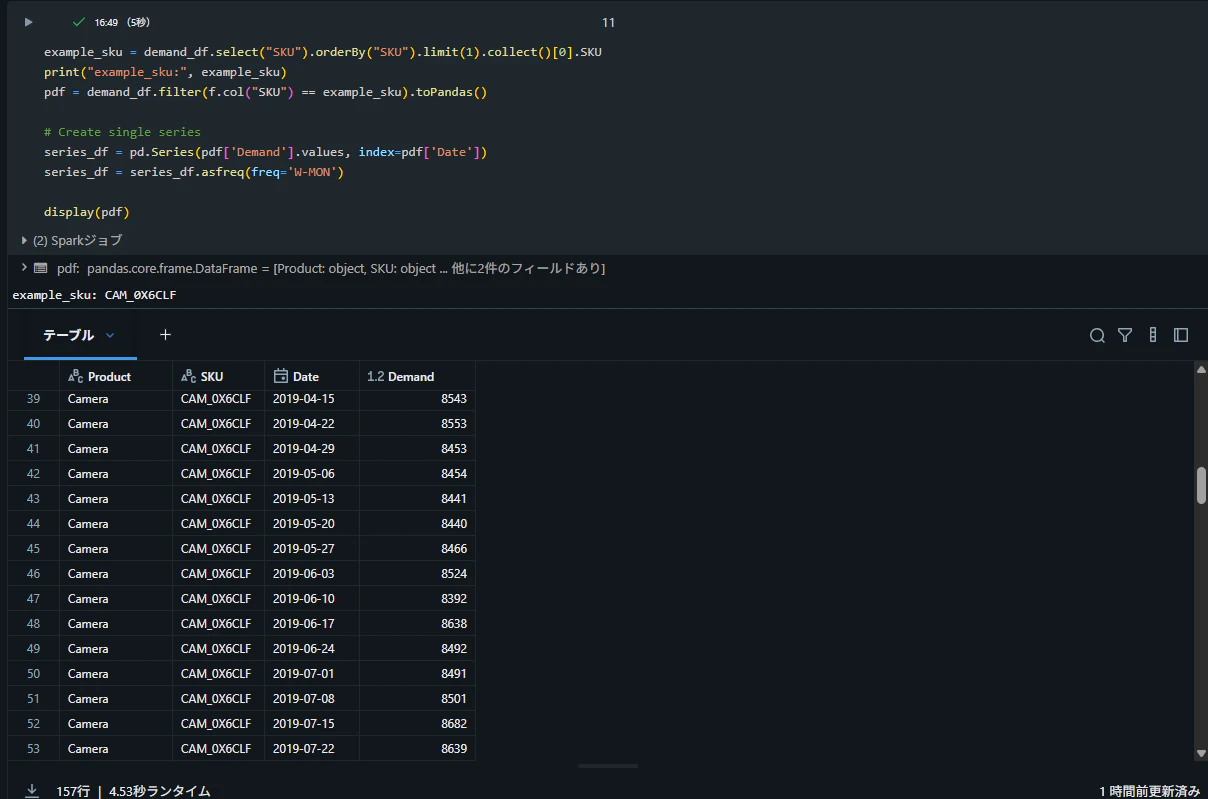
pd.Series(
pdf['Demand'].values,
index=pdf['Date']
)
👉 Demandを値、Dateをインデックスに整形
series_df = series_df.asfreq('W-MON')
👉 週次データとして統一
※ 時系列モデルでは 時間間隔が一定であることが必須
05 学習データの作成(バックテスト)

forecast_horizon = 40
👉 未来40週を予測
is_history = [True] * (len(series_df) - forecast_horizon) + [False] * forecast_horizon
| 値 | 意味 |
|---|---|
| True | 学習データ |
| False | 評価データ |
バックテストとは
未来データがないため、
👉 過去の一部を「未来」として扱う
06 外部要因の作成
需要は外部要因にも影響されます。
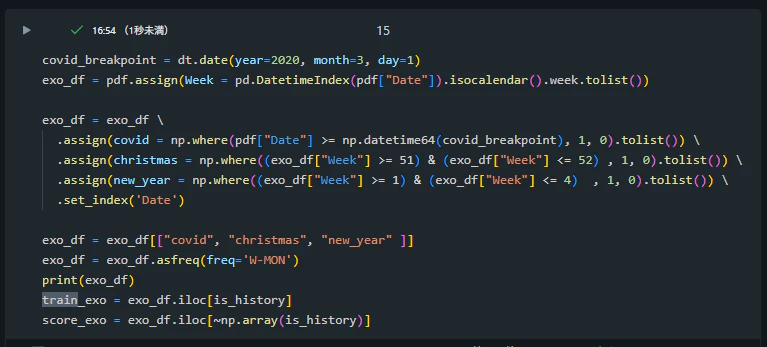
例👇
- コロナ
- クリスマス
- 年始
covid_breakpoint = dt.date(year=2020, month=3, day=1)
👉 コロナ開始日の定義
「2020/3/1以降はコロナ影響があるとみなす」という“境界日”を決めています
exo_df = pdf.assign(Week = pd.DatetimeIndex(pdf["Date"]).isocalendar().week.tolist())
👉 Week(週番号)を作る:クリスマス/年始判定に使う
exo_df = exo_df \
.assign(covid = np.where(pdf["Date"] >= np.datetime64(covid_breakpoint), 1, 0).tolist()) \
.assign(christmas = np.where((exo_df["Week"] >= 51) & (exo_df["Week"] <= 52) , 1, 0).tolist()) \
.assign(new_year = np.where((exo_df["Week"] >= 1) & (exo_df["Week"] <= 4) , 1, 0).tolist()) \
.set_index('Date')
👉 covid / christmas / new_year の “0/1フラグ” を作る
07 指数平滑法(Holt-Winters法)
ここからモデルの話です。指数平滑法のモデルを利用して分析とモデルの比較を行います。
💡 なぜ最初に指数平滑法を使うのか
需要予測には様々なモデルがありますが、
- シンプルで理解しやすい
- トレンド・季節性を扱える
- ベースラインとして使える
という理由から、まず最初に指数平滑法を使って全体像を理解します。
以下の画面では、指数平滑法で4種類のモデルを作成と各モデルの比較を行っています。
指数平滑法(Holt-Winters法)とは?
👉 時系列データの以下を扱えるモデルとなります
- トレンド(増減)
- 季節性(周期)
モデル作成
ExponentialSmoothing(
train,
seasonal_periods=3,
trend="add",
seasonal="add"
).fit()
パラメータ解説
seasonal_periods
| データ | 値 |
|---|---|
| 月次 | 12 |
| 週次 | 52 |
| 四半期 | 4 |
※ 今回はサンプルデータの都合上、seasonal_periods=3となっていますが、
通常の週次データでは52(1年周期)を設定することが一般的とされています。
trend
- add:一定の変化
- mul:比例変化
seasonal
- add:一定の季節変動
- mul:変動が大きくなる
use_boxcox
👉 データを安定させる
08 結果の確認
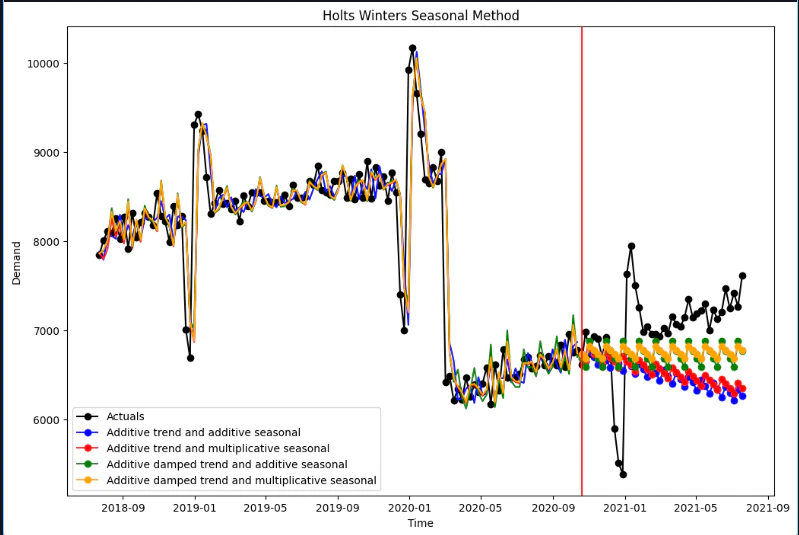
- 黒:実績
- 左側:学習
- 右側:予測
結果の考察
結果を見ると、予測データが実績データのデータと差があるように見られます。
指数平滑法は、指数平滑法はシンプルで扱いやすい一方、
- 外部要因を直接扱えない
- 複雑な変動に弱い
といった特徴があります。
そのため、今回のようなデータでは精度が出にくい結果となりました。
まとめ
今回は、
- 時系列データの扱い方
- Holt-Wintersモデル
- 需要予測の基本
について整理してみました。
指数平滑法では精度が出なかったため、次回はより高度なモデルであるSARIMAXを使って需要予測を行っていきます。
外部要因も考慮した予測がどのように変わるのかを見ていきたいと思います。